W świecie SQL Server istnieją dwa typy ludzi:ci, którzy lubią, gdy wszystkie ich obiekty mają prefiksy, i ci, którzy tego nie lubią. Pierwsza grupa jest dalej podzielona na dwie kategorie:ci, którzy poprzedzają procedury składowane przedrostkiem sp_ i tych, którzy wybierają inne prefiksy (takie jak usp_ lub proc_ ). Od dawna zaleca się unikanie sp_ prefiks, zarówno ze względu na wydajność, jak i w celu uniknięcia niejednoznaczności lub kolizji w przypadku wybrania nazwy, która już istnieje w katalogu systemowym. Kolizje z pewnością nadal stanowią problem, ale zakładając, że zweryfikowałeś nazwę swojego obiektu, czy nadal jest to problem z wydajnością?
Wersja TL;DR:TAK.
Prefiks sp_ jest nadal nie-nie. Ale w tym poście wyjaśnię, dlaczego, jak SQL Server 2012 może prowadzić do przekonania, że ta ostrzegawcza rada już nie ma zastosowania, oraz kilka innych potencjalnych skutków ubocznych wyboru tej konwencji nazewnictwa.
Na czym polega problem z sp_?
sp_ prefiks nie oznacza tego, co myślisz, że robi:większość ludzi myśli sp oznacza „procedura składowana”, podczas gdy w rzeczywistości oznacza „specjalny”. Procedury składowane (a także tabele i widoki) przechowywane we wzorcu z sp_ prefiksy są dostępne z dowolnej bazy danych bez odpowiedniego odniesienia (zakładając, że nie istnieje wersja lokalna). Jeśli procedura jest oznaczona jako obiekt systemowy (za pomocą sp_MS_marksystemobject (nieudokumentowana i nieobsługiwana procedura systemowa, która ustawia is_ms_shipped do 1), to procedura w master zostanie wykonana w kontekście wywołującej bazy danych. Spójrzmy na prosty przykład:
CREATE DATABASE sp_test;
GO
USE sp_test;
GO
CREATE TABLE dbo.foo(id INT);
GO
USE master;
GO
CREATE PROCEDURE dbo.sp_checktable
AS
SELECT DB_NAME(), name
FROM sys.tables WHERE name = N'foo';
GO
USE sp_test;
GO
EXEC dbo.sp_checktable; -- runs but returns 0 results
GO
EXEC master..sp_MS_marksystemobject N'dbo.sp_checktable';
GO
EXEC dbo.sp_checktable; -- runs and returns results
GO Wyniki:
(0 row(s) affected) sp_test foo (1 row(s) affected)
Problem z wydajnością wynika z faktu, że master może być sprawdzany pod kątem równoważnej procedury składowanej, w zależności od tego, czy istnieje lokalna wersja procedury i czy faktycznie istnieje równoważny obiekt w master. Może to prowadzić do dodatkowych kosztów metadanych, a także dodatkowego SP:CacheMiss wydarzenie. Pytanie brzmi, czy ten koszt jest namacalny.
Rozważmy więc bardzo prostą procedurę w testowej bazie danych:
CREATE DATABASE sp_prefix; GO USE sp_prefix; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
I równoważne procedury w masterze:
USE master; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'master', DB_NAME(); END GO EXEC sp_MS_marksystemobject N'sp_something';
CacheMiss:fakt czy fikcja?
Jeśli uruchomimy szybki test z naszej testowej bazy danych, zobaczymy, że wykonanie tych procedur składowanych nigdy nie wywoła w rzeczywistości wersji z wzorca, niezależnie od tego, czy prawidłowo zakwalifikujemy procedurę w oparciu o bazę danych lub schemat (powszechne błędne przekonanie), czy też zaznaczymy wersja główna jako obiekt systemowy:
USE sp_prefix; GO EXEC sp_prefix.dbo.sp_something; GO EXEC dbo.sp_something; GO EXEC sp_something;
Wyniki:
sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix
Uruchommy także Quick TraceSP:CacheMiss wydarzenia:
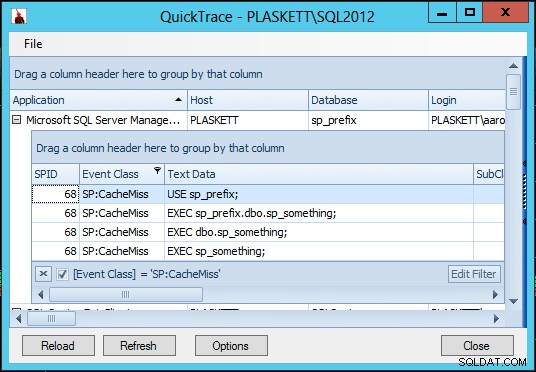
Widzimy CacheMiss zdarzenia dla partii ad hoc, która wywołuje procedurę składowaną (ponieważ program SQL Server zazwyczaj nie przejmuje się buforowaniem partii, która składa się głównie z wywołań procedur), ale nie dla samej procedury składowanej. Zarówno z, jak i bez sp_something procedura istniejąca w master (i gdy istnieje, zarówno z zaznaczeniem, jak i bez oznaczenia jako obiekt systemowy), wywołania sp_something w bazie danych użytkownika nigdy "przypadkowo" nie wywołuj procedury w master i nigdy nie generuj żadnego CacheMiss wydarzenia dla procedury.
To było na SQL Server 2012. Powtórzyłem te same testy na SQL Server 2008 R2 i znalazłem nieco inne wyniki:
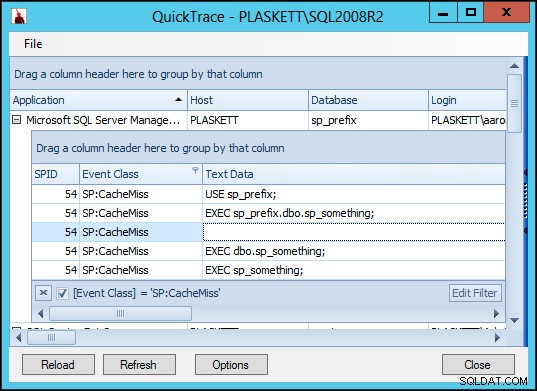
Tak więc w SQL Server 2008 R2 widzimy dodatkowy CacheMiss zdarzenie, które nie występuje w programie SQL Server 2012. Dzieje się tak we wszystkich scenariuszach (brak równoważnego wzorca obiektu, obiekt w wzorcu oznaczony jako obiekt systemowy i obiekt w wzorcu nieoznaczony jako obiekt systemowy). Od razu byłem ciekaw, czy to dodatkowe wydarzenie będzie miało jakiś zauważalny wpływ na wydajność.
Problem z wydajnością:fakt czy fikcja?
Dokonałem dodatkowej procedury bez sp_ prefiks do porównania surowej wydajności, CacheMiss na bok:
USE sp_prefix; GO CREATE PROCEDURE dbo.proc_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
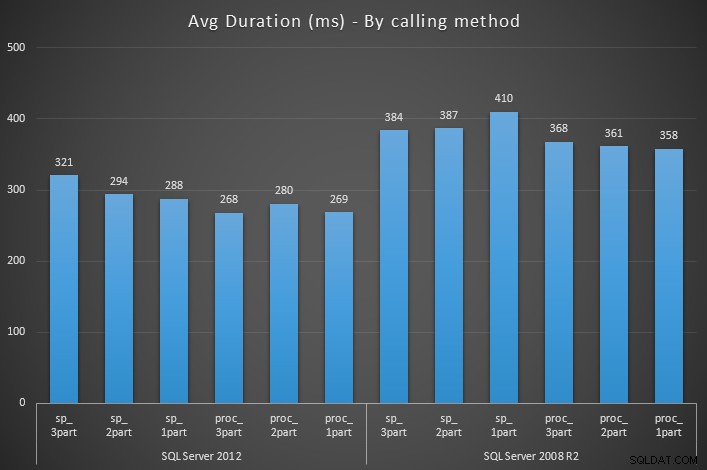
Więc jedyna różnica między sp_something i proc_something . Następnie utworzyłem procedury opakowujące, aby wykonać je 1000 razy każda, używając EXEC sp_prefix.dbo.<procname> , EXEC dbo.<procname> i EXEC <procname> składnia, z równoważnymi procedurami składowanymi znajdującymi się w systemie nadrzędnym i oznaczonymi jako obiekt systemowy, znajdującymi się w systemie nadrzędnym, ale nie oznaczonymi jako obiekt systemowy i w ogóle nie działającymi w systemie nadrzędnym.
USE sp_prefix;
GO
CREATE PROCEDURE dbo.wrap_sp_3part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_prefix.dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_2part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_1part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_something;
SET @i += 1;
END
END
GO
-- repeat for proc_something
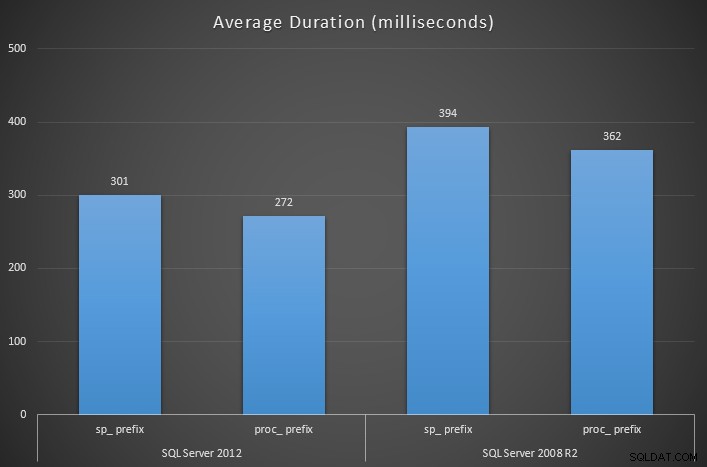
Mierząc czas trwania każdej procedury opakowującej za pomocą SQL Sentry Plan Explorer, wyniki pokazują, że przy użyciu sp_ prefiks ma znaczący wpływ na średni czas trwania w prawie wszystkich przypadkach (i na pewno średnio):