To jest pisemna wersja mojego nowego filmu na YouTube
W tym samouczku Redis dowiesz się o Redis i jak Redis może być używany jako podstawowa baza danych dla złożonych aplikacji które muszą przechowywać dane w wielu formatach.
Przegląd 📝
- Co to jest Redis i jego zastosowania a także dlaczego nadaje się do nowoczesnych złożonych aplikacji mikroserwisowych?
- Jak Redis obsługuje przechowywanie wielu formatów danych do różnych celów za pomocą swoich modułów ?
- Jak Redis jako baza danych w pamięci może utrwalić dane i odzyskać dane po utracie ?
- Jak skalować i replikować Redis ?
- Wreszcie, ponieważ jedną z najpopularniejszych platform do uruchamiania mikrousług jest Kubernetes, a uruchamianie aplikacji stanowych w Kubernetes jest nieco trudne, zobaczymy, jak łatwo uruchomić Redis w Kubernetes
Co to jest Redis?
Redis oznacza re mote dyk y serwer
Redis to baza danych w pamięci . Tak więc wiele osób używało go jako pamięci podręcznej nad innymi bazami danych w celu poprawy wydajności aplikacji.
Jednak wiele osób nie wie, że Redis jest w pełni rozwiniętą podstawową bazą danych które mogą być używane do przechowywania i utrwalania wielu formatów danych dla złożonych aplikacji.
Zobaczmy więc przypadki użycia tego.
Dlaczego wielomodelowa baza danych?
Spójrzmy na typową konfigurację aplikacji mikroserwisów.
Załóżmy, że mamy złożoną aplikację społecznościową z milionami użytkowników. W tym celu może być konieczne przechowywanie różnych formatów danych w różnych bazach danych:
- Relacyjna baza danych , jak Mysql, do przechowywania naszych danych
- ElasticSearch do szybkiego wyszukiwania i filtrowania
- Baza danych wykresów do reprezentowania połączeń użytkowników
- Baza danych dokumentów , jak MongoDB do przechowywania treści multimedialnych udostępnianych codziennie przez naszych użytkowników
- Usługa pamięci podręcznej dla lepszej wydajności aplikacji
To oczywiste, że jest to dość skomplikowana konfiguracja.
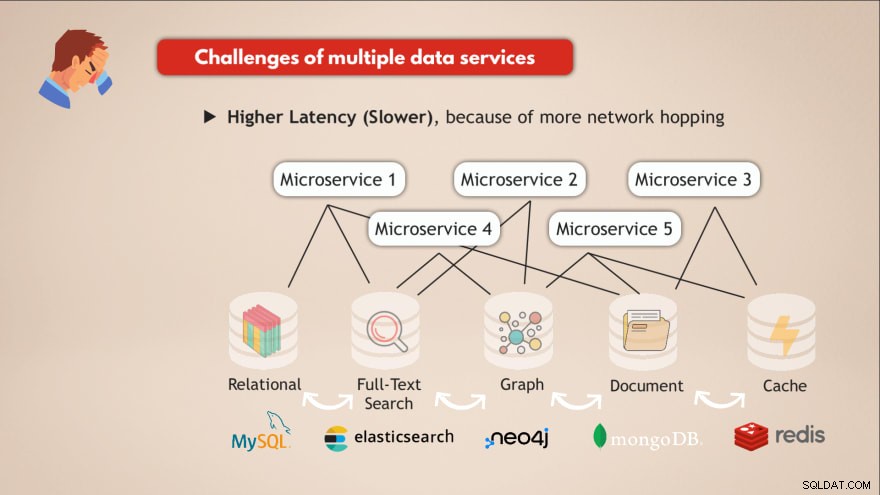
Wyzwania związane z posiadaniem wielu usług danych
- ❌ Każda usługa danych musi być wdrożona i utrzymywana
- ❌ Know-How potrzebne dla każdej usługi danych
- ❌ Różne wymagania dotyczące skalowania i infrastruktury
- ❌ Bardziej złożony kod aplikacji do interakcji z tymi wszystkimi różnymi bazami danych
- ❌ Większe opóźnienie (wolniej), ze względu na większe przeskakiwanie sieci
Posiadanie wielomodelowej bazy danych
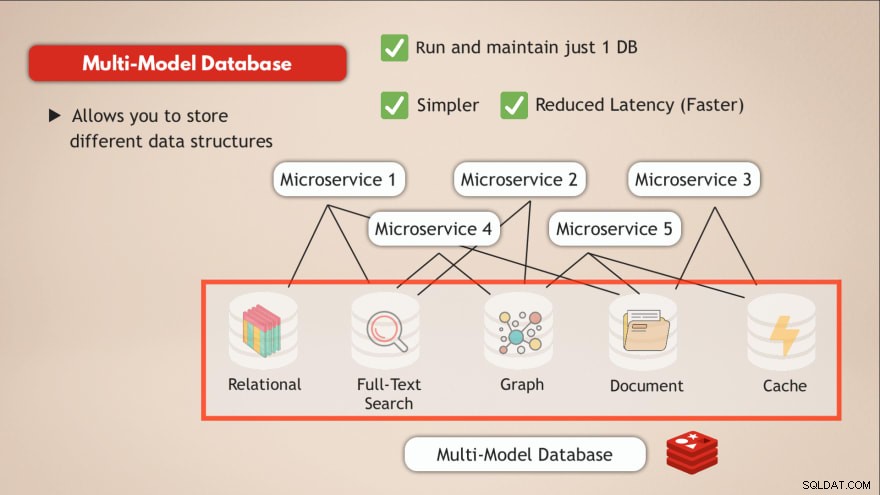
W porównaniu z wielomodelową bazą danych rozwiązujesz większość tych wyzwań. Przede wszystkim uruchamiasz i utrzymujesz tylko 1 usługę danych . Twoja aplikacja musi również komunikować się z jednym magazynem danych, a to wymaga tylko jednego interfejsu programistycznego dla tej usługi danych.
Ponadto opóźnienia zostaną zmniejszone dzięki przejściu do jednego punktu końcowego danych i wyeliminowaniu kilku koncentratorów sieci wewnętrznej.
Posiadanie jednej bazy danych, takiej jak Redis, która pozwala przechowywać różne typy danych lub w zasadzie pozwala mieć wiele typów baz danych w jednej, a także działać jako pamięć podręczna, rozwiązuje takie wyzwania.
- ✅ Uruchom i utrzymuj tylko 1 bazę danych
- ✅ Prostsze
- ✅ Zmniejszone opóźnienie (szybciej)
Jak działa Redis?
Moduły Redis
Działa to tak, że masz Redis Core, który jest kluczem do przechowywania wartości który już obsługuje przechowywanie wielu typów danych, a następnie możesz rozszerzyć ten rdzeń za pomocą tak zwanych modułów dla różnych typów danych , których Twoja aplikacja potrzebuje do różnych celów. Na przykład RediSearch dla funkcji wyszukiwania, takich jak ElasticSearch lub Redis Graph do przechowywania danych wykresów i tak dalej:

Wspaniałą rzeczą w tym jest to, że jest modułowy . Tak więc te różne typy funkcji bazy danych nie są ściśle zintegrowane z jedną bazą danych, ale raczej możesz wybrać dokładnie taką funkcjonalność usługi danych, której potrzebujesz dla swojej aplikacji, a następnie w zasadzie dodać ten moduł.
Niestandardowa pamięć podręczna
Oczywiście, gdy używasz Redis jako podstawowej bazy danych, nie potrzebujesz dodatkowej pamięci podręcznej, ponieważ masz ją automatycznie po wyjęciu z pudełka z Redis. Oznacza to ponownie mniejszą złożoność Twojej aplikacji, ponieważ nie musisz implementować logiki zarządzania wypełnianiem i unieważnianiem pamięci podręcznej.
Redis jest szybki
Jako baza danych w pamięci (dane są przechowywane w pamięci RAM), Redis jest bardzo szybki i wydajny, co oczywiście przyspiesza samą aplikację.
Ale w tym momencie możesz się zastanawiać:
Jak baza danych w pamięci może utrwalać dane?
W jaki sposób Redis może utrwalać dane i odzyskiwać dane po ich utracie?
Jeśli proces Redis lub serwer, na którym działa Redis, ulegnie awarii, wszystkie dane w pamięci zniknęły, prawda? Jak więc dane są utrwalane i jak mogę mieć pewność, że moje dane są bezpieczne?
Replikować Redisa?
Cóż, najprostszym sposobem na tworzenie kopii zapasowych danych jest replikacja Redis . Jeśli więc instancja główna Redis ulegnie awarii, repliki będą nadal działać i będą miały wszystkie dane. Więc jeśli masz zreplikowany Redis, repliki będą zawierały dane.
Ale oczywiście, jeśli wszystkie instancje Redis ulegną awarii, utracisz dane, ponieważ nie pozostanie żadna replika. 🤯Więc potrzebujemy prawdziwej wytrwałości .
Migawki i AOF
Redis ma wiele mechanizmów utrwalania danych i ich bezpieczeństwa.
Migawki
Pierwsza:migawki, które możesz skonfigurować na podstawie czasu, liczby żądań itp. Zatem migawki Twoich danych będą przechowywane na dysku , którego możesz użyć do odzyskania danych, jeśli cała baza danych Redis zniknie.
Pamiętaj jednak, że stracisz ostatnie minuty danych , ponieważ zwykle robisz zrzuty co pięć minut lub godzinę, w zależności od potrzeb.
AOF
Jako alternatywę Redis używa czegoś, co nazywa się AOF , co oznacza A dołącz O tylko K ile.
W takim przypadku każda zmiana jest zapisywana na dysku w celu ciągłego utrwalania . A po ponownym uruchomieniu Redis lub po wyłączeniu Redis ponownie odtworzy dzienniki tylko dołączaj pliki, aby odbudować stan.
Więc AOF jest trwalszy , ale może być wolniejsze niż robienie zrzutów.
Najlepsza opcja Uwaga:Użyj kombinacji zarówno AOF, jak i migawek, w których AOF stale utrwala dane z pamięci na dysk, a ponadto masz regularne migawki, aby zapisać stan danych na wypadek konieczności ich odzyskania:

Jak skalować bazę danych Redis?
Załóżmy, że moja 1 instancja Redis zabraknie pamięci, więc dane stają się zbyt duże, aby pomieścić w pamięci lub Redis staje się wąskim gardłem i nie może obsłużyć więcej żądań. W takim przypadku, jak zwiększyć pojemność i rozmiar pamięci? dla mojej bazy danych Redis?
Mamy na to kilka opcji:
1. Klastrowanie
Przede wszystkim Redis obsługuje klastrowanie . Oznacza to, że możesz mieć podstawową lub główną instancję Redis, która może służyć do odczytywania i zapisywania danych, a także możesz mieć wiele replik tej podstawowej instancji do odczytywania danych :
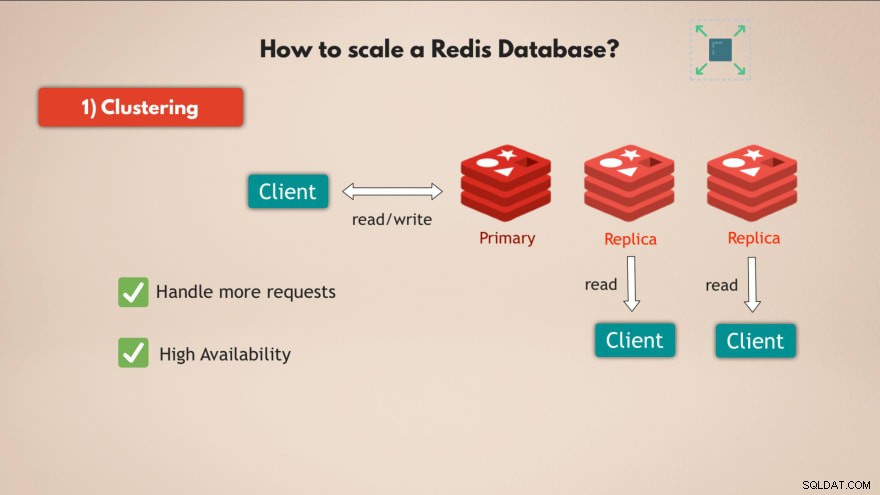
W ten sposób możesz skalować Redis, aby obsłużyć więcej żądań, a ponadto zwiększyć wysoką dostępność Twojej bazy danych, ponieważ jeśli master ulegnie awarii, 1 z replik może przejąć kontrolę, a Twoja baza danych Redis w zasadzie może nadal działać bez żadnych problemów.
2. Sharding
Cóż, wydaje się to wystarczająco dobre, ale co jeśli
- Twój zestaw danych staje się zbyt duży, aby zmieścić się w pamięci na jednym serwerze .
- Dodatkowo przeskalowaliśmy odczyty w bazie danych, więc wszystkie żądania, które w zasadzie tylko odpytują dane. Ale nasza główna instancja jest nadal sama i nadal musi obsługiwać wszystkie zapisy .
Więc jakie jest tutaj rozwiązanie?
W tym celu używamy koncepcji shardingu , która jest ogólną koncepcją w bazach danych i którą obsługuje również Redis.
Więc sharding zasadniczo oznacza to, że zabierasz cały zestaw danych i dzielisz go na mniejsze porcje lub podzbiory danych , gdzie każdy fragment odpowiada za własny podzbiór danych.
Oznacza to, że zamiast mieć jedną główną instancję, która obsługuje wszystkie zapisy do pełnego zestawu danych, możesz podzielić go na, powiedzmy, 4 fragmenty, z których każdy odpowiada za odczyty i zapisy w podzbiorze danych .
Każdy odłamek wymaga również mniej pojemności pamięci , ponieważ mają tylko jedną czwartą danych. Oznacza to, że możesz dystrybuować i uruchamiać shardy na mniejszych węzłach i zasadniczo skalować swój klaster w poziomie:
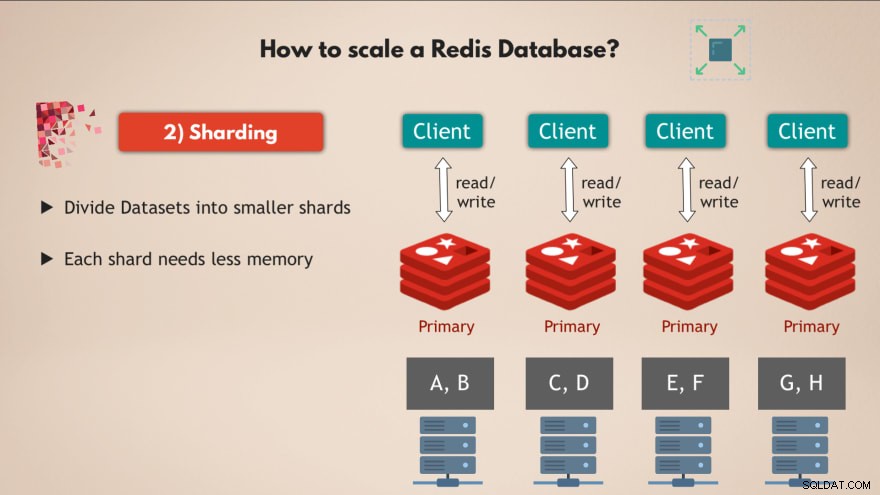
Zatem posiadanie wielu węzłów , które uruchamiają wiele replik Redis, które są wszystkie podzielone zapewnia bardzo wydajną i wysoce dostępną bazę danych Redis, która może obsłużyć znacznie więcej żądań bez tworzenia wąskich gardeł 👍
Więcej tematów...
Obejrzyj mój film poniżej, aby poznać 2 ostatnie tematy i scenariusze:
- Aplikacje, które wymagają jeszcze wyższej dostępności i wydajności w wielu lokalizacjach geograficznych
- Nowym standardem uruchamiania mikroserwisów jest platforma Kubernetes, więc uruchamianie Redis w Kubernetes jest bardzo interesującym i powszechnym przypadkiem użycia
Pełny film jest dostępny tutaj:🤓
Mam nadzieję, że dla niektórych z Was było to pomocne i interesujące!
Polub, udostępnij i obserwuj mnie 😍 więcej treści:
- Instagram – publikowanie wielu rzeczy zza kulis
- Prywatna grupa na FB



