W tym artykule zbudujemy skrobak dla rzeczywistego koncert dla freelancerów, podczas którego klient chce, aby program w Pythonie pobierał dane z Stack Overflow, aby pobrać nowe pytania (tytuł pytania i adres URL). Zeskrobane dane powinny być następnie przechowywane w MongoDB. Warto zauważyć, że Stack Overflow ma interfejs API, za pomocą którego można uzyskać dostęp do dokładnego te same dane. Jednak klient chciał skrobaka, więc skrobak jest tym, co otrzymał.
Bezpłatny bonus: Kliknij tutaj, aby pobrać szkielet projektu Python + MongoDB z pełnym kodem źródłowym, który pokazuje, jak uzyskać dostęp do MongoDB z Pythona.
Aktualizacje:
- 01.03.2014 - Refaktoryzacja pająka. Dzięki, @kissgyorgy.
- 18.02.2015 – Dodano część 2.
- 06.09.2015 – Zaktualizowano do najnowszej wersji Scrapy i PyMongo – na zdrowie!
Jak zawsze, zapoznaj się z warunkami użytkowania/usługami witryny i przestrzegaj pliku robots.txt pliku przed rozpoczęciem jakiejkolwiek pracy zgarniania. Upewnij się, że przestrzegasz etycznych praktyk skrobania, nie zalewając witryny licznymi prośbami w krótkim czasie. Traktuj każdą wyszukiwaną witrynę jak własną .
Instalacja
Potrzebujemy biblioteki Scrapy (v1.0.3) wraz z PyMongo (v3.0.3) do przechowywania danych w MongoDB. Musisz również zainstalować MongoDB (nie omówione).
Zadrapanie
Jeśli używasz OSX lub odmiany Linuksa, zainstaluj Scrapy za pomocą pip (z aktywowanym virtualenv):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Jeśli jesteś na komputerze z systemem Windows, będziesz musiał ręcznie zainstalować kilka zależności. Zapoznaj się z oficjalną dokumentacją, aby uzyskać szczegółowe instrukcje, a także z tym filmem na YouTube, który stworzyłem.
Po skonfigurowaniu Scrapy zweryfikuj swoją instalację, uruchamiając to polecenie w powłoce Pythona:
>>>>>> import scrapy
>>>
Jeśli nie pojawi się błąd, dobrze jest iść!
PyMongo
Następnie zainstaluj PyMongo za pomocą pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Teraz możemy zacząć budować robota.
Scrapy projekt
Zacznijmy nowy projekt Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Spowoduje to utworzenie wielu plików i folderów, które zawierają podstawowy szablon, który umożliwia szybkie rozpoczęcie pracy:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Określ dane
items.py plik służy do definiowania „kontenerów” przechowywania danych, które planujemy zeskrobać.
StackItem() klasa dziedziczy z Item (dokumenty), który zasadniczo zawiera wiele predefiniowanych obiektów, które Scrapy już dla nas zbudował:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Dodajmy kilka przedmiotów, które faktycznie chcemy zebrać. Dla każdego pytania klient potrzebuje tytułu i adresu URL. Zaktualizuj items.py jak tak:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Stwórz Pająka
Utwórz plik o nazwie stack_spider.py w katalogu „pająki”. To tutaj dzieje się magia – np. kiedy powiemy Scrapy, jak znaleźć dokładnie dane, których szukamy. Jak możesz sobie wyobrazić, jest to konkretne do każdej strony internetowej, którą chcesz zeskrobać.
Zacznij od zdefiniowania klasy, która dziedziczy po Spider Scrapy'ego a następnie dodawanie atrybutów według potrzeb:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Kilka pierwszych zmiennych nie wymaga wyjaśnień (dokumenty):
namedefiniuje nazwę Pająka.allowed_domainszawiera podstawowe adresy URL dozwolonych domen do indeksowania przez pająka.start_urlsto lista adresów URL, od których pająk ma zacząć indeksować. Wszystkie kolejne adresy URL będą zaczynały się od danych, które pająk pobiera z adresów URL wstart_urls.
Selektory XPath
Następnie Scrapy używa selektorów XPath do wyodrębniania danych ze strony internetowej. Innymi słowy, możemy wybrać określone części danych HTML na podstawie podanej ścieżki XPath. Jak stwierdzono w dokumentacji Scrapy, „XPath to język do wybierania węzłów w dokumentach XML, który może być również używany z HTML”.
Możesz łatwo znaleźć konkretną ścieżkę XPath za pomocą Narzędzi programistycznych Chrome. Po prostu sprawdź określony element HTML, skopiuj XPath, a następnie dostosuj (w razie potrzeby):
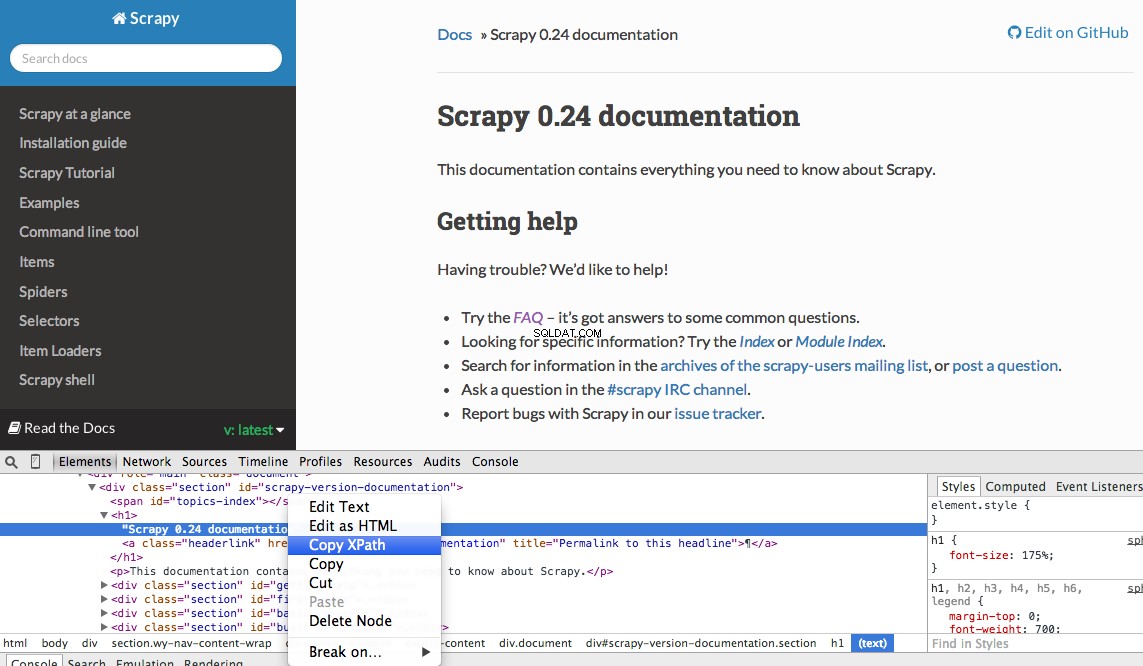
Narzędzia programistyczne dają również możliwość testowania selektorów XPath w konsoli JavaScript za pomocą $x - np. $x("//img") :
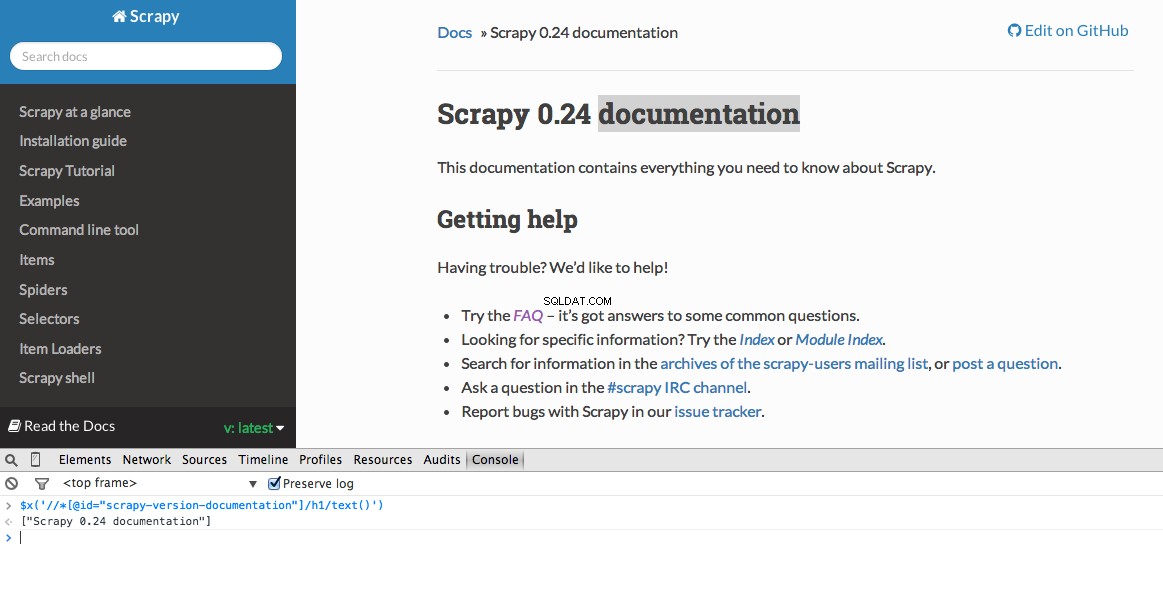
Ponownie, zasadniczo mówimy Scrapy, od czego zacząć szukać informacji na podstawie zdefiniowanej ścieżki XPath. Przejdźmy do witryny Stack Overflow w Chrome i znajdźmy selektory XPath.
Kliknij prawym przyciskiem myszy pierwsze pytanie i wybierz „Sprawdź element”:
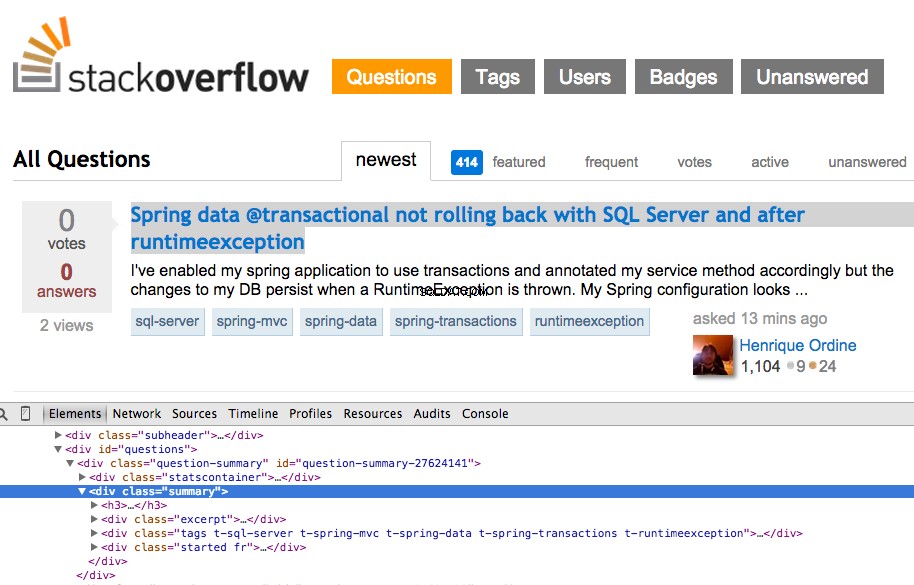
Teraz pobierz ścieżkę XPath dla <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , a następnie przetestuj go w konsoli JavaScript:
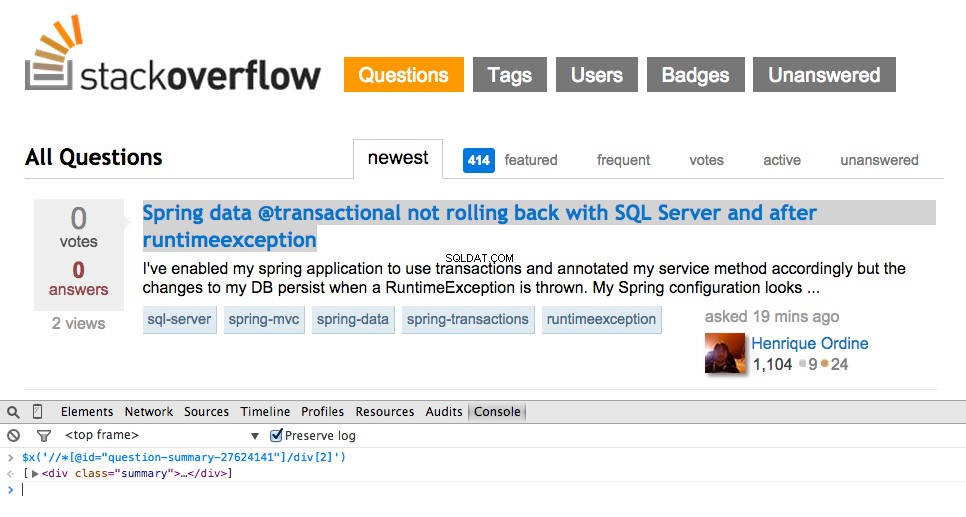
Jak widać, po prostu wybiera ten jeden pytanie. Musimy więc zmienić XPath, aby pobrać wszystkie pytania. Jakieś pomysły? To proste://div[@class="summary"]/h3 . Co to znaczy? Zasadniczo ten XPath stwierdza:Pobierz wszystkie <h3> elementy będące dziećmi <div> który ma klasę summary . Przetestuj tę ścieżkę XPath w konsoli JavaScript.
Zwróć uwagę, że nie używamy rzeczywistych danych wyjściowych XPath z Narzędzi dla programistów Chrome. W większości przypadków dane wyjściowe są tylko pomocne, co generalnie wskazuje właściwy kierunek do znalezienia działającej ścieżki XPath.
Teraz zaktualizujmy stack_spider.py skrypt:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Wyodrębnij dane
Nadal musimy analizować i przeszukiwać żądane dane, które mieszczą się w zakresie <div class="summary"><h3> . Ponownie zaktualizuj stack_spider.py jak tak:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Wraz ze śladem stosu Scrapy powinno zostać wyświetlonych 50 tytułów pytań i adresów URL. Możesz renderować dane wyjściowe do pliku JSON za pomocą tego małego polecenia:
$ scrapy crawl stack -o items.json -t json
Wdrożyliśmy teraz naszego Spidera w oparciu o nasze dane, których szukamy. Teraz musimy przechowywać zeskrobane dane w MongoDB.
Przechowuj dane w MongoDB
Za każdym razem, gdy zwracany jest element, chcemy zweryfikować dane, a następnie dodać je do kolekcji Mongo.
Pierwszym krokiem jest utworzenie bazy danych, której planujemy użyć do zapisania wszystkich naszych przeszukanych danych. Otwórz settings.py i określ potok i dodaj ustawienia bazy danych:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Zarządzanie rurociągami
Skonfigurowaliśmy naszego pająka do indeksowania i analizowania kodu HTML oraz skonfigurowaliśmy ustawienia bazy danych. Teraz musimy połączyć je razem przez potok w pipelines.py .
Połącz z bazą danych
Najpierw zdefiniujmy metodę rzeczywistego połączenia z bazą danych:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Tutaj tworzymy klasę MongoDBPipeline() i mamy funkcję konstruktora, która zainicjuje klasę przez zdefiniowanie ustawień Mongo, a następnie połączenie z bazą danych.
Przetwarzaj dane
Następnie musimy zdefiniować metodę przetwarzania przeanalizowanych danych:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Nawiązujemy połączenie z bazą danych, rozpakowujemy dane, a następnie zapisujemy je w bazie danych. Teraz możemy ponownie przetestować!
Test
Ponownie uruchom następujące polecenie w katalogu „stos”:
$ scrapy crawl stack
UWAGA :Upewnij się, że masz demona Mongo - mongod - działa w innym oknie terminala.
Hurra! Pomyślnie zapisaliśmy nasze zindeksowane dane w bazie danych:
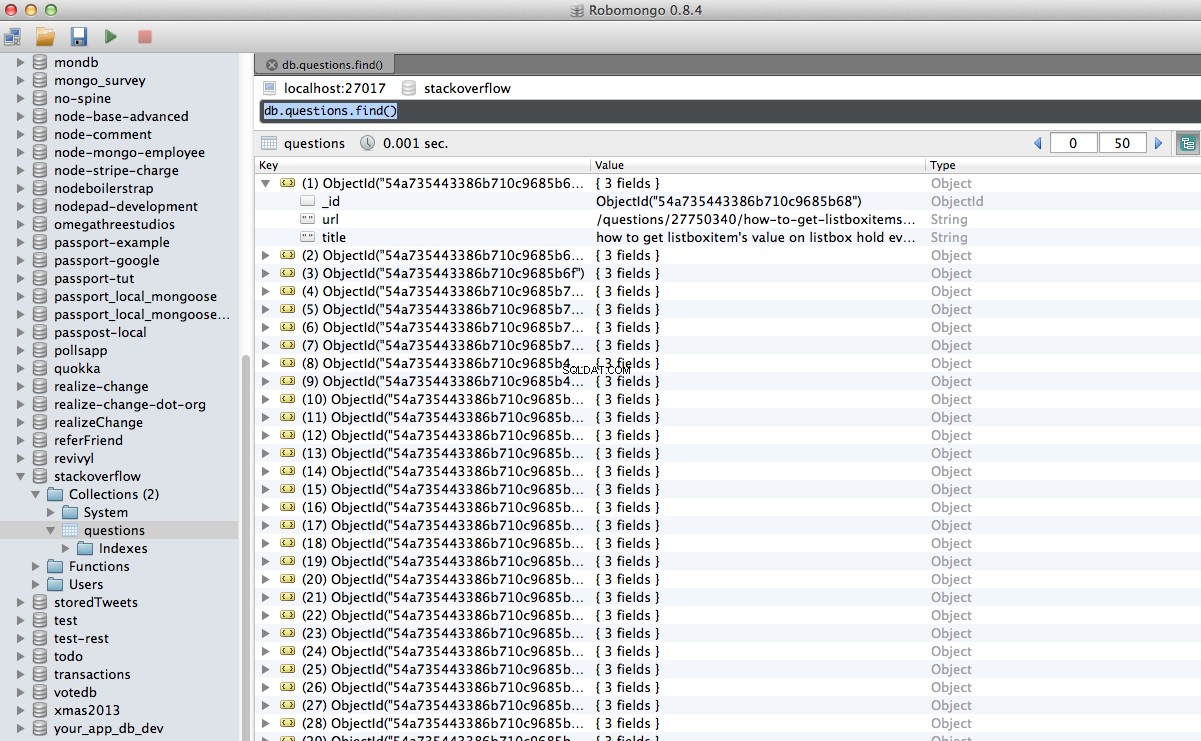
Wniosek
To całkiem prosty przykład wykorzystania Scrapy do indeksowania i skrobania strony internetowej. Rzeczywisty projekt freelancera wymagał od skryptu podążania za linkami stronicowania i skrobania każdej strony za pomocą CrawlSpider (dokumenty), co jest bardzo łatwe do wdrożenia. Spróbuj zaimplementować to na własną rękę i zostaw komentarz poniżej z linkiem do repozytorium Github, aby szybko sprawdzić kod.
Potrzebuję pomocy? Zacznij od tego skryptu, który jest prawie gotowy. Następnie zobacz część 2, aby zobaczyć pełne rozwiązanie!
Bezpłatny bonus: Kliknij tutaj, aby pobrać szkielet projektu Python + MongoDB z pełnym kodem źródłowym, który pokazuje, jak uzyskać dostęp do MongoDB z Pythona.
Możesz pobrać cały kod źródłowy z repozytorium Github. Komentarz poniżej z pytaniami. Dziękujemy za przeczytanie!



