Kiedy instalujesz ClusterControl, ma on domyślną konfigurację, która być może nie spełnia Twoich wymagań, więc prawdopodobnie będziesz musiał dostosować tę instalację. W tym celu można modyfikować pliki konfiguracyjne, ale można również sprawdzić lub zmodyfikować ustawienia środowiska wykonawczego ClusterControl. W tym blogu pokażemy, gdzie można zobaczyć tę konfigurację i jakie są dostępne opcje, których można tutaj użyć.
Gdzie możesz zobaczyć konfigurację środowiska wykonawczego ClusterControl?
Są dwa różne sposoby sprawdzenia tego. Najpierw możesz przejść do ClusterControl -> Ustawienia globalne -> Konfiguracje środowiska wykonawczego, a następnie wybrać swój klaster.
Innym sposobem jest ClusterControl -> Wybierz Cluster -> Ustawienia -> Konfiguracje wykonawcze .
W obu przypadkach przejdziesz w to samo miejsce, w Konfiguracji środowiska wykonawczego sekcja.
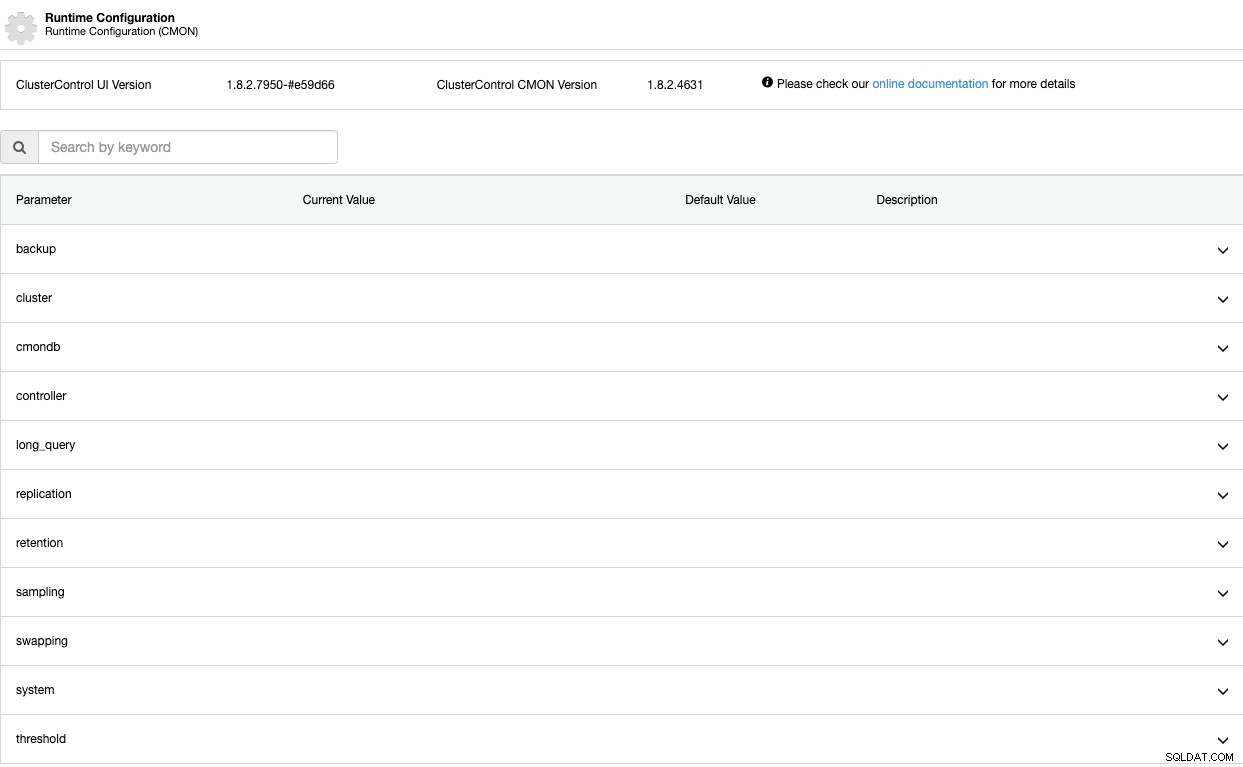
Parametry konfiguracji środowiska wykonawczego
Teraz zobaczmy te parametry jeden po drugim. Pamiętaj, że te parametry zależą od używanej technologii bazy danych, więc najprawdopodobniej nie zobaczysz ich wszystkich jednocześnie w tym samym klastrze.
Kopia zapasowa
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| disable_backup_email | fałsz | To ustawienie kontroluje, czy e-maile są wysyłane, czy nie, jeśli kopia zapasowa została zakończona lub nie powiodła się. |
| użytkownik_kopii zapasowej | użytkownik kopii zapasowej | Nazwa użytkownika konta bazy danych używanego do zarządzania kopiami zapasowymi. |
| backup_create_hash | prawda | Konfiguruje ClusterControl, jeśli ma obliczać md5hash na utworzonych plikach kopii zapasowych i je weryfikować. |
| pitr_retention_hours | 0 | Godziny przechowywania (w celu usunięcia starych dzienników archiwum WAL) dla PITR. |
| netcat_port | 9999,9990-9998 | Lista portów Netcat i zakresów portów używanych do przesyłania strumieniowego kopii zapasowych. Domyślnie jest to „9999,9990-9998”, a port 9999 będzie preferowany, jeśli jest dostępny. |
| katalog kopii zapasowych | /home/user/backups | Domyślny katalog kopii zapasowych, który ma być wstępnie wypełniony w Frontend. |
| backup_subdir | KOPIA ZAPASOWA-%I | Ustaw nazwę podkatalogu kopii zapasowej. Ten ciąg może zawierać standardowe separatory pól „%X”, na przykład „%06I” zostanie zastąpiony numerycznym identyfikatorem kopii zapasowej w formacie obejmującym 6 pól, w którym jako wiodące znaki wypełniające są używane „0”. Oto lista pól aktualnie obsługiwanych przez backend:- B Data i godzina rozpoczęcia tworzenia kopii zapasowej. - H Nazwa hosta kopii zapasowej, hosta, który utworzył kopię zapasową. - i Numeryczny identyfikator klastra. - I Numeryczny identyfikator kopii zapasowej. - J Numeryczny identyfikator zadania, które utworzyło kopię zapasową. - M Metoda tworzenia kopii zapasowej (np. "mysqldump"). - O Nazwa użytkownika, który zainicjował zadanie tworzenia kopii zapasowej. - S Nazwa hosta przechowywania, hosta przechowującego pliki kopii zapasowej. - % Sam znak procentu. Użyj dwóch znaków procentu, "%%" w taki sam sposób, w jaki standardowa funkcja printf() interpretuje go jako jeden znak procenta. |
| backup_retention | 31 | Ustawienie liczby dni przechowywania kopii zapasowych. Kopie zapasowe pasujące do okresu przechowywania są usuwane. |
| backup_cloud_retention | 180 | Ustawienie liczby dni przechowywania kopii zapasowych przesyłanych do chmury. Kopie zapasowe pasujące do okresu przechowywania są usuwane. |
| backup_n_safety_kopie | 1 | Ustawienie liczby wykonanych pełnych kopii zapasowych, które będą przechowywane niezależnie od ich stanu przechowywania. |
Klaster
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| nazwa_klastra | Nazwa klastra ułatwiająca identyfikację. | |
| enable_node_autorecovery | prawda | Ustawienie automatycznego odzyskiwania węzła. |
| enable_cluster_autorecovery | prawda | Jeśli true, ClusterControl wykona automatyczne odzyskiwanie klastra, jeśli false, odzyskiwanie klastra nie zostanie wykonane automatycznie. |
| katalog konfiguracji | /etc/ | Katalog konfiguracji serwera bazy danych. |
| created_by_job | Identyfikator zadania utworzonego w tym klastrze. | |
| ssh_keypath | /home/user/.ssh/id_rsa | Plik klucza SSH używany do połączenia z węzłami. |
| server_selection_try_once | prawda | Opcja identyfikatora URI połączenia MongoDB. Określa, czy wybór serwera powinien być powtarzany w przypadku niepowodzenia, aż do wygaśnięcia limitu czasu wyboru serwera, czy po prostu powrócić z natychmiastowym niepowodzeniem. |
| server_selection_timeout_ms | 30000 | Opcja identyfikatora URI połączenia MongoDB. Definiuje wartość limitu czasu do momentu, gdy mongodriver spróbuje wykonać pomyślną operację wyboru serwera. |
| właściciel | Identyfikator użytkownika ClusterControl właściciela obiektu klastra. | |
| właściciel_grupy | Identyfikator grupy ClusterControl grupy, która jest właścicielem obiektu klastra. | |
| cdt_path | Lokalizacja obiektu klastra w drzewie katalogów ClusterControl. | |
| tagi | / | Zestaw ciągów znaków, które użytkownik może określić. |
| acl | Lista kontroli dostępu jako ciąg znaków kontrolujący dostęp do obiektu klastra. | |
| mongodb_user | administracja | Nazwa użytkownika MongoDB. |
| mongodb_basedir | /usr/ | Baza instalacji MongoDB. |
| mysql_basedir | /usr/ | Baza do instalacji MySQL. |
| katalog skryptu | /usr/bin/ | Katalog skryptów instalacji MySQL. |
| katalog_stagingowy | /home/user/s9s_tmp | Ścieżka pomostowa dla plików tymczasowych. |
| bindir | /usr/bin | Katalog /bin instalacji MySQL. |
| monitorowany_mysql_port | 3306 | Numer portu monitorowanego serwera MySQL. |
| ndb_connectstring | 127.0.0.1:1186 | Ustawienie ciągu połączenia NDB dla klastra MySQL. |
| ndbd_datadir | Katalog danych węzłów NDBD. | |
| mgmd_datadir | Katalog danych węzłów NDB MGMD. | |
| os_user | Nazwa użytkownika SSH używana do uzyskiwania dostępu do węzłów. | |
| użytkownik_repl | cmon_replication | Nazwa użytkownika replikacji. |
| dostawca | Nazwa dostawcy bazy danych używana do wdrożeń. | |
| galera_version | Numer używanej wersji Galera. | |
| wersja_serwera | Używana wersja serwera bazy danych do wdrożeń. | |
| użytkownik_postgresql | administracja | Nazwa użytkownika PostgreSQL. |
| galera_port | 4567 | Port galera używany podczas dodawania węzłów/garbd i tworzenia wsrep_cluster_address. Nie zmieniaj w czasie wykonywania. |
| auto_manage_readonly | prawda | Zezwól ClusterControl na zarządzanie flagą tylko do odczytu zarządzanych serwerów MySQL. |
| node_recovery_lock_file | Określ plik blokady, a jeśli jest obecny w węźle, węzeł nie zostanie odzyskany. Za utworzenie/usunięcie pliku odpowiada administrator. |
Polecenie
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| cmon_db | cmon | Nazwa lokalnej bazy danych ClusterControl. |
| cmondb_hostname | 127.0.0.1 | Lokalna nazwa hosta serwera MySQL bazy danych ClusterControl. |
| mysql_port | 3306 | Lokalny port serwera MySQL bazy danych ClusterControl. |
| użytkownik_cmon | cmon | Nazwa konta dostępu do lokalnej bazy danych ClusterControl. |
Kontroler
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| identyfikator_kontrolera | 5a3a993d-xxxx | Dowolny ciąg identyfikatora tej instancji kontrolera. |
| cmon_hostname | 192.168.xx.xx | Nazwa hosta kontrolera. |
| error_report_dir | /home/user/s9s_tmp | Lokalizacja przechowywania raportów o błędach. |
Long_query
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| long_query_time | 0,5 | Wartość progowa dla powolnego sprawdzania zapytań. |
| query_monitor_alert_long_running_query | prawda | Zgłasza alarm, jeśli zapytanie jest wykonywane dłużej niż query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | fałsz | Zamknij zapytanie, jeśli zapytanie jest wykonywane dłużej niż query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30000 | Wywołuje alarm, jeśli zapytanie jest wykonywane dłużej niż query_monitor_long_running_query_ms. Minimalna wartość to 1000. |
| query_monitor_long_running_query_matching_info | Dopasuj tylko zapytania z 'Info' pasującym tylko do tego wyrażenia regularnego POSIX. Brak wartości domyślnej, dopasuj dowolne informacje. | |
| query_monitor_long_running_query_matching_info_negate | fałsz | Zaneguj wynik query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Dopasuj tylko zapytania z 'Host' pasującym tylko do tego wyrażenia regularnego POSIX. Brak wartości domyślnej, pasuje do dowolnego hosta. | |
| query_monitor_long_running_query_matching_db | Dopasuj tylko zapytania z 'Db' pasującym tylko do tego wyrażenia regularnego POSIX. Brak wartości domyślnej, pasuje do dowolnego Db. | |
| query_monitor_long_running_query_matching_user | Dopasuj tylko zapytania z „Użytkownikiem” pasującym tylko do tego wyrażenia regularnego POSIX. Brak wartości domyślnej, pasuje do dowolnego użytkownika. | |
| query_monitor_long_running_query_matching_user_negate | fałsz | Zanegować wynik query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Zapytanie | Dopasuj tylko zapytania z „Poleceniem” pasującym tylko do tego wyrażenia regularnego POSIX. Domyślnie jest to „Zapytanie”. |
Replikacja
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| max_replication_lag | 10 | Maksymalne dozwolone opóźnienie replikacji w sekundach przed wysłaniem alarmu. |
| replication_stop_on_error | prawda | Kontroluje, czy procedury przełączania awaryjnego/przełączania powinny zakończyć się niepowodzeniem w przypadku napotkania błędów, które mogą spowodować utratę danych. |
| replication_auto_rebuild_slave | fałsz | Jeżeli GWINT SQL zostanie zatrzymany, a kod błędu jest niezerowy, wówczas urządzenie podrzędne zostanie automatycznie odbudowane. |
| replication_failover_blacklist | Lista rozdzielonych przecinkami nazw hostów:par portów. Serwery umieszczone na czarnej liście nie będą brane pod uwagę podczas przełączania awaryjnego. replication_failover_blacklist jest ignorowana, jeśli ustawiono replication_failover_whitelist. | |
| replication_failover_whitelist | Lista rozdzielonych przecinkami nazw hostów:par portów. Tylko serwery z białej listy będą brane pod uwagę podczas przełączania awaryjnego. Jeśli żaden serwer na białej liście nie jest dostępny (podłączony/podłączony), przełączanie awaryjne nie powiedzie się. replication_failover_blacklist jest ignorowana, jeśli ustawiono replication_failover_whitelist. | |
| replication_onfail_failover_script | Ten skrypt jest wykonywany, gdy tylko zostanie wykryte, że konieczne jest przełączenie awaryjne. Jeśli skrypt zwróci wartość niezerową lub nie istnieje, przełączanie awaryjne zostanie przerwane. Do skryptu dostarczane są cztery argumenty i ustawiane, jeśli są znane, w przeciwnym razie są puste:arg1='wszystkie serwery' arg2='nieudane master' arg3='wybrany kandydat', arg4='niewolnicy starego mistrza (kandydaci)' i przekazywane jak this:'nazwa_skryptu arg1 arg2 arg3 arg4' Skrypt musi być dostępny na kontrolerze i wykonywalny. | |
| replication_pre_failover_script | Skrypt ten jest wykonywany przed przejściem awaryjnym, ale po wybraniu kandydata i możliwe jest kontynuowanie procesu przełączania awaryjnego. Jeśli skrypt zwróci wartość niezerową lub nie istnieje, przełączanie awaryjne zostanie przerwane. Do skryptu dostarczane są cztery argumenty i ustawiane, jeśli są znane, w przeciwnym razie są puste:arg1='wszystkie serwery' arg2='nieudane master' arg3='wybrany kandydat', arg4='niewolnicy starego mistrza (kandydaci)' i przekazywane jak this:'nazwa_skryptu arg1 arg2 arg3 arg4' Skrypt musi być dostępny na kontrolerze i wykonywalny. | |
| replication_post_failover_script | Skrypt ten jest wykonywany po wystąpieniu przełączenia awaryjnego (wybrany zostaje nowy master, który działa). Jeśli skrypt zwróci wartość niezerową lub nie istnieje, przełączanie awaryjne zostanie przerwane. Do skryptu dostarczane są cztery argumenty i ustawiane, jeśli są znane, w przeciwnym razie są puste.:arg1='wszystkie serwery' arg2='nieudany master' arg3='wybrany kandydat', arg4='niewolnicy starego mistrza (kandydatów)' i zaliczony tak:'nazwa_skryptu arg1 arg2 arg3 arg4' Skrypt musi być dostępny na kontrolerze i wykonywalny. | |
| replication_post_unsuccessful_failover_script | Ten skrypt jest wykonywany, jeśli próba przełączenia awaryjnego nie powiedzie się. Jeśli skrypt zwróci wartość niezerową lub nie istnieje, przełączanie awaryjne zostanie przerwane. Do skryptu dostarczane są cztery argumenty i ustawiane, jeśli są znane, w przeciwnym razie są puste.:arg1='wszystkie serwery' arg2='nieudany master' arg3='wybrany kandydat', arg4='niewolnicy starego mistrza (kandydatów)' i zaliczony tak:'nazwa_skryptu arg1 arg2 arg3 arg4' Skrypt musi być dostępny na kontrolerze i wykonywalny. |
Przechowywanie
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| ops_report_retention | 31 | Ustawienie liczby dni przechowywania raportów operacyjnych. Raporty pasujące do okresu przechowywania są usuwane. |
Próbkowanie
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| enable_icmp_ping | prawda | Przełącza, czy ClusterControl ma mierzyć czasy pingów ICMP do hosta. |
| host_stats_collection_interval | 30 | Ustawienie interwału gromadzenia danych z hosta (procesora, pamięci itp.). |
| host_stats_window_size | 180 | Ustawianie rozmiaru okna (w sekundach) do sprawdzania statystyk w celu podniesienia/wyczyszczenia alarmów statystyk hosta. |
| db_stats_collection_interval | 30 | Ustawienie interwału zbierania statystyk bazy danych. |
| db_proc_stats_collection_interval | 5 | Ustawienie interwału zbierania statystyk procesu bazy danych. Minimalna dozwolona wartość to 1 sekunda. Wymaga ponownego uruchomienia usługi cmon. |
| lb_stats_collection_interval | 15 | Ustawienie interwału zbierania statystyk modułu równoważenia obciążenia. |
| db_schema_stats_collection_interval | 108000 | Ustawienie interwału monitorowania statystyk schematu. |
| db_deadlock_check_interval | 0 | Jak często sprawdzać zakleszczenia. Określone w sekundach. Wykrywanie zakleszczeń wpłynie na użycie procesora w węzłach bazy danych. |
| log_collection_interval | 600 | Kontroluje interwał między kolekcjami plików dziennika. |
| db_hourly_stats_collection_interval | 5 | Kontroluje liczbę sekund między poszczególnymi próbkami w statystykach zakresu godzinowego. |
| monitorowane_punkty montowania | Lista punktów montowania do monitorowania. | |
| monitor_cpu_temperature | fałsz | Monitoruj temperaturę procesora. |
| log_queries_not_using_indexes | fałsz | Ustaw monitor zapytań tak, aby wykrywał zapytania nie używające indeksów. |
| query_sample_interval | 1 | Kontroluje interwał monitorowania zapytań w sekundach, -1 oznacza brak monitorowania zapytań. |
| query_monitor_auto_purge_ps | fałsz | Jeśli ta opcja jest włączona, tabela P_S events_statements_summary_by_digest będzie automatycznie czyszczona (TRUNCATE TABLE) co godzinę. |
| schema_change_detection_address | Sprawdzenia zostaną wykonane (przy użyciu SHOW TABLES/SHOW CREATE TABLE) w celu ustalenia, czy schemat uległ zmianie. Kontrole są wykonywane pod podanym adresem i mają format NAZWA HOSTA:PORT. Należy również ustawić schema_change_detection_databases. Zostanie utworzona różnica zmienionej tabeli. | |
| schema_change_detection_bazy danych | Lista oddzielonych przecinkami baz danych do monitorowania pod kątem zmian w schemacie. Jeśli jest pusty, nie są wykonywane żadne kontrole. | |
| schema_change_detection_pause_time_ms | 0 | Czas pauzy w ms pomiędzy poszczególnymi funkcjami SHOW CREATE TABLE. Czas przerwy wpłynie na czas trwania procesu wykrywania. |
| enable_is_queries | prawda | Określa, czy zapytania do schematu information_schema będą wykonywane, czy nie. Zapytania do schematu informacji mogą nie być odpowiednie, gdy istnieje wiele obiektów schematu (100 baz danych, setki tabel w każdej bazie danych, wyzwalacze, użytkownicy, zdarzenia, sprocs). Jeśli wyłączone, zapytanie, które zostanie wykonane, zostanie zarejestrowane, aby można było określić, czy zapytanie jest odpowiednie w Twoim środowisku. |
Zamiana
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| swap_warning | 20 | Próg alarmu ostrzegawczego dla użycia wymiany. |
| swap_critical | 90 | Krytyczny próg alarmowy dla użycia wymiany. |
| swap_inout_period | 0 | Interwał dla alarmów wymiany we/wy (<=0 wyłącza). |
| swap_inout_warning | 10240 | Liczba stron zamienionych we/wy w określonym przedziale czasu (swap_inout_period, domyślnie 10 minut) dla ostrzeżenia. |
| swap_inout_critical | 102400 | Liczba stron zamienionych we/wy w określonym przedziale czasu (swap_inout_period, domyślnie 10 minut) na krytyczne. |
System
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | Ścieżka pliku konfiguracyjnego. Ta wartość konfiguracji jest tylko do odczytu. |
| os | debian/redhat | Typ systemu operacyjnego. Możliwe wartości to 'debian' lub 'redhat'. |
| libssh_timeout | 30 | Wartość limitu czasu sieci dla połączeń SSH. |
| sudo | sudo -n 2>/dev/null | Polecenie używane do uzyskania uprawnień superużytkownika. |
| ssh_port | 22 | Port dla połączeń SSH z węzłami. |
| lokalna_nazwa_repo | Nazwy lokalnych repozytorium używane do wdrażania klastra. | |
| frontend_url | URL wysyłany w wiadomościach e-mail w celu przekierowania odbiorcy do interfejsu sieciowego ClusterControl. | |
| oczyść | 7 | Jak długo ClusterControl ma przechowywać dane. Mierzone w dniach, zadania, komunikaty o zadaniach, alarmy, zebrane dzienniki, raporty operacyjne, informacje o przyroście bazy danych starsze niż te zostaną usunięte. |
| os_user_home | /home/użytkownik | Katalog HOME użytkownika używanego w węzłach. |
| cmon_mail_sender | Użyty nadawca e-maili dla wysłanych e-maili. | |
| katalog_wtyczek | Ścieżka katalogu wtyczek. | |
| use_internal_repos | fałsz | Ustawienie wyłączające konfigurację repozytorium innej firmy. |
| cmon_use_mail | fałsz | Ustawienie używania polecenia „poczta” do wysyłania e-maili. |
| enable_html_emails | prawda | Włącza wysyłanie wiadomości e-mail w formacie HTML. |
| send_clear_alarm | prawda | Przełącza wysyłanie wiadomości e-mail w przypadku usunięcia alarmów klastra. |
| oprogramowanie_pakietowe | To jest lokalizacja przechowywania pakietów oprogramowania, tj. wszystkie niezbędne pliki do pomyślnej instalacji węzła, jeśli nie ma dostępnego repozytorium yum/apt, muszą być tutaj umieszczone. Dotyczy głównie MySQL Cluster lub starszych instalacji Codership/Galera. |
Próg
| Nazwa | Wartość domyślna | Opis |
|---|---|---|
| ram_warning | 80 | Próg alarmu ostrzegawczego dla użycia pamięci RAM. |
| ram_critical | 90 | Krytyczny próg alarmowy użycia pamięci RAM. |
| diskspace_warning | 80 | Próg alarmu ostrzegawczego dla użycia dysku. |
| diskspace_critical | 90 | Krytyczny próg alarmowy użycia dysku. |
| cpu_warning | 80 | Próg alarmu ostrzegawczego dla użycia procesora. |
| cpu_critical | 90 | Krytyczny próg alarmowy dotyczący użycia procesora. |
| cpu_steal_warning | 10 | Próg alarmu ostrzeżenia o kradzieży procesora. |
| cpu_steal_critical | 20 | Krytyczny próg alarmu dla kradzieży procesora. |
| cpu_iowait_warning | 50 | Próg alarmu ostrzegawczego dla CPU IO Wait. |
| cpu_iowait_critical | 60 | Krytyczny próg alarmu dla CPU IO Wait. |
| slow_ssh_warning | 6 | Alarm ostrzegawczy zostanie podniesiony, jeśli nawiązanie połączenia SSH zajmie więcej niż określony czas (sekundy). |
| slow_ssh_critical | 12 | Alarm krytyczny zostanie wywołany, jeśli konfiguracja połączenia SSH zajmie więcej czasu niż określony (s). |
Wnioski
Jak widać, istnieje wiele parametrów, które należy zmienić, jeśli trzeba dostosować ClusterControl do obciążenia pracą lub działalności. Przeglądanie wszystkich wartości i ich odpowiednia zmiana może być czasochłonnym zadaniem, ale pod koniec dnia zaoszczędzisz czas, ponieważ możesz w pełni wykorzystać wszystkie funkcje ClusterControl.



