Jednym z największych problemów związanych z obsługą baz danych i zarządzaniem nimi jest złożoność danych i rozmiaru. Często organizacje zastanawiają się, jak radzić sobie ze wzrostem i zarządzać wpływem na wzrost, ponieważ zarządzanie bazą danych zawodzi. Złożoność wiąże się z obawami, które nie zostały początkowo rozwiązane i nie zostały zauważone lub mogą zostać przeoczone, ponieważ obecnie używana technologia powinna być w stanie sama sobie poradzić. Zarządzanie złożoną i dużą bazą danych należy odpowiednio zaplanować, zwłaszcza gdy oczekuje się, że rodzaj danych, którymi zarządzasz lub którymi się zajmujesz, masowo wzrosnąć, albo w sposób oczekiwany, albo w nieprzewidywalny sposób. Głównym celem planowania jest uniknięcie niechcianych katastrof, a raczej nie wpadaj w dym! W tym blogu omówimy, jak efektywnie zarządzać dużymi bazami danych.
Rozmiar danych ma znaczenie
Rozmiar bazy danych ma znaczenie, ponieważ ma wpływ na wydajność i metodologię zarządzania. Sposób przetwarzania i przechowywania danych wpłynie na sposób zarządzania bazą danych, co dotyczy zarówno danych przesyłanych, jak i spoczynkowych. W wielu dużych organizacjach dane są złotem, a ich wzrost może spowodować drastyczną zmianę procesu. Dlatego ważne jest, aby mieć wcześniejsze plany obsługi rosnących danych w bazie danych.
Z mojego doświadczenia w pracy z bazami danych widziałem, jak klienci mają problemy z karami za wydajność i zarządzaniem ekstremalnym przyrostem danych. Pojawiają się pytania, czy normalizować tabele, czy denormalizować tabele.
Normalizacja tabel
Normalizacja tabel zapewnia integralność danych, zmniejsza nadmiarowość i ułatwia organizowanie danych w bardziej efektywny sposób zarządzania, analizowania i wyodrębniania. Praca ze znormalizowanymi tabelami zapewnia wydajność, zwłaszcza podczas analizowania przepływu danych i pobierania danych za pomocą instrukcji SQL lub pracy z językami programowania, takimi jak C/C++, Java, Go, Ruby, PHP lub Python z interfejsami za pomocą łączników MySQL.
Chociaż problemy ze znormalizowanymi tabelami powodują spadek wydajności i mogą spowolnić zapytania z powodu serii złączeń podczas pobierania danych. Podczas gdy zdenormalizowane tabele, wszystko, co należy wziąć pod uwagę podczas optymalizacji, opiera się na indeksie lub kluczu podstawowym do przechowywania danych w buforze w celu szybszego wyszukiwania niż wykonywanie wyszukiwania na wielu dyskach. Zdenormalizowane tabele nie wymagają łączeń, ale poświęcają integralność danych, a rozmiar bazy danych staje się coraz większy.
Gdy baza danych jest duża, rozważ posiadanie języka DDL (Data Definition Language) dla tabeli bazy danych w MySQL/MariaDB. Dodanie klucza podstawowego lub unikatowego do tabeli wymaga przebudowy tabeli. Zmiana typu danych kolumny wymaga również przebudowania tabeli, ponieważ stosowanym algorytmem jest tylko ALGORITHM=COPY.
Jeśli robisz to w swoim środowisku produkcyjnym, może to być trudne. Podwój wyzwanie, jeśli Twój stół jest ogromny. Wyobraź sobie milion lub miliard liczb wierszy. Nie można zastosować instrukcji ALTER TABLE bezpośrednio do tabeli. Może to zablokować cały ruch przychodzący, który będzie musiał uzyskać dostęp do tabeli, w której aktualnie stosujesz DDL. Można to jednak złagodzić za pomocą zmiany schematu pt-online lub wielkiego ducha. Niemniej jednak wymaga monitorowania i konserwacji podczas wykonywania procesu DDL.
Sharding i partycjonowanie
Dzięki shardingowi i partycjonowaniu pomaga segregować lub segmentować dane zgodnie z ich logiczną tożsamością. Na przykład, segregując według daty, porządku alfabetycznego, kraju, stanu lub klucza podstawowego na podstawie podanego zakresu. Pomaga to w zarządzaniu rozmiarem bazy danych. Utrzymuj rozmiar bazy danych do limitu, który jest możliwy do zarządzania dla Twojej organizacji i zespołu. W razie potrzeby łatwe do skalowania lub łatwe w zarządzaniu, zwłaszcza w przypadku katastrofy.
Kiedy mówimy do zarządzania, weź pod uwagę również zasoby pojemności serwera, a także zespół inżynierów. Nie możesz pracować z dużymi i dużymi danymi z kilkoma inżynierami. Praca z dużymi zbiorami danych, takimi jak 1000 baz danych z dużą liczbą zestawów danych, wymaga ogromnego czasu. Umiejętności i wiedza są koniecznością. Jeśli koszt jest problemem, jest to czas, w którym możesz skorzystać z usług stron trzecich, które oferują usługi zarządzane lub płatne konsultacje lub wsparcie dla wszelkich takich prac inżynieryjnych.
Zestawy znaków i sortowanie
Zestawy znaków i sortowanie wpływają na przechowywanie danych i wydajność, zwłaszcza w przypadku danego zestawu znaków i wybranych sortowań. Każdy zestaw znaków i zestawienia mają swój cel i wymagają w większości różnych długości. Jeśli masz tabele wymagające innych zestawów znaków i sortowania ze względu na kodowanie znaków, dane, które mają być przechowywane i przetwarzane dla bazy danych i tabel, a nawet z kolumnami.
Ma to wpływ na efektywne zarządzanie bazą danych. Wpływa na przechowywanie danych, a także wydajność, jak wspomniano wcześniej. Jeśli znasz rodzaje znaków, które mają być przetwarzane przez twoją aplikację, zwróć uwagę na zestaw znaków i sortowanie, które mają być używane. Zestawy znaków typu ŁACIŃSKIEGO wystarczą głównie do przechowywania i przetwarzania znaków alfanumerycznych.
Jeśli jest to nieuniknione, dzielenie na fragmenty i partycjonowanie pomaga przynajmniej złagodzić i ograniczyć dane, aby uniknąć nadmiernej ilości danych na serwerze bazy danych. Zarządzanie bardzo dużymi danymi na jednym serwerze bazy danych może wpłynąć na wydajność, szczególnie w przypadku tworzenia kopii zapasowych, awarii i odzyskiwania lub odzyskiwania danych, a także w przypadku uszkodzenia lub utraty danych.
Złożoność bazy danych wpływa na wydajność
Duża i złożona baza danych ma tendencję do obniżania wydajności. Złożona oznacza w tym przypadku, że zawartość Twojej bazy danych składa się z równań matematycznych, współrzędnych lub zapisów liczbowych i finansowych. Teraz pomieszaj te rekordy z zapytaniami, które agresywnie używają funkcji matematycznych natywnych dla swojej bazy danych. Spójrz na przykładowe zapytanie SQL (zgodne z MySQL/MariaDB) poniżej,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Rozważ, że to zapytanie jest stosowane do tabeli liczącej od miliona wierszy. Istnieje duże prawdopodobieństwo, że może to spowodować zatrzymanie serwera, co może wymagać dużych zasobów, powodując zagrożenie dla stabilności klastra produkcyjnej bazy danych. Zaangażowane kolumny są zwykle indeksowane w celu optymalizacji i zwiększenia wydajności tego zapytania. Jednak dodanie indeksów do kolumn, do których istnieją odwołania, w celu uzyskania optymalnej wydajności, nie gwarantuje wydajności zarządzania dużymi bazami danych.
Podczas obsługi złożoności, bardziej efektywnym sposobem jest unikanie rygorystycznego stosowania złożonych równań matematycznych i agresywnego korzystania z tej wbudowanej złożonej zdolności obliczeniowej. Może to być obsługiwane i transportowane za pomocą złożonych obliczeń przy użyciu języków programowania zaplecza zamiast korzystania z bazy danych. Jeśli masz złożone obliczenia, to dlaczego nie przechowywać tych równań w bazie danych, pobierać zapytań, organizować je w sposób łatwiejszy do analizy lub debugowania w razie potrzeby.
Czy używasz odpowiedniego silnika bazy danych?
Struktura danych wpływa na wydajność serwera bazy danych w oparciu o kombinację podanego zapytania i rekordów, które są odczytywane lub pobierane z tabeli. Silniki baz danych w MySQL/MariaDB obsługują InnoDB i MyISAM, które używają B-Trees, podczas gdy silniki baz danych NDB lub Memory używają Hash Mapping. Te struktury danych mają swoją notację asymptotyczną, która wyraża wydajność algorytmów wykorzystywanych przez te struktury danych. W informatyce nazywamy je notacją Big O, która opisuje wydajność lub złożoność algorytmu. Biorąc pod uwagę, że InnoDB i MyISAM używają B-Trees, do wyszukiwania używa O(log n). Natomiast Hash Tables lub Hash Maps używają O(n). Obydwa dzielą przeciętny i najgorszy przypadek jego działania z jego zapisem.
Wracając do konkretnego silnika, biorąc pod uwagę strukturę danych silnika, zapytanie, które ma być zastosowane w oparciu o docelowe dane, które mają zostać pobrane, oczywiście wpływa na wydajność serwera bazy danych. Tabele haszujące nie mogą wyszukiwać zakresów, podczas gdy B-Trees jest bardzo wydajne w tego typu wyszukiwaniach, a także może obsługiwać duże ilości danych.
Korzystając z odpowiedniego silnika dla przechowywanych danych, musisz określić, jakiego typu zapytania stosujesz dla tych konkretnych przechowywanych danych. Jaki rodzaj logiki należy sformułować w tych danych, gdy przekształci się ona w logikę biznesową.
Praca z tysiącami lub tysiącami baz danych, użycie odpowiedniego silnika w połączeniu zapytań i danych, które chcesz pobrać i przechowywać, zapewni dobrą wydajność. Biorąc pod uwagę, że wstępnie określiłeś i przeanalizowałeś swoje wymagania pod kątem odpowiedniego środowiska bazy danych.
Właściwe narzędzia do zarządzania dużymi bazami danych
Zarządzanie bardzo dużą bazą danych bez solidnej platformy, na której można polegać, jest bardzo trudne i trudne. Nawet z dobrymi i wykwalifikowanymi inżynierami baz danych, technicznie używany serwer bazy danych jest podatny na błędy ludzkie. Jeden błąd jakichkolwiek zmian parametrów i zmiennych konfiguracyjnych może spowodować drastyczną zmianę powodującą obniżenie wydajności serwera.
Wykonywanie kopii zapasowej w bardzo dużej bazie danych może być czasami trudne. Zdarzają się sytuacje, w których tworzenie kopii zapasowej może się nie powieść z dziwnych powodów. Zwykle zapytania, które mogą spowodować zatrzymanie serwera, na którym działa kopia zapasowa, powodują niepowodzenie. W przeciwnym razie musisz zbadać przyczynę.
Korzystanie z automatyzacji, takiej jak Chef, Puppet, Ansible, Terraform lub SaltStack, może być używane jako IaC, aby zapewnić szybsze wykonywanie zadań. Podczas korzystania z innych narzędzi innych firm, aby pomóc Ci w monitorowaniu i dostarczaniu wysokiej jakości obrazów wykresów. Systemy powiadamiania o alarmach i alarmach są również bardzo ważne, aby powiadamiać Cię o problemach, które mogą wystąpić, od poziomu ostrzeżenia do stanu krytycznego. W takich sytuacjach ClusterControl jest bardzo przydatny w takiej sytuacji.
ClusterControl oferuje łatwość zarządzania dużą liczbą baz danych, a nawet środowisk typu sharded. Został przetestowany i zainstalowany tysiąc razy i działał w produkcjach dostarczających alarmy i powiadomienia dla administratorów baz danych, inżynierów lub DevOps obsługujących środowisko bazy danych. Począwszy od etapu lub rozwoju, kontroli jakości, po środowisko produkcyjne.
ClusterControl może również wykonać kopię zapasową i przywrócić. Nawet w przypadku dużych baz danych może być wydajny i łatwy w zarządzaniu, ponieważ interfejs użytkownika zapewnia planowanie, a także ma opcje przesyłania go do chmury (AWS, Google Cloud i Azure).
Dostępna jest również weryfikacja kopii zapasowej i wiele opcji, takich jak szyfrowanie i kompresja. Zobacz na przykład zrzut ekranu poniżej (tworzenie kopii zapasowej dla MySQL za pomocą Xtrabackup):
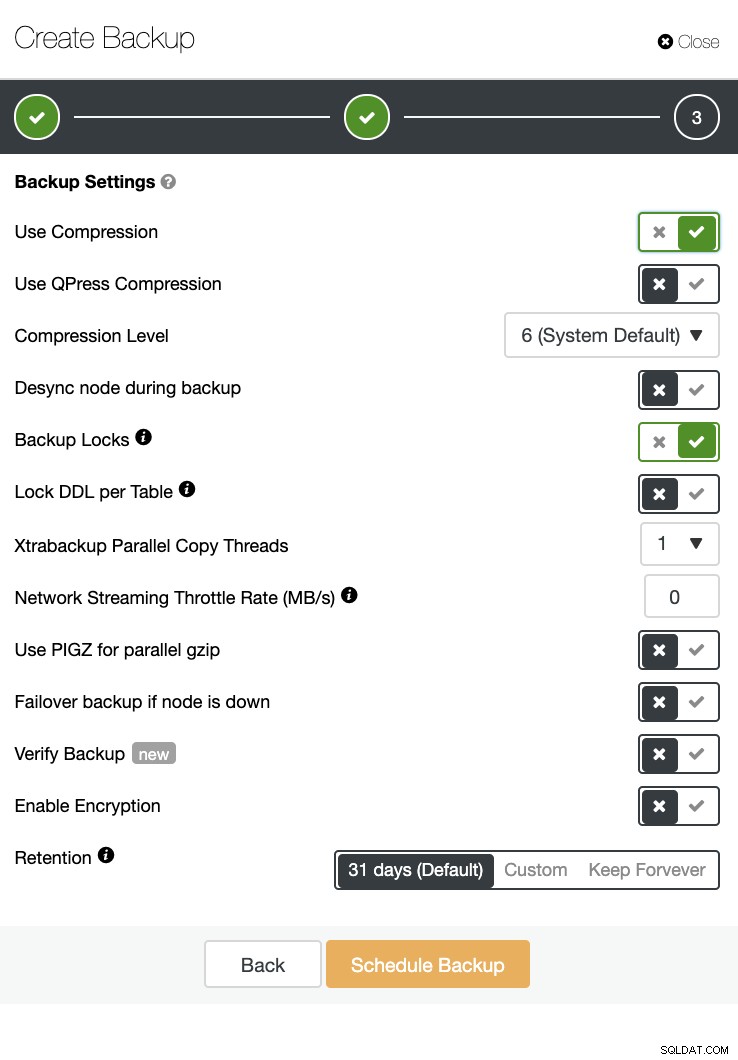
Wnioski
Zarządzanie dużymi bazami danych, takimi jak tysiąc lub więcej, można wydajnie wykonywać, ale należy to wcześniej określić i przygotować. Korzystanie z odpowiednich narzędzi, takich jak automatyzacja, a nawet subskrypcja usług zarządzanych, bardzo pomaga. Chociaż wiąże się to z kosztami, zwrot usługi i budżet, który należy przeznaczyć na pozyskanie wykwalifikowanych inżynierów, można zmniejszyć, o ile dostępne są odpowiednie narzędzia.



