W ostatnich pięciu postach z serii blogów omówiliśmy wdrażanie klastrów/replikacji (MySQL / Galera, MySQL Replication, MongoDB i PostgreSQL), zarządzanie i monitorowanie istniejących baz danych i klastrów, monitorowanie wydajności i kondycji, jak dokonać konfiguracji wysoce dostępne dzięki HAProxy i MaxScale, a w ostatnim poście, jak przygotować się na katastrofy, planując tworzenie kopii zapasowych.
Od wersji ClusterControl 1.2.11 wprowadziliśmy znaczne ulepszenia w menedżerze konfiguracji bazy danych. Nowa wersja umożliwia zmianę parametrów na wielu hostach bazy danych w tym samym czasie i, jeśli to możliwe, zmianę ich wartości w czasie wykonywania.
Opisaliśmy nowe zarządzanie konfiguracją MySQL w poście na blogu Tips &Tricks, ale ten post będzie bardziej szczegółowy i obejmie zarządzanie konfiguracją w ramach ClusterControl dla MySQL, PostgreSQL i MongoDB.
Zarządzanie konfiguracją ClusterControl
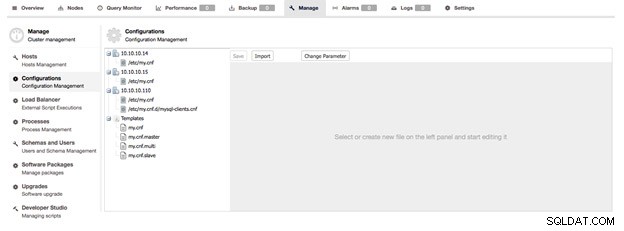
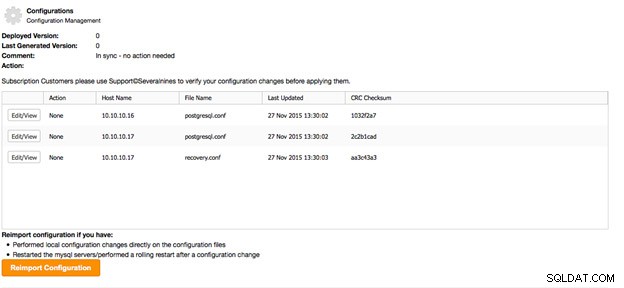
Interfejs zarządzania konfiguracją można znaleźć w sekcji Zarządzaj> Konfiguracje. Z tego miejsca możesz przeglądać lub zmieniać konfiguracje węzłów bazy danych i innych narzędzi zarządzanych przez ClusterControl. ClusterControl zaimportuje najnowszą konfigurację ze wszystkich węzłów i zastąpi poprzednie wykonane kopie. Obecnie nie są przechowywane żadne dane historyczne.
Jeśli wolisz ręcznie edytować pliki konfiguracyjne bezpośrednio w węzłach, możesz ponownie zaimportować zmienioną konfigurację, naciskając przycisk Importuj.
I wreszcie:możesz tworzyć lub edytować szablony konfiguracji. Te szablony są używane przy każdym wdrażaniu nowych węzłów w klastrze. Oczywiście wszelkie zmiany wprowadzone w szablonach nie zostaną wstecznie zastosowane do już wdrożonych węzłów, które zostały utworzone przy użyciu tych szablonów.
Zarządzanie konfiguracją MySQL
Jak wcześniej wspomniano, zarządzanie konfiguracją MySQL zostało całkowicie zmienione w ClusterControl 1.2.11. Interfejs jest teraz bardziej intuicyjny. Podczas zmiany parametrów ClusterControl sprawdza, czy parametr rzeczywiście istnieje. Gwarantuje to, że Twoja konfiguracja nie odmówi uruchomienia MySQL z powodu nieistniejących parametrów.
W Zarządzaj -> Konfiguracje znajdziesz przegląd wszystkich plików konfiguracyjnych używanych w wybranym klastrze, w tym węzłów równoważenia obciążenia.
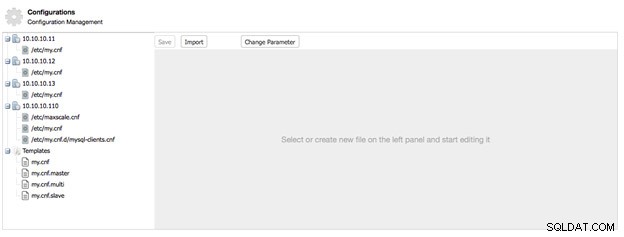
Używamy struktury drzewa, aby łatwo przeglądać hosty i ich odpowiednie pliki konfiguracyjne. U dołu drzewa znajdziesz szablony konfiguracji dostępne dla tego klastra.
Zmiana parametrów
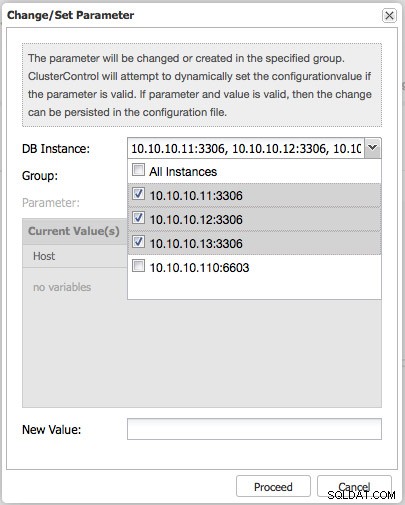
Załóżmy, że musimy zmienić prosty parametr, taki jak maksymalna liczba dozwolonych połączeń (max_connections), możemy po prostu zmienić ten parametr w czasie wykonywania.
Najpierw wybierz hosty, na których chcesz zastosować tę zmianę.
Następnie wybierz sekcję, którą chcesz zmienić. W większości przypadków będziesz chciał zmienić sekcję MYSQLD. Jeśli chcesz zmienić domyślny zestaw znaków dla MySQL, musisz to zmienić zarówno w sekcji MYSQLD, jak i klienta.
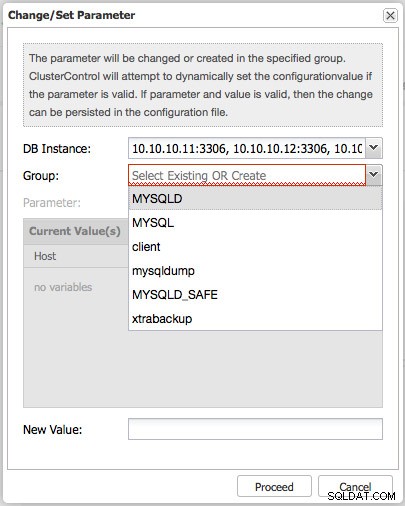
W razie potrzeby możesz również utworzyć nową sekcję, wpisując po prostu nazwę nowej sekcji. Spowoduje to utworzenie nowej sekcji w my.cnf.
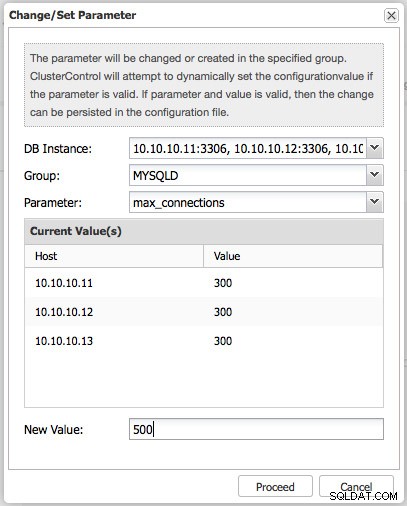
Gdy zmienimy parametr i ustawimy jego nową wartość, naciskając „Proceed”, ClusterControl sprawdzi, czy parametr istnieje dla tej wersji MySQL. Ma to na celu zapobieganie blokowaniu przez nieistniejące parametry inicjalizacji MySQL przy następnym ponownym uruchomieniu.
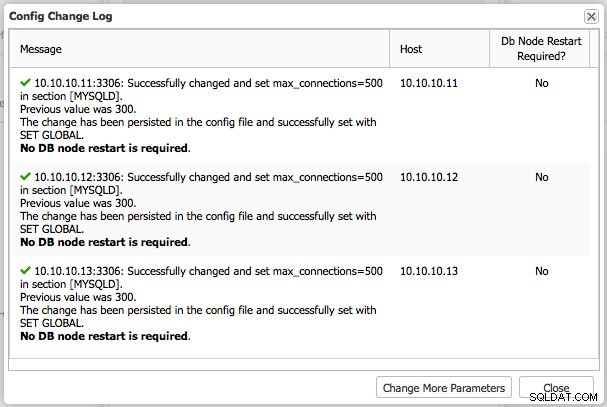
Gdy naciśniemy „proceed” w celu zmiany max_connections, otrzymamy potwierdzenie, że została ona zastosowana do konfiguracji i ustawiona w czasie wykonywania za pomocą SET GLOBAL. Ponowne uruchomienie nie jest wymagane, ponieważ max_connections to parametr, który możemy zmienić w czasie wykonywania.
Załóżmy teraz, że chcemy zmienić rozmiar puli buforów, wymagałoby to ponownego uruchomienia MySQL, zanim zacznie obowiązywać:
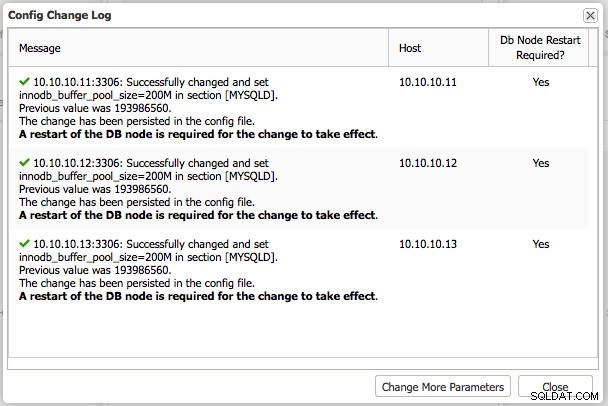
Zgodnie z oczekiwaniami wartość została zmieniona w pliku konfiguracyjnym, ale wymagane jest ponowne uruchomienie. Możesz to zrobić, logując się ręcznie do hosta i ponownie uruchamiając proces MySQL. Innym sposobem na zrobienie tego z ClusterControl jest użycie pulpitu nawigacyjnego Nodes.
Ponowne uruchamianie węzłów w klastrze Galera
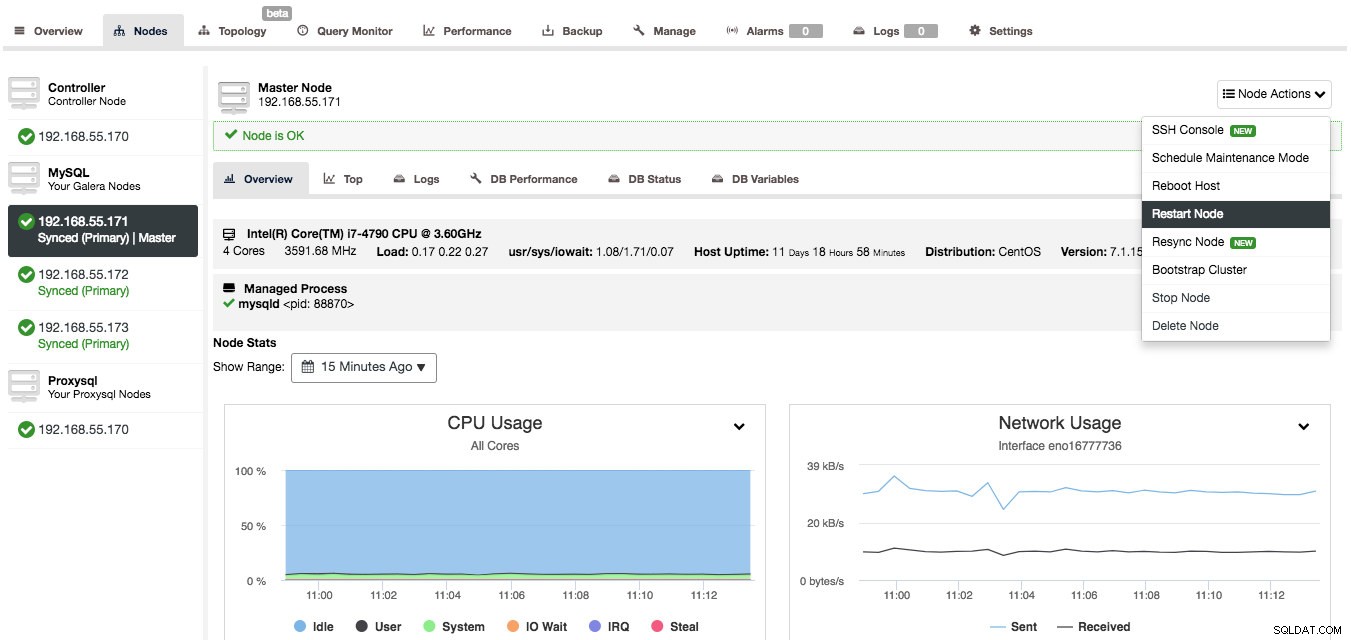
Możesz wykonać ponowne uruchomienie każdego węzła, wybierając „Uruchom ponownie węzeł” i naciskając przycisk „Kontynuuj”.
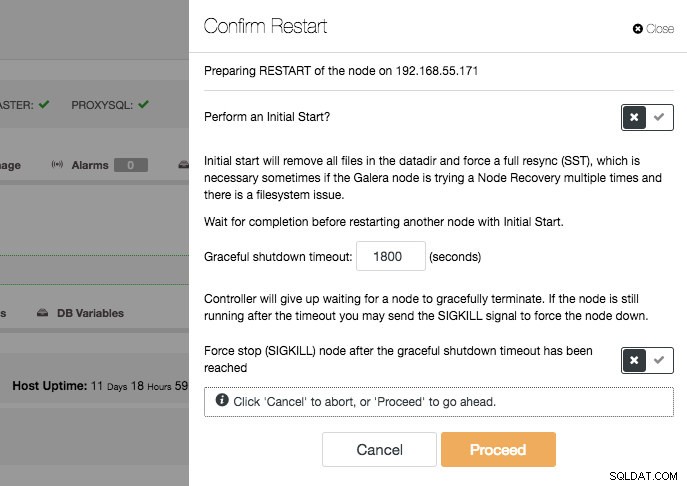
Po wybraniu opcji „Początkowy start” w węźle Galera, ClusterControl opróżni katalog danych MySQL i wymusi wykonanie w ten sposób pełnej kopii. Nie jest to oczywiście konieczne do zmiany konfiguracji. Upewnij się, że pole wyboru „początkowe” nie jest zaznaczone w oknie dialogowym potwierdzenia. Spowoduje to zatrzymanie i uruchomienie MySQL na hoście, ale w zależności od obciążenia i rozmiaru puli buforów może to chwilę potrwać, ponieważ MySQL zacznie opróżniać brudne strony z puli buforów InnoDB na dysk. Są to strony, które zostały zmodyfikowane w pamięci, ale nie na dysku.
Ponowne uruchamianie węzłów w topologii MySQL Master-Slave
W przypadku topologii typu master-slave MySQL nie można po prostu restartować węzeł po węźle. O ile przestój urządzenia nadrzędnego nie jest akceptowalny, będziesz musiał najpierw zastosować zmiany w konfiguracji do urządzeń podrzędnych, a następnie awansować urządzenie podrzędne na nowego urządzenia nadrzędnego.
Możesz przejść przez urządzenia podrzędne jeden po drugim i wykonać na nich „Restart Node”.
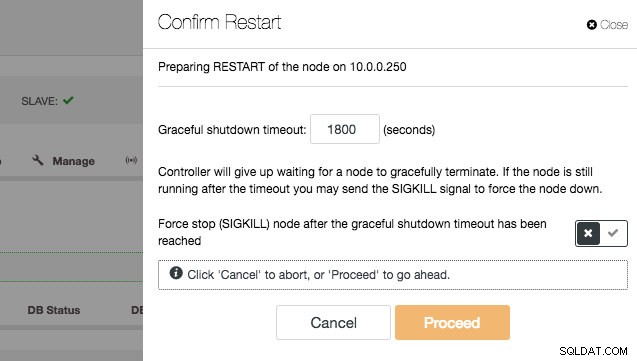
Po zastosowaniu zmian we wszystkich jednostkach podrzędnych, zmień podrzędnego na nowego nadrzędnego:
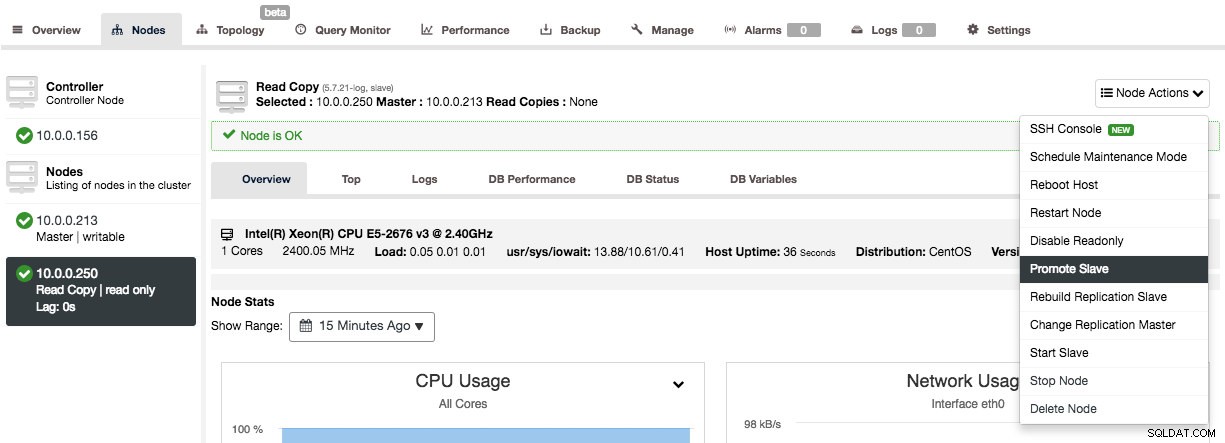
Po tym, jak slave stanie się nowym masterem, możesz wyłączyć i ponownie uruchomić stary węzeł master, aby zastosować zmianę.
Importowanie konfiguracji
Teraz, gdy zastosowaliśmy zmianę bezpośrednio w bazie danych, a także w pliku konfiguracyjnym, po kolejnym zaimportowaniu konfiguracji zmiana zostanie odzwierciedlona w konfiguracji przechowywanej w ClusterControl. Jeśli jesteś mniej cierpliwy, możesz zaplanować natychmiastowy import konfiguracji, naciskając przycisk „Importuj”.
Zarządzanie konfiguracją PostgreSQL
W przypadku PostgreSQL zarządzanie konfiguracją działa nieco inaczej niż zarządzanie konfiguracją MySQL. Ogólnie rzecz biorąc, masz tutaj tę samą funkcjonalność:zmiana konfiguracji, importowanie konfiguracji dla wszystkich węzłów i definiowanie/zmiana szablonów.
Różnica polega na tym, że możesz natychmiast zmienić cały plik konfiguracyjny i zapisać tę konfigurację z powrotem w węźle bazy danych.
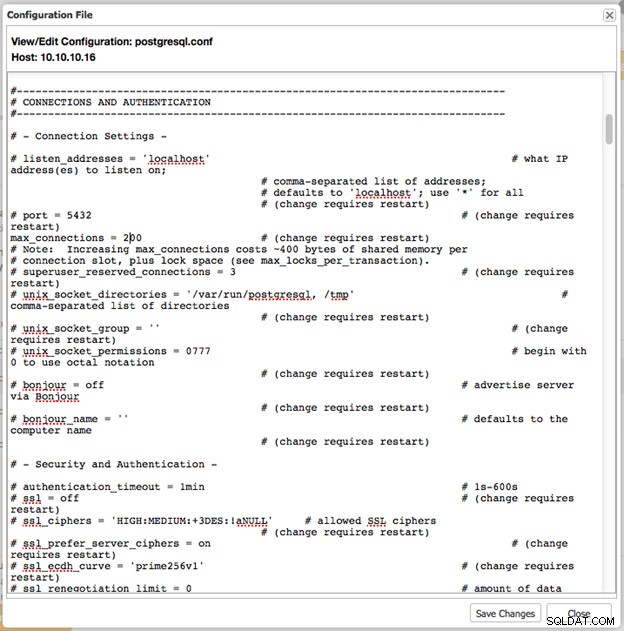
Jeśli wprowadzone zmiany wymagają ponownego uruchomienia, pojawi się przycisk „Uruchom ponownie”, który umożliwi ponowne uruchomienie węzła w celu zastosowania zmian.
Zarządzanie konfiguracją MongoDB
Zarządzanie konfiguracją MongoDB działa podobnie do zarządzania konfiguracją MySQL:możesz zmieniać konfigurację, importować konfiguracje dla wszystkich węzłów, zmieniać parametry i modyfikować szablony.
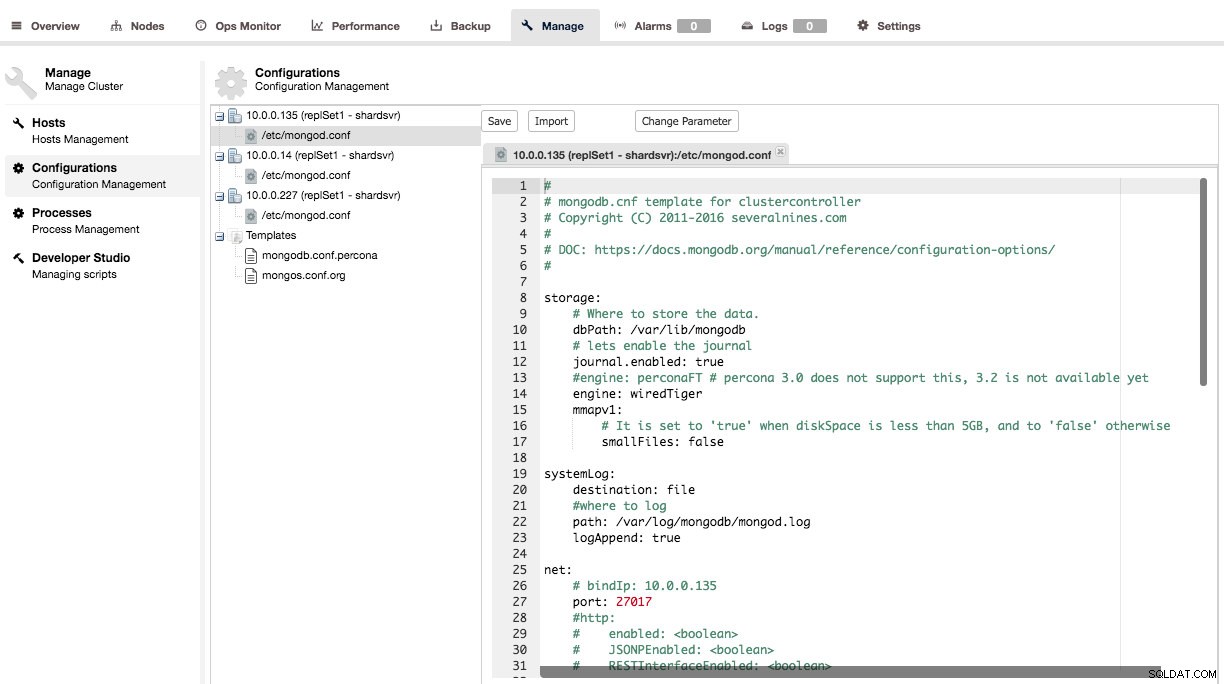
Zmiana konfiguracji jest dość prosta, za pomocą okna dialogowego Zmień parametr (jak opisano w sekcji „Zmiana parametrów”::
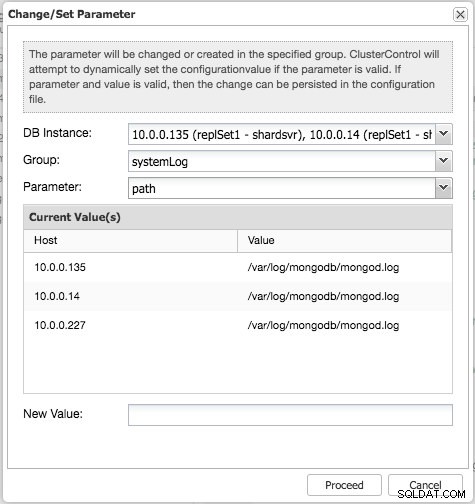
Po zmianie możesz zobaczyć działanie po modyfikacji proponowane przez ClusterControl w oknie dialogowym „Config Change Log”:
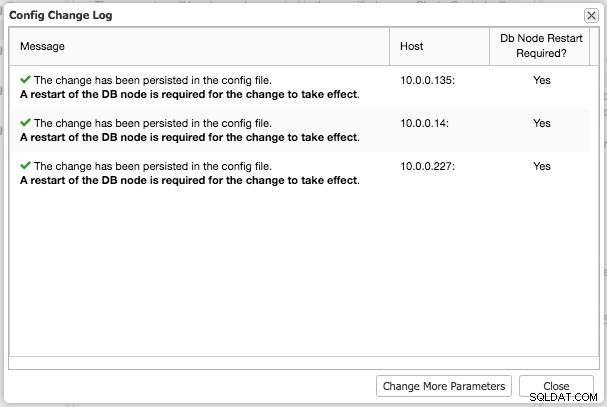
Następnie możesz przystąpić do ponownego uruchamiania odpowiednich węzłów MongoDB, po jednym węźle na raz, aby załadować zmiany.
Ostateczne myśli
W tym poście na blogu dowiedzieliśmy się, jak zarządzać, zmieniać i szablonować konfiguracje w ClusterControl. Zmiana szablonów może zaoszczędzić dużo czasu, gdy wdrożyłeś tylko jeden węzeł w swojej topologii. Ponieważ szablon będzie używany dla nowych węzłów, zaoszczędzi ci to późniejszej zmiany wszystkich konfiguracji. Jednak w przypadku węzłów opartych na MySQL i MongoDB zmiana konfiguracji na wszystkich węzłach stała się trywialna dzięki nowemu interfejsowi zarządzania konfiguracją.
Przypominamy, że ostatnio omawialiśmy w tej samej serii wdrażanie klastrów/replikacji (MySQL / Galera, MySQL Replication, MongoDB i PostgreSQL), zarządzanie i monitorowanie istniejących baz danych i klastrów, monitorowanie wydajności i kondycji, jak sprawić, by konfiguracja była wysoce dostępne przez HAProxy i MaxScale oraz w ostatnim poście, jak przygotować się na katastrofy, planując tworzenie kopii zapasowych.



