Raportowanie operacyjne zapewnia wsparcie w codziennym monitorowaniu i kontroli działalności przedsiębiorstwa. Celem tego artykułu na blogu jest zapoznanie się z raportami operacyjnymi dostępnymi w ClusterControl.
Raporty operacyjne ClusterControl dostarczają informacji o stanie infrastruktury bazy danych, które można wykorzystać do audytu środowiska lub w ramach wsparcia operacyjnego. Raporty te składają się z różnych kontroli i dotyczą różnych codziennych zadań DBA. Ideą raportowania operacyjnego ClusterControl jest umieszczenie wszystkich najbardziej istotnych danych w jednym dokumencie, który można szybko przeanalizować w celu uzyskania jasnego zrozumienia stanu baz danych i ich procesów.
Dzięki ClusterControl możesz zaplanować raporty w różnych środowiskach, takie jak „Codzienny raport systemowy”, „Raport aktualizacji pakietu”, „Raport zmiany schematu”, a także „Kopie zapasowe” i „Dostępność”. Raporty te pomogą Ci zapewnić bezpieczeństwo i sprawność środowiska. Zobaczysz również zalecenia, jak naprawić luki. Raporty mogą być adresowane do SysOps, DevOps, a nawet menedżerów, którzy chcieliby otrzymywać regularne aktualizacje statusu dotyczące kondycji danego systemu.
Dlaczego potrzebuję raportów operacyjnych?
Być może masz już doskonałe narzędzie do monitorowania ze wszystkimi możliwymi metrykami/wykresami i prawdopodobnie skonfigurowałeś również alerty oparte na metrykach i progach (niektórzy mają nawet automatycznych doradców, którzy dostarczają im rekomendacje lub automatycznie naprawiają rzeczy). system jest ważny; niemniej jednak musisz być w stanie przetworzyć wiele informacji. Zintegrowane narzędzia, takie jak ClusterControl, mają tę zaletę, że wszystkie różne bity informacji znajdują się w tym samym miejscu.
W mniejszych systemach możesz chcieć przeprowadzić ręczne kontrole, ale w większych środowiskach nie jest możliwe przeanalizowanie wszystkiego w czasie rzeczywistym. To też brzmi jak strata czasu. Aby upewnić się, że Twoje systemy są w dobrym stanie, musisz przejrzeć całkiem sporo informacji. Zwykle obejmuje to statystyki hosta, statystyki bazy danych, stan kopii zapasowych, dzienniki i tak dalej.
Co monitorować i jak często?
Po skonfigurowaniu wszystkich narzędzi do monitorowania/zarządzania bazą danych należy ustanowić procedurę sprawdzania kondycji baz danych. To, jak często chcesz to robić, zależy od Ciebie i powinno zależeć od rozmiaru/obciążenia pracą Twojego środowiska lub standardów zgodności Twojej firmy lub branży. W przypadku mniejszych konfiguracji sprawdzane będą codzienne kontrole. W przypadku większych konfiguracji prawdopodobnie będziesz musiał to robić co tydzień. Powodem tego jest to, że regularne testy powinny umożliwiać proaktywne działanie i rozwiązywanie wszelkich problemów, zanim się pojawią lub staną się poważne. Oczywiście w końcu opracujesz swój wzór, ale oto kilka wskazówek dotyczących tego, jak możesz chcieć wyglądać.
To, co monitorować, będzie prawdopodobnie związane z rolą, jaką pełnisz w swojej organizacji IT. DBA, DevOps, programiści lub kierownictwo IT będą mieć inne potrzeby.
 Raporty operacyjne ClusterControl
Raporty operacyjne ClusterControl Harmonogram raportów operacyjnych
Zanim zaczniemy opisywać poszczególne raporty operacyjne, rzućmy okiem na harmonogram raportów. Możesz skonfigurować automatyczne raporty cykliczne na podstawie nazwy klastra. Współczynnik generacji jest podzielony na typ dzienny, tygodniowy, miesięczny. Każdy z nich daje możliwość skonfigurowania raportu w razie potrzeby, na przykład co piąty dzień miesiąca w przypadku typu miesięcznego lub w każdy wtorek, jeśli wybierzesz Raporty tygodniowe.
 Harmonogram raportów operacyjnych ClusterControl
Harmonogram raportów operacyjnych ClusterControl W drugiej sekcji harmonogramu raportów możesz wybrać odbiorców. To dobra okazja, aby ustawić kilka alertów dla zespołu zarządzającego, a później bardziej technicznych dla wsparcia IT. Właściwe zaplanowanie tego może znacznie odciążyć dział IT, np. gdy kierownictwo prosi o raporty dotyczące dostępności lub zespół ds. bezpieczeństwa musi znać wersję pakietów i zmiany schematu.
Raport kopii zapasowej
Tygodniowy raport kopii zapasowej to raport w formacie HTML, który zawiera przegląd kopii zapasowych w okresie raportowania dla wszystkich zarządzanych klastrów. Raport kopii zapasowej podzielony jest na dwie sekcje; podsumowanie kopii zapasowej i szczegóły kopii zapasowej.
W głównej sekcji raportu możesz zobaczyć podsumowanie wszystkich swoich klastrów wraz z typem klastra, ostatnią kopią zapasową, nieudanymi i udanymi kopiami zapasowymi, wskaźnikiem powodzenia i okresem przechowywania. Co ważne, zobaczysz również informacje o klastrach bez zestawu kopii zapasowych. Jest to niezwykle pomocne, jeśli zapomnisz skonfigurować kopię zapasową lub jeśli z jakiegoś powodu kopie zapasowe przestały działać.
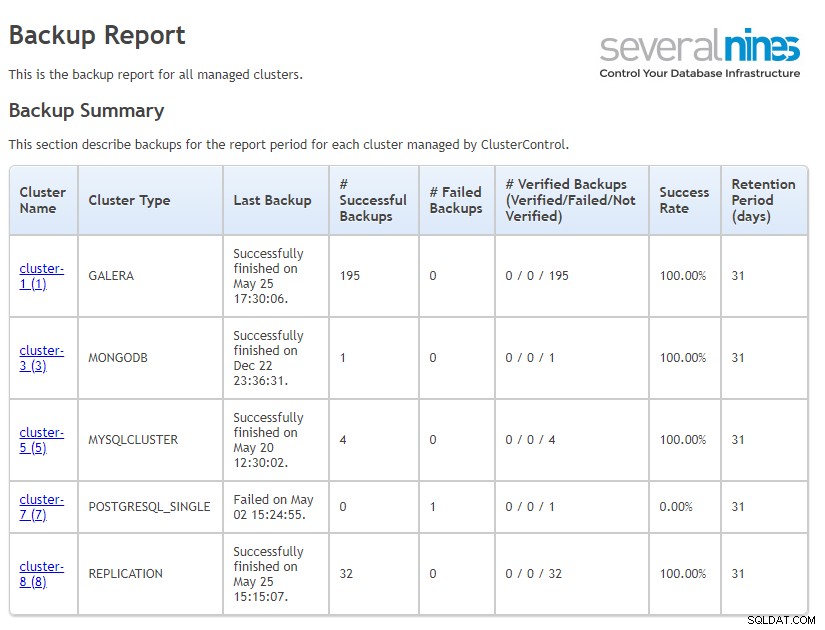 Raport operacyjny podsumowujący program ClusterControl Backup
Raport operacyjny podsumowujący program ClusterControl Backup W szczegółach kopii zapasowej możesz śledzić konkretny identyfikator kopii zapasowej ze szczegółowymi informacjami o lokalizacji, rozmiarze, czasie i metodzie. Używamy tych samych szablonów z danymi dla różnych typów baz danych, więc zarządzając mieszanym środowiskiem, uzyskasz ten sam wygląd i wygląd. Pomaga lepiej zarządzać różnymi kopiami zapasowymi baz danych.
Jak działa to rozwiązanie? Zbieramy informacje o procesie backupu, systemach, platformach i urządzeniach w infrastrukturze backupu w momencie uruchomienia zadania backupu. Wszystkie te informacje są agregowane i przechowywane w CMON (baza danych repozytorium ClusterControl), więc nie ma potrzeby dodatkowego odpytywania poszczególnych baz danych.
Domyślny raport dotyczący klastrów
Domyślny raport o klastrze zawiera wszystkie szczegółowe informacje o konkretnym klastrze. Rozpoczyna się przeglądem różnych alertów związanych z grupą klastrów.
 Domyślny raport klastra ClusterControl
Domyślny raport klastra ClusterControl Następna sekcja dotyczy stanu węzłów wchodzących w skład klastra. Masz listę węzłów w klastrze, ich typ, rolę (master lub slave), status węzła, czas pracy i system operacyjny.
 ClusterControl Domyślny czas pracy węzła raportu klastra i role
ClusterControl Domyślny czas pracy węzła raportu klastra i role Kolejną sekcją raportu jest podsumowanie kopii zapasowej, takie samo jak omówione powyżej.
 ClusterControl Szczegóły kopii zapasowej raportu domyślnego klastra
ClusterControl Szczegóły kopii zapasowej raportu domyślnego klastra Kolejna przedstawia przegląd najpopularniejszych zapytań w klastrze. Na koniec widzimy „Przegląd stanu węzła”, w którym otrzymasz wykresy związane z metrykami systemu operacyjnego i MySQL dla każdego węzła.

 ClusterControl Stan węzła przeglądu domyślnego klastra
ClusterControl Stan węzła przeglądu domyślnego klastra Raport uaktualnienia
Ten raport klastra pomoże Ci zapewnić aktualność i bezpieczeństwo Twoich pakietów. Raport z aktualizacji zbiera informacje z systemu operacyjnego i porównuje je z pakietami dostępnymi w repozytorium.
Raport podzielony jest na cztery sekcje; podsumowanie aktualizacji, pakiety baz danych, pakiety bezpieczeństwa i inne pakiety. Możesz szybko porównać to, co zainstalowałeś w swoim systemie i znaleźć zalecaną aktualizację lub poprawkę.



Raport wykrywania zmian schematu
Raport wykrywania zmian schematu pokazuje wszelkie zmiany DDL w Twojej bazie danych. Do poprawnej pracy wymagany jest dodatkowy parametr w pliku konfiguracyjnym ClusterControl. Jeśli to nie jest ustawione, zobaczysz następujące informacje:schema_change_detection_address nie jest ustawiony w /etc/cmon.d/cmon_1.cnf. Gdy to nastąpi, przykładowe wyjście może wyglądać jak poniżej:
 Raport o zmianie schematu ClusterControl
Raport o zmianie schematu ClusterControl Raport dostępności
Ostatni, ale nie mniej ważny jest raport dostępności. Dostępność jest niezwykle trudna do zmierzenia i raportowania, chociaż jest to ważny wskaźnik KPI w każdej umowie SLA między Tobą a Twoim klientem. Mając to na uwadze, stworzyliśmy raport, który może mierzyć czas pracy Twojej bazy danych. Skrypt jest umieszczany na Twoim koncie podczas planowanej konserwacji, którą możesz ustawić w ClusterControl. Na podstawie informacji zawartych w raporcie możesz sprawdzić, czy jesteś zgodny z wewnętrzną lub zewnętrzną umową SLA i zaplanować zmiany w infrastrukturze bazy danych, aby zachować zaplanowane dziewiątki.
 Raport o zmianie schematu ClusterControl
Raport o zmianie schematu ClusterControl Główna sekcja raportu opisuje czas działania/przestoju i dostępność w okresie raportowania dla każdego klastra zarządzanego przez ClusterControl. Informacje są łączone dla wszystkich klastrów, niezależnie od typu klastra.
 Historia stanu klastra Raport dostępności ClusterControl
Historia stanu klastra Raport dostępności ClusterControl Poniżej znajdziesz szczegółowe informacje na temat ważnych zmian stanu, które nastąpiły w okresie raportowania, a także restartów kontrolera. Ponowne uruchomienie kontrolera nie wpływa na czas działania ani przestoje, a planowana konserwacja nie zostanie uwzględniona w raporcie.
 Historia węzłów raportu dostępności ClusterControl
Historia węzłów raportu dostępności ClusterControl Wniosek
Kilkadziesiąt ClusterControl może pomóc w omówieniu kilku aspektów zgodności systemu bazy danych. Począwszy od szczegółów historii tworzenia kopii zapasowych, których można użyć do śledzenia takich rzeczy, jak ukończenie tworzenia kopii zapasowych, historia i serwery bez odpowiedniej polityki tworzenia kopii zapasowych, po raporty dotyczące aktualizacji pakietów z przestarzałymi pakietami systemowymi i zmianami w schemacie. W kilku krokach możesz zaplanować kontrole na poziomie przedsiębiorstwa w bazach danych typu open source. Wszystko to zapewni kierownictwu i zespołom wsparcia lepszy wgląd w operacje bazy danych.



