SCUMM (Severalnines ClusterControl Unified Monitoring &Management) to rozwiązanie oparte na agentach z agentami zainstalowanymi na węzłach bazy danych. Zapewnia zestaw monitorujących pulpitów nawigacyjnych, w których Prometheus jest magazynem danych z elastycznym językiem zapytań i wielowymiarowym modelem danych. Prometheus zbiera dane metryk od eksporterów działających na hostach bazy danych.
Architektura ClusterControl SCUMM została wprowadzona w wersji 1.7.0 rozszerzającej funkcjonalność monitorowania dla MySQL, Galera Cluster, PostgreSQL i ProxySQL.
Nowy ClusterControl 1.7.1 dodaje monitorowanie w wysokiej rozdzielczości dla systemów MongoDB.
 Lista pulpitu nawigacyjnego ClusterControl MongoDB
Lista pulpitu nawigacyjnego ClusterControl MongoDB W tym artykule opiszemy dwa główne dashboardy dla środowisk MongoDB. Serwer MongoDB i zestaw replik MongoDB.
Panel i lista wskaźników
Lista pulpitów nawigacyjnych i ich wskaźników:
| Serwer MongoDB | |
|---|---|
| Nazwa ReplSet Name Czas dostępności serwera OpsCounters Połączenia WT - Równoczesne bilety (odczyt) WT - Równoczesne bilety (zapis) WT — pamięć podręczna Globalna blokada potwierdzeń |
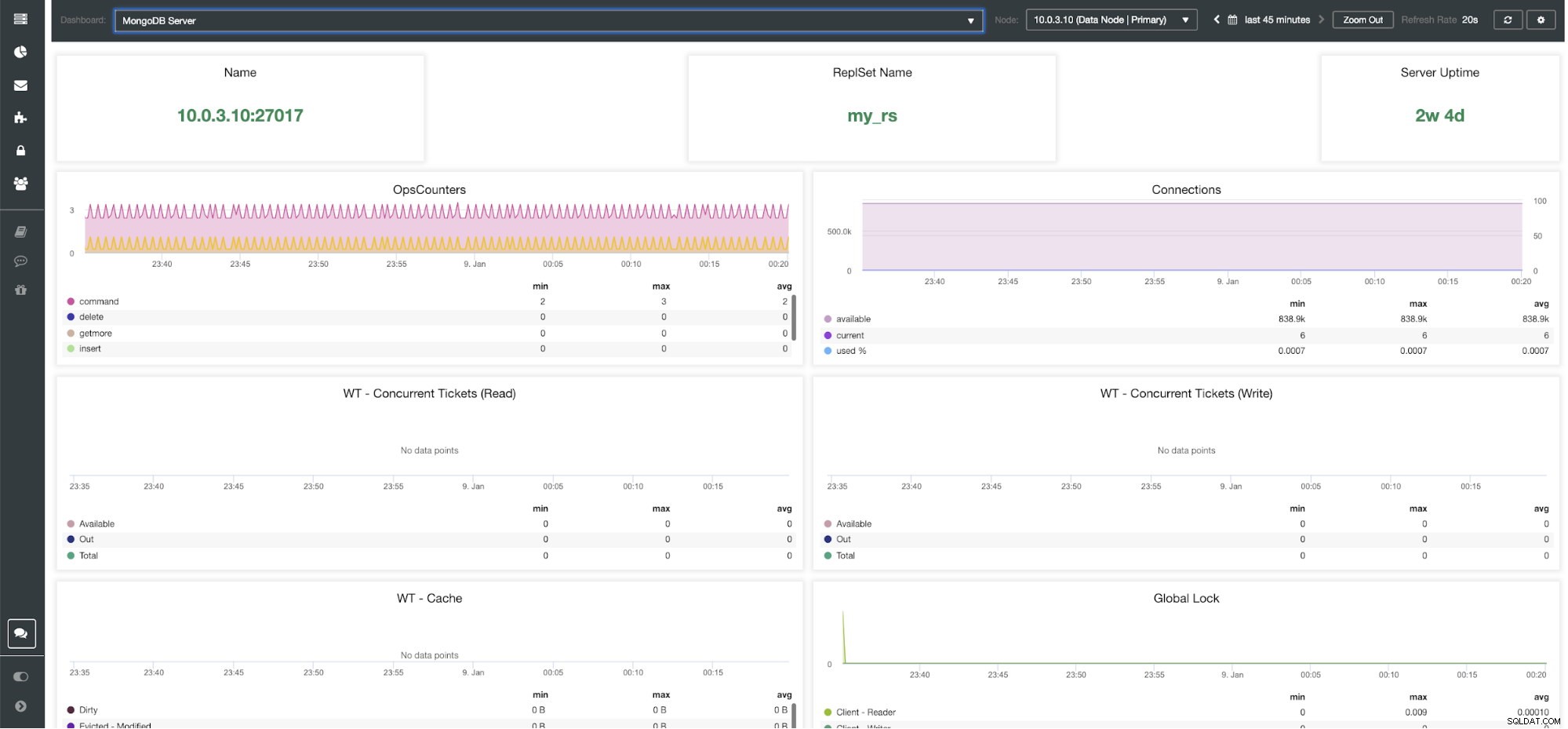 Panel ClusterControl MongoDB Server
Panel ClusterControl MongoDB Server| MongoDB ReplicaSet | |
|---|---|
| Rozmiar zestawu replik Nazwa zestawu replik PODSTAWOWY Wersja serwera Zestawy replik i elementy członkowskie Okno Oplog na zestaw replik Zapas replik Łącznie PODSTAWOWY/WTÓRNY online na ReplSet Open Cursors per ReplSet ReplSet - Przeterminowane kursory na zestaw Maksymalne opóźnienie replikacji na ReplSet Rozmiar Oplog OpsCounters Czas pingowania do członków zestawu replik z PODSTAWOWYCH |
 Pulpit nawigacyjny ClusterControl MongoDB ReplicaSet
Pulpit nawigacyjny ClusterControl MongoDB ReplicaSet Systemy baz danych w dużym stopniu zależą od zasobów systemu operacyjnego, więc możesz również znaleźć dwa dodatkowe pulpity nawigacyjne dla Przeglądu systemu i Przeglądu klastrów Twojego środowiska MongoDB.
| Przegląd systemu | |
|---|---|
| Czas pracy serwera Rdzenie procesora Całkowita pamięć RAM Średnie obciążenie Użycie procesora Użycie pamięci RAM Użycie miejsca na dysku Użycie sieci Dysk IOPS Dysk IOPS Util % Przepustowość dysku |
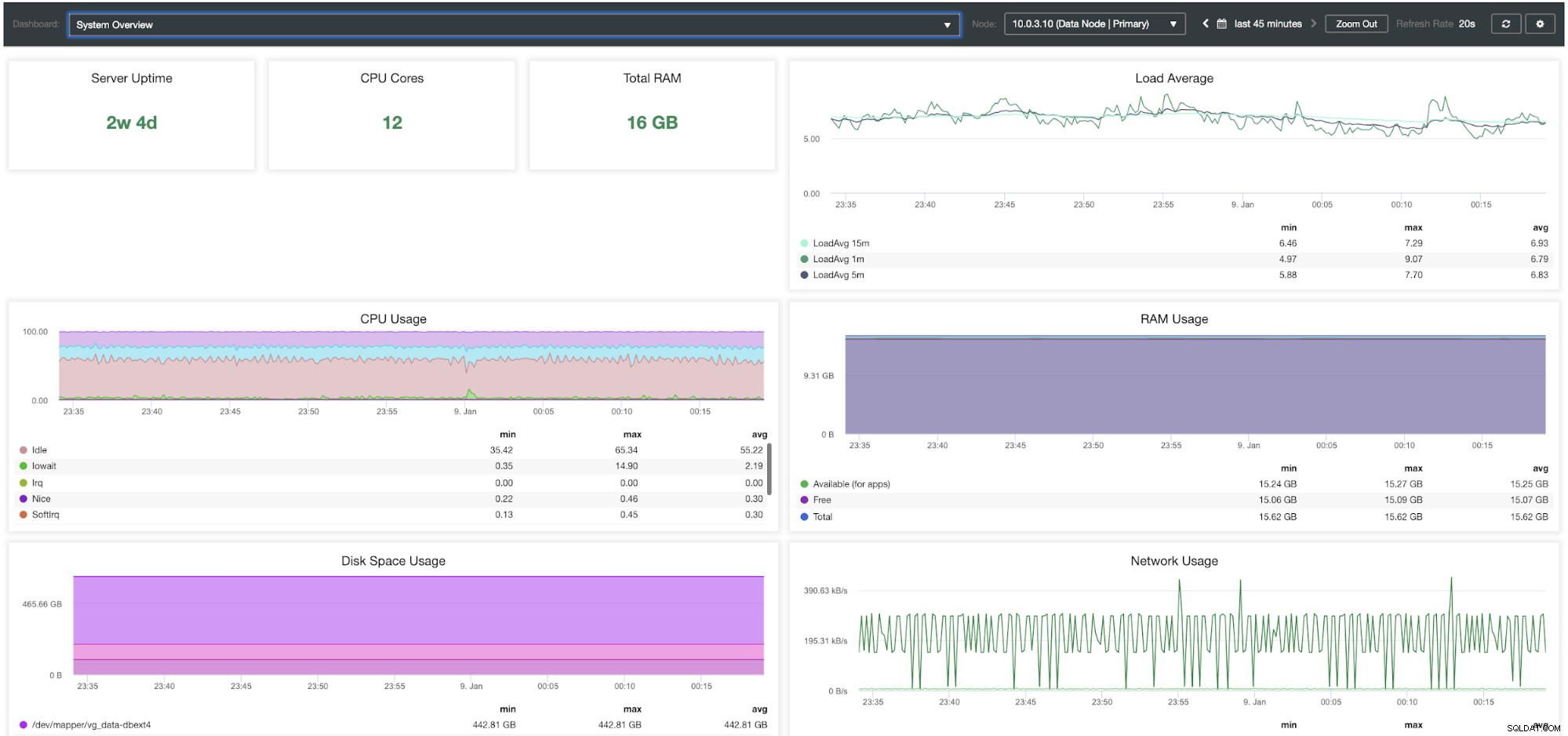 Panel przeglądu systemu ClusterControl
Panel przeglądu systemu ClusterControl| Przegląd klastra | |
|---|---|
| Średnie obciążenie 1m Średnio obciążenie 5m Średnio obciążenie 15m Pamięć dostępna dla aplikacji Transmisja w sieci Odbiór w sieci IOPS odczytu dysku Zapis IOPS na dysku Zapis na dysku + IOPS odczytu |
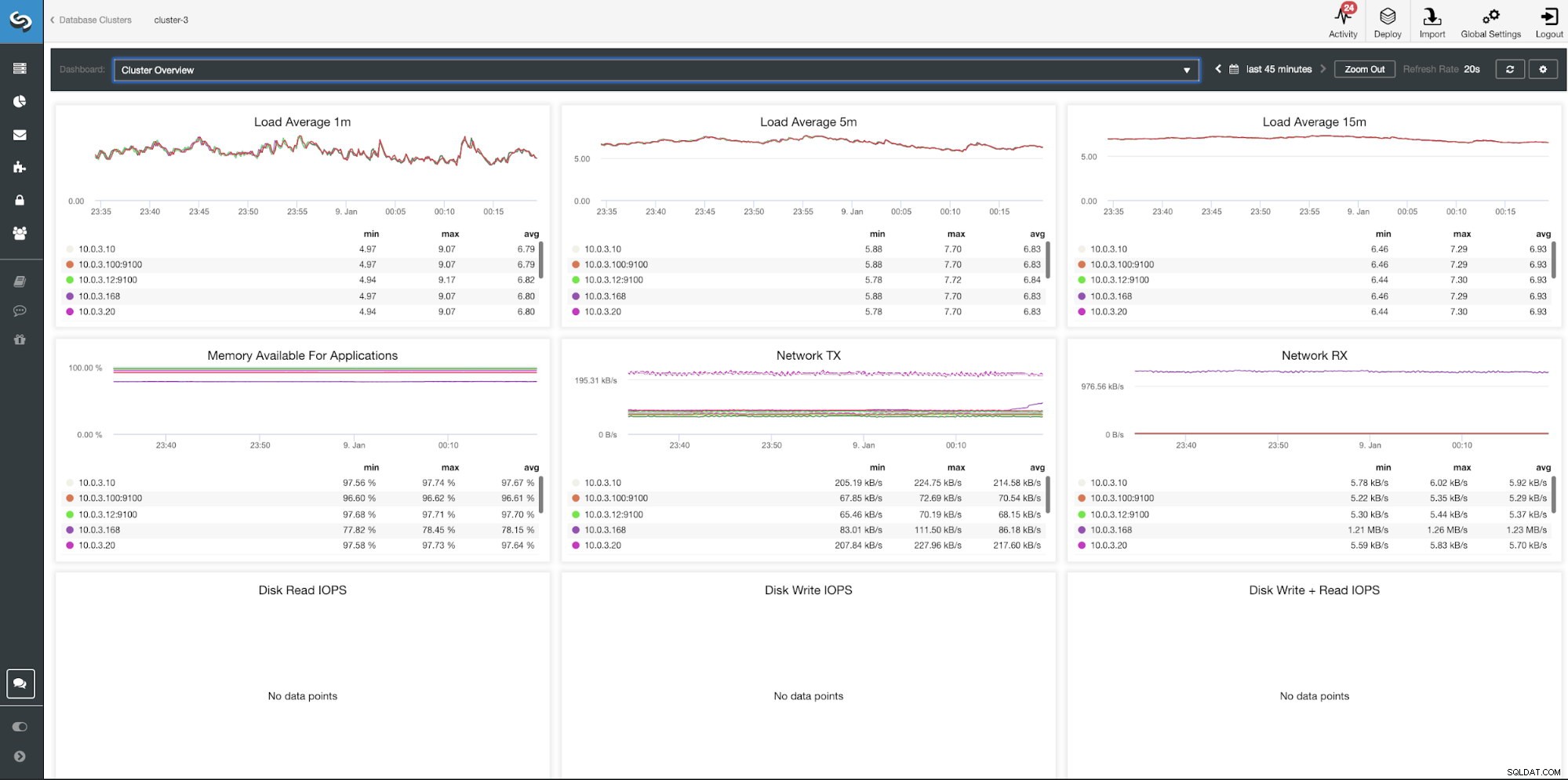 Panel informacyjny ClusterControl Cluster Overview
Panel informacyjny ClusterControl Cluster Overview Pulpit nawigacyjny serwera MongoDB
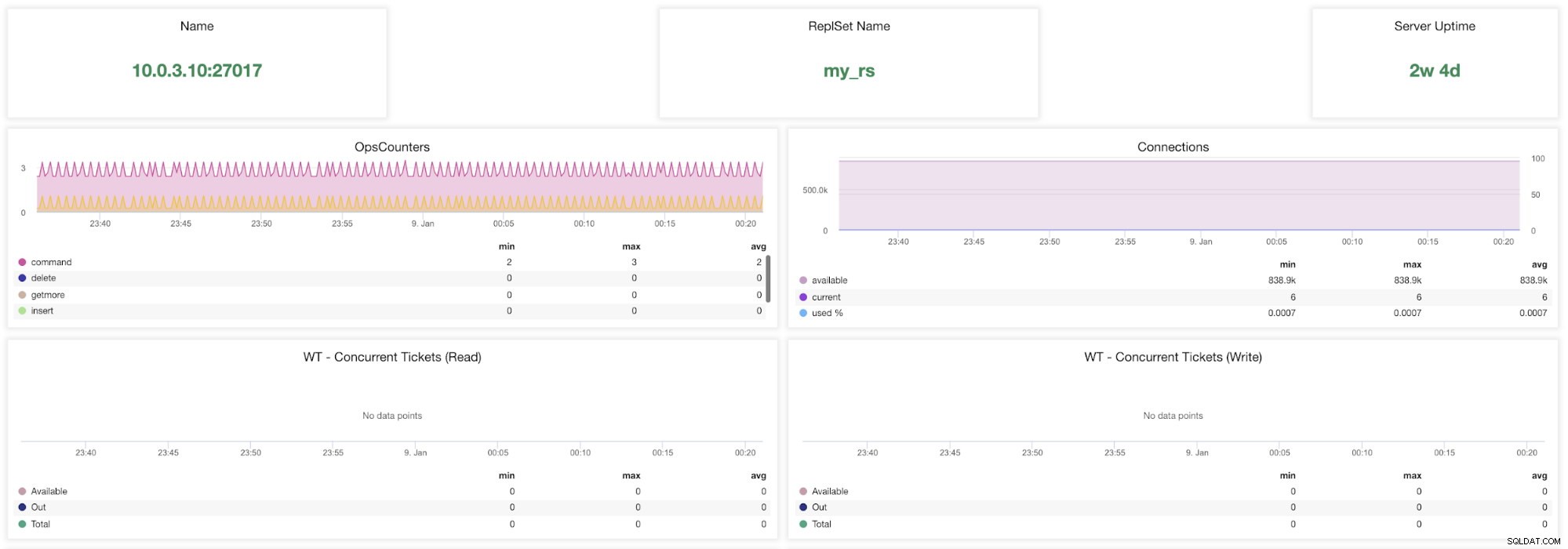 Wskaźniki ClusterControl MongoDB
Wskaźniki ClusterControl MongoDB Nazwa - Adres serwera i port.
Nazwa zestawu odpowiedzi - Przedstawia nazwę zestawu replik, do którego należy serwer.
Czas pracy serwera - Czas od ostatniego restartu serwera.
Ops Couters - Liczba wniosków otrzymanych w wybranym okresie z podziałem na rodzaj operacji. Te liczby obejmują wszystkie otrzymane operacje, w tym te, które zakończyły się niepowodzeniem.
Połączenia — Ten wykres przedstawia jeden z najważniejszych wskaźników do obserwowania — liczbę połączeń otrzymanych w wybranym okresie, w tym nieudane żądania. Nietypowe obciążenie ruchem może prowadzić do problemów z wydajnością. Jeśli MongoDB ma mało połączeń, może nie być w stanie obsłużyć przychodzących żądań w odpowiednim czasie.
WT — bilety równoczesne (odczyt) / WT — bilety równoczesne (zapis) Te dwa wykresy pokazują bilety odczytu i zapisu, które kontrolują współbieżność w WiredTiger (WT). Bilety WT kontrolują liczbę operacji odczytu i zapisu, które mogą być jednocześnie wykonywane w aparacie pamięci masowej. Gdy dostępne bilety odczytu i zapisu spadną do zera, liczba współbieżnie działających operacji jest równa skonfigurowanym wartościom odczytu/zapisu. Oznacza to, że przed wykonaniem wszelkie inne operacje muszą poczekać, aż jeden z uruchomionych wątków zakończy swoją pracę na silniku pamięci masowej.
 Wskaźniki ClusterControl MongoDB
Wskaźniki ClusterControl MongoDB WT – pamięć podręczna (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - Rozmiar pamięci podręcznej jest najważniejszą pokrętłem dla WiredTiger. Domyślnie MongoDB 3.x rezerwuje 50% (60% w 3.2) dostępnej pamięci na swoją pamięć podręczną danych.
Blokada globalna (Klient-odczyt, Klient - Zapis, Bieżąca kolejka - Czytnik, Bieżąca kolejka - Zapis) — Słabe wzorce projektowe schematu lub duże żądania odczytu i zapisu od wielu klientów mogą powodować rozległe blokowanie. W takim przypadku istnieje potrzeba zachowania spójności i unikania konfliktów zapisu.
Aby to osiągnąć, MongoDB używa blokowania wieloziarnistego, które umożliwia wykonywanie operacji blokowania na różnych poziomach, takich jak poziom globalny, bazy danych lub kolekcji .
Atesty (msg, regular, rollovers, user) — ten wykres przedstawia liczbę asercji, które są zgłaszane w każdej sekundzie. Należy przeanalizować wysokie wartości i odchylenia od trendów.
Pulpit nawigacyjny zestawu replik MongoDB
Dane wyświetlane w tym panelu mają znaczenie tylko wtedy, gdy używasz zestawu replik.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Rozmiar zestawu replik - Liczba członków w zestawie replik. Standardowe wdrożenie zestawu replik dla systemu produkcyjnego to trzyczłonowy zestaw replik. Ogólnie rzecz biorąc, zaleca się, aby zestaw replik miał nieparzystą liczbę członków głosujących. Odporność na awarie dla zestawu replik to liczba członków, które mogą stać się niedostępne i nadal pozostawiać wystarczającą liczbę członków w zestawie, aby wybrać podstawowy. Tolerancja błędów dla trzech członków wynosi jeden, dla pięciu to dwa itd.
Nazwa zestawu odpowiedzi - Jest to nazwa przypisana w pliku konfiguracyjnym MongoDB. Nazwa odnosi się do wartości /etc/mongod.conf replSet.
PODSTAWOWA - Węzeł główny odbiera wszystkie operacje zapisu i rejestruje wszystkie inne zmiany w swoim zestawie danych w swoim dzienniku operacji. Wartość służy do identyfikacji adresu IP i portu węzła podstawowego w klastrze zestawu replik MongoDB.
Wersja serwera - Zidentyfikuj wersję serwera. ClusterControl w wersji 1.7.1 obsługuje wersje MongoDB 3.2/3.4/3.6/4.0.
Zestawy replik i elementy członkowskie (min., maks., śr.) — ten wykres może pomóc w identyfikacji aktywnych członków w danym okresie. Możesz śledzić minimalną, maksymalną i średnią liczbę węzłów głównych i drugorzędnych oraz sposób, w jaki te liczby zmieniały się w czasie. Każde odchylenie może wpłynąć na odporność na uszkodzenia i dostępność klastra.
Okno Oploga na zestaw Repl - Okno replikacji jest niezbędnym wskaźnikiem do obejrzenia. Oplog MongoDB to pojedyncza kolekcja, która została ograniczona do (wstępnie ustawionego) rozmiaru. Można to opisać jako różnicę między pierwszym a ostatnim znacznikiem czasu w oplog.rs. Jest to czas, przez jaki pomocnicza może być w trybie offline, zanim będzie potrzebna początkowa synchronizacja do zsynchronizowania instancji. Te metryki informują Cię, ile czasu Ci pozostało, zanim nasza następna transakcja zostanie usunięta z oploga.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Zapas replikacji — Ten wykres przedstawia różnicę między głównym oknem oplog a opóźnieniem replikacji węzłów drugorzędnych. Oplog MongoDB ma ograniczony rozmiar i jeśli węzeł zbytnio się opóźnia, nie będzie w stanie nadrobić zaległości. W takim przypadku zostanie wydana pełna synchronizacja i jest to kosztowna operacja, której należy zawsze unikać.
Łącznie PRIMARY/SECONDARY online na zestaw ReplSet - Całkowita liczba węzłów klastra w okresie czasu.
Otwarte kursory na zestaw powtórzeń (przypięte, limit czasu, łącznie) - Żądanie odczytu pochodzi z kursorem, który jest wskaźnikiem do zbioru danych wyniku. Pozostanie otwarta na serwerze, a tym samym będzie zużywać pamięć, chyba że zostanie przerwana przez domyślne ustawienie MongoDB. Powinieneś identyfikować nieaktywne kursory i odciąć je, aby zaoszczędzić na pamięci.
Zestaw uzupełnień - Timeout Cursors per SetsMax Replication Lag per ReplSet - Opóźnienie replikacji jest bardzo ważne, aby mieć na oku, jeśli skalujesz odczyty poprzez dodanie większej liczby drugorzędnych. MongoDB użyje tych serwerów pomocniczych tylko wtedy, gdy nie pozostaną zbyt daleko w tyle. Jeśli serwer pomocniczy ma opóźnienie replikacji, ryzykujesz udostępnienie nieaktualnych danych, które zostały już nadpisane na serwerze podstawowym.
Rozmiar Oploga - Niektóre obciążenia mogą wymagać większego rozmiaru oploga. Aktualizacje wielu dokumentów naraz, usunięcia to taka sama ilość danych jak wstawka lub znaczna liczba aktualizacji na miejscu.
OpsConters - Ten wykres pokazuje liczbę wykonań zapytań.
Czas ping do Replica Set Member from Primary - Pozwala to odkryć elementy zestawu replik, które są wyłączone lub niedostępne z węzła podstawowego.
Uwagi końcowe
Nowa funkcja pulpitu nawigacyjnego ClusterControl 1.7.1 MongoDB jest dostępna w wersji Community za darmo. Zespoły ds. obsługi baz danych mogą czerpać z tego korzyści, korzystając z wykresów o wysokiej rozdzielczości, zwłaszcza podczas wykonywania codziennych czynności jako analizy przyczyn źródłowych i planowania wydajności.
Wystarczy jedno kliknięcie, aby wdrożyć nowe agenty monitorowania. ClusterControl instaluje agentów Prometheus, konfiguruje metryki i utrzymuje dostęp do konfiguracji eksporterów Prometheus za pośrednictwem swojego GUI, dzięki czemu można lepiej zarządzać konfiguracją parametrów, taką jak flagi zbierające dla eksporterów (Prometheus).
Odpowiednio monitorując liczbę żądań odczytów i zapisów, możesz zapobiec przeciążeniu zasobów, szybko znaleźć źródło potencjalnych przeciążeń i wiedzieć, kiedy skalować w górę.



