Kopie zapasowe - jedna z najważniejszych rzeczy, o które należy zadbać podczas zarządzania bazami danych. Mówi się, że istnieją dwa rodzaje ludzi - ci, którzy wykonują kopie zapasowe swoich danych i ci, którzy zrobią kopię zapasową swoich danych. W tym poście na blogu omówimy dobre praktyki związane z tworzeniem kopii zapasowych i pokażemy, jak zbudować niezawodny system tworzenia kopii zapasowych za pomocą ClusterControl.
Zobaczymy, jak ClusterControl zapewnia scentralizowane zarządzanie kopiami zapasowymi dla MySQL, MariaDB, MongoDB i PostgreSQL. Zapewnia tworzenie kopii zapasowych na gorąco dużych zestawów danych, odzyskiwanie do określonego momentu, szyfrowanie danych w stanie spoczynku i w trakcie przesyłania, integralność danych dzięki automatycznej weryfikacji przywracania, kopie zapasowe w chmurze (AWS, Google i Azure) do odzyskiwania po awarii, zasady przechowywania zapewniające zgodność oraz automatyczne alerty i raporty.
Typy kopii zapasowych
Istnieją dwa główne typy kopii zapasowych, które możemy wykonać w ClusterControl:
- Logiczna kopia zapasowa - kopia zapasowa danych jest przechowywana w formacie czytelnym dla człowieka, takim jak SQL
- Fizyczna kopia zapasowa — kopia zapasowa zawiera dane binarne
Obydwa się uzupełniają - logiczny backup pozwala (w mniej lub bardziej prosty sposób) odzyskać nawet jeden wiersz danych. Fizyczne kopie zapasowe wymagałyby więcej czasu, ale z drugiej strony umożliwiają bardzo szybkie przywrócenie całego hosta (coś, co może zająć godziny lub nawet dni w przypadku logicznej kopii zapasowej).
ClusterControl obsługuje tworzenie kopii zapasowych dla MySQL/MariaDB/Percona Server, PostgreSQL i MongoDB.
Zaplanuj tworzenie kopii zapasowych
Rozpoczęcie tworzenia kopii zapasowej w ClusterControl jest proste i wydajne przy użyciu kreatora. Planowanie kopii zapasowej zapewnia łatwość obsługi i dostęp do innych funkcji, takich jak szyfrowanie, automatyczny test/weryfikacja kopii zapasowej lub archiwizacja w chmurze.
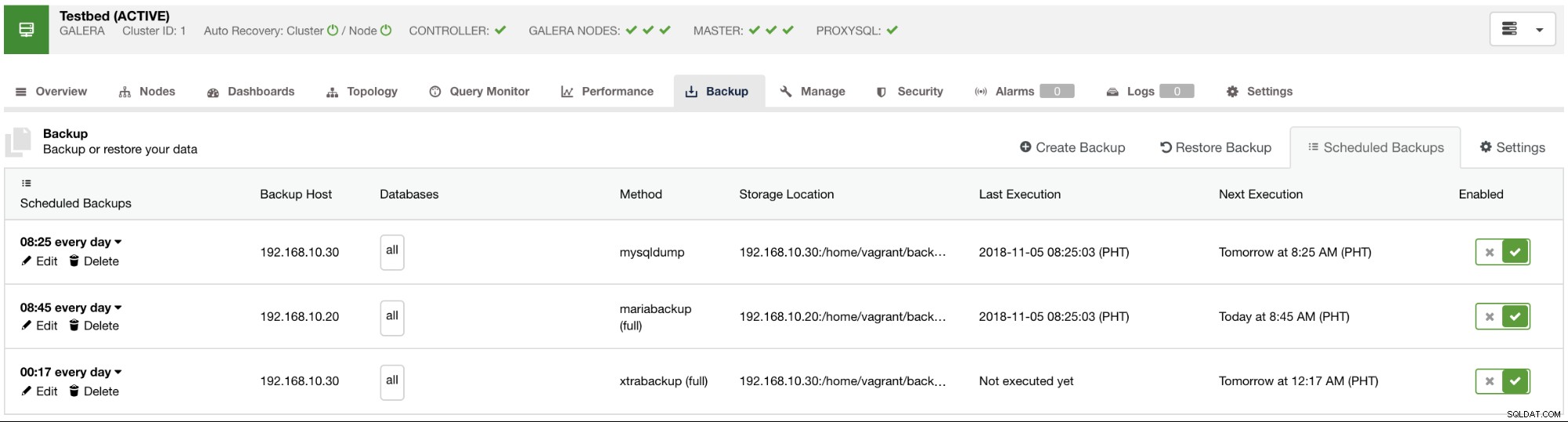
Dostępne zaplanowane kopie zapasowe zostaną wyświetlone na karcie Zaplanowane kopie zapasowe, jak pokazano na poniższym obrazku:
Dobrą praktyką przy planowaniu tworzenia kopii zapasowych jest zdefiniowanie czasu przechowywania kopii zapasowych i zalecana jest codzienna kopia zapasowa. Jednak zależy to również od potrzebnych danych, oczekiwanego ruchu i dostępności danych, gdy ich potrzebujesz, zwłaszcza podczas odzyskiwania danych, gdy dane zostały przypadkowo usunięte lub uszkodzenia dysku - co jest nieuniknione. Zdarzają się również sytuacje, w których utratę danych można odtworzyć lub można ją ręcznie zduplikować, na przykład generowanie raportów, miniatury lub dane w pamięci podręcznej. Chociaż pytanie zależy od tego, jak natychmiast ich potrzebujesz, gdy wydarzy się katastrofa; jeśli to możliwe, chciałbyś codziennie wykonywać kopie zapasowe mysqldump i xtrabackup dla MySQL, wykorzystując logiczną i fizyczną dostępność kopii zapasowych. Aby pokryć jeszcze więcej podstaw, możesz zaplanować kilka przyrostowych uruchomień xtrabackup dziennie. Może to zaoszczędzić trochę miejsca na dysku, we/wy dysku, a nawet we/wy procesora niż wykonanie pełnej kopii zapasowej.
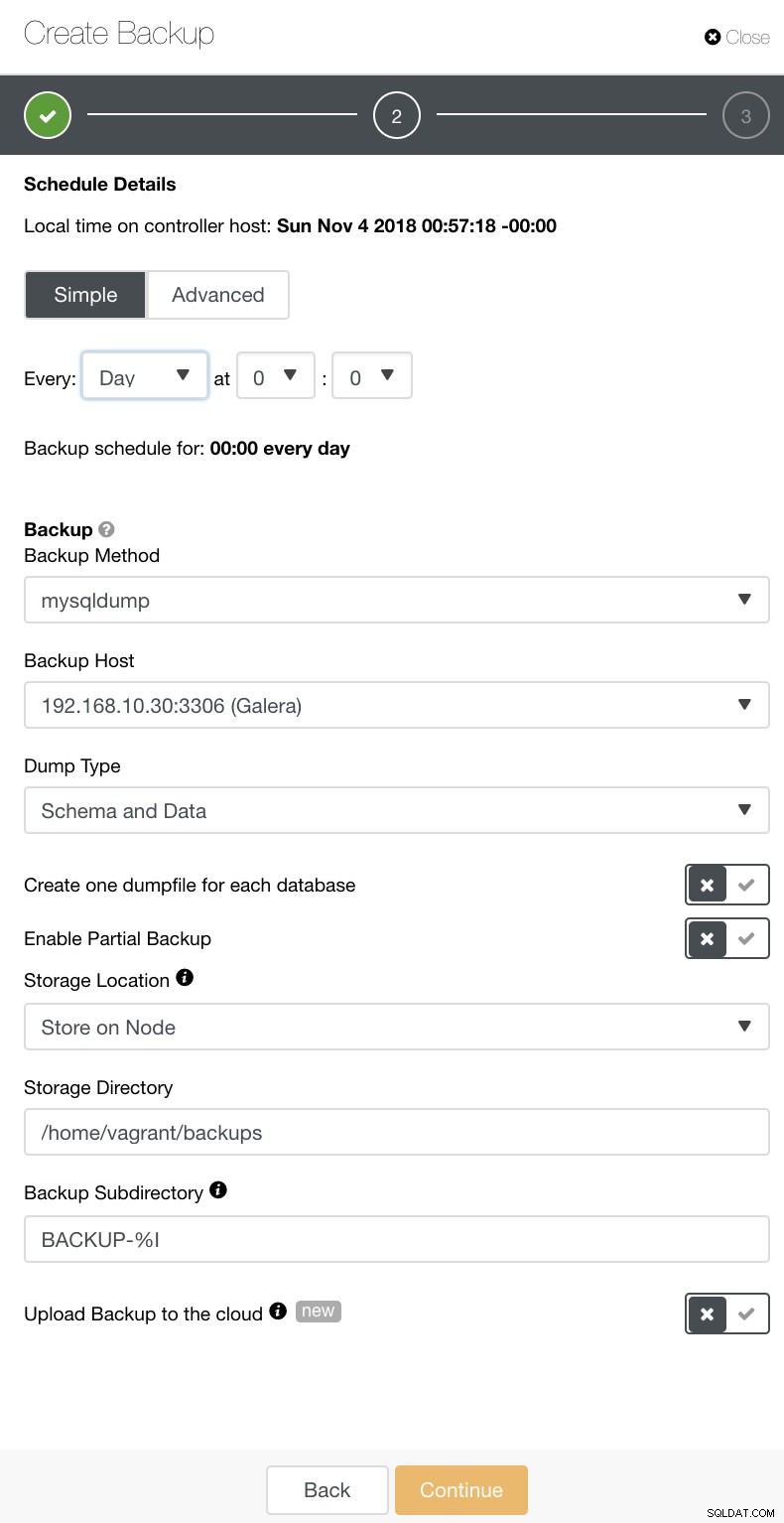
W ClusterControl możesz łatwo zaplanować te różne typy kopii zapasowych. Do wyboru jest kilka ustawień. Kopię zapasową można przechowywać na kontrolerze lub lokalnie, w węźle bazy danych, w którym wykonywana jest kopia zapasowa. Musisz wybrać lokalizację, w której ma być przechowywana kopia zapasowa, i które bazy danych chcesz wykonać — cały zestaw danych czy osobne schematy? Zobacz obrazek poniżej:
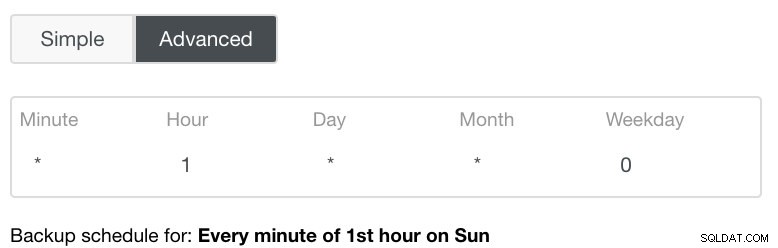
Ustawienie Zaawansowane skorzystałoby z konfiguracji podobnej do crona, aby uzyskać większą szczegółowość. Zobacz obrazek poniżej:
Za każdym razem, gdy wystąpi awaria, ClusterControl skutecznie radzi sobie z tymi problemami i tworzy logi do dalszej diagnostyki awarii kopii zapasowej.
W zależności od wybranego typu kopii zapasowej, istnieją osobne ustawienia do skonfigurowania. W przypadku Xtrabackup i Galera Cluster możesz wybrać ustawienia, które zostaną zastosowane podczas uruchamiania fizycznej kopii zapasowej. Zobacz poniżej:
- Użyj kompresji
- Poziom kompresji
- Desynchronizacja węzła podczas tworzenia kopii zapasowej
- Blokady kopii zapasowych
- Zablokuj DDL na tabelę
- Wątki kopiowania równoległego Xtrabackup
- Prędkość przesyłania strumieniowego w sieci (MB/s)
- Użyj PIGZ do równoległego gzip
- Włącz szyfrowanie
- Przechowywanie
Na poniższym obrazku możesz zobaczyć, w jaki sposób możesz odpowiednio oznaczyć opcje, a także znajdują się ikony podpowiedzi, które dostarczają więcej informacji o opcjach, które chcesz wykorzystać do tworzenia zasad tworzenia kopii zapasowych.
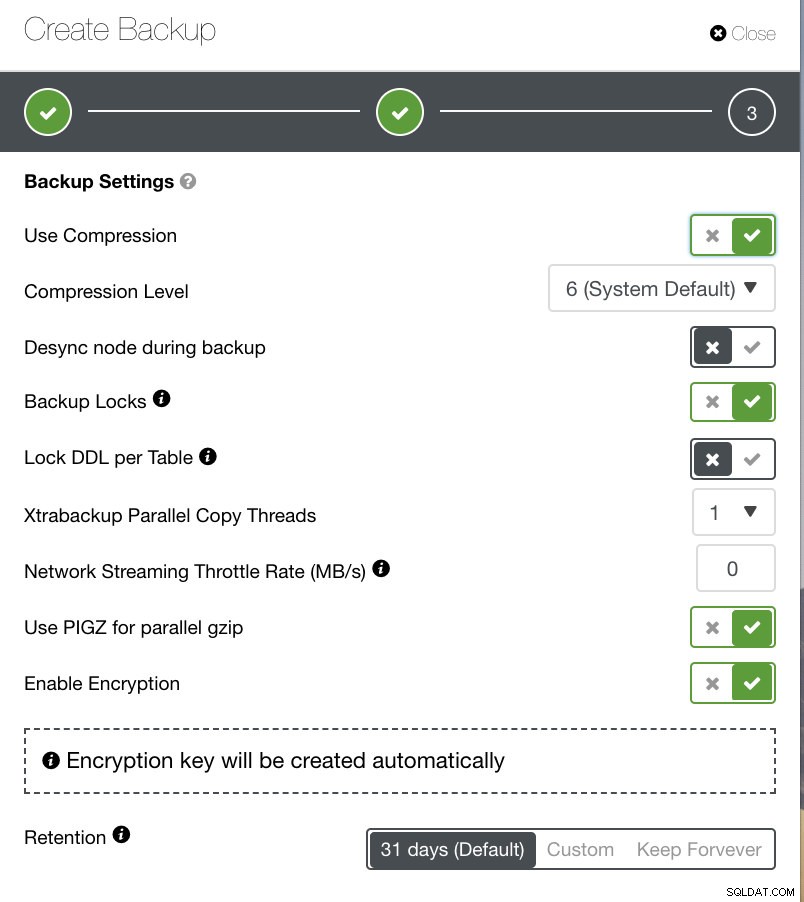
W zależności od zasad tworzenia kopii zapasowych ClusterControl można dostosować zgodnie z najlepszymi praktykami dotyczącymi aktualizowania dostępnych kopii zapasowych. Po zdefiniowaniu zasad tworzenia kopii zapasowych oczekuje się, że wymagana konfiguracja będzie dostępna od sprzętu i oprogramowania po chmurę, trwałość, wysoką dostępność lub skalowalność.
Podczas tworzenia kopii zapasowych w klastrze Galera dobrą praktyką jest ustawienie węzła Galera wsrep_desync=ON, gdy kopia zapasowa jest uruchomiona. Spowoduje to usunięcie węzła z udziału w kontroli przepływu i ochroni cały klaster przed opóźnieniem replikacji, zwłaszcza jeśli dane, które mają zostać uwzględnione w kopii zapasowej, są duże. W ClusterControl należy pamiętać, że może to również spowodować usunięcie docelowego węzła kopii zapasowej z zestawu równoważenia obciążenia. Jest to szczególnie ważne, jeśli używasz serwerów proxy HAProxy, ProxySQL lub MaxScale. Jeśli masz skonfigurowanego menedżera alertów na wypadek desynchronizacji węzła, możesz wyłączyć go w okresie, w którym uruchomiono kopię zapasową.
Innym popularnym sposobem na zminimalizowanie wpływu kopii zapasowej na klaster Galera lub urządzenie główne replikacji jest wdrożenie urządzenia podrzędnego replikacji, a następnie wykorzystanie go jako źródła kopii zapasowych — w ten sposób klaster Galera nie zostanie naruszony w żadnym momencie jako kopia zapasowa na slave jest odłączony od klastra.
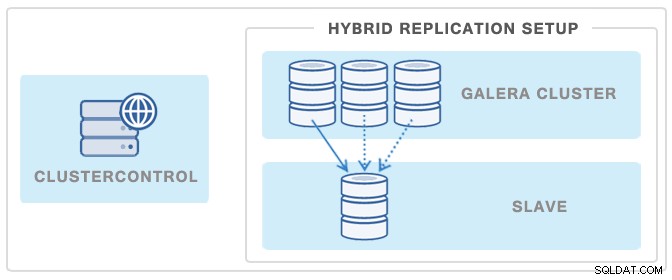
Możesz wdrożyć takie urządzenie podrzędne za pomocą zaledwie kilku kliknięć za pomocą ClusterControl. Zobacz obrazek poniżej:
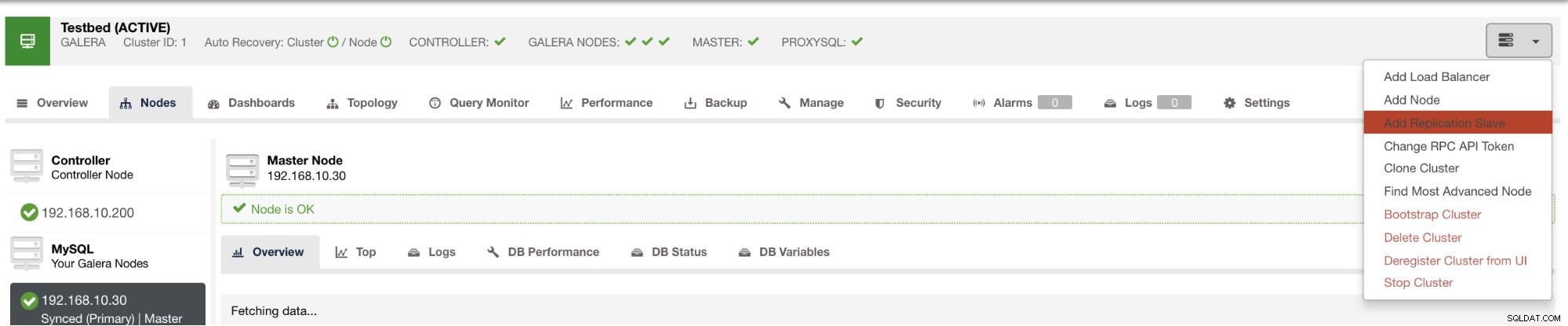
a po kliknięciu tego przycisku możesz wybrać węzły, na których chcesz skonfigurować urządzenie podrzędne. Upewnij się, że logowanie binarne węzłów jest włączone. Włączenie dziennika binarnego można również wykonać za pomocą ClusterControl, który zwiększa możliwości administrowania wybranym masterem. Zobacz obrazek poniżej:
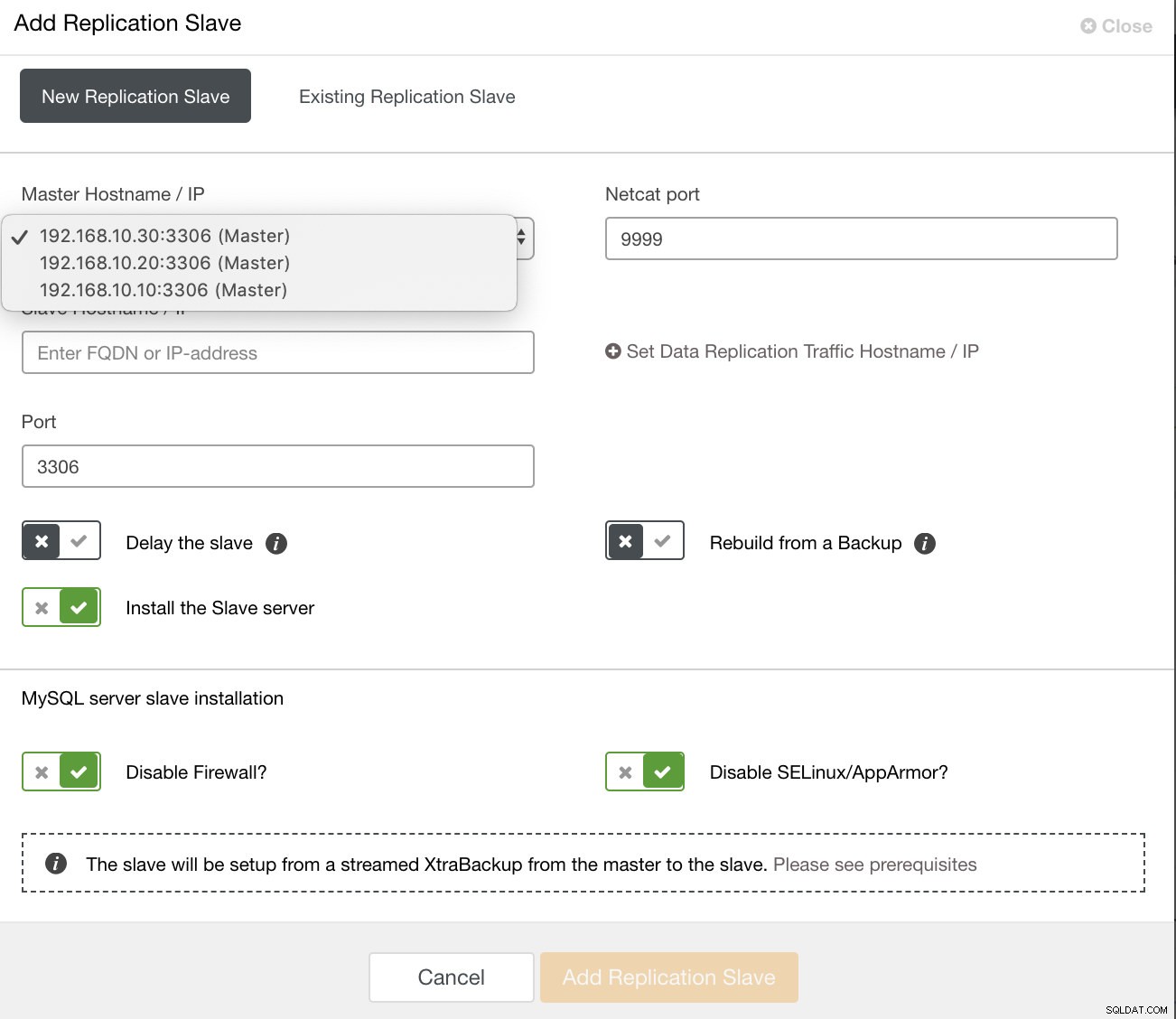
możesz także skonfigurować istniejące urządzenie podrzędne replikacji,
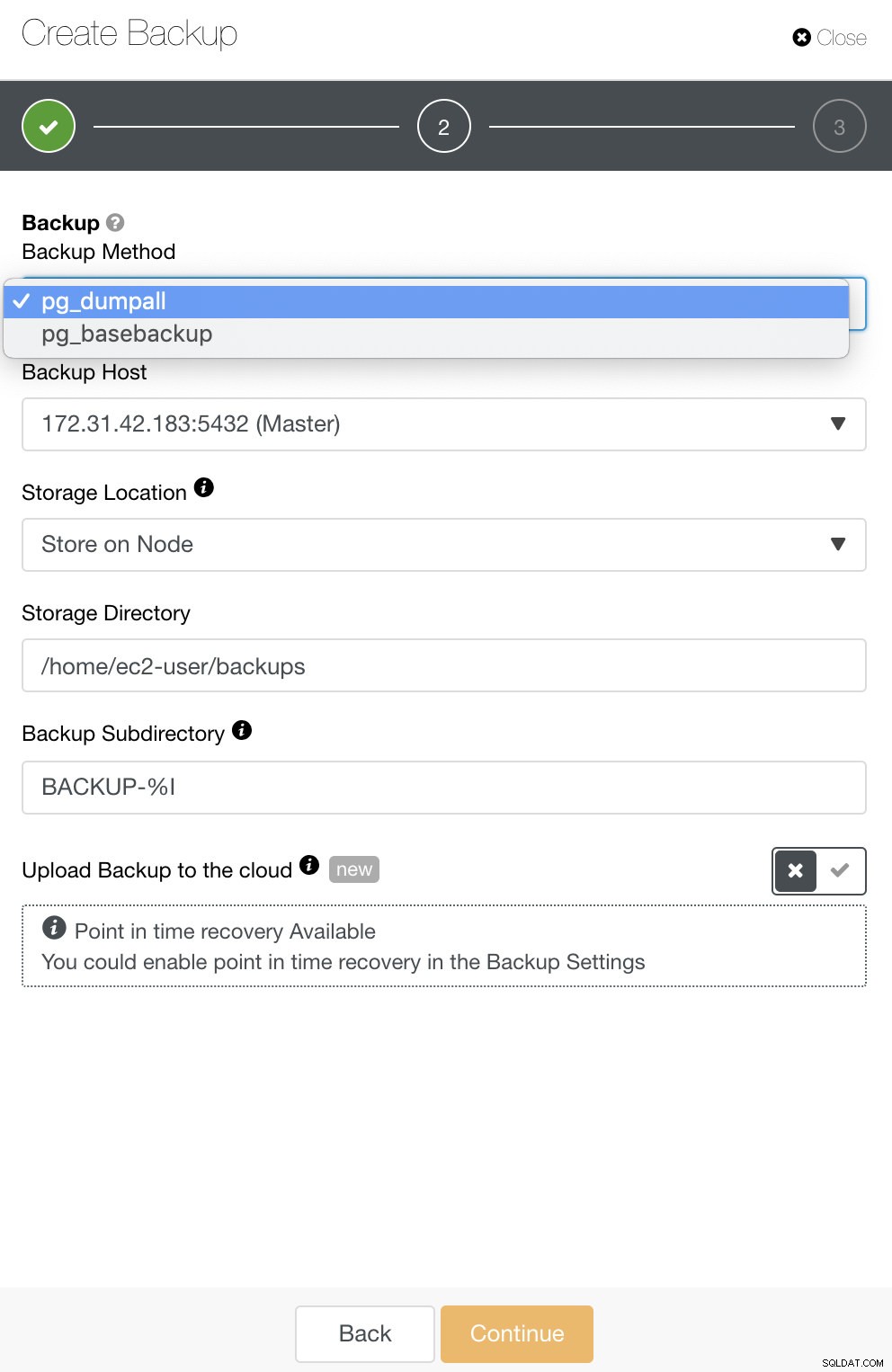
W przypadku PostgreSQL masz opcje tworzenia kopii zapasowych logicznych lub fizycznych. W ClusterControl możesz wykorzystać swoje kopie zapasowe PostgreSQL, wybierając pg_dump lub pg_basebackup. pg_basebackup nie będzie działać w wersjach starszych niż 9.3.
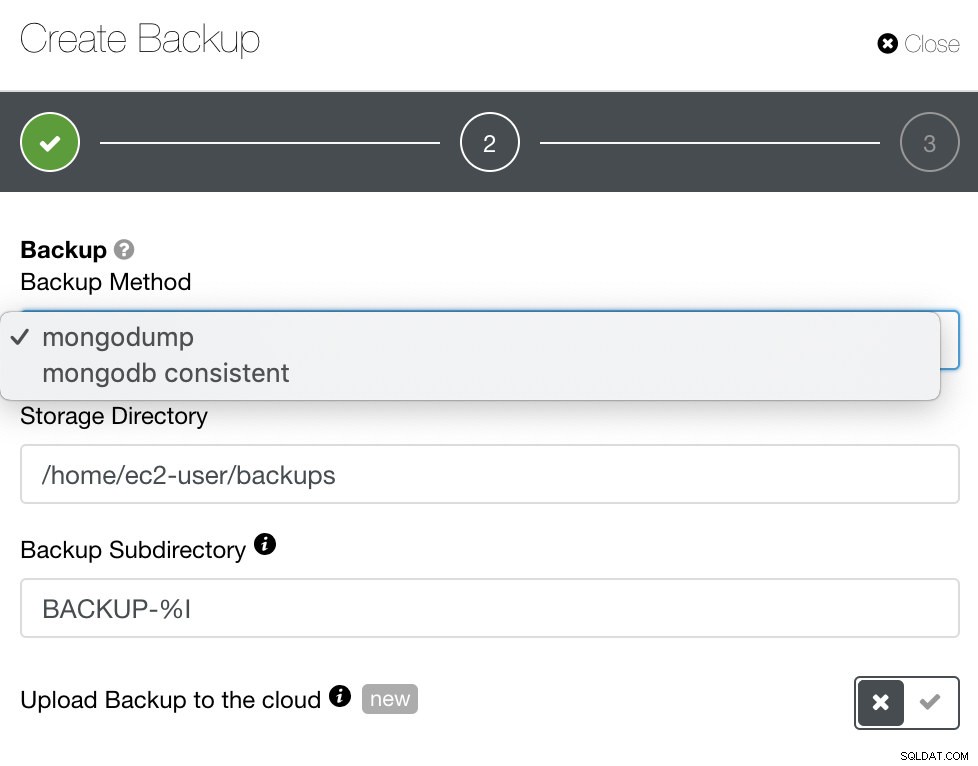
W przypadku MongoDB ClusterControl oferuje spójność mongodump lub mongodb. Być może będziesz musiał zauważyć, że mongodb spójne nie obsługuje RHEL 7, ale możesz zainstalować go ręcznie.
Domyślnie ClusterControl wyświetli raport dla wszystkich kopii zapasowych, które zostały wykonane, udane lub nieudane. Zobacz poniżej:
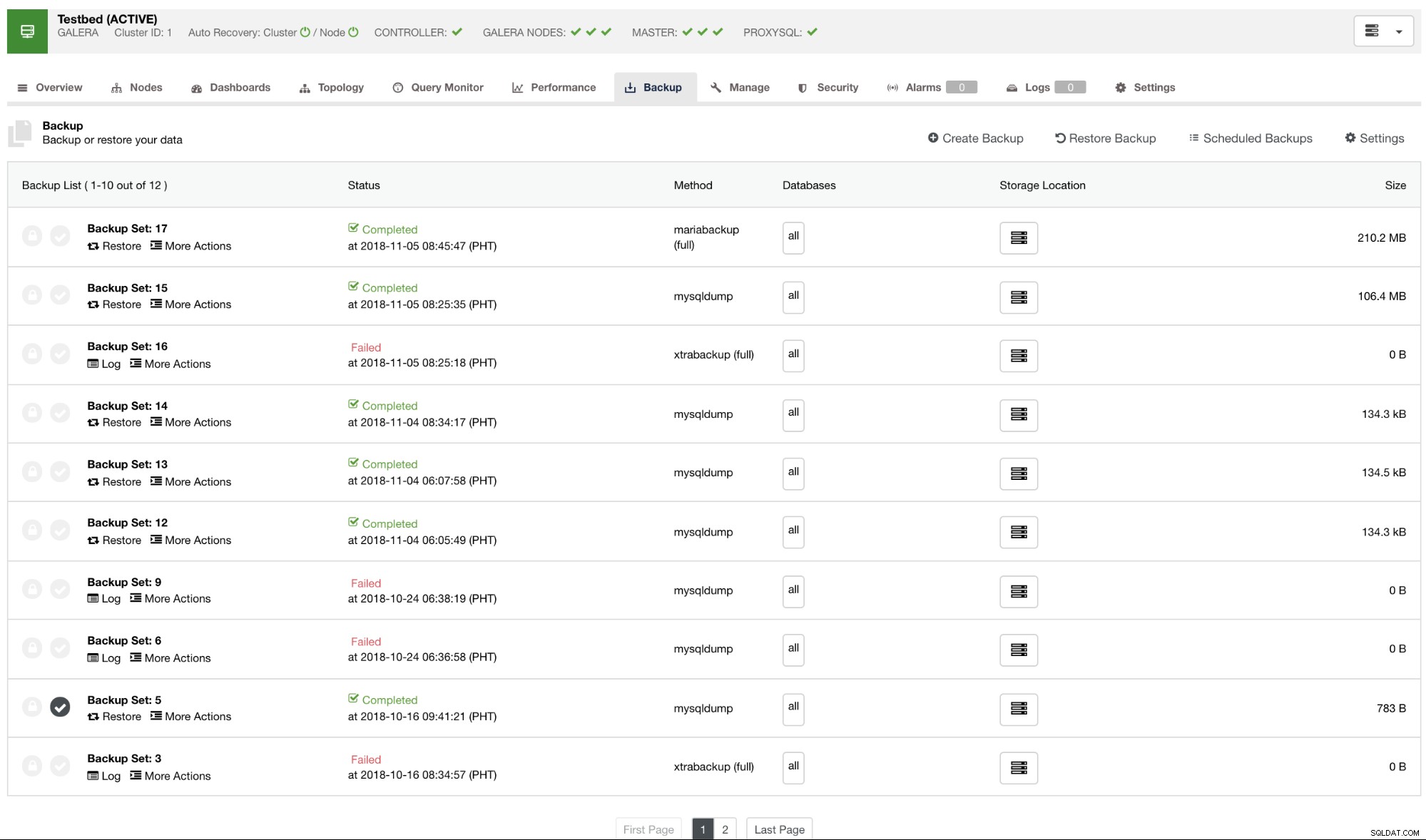
Możesz sprawdzić listę raportów kopii zapasowych, które zostały utworzone lub zaplanowane za pomocą ClusterControl. Na liście możesz przeglądać dzienniki w celu dalszego badania i diagnozy. Na przykład, jeśli kopia zapasowa została ukończona poprawnie zgodnie z żądanymi zasadami tworzenia kopii zapasowych, czy kompresja i szyfrowanie są ustawione poprawnie lub czy żądany rozmiar danych kopii zapasowej jest poprawny. To dobry sposób na szybkie sprawdzenie poprawności — jeśli Twój zestaw danych ma rozmiar około 1 GB, nie ma mowy, aby pełna kopia zapasowa mogła być tak mała, jak 100 KB — w pewnym momencie coś musiało pójść nie tak.
Odzyskiwanie po awarii
Przechowywanie kopii zapasowych w klastrze (bezpośrednio w węźle bazy danych lub na hoście ClusterControl) przydaje się, gdy chcesz szybko przywrócić dane:wszystkie pliki kopii zapasowych są na swoim miejscu i można je szybko zdekompresować i przywrócić. Jeśli chodzi o odzyskiwanie po awarii (DR), może to nie być najlepsza opcja. Mogą się zdarzyć różne problemy - serwery mogą ulec awarii, sieć może nie działać niezawodnie, nawet całe centra danych mogą być niedostępne z powodu jakiegoś rodzaju awarii. Może się to zdarzyć, niezależnie od tego, czy pracujesz z mniejszym dostawcą usług z jednym centrum danych, czy globalnym dostawcą, takim jak Amazon Web Services. Dlatego trzymanie wszystkich jajek w jednym koszyku nie jest bezpieczne – powinieneś upewnić się, że masz kopię zapasową przechowywaną w jakiejś zewnętrznej lokalizacji. ClusterControl obsługuje Amazon S3, Google Storage i Azure Cloud Storage.
Dla tych, którzy chcieliby wdrożyć własne zasady DR, kopie zapasowe ClusterControl są przechowywane w ładnie ustrukturyzowanym katalogu. Masz również możliwość przesłania kopii zapasowej do chmury. Zobacz obrazek poniżej:
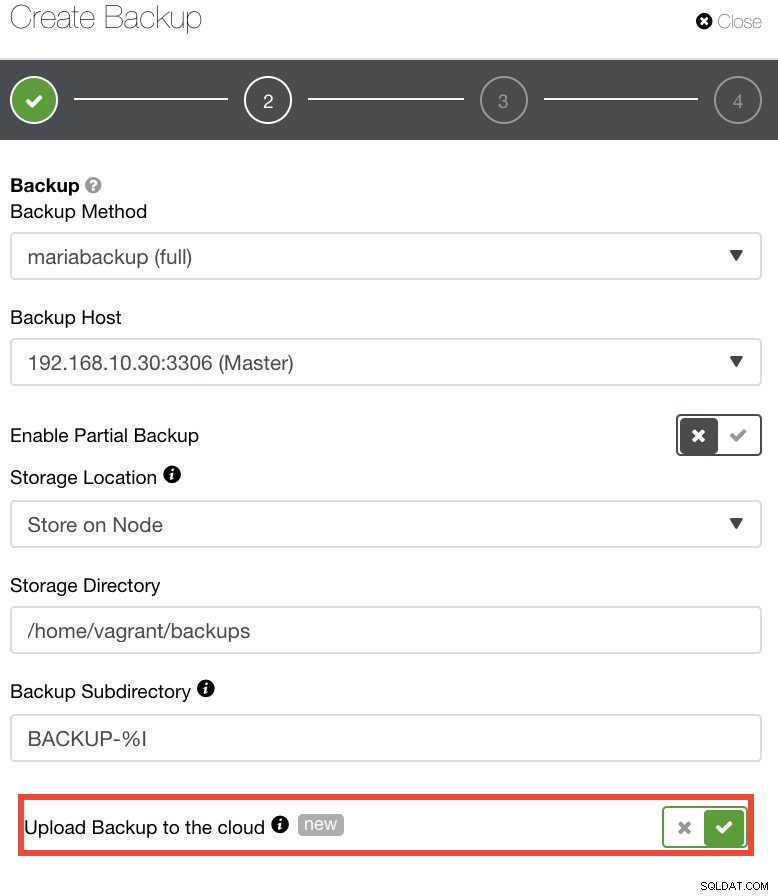
Możesz wybrać i przesłać do Amazon Web Services, Google Cloud i Microsoft Azure. Zobacz obrazek poniżej:
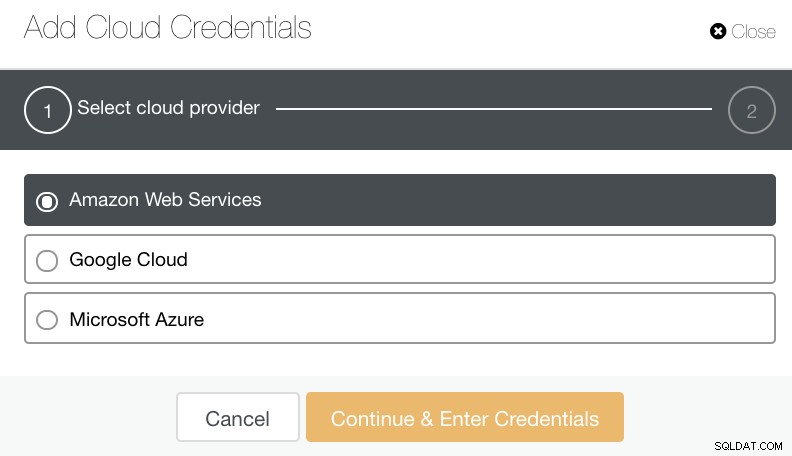
Dobrą praktyką podczas archiwizowania kopii zapasowych bazy danych jest upewnienie się, że docelowa chmura docelowa znajduje się w tym samym regionie co serwery baz danych lub przynajmniej najbliżej. Upewnij się, że oferuje wysoką dostępność, trwałość i skalowalność; ponieważ musisz zastanowić się, jak często i natychmiast potrzebujesz swoich danych.
Oprócz tworzenia logicznej lub fizycznej kopii zapasowej dla DR, utworzenie pełnej migawki danych (np. przy użyciu migawki LVM, migawek Amazon EBS lub migawek woluminów w przypadku korzystania z systemu plików Veritas) w określonym węźle może zwiększyć odzyskiwanie kopii zapasowej. Możesz również użyć WAL (dla Postgres) do odzyskiwania punktu w czasie (PITR) lub dzienników binarnych MySQL dla swojego PITR. Dlatego musisz wziąć pod uwagę, że być może będziesz musiał stworzyć własną archiwizację dla swojego PITR. Dlatego doskonale jest budować i wdrażać własny zestaw skryptów i obsługiwać DR zgodnie z dokładnymi wymaganiami.
Innym świetnym sposobem na wdrożenie zasad odzyskiwania po awarii jest użycie asynchronicznego urządzenia podrzędnego replikacji — o czym wspomnieliśmy wcześniej w tym poście na blogu. Możesz wdrożyć takie asynchroniczne urządzenie podrzędne w zdalnej lokalizacji, być może w innym centrum danych, a następnie użyć go do tworzenia kopii zapasowych i przechowywania ich lokalnie na tym urządzeniu podrzędnym. Oczywiście warto wykonać lokalną kopię zapasową klastra, aby mieć ją lokalnie, jeśli zajdzie potrzeba odzyskania klastra. Przenoszenie danych między centrami danych może zająć dużo czasu, więc posiadanie plików kopii zapasowych dostępnych lokalnie może zaoszczędzić trochę czasu. W przypadku utraty dostępu do głównego klastra produkcyjnego, nadal możesz mieć dostęp do urządzenia podrzędnego. Ta konfiguracja jest bardzo elastyczna — po pierwsze, masz działający host MySQL z danymi produkcyjnymi, więc wdrożenie pełnej aplikacji w witrynie DR nie powinno być zbyt trudne. Będziesz mieć również kopie zapasowe danych produkcyjnych, których możesz użyć do skalowania środowiska DR.
Wreszcie i co najważniejsze, kopia zapasowa, która nie została przetestowana, pozostaje niezweryfikowaną kopią zapasową, czyli Schroedinger Backup. Aby upewnić się, że masz działającą kopię zapasową, musisz wykonać test odzyskiwania. ClusterControl oferuje sposób na automatyczną weryfikację i testowanie kopii zapasowej.
Mamy nadzieję, że dostarczy to wystarczających informacji, aby stworzyć bezpieczną i niezawodną procedurę tworzenia kopii zapasowych dla baz danych o otwartym kodzie źródłowym.



