Konserwacja to coś, czego zespół operacyjny nie może uniknąć. Serwery muszą nadążać za najnowszym oprogramowaniem, sprzętem i technologią, aby zapewnić stabilność systemów i działanie z możliwie najmniejszym ryzykiem, przy jednoczesnym korzystaniu z nowszych funkcji w celu poprawy ogólnej wydajności.
Niewątpliwie istnieje długa lista zadań konserwacyjnych, które muszą wykonać administratorzy systemów, zwłaszcza jeśli chodzi o systemy krytyczne. Niektóre zadania muszą być wykonywane w regularnych odstępach czasu, np. codziennie, co tydzień, co miesiąc i co rok. Niektóre trzeba zrobić od razu, pilnie. Niemniej jednak żadna operacja konserwacyjna nie powinna prowadzić do innego większego problemu, a każda konserwacja musi być wykonywana ze szczególną ostrożnością, aby uniknąć jakichkolwiek przerw w działalności.
Otrzymywanie wątpliwego stanu i fałszywych alarmów jest powszechne podczas konserwacji. Jest to oczekiwane, ponieważ w okresie konserwacji serwer nie będzie działał tak, jak powinien, dopóki zadanie konserwacji nie zostanie zakończone. ClusterControl, kompleksowa platforma do zarządzania i monitorowania baz danych typu open source, może zostać skonfigurowana tak, aby zrozumieć te okoliczności i uprościć procedury konserwacji, bez poświęcania funkcji monitorowania i automatyzacji, które oferuje.
Tryb konserwacji
ClusterControl wprowadził tryb konserwacji w wersji 1.4.0, w którym można umieścić pojedynczy węzeł w trybie konserwacji, co uniemożliwia ClusterControl zgłaszanie alarmów i wysyłanie powiadomień przez określony czas. Tryb konserwacji można skonfigurować z ClusterControl UI, a także za pomocą narzędzia ClusterControl CLI o nazwie „s9s”. W interfejsie przejdź do Węzły -> wybierz węzeł -> Akcje węzła -> Zaplanuj tryb konserwacji :
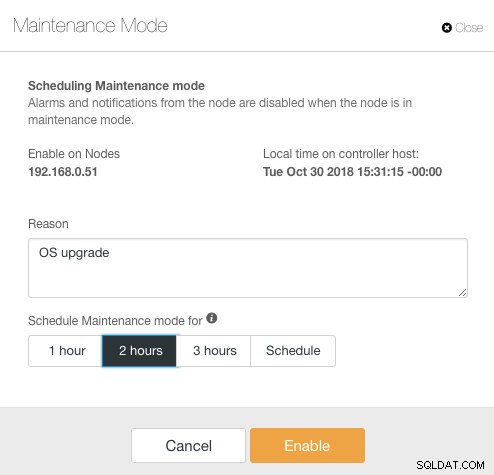
Tutaj można ustawić okres konserwacji na wcześniej zdefiniowany czas lub odpowiednio go zaplanować. Możesz również zapisać przyczynę zaplanowania aktualizacji, co jest przydatne do celów audytu. Gdy tryb konserwacji jest aktywny, powinno zostać wyświetlone następujące powiadomienie:
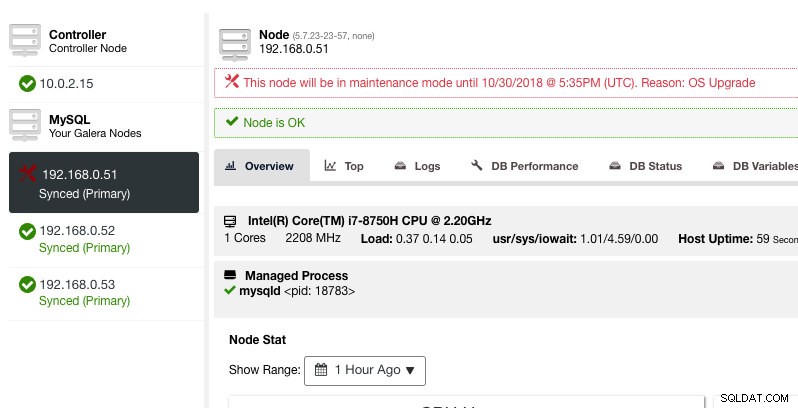
ClusterControl nie degraduje węzła, dlatego stan węzła pozostaje niezmieniony, chyba że wykonasz jakąkolwiek czynność, która zmieni stan. Alarmy i powiadomienia dla tego węzła zostaną ponownie aktywowane po zakończeniu okresu konserwacji lub po wyłączeniu go przez operatora, przechodząc do Akcje węzła -> Wyłącz tryb konserwacji .
Zwróć uwagę, że jeśli włączone jest automatyczne odzyskiwanie węzła, ClusterControl zawsze odzyska węzeł, niezależnie od stanu trybu konserwacji. Nie zapomnij wyłączyć odzyskiwania węzłów, aby uniknąć zakłócania przez program ClusterControl zadań konserwacji, można to zrobić z górnego paska podsumowania.
Tryb konserwacji można również skonfigurować za pomocą ClusterControl CLI lub „s9s”. Możesz użyć polecenia „konserwacja s9s”, aby wyświetlić i manipulować okresami konserwacji. Poniższy wiersz poleceń zaplanuje jednogodzinne okno konserwacji na jutro dla węzła 192.168.1.121:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Więcej szczegółów i przykładów można znaleźć w dokumentacji konserwacji s9s.
Tryb konserwacji dla całego klastra
W chwili pisania tego tekstu konfiguracja trybu konserwacji musi być skonfigurowana dla każdego węzła zarządzanego. W przypadku konserwacji całego klastra należy powtórzyć proces planowania dla każdego zarządzanego węzła klastra. Może to być niepraktyczne, jeśli masz dużą liczbę węzłów w klastrze lub jeśli interwał konserwacji jest bardzo krótki między dwoma zadaniami.
Na szczęście ClusterControl CLI (znany również jako s9s) może być używany jako obejście w celu przezwyciężenia tego ograniczenia. Możesz użyć „węzłów s9s”, aby wyświetlić listę węzłów zarządzanych w klastrze i manipulować nimi. Tę listę można powtarzać, aby zaplanować tryb konserwacji dla całego klastra w określonym czasie za pomocą polecenia „s9s maintenance”.
Spójrzmy na przykład, aby lepiej to zrozumieć. Rozważmy następujący trzywęzłowy klaster Percona XtraDB, który mamy:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Klaster ma łącznie 4 węzły — 3 węzły bazy danych z jednym węzłem ClusterControl. Pierwsza kolumna, STAT, pokazuje rolę i status węzła. Pierwszy znak to rola węzła - „c” oznacza kontroler, a „g” oznacza węzeł bazy danych Galera. Załóżmy, że chcemy zaplanować konserwację tylko węzłów bazy danych, możemy odfiltrować dane wyjściowe, aby uzyskać nazwę hosta lub adres IP, gdzie raportowany STAT ma „g” na początku:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Dzięki prostej iteracji możemy zaplanować okno konserwacji dla całego klastra dla każdego węzła w klastrze. Następujące polecenie iteruje tworzenie konserwacji w oparciu o wszystkie adresy IP znalezione w klastrze przy użyciu pętli for, gdzie planujemy rozpocząć operację konserwacji jutro o tej samej godzinie i zakończyć godzinę później:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bPowinieneś zobaczyć wydruk 3 UUID, unikalnego ciągu identyfikującego każdy okres konserwacji. Następnie możemy zweryfikować za pomocą następującego polecenia:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Z powyższych danych wyjściowych otrzymaliśmy listę zaplanowanych czasów konserwacji dla każdego węzła bazy danych. W zaplanowanym czasie ClusterControl nie będzie zgłaszać alarmów ani wysyłać powiadomień, jeśli wykryje nieprawidłowości w klastrze.
Iteracja trybu konserwacji
Niektóre procedury konserwacyjne muszą być wykonywane w regularnych odstępach czasu, np. tworzenie kopii zapasowych, sprzątanie i zadania porządkowe. W czasie konserwacji oczekiwalibyśmy, że serwer będzie zachowywał się inaczej. Jednak każda awaria usługi, chwilowa niedostępność lub duże obciążenie z pewnością spowodowałyby spustoszenie w naszym systemie monitoringu. W przypadku częstych i krótkich przerw konserwacyjnych może to być bardzo denerwujące, a pomijanie podnoszonych fałszywych alarmów może zapewnić lepszy sen w nocy.
Jednak włączenie trybu konserwacji może również narazić serwer na większe ryzyko, ponieważ ścisłe monitorowanie jest przez pewien czas ignorowane. Dlatego prawdopodobnie dobrym pomysłem jest zrozumienie charakteru operacji konserwacyjnej, którą chcielibyśmy wykonać przed włączeniem trybu konserwacji. Poniższa lista kontrolna powinna pomóc nam określić nasze zasady dotyczące trybu konserwacji:
- Dotknięte węzły – które węzły są zaangażowane w konserwację?
- Konsekwencje — Co dzieje się z węzłem, gdy trwa konserwacja? Czy będzie niedostępny, mocno obciążony lub zrestartowany?
- Czas trwania — Ile czasu zajmuje wykonanie czynności konserwacyjnej?
- Częstotliwość — Jak często powinna być wykonywana konserwacja?
Umieśćmy to w przypadku użycia. Rozważmy, że mamy trzywęzłowy klaster Percona XtraDB z węzłem ClusterControl. Załóżmy, że wszystkie nasze serwery działają na maszynach wirtualnych, a zasady tworzenia kopii zapasowych maszyn wirtualnych wymagają tworzenia kopii zapasowych wszystkich maszyn wirtualnych codziennie, począwszy od godziny 1:00, po jednym węźle na raz. Podczas tej operacji tworzenia kopii zapasowej węzeł zostanie zamrożony na maksymalnie około 10 minut, a węzeł zarządzany i monitorowany przez ClusterControl będzie niedostępny do czasu zakończenia tworzenia kopii zapasowej. Z perspektywy klastra Galera ta operacja nie powoduje wyłączenia całego klastra, ponieważ klaster pozostaje w kworum i nie ma to wpływu na główny komponent.
W zależności od charakteru zadania konserwacyjnego możemy je podsumować w następujący sposób:
- Dotknięte węzły - Wszystkie węzły dla klastra o identyfikatorze 1 (3 węzły bazy danych i 1 węzeł ClusterControl).
- Konsekwencja — maszyna wirtualna, której kopia zapasowa jest tworzona, będzie niedostępna do czasu zakończenia.
- Czas trwania — każda operacja tworzenia kopii zapasowej maszyny wirtualnej zajmuje około 5 do 10 minut.
- Częstotliwość — tworzenie kopii zapasowej maszyny wirtualnej jest zaplanowane codziennie, począwszy od godziny 1:00 w pierwszym węźle.
Następnie możemy opracować plan wykonania, aby zaplanować nasz tryb konserwacji:
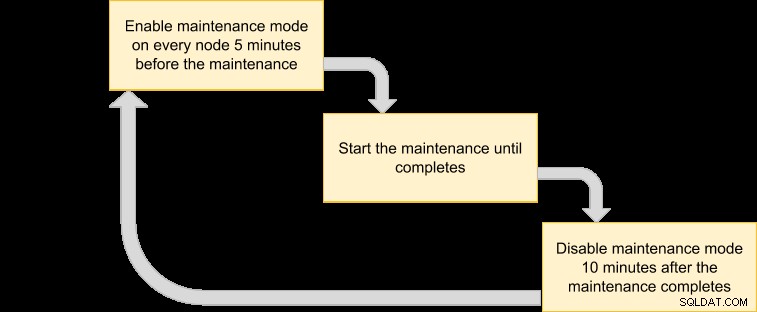
Ponieważ chcemy, aby wszystkie węzły w klastrze były archiwizowane przez menedżera VM, po prostu wypisz węzły dla odpowiedniego identyfikatora klastra:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Powyższe dane wyjściowe mogą służyć do planowania konserwacji w całym klastrze. Na przykład, jeśli uruchomisz następujące polecenie, ClusterControl aktywuje tryb konserwacji dla wszystkich węzłów w klastrze o identyfikatorze 1 od teraz do następnych 50 minut:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneKorzystając z powyższego polecenia, możemy przekonwertować go do pliku wykonawczego, umieszczając go w skrypcie. Utwórz plik:
$ vim /usr/local/bin/enable_maintenance_modeI dodaj następujące wiersze:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneZapisz go i upewnij się, że uprawnienia do pliku są wykonywane:
$ chmod 755 /usr/local/bin/enable_maintenance_modeNastępnie użyj crona, aby zaplanować uruchamianie skryptu codziennie od 5 minut do 1:00, tuż przed rozpoczęciem operacji tworzenia kopii zapasowej maszyny wirtualnej o 1:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeZaładuj ponownie demona crona, aby upewnić się, że nasz skrypt jest umieszczany w kolejce:
$ systemctl reload crond # or service crond reloadOtóż to. Możemy teraz wykonywać nasze codzienne czynności konserwacyjne bez narażania się na fałszywe alarmy i powiadomienia pocztą do czasu zakończenia konserwacji.
Dodatkowa funkcja konserwacji — Pomijanie odzyskiwania węzła
Po włączeniu automatycznego odzyskiwania ClusterControl jest wystarczająco inteligentny, aby wykryć awarię węzła i spróbuje odzyskać uszkodzony węzeł po 30-sekundowym okresie karencji, niezależnie od stanu trybu konserwacji. Czy wiesz, że ClusterControl można skonfigurować tak, aby celowo pomijał odzyskiwanie węzła dla konkretnego węzła? Może to być bardzo pomocne, gdy musisz przeprowadzić pilną konserwację bez znajomości czasu i wyniku konserwacji.
Na przykład wyobraź sobie, że doszło do uszkodzenia systemu plików, a po twardym restarcie wymagane jest sprawdzenie i naprawa systemu plików. Trudno z góry określić, ile czasu zajęłoby wykonanie tej operacji. W ten sposób możemy po prostu użyć pliku flagi, aby zasygnalizować ClusterControl, aby pominął odzyskiwanie węzła.
Najpierw dodaj następujący wiersz w /etc/cmon.d/cmon_X.cnf (gdzie X to identyfikator klastra) w węźle ClusterControl:
node_recovery_lock_file=/root/do_not_recoverNastępnie uruchom ponownie usługę cmon, aby załadować zmianę:
$ systemctl restart cmon # service cmon restartNa koniec upewnij się, że określony plik znajduje się w węźle, który chcemy pominąć w celu odzyskania ClusterControl:
$ touch /root/do_not_recoverNiezależnie od stanu trybu automatycznego odzyskiwania i konserwacji, ClusterControl odzyska węzeł tylko wtedy, gdy ten plik flagi nie istnieje. Administrator jest wtedy odpowiedzialny za tworzenie i usuwanie pliku w węźle bazy danych.
To wszystko, ludzie. Miłej konserwacji!



