Audyt to monitorowanie i rejestrowanie wybranych działań w bazie danych użytkowników. Jest zwykle używany do badania podejrzanych działań lub monitorowania i gromadzenia danych o określonych działaniach w bazie danych. Na przykład administrator bazy danych może gromadzić statystyki dotyczące aktualizowanych tabel, liczby wykonywanych operacji lub liczby jednoczesnych użytkowników łączących się w określonym czasie.
W tym wpisie na blogu omówimy podstawowe aspekty audytu naszych systemów baz danych typu open source, w szczególności MySQL, MariaDB, PostgreSQL i MongoDB. Ten artykuł jest skierowany do inżynierów DevOps, którzy zwykle mają mniejsze doświadczenie lub mniejsze narażenie w zakresie najlepszych praktyk audytu zgodności i dobrego zarządzania danymi podczas zarządzania infrastrukturą głównie dla systemów baz danych.
Kontrola wyciągów
Kontrola instrukcji MySQL
MySQL ma ogólny dziennik zapytań (lub general_log), który zasadniczo rejestruje, co robi mysqld. Serwer zapisuje informacje w tym dzienniku, gdy klienci łączą się lub rozłączają, i rejestruje każdą instrukcję SQL otrzymaną od klientów. Ogólny dziennik zapytań może być bardzo przydatny podczas rozwiązywania problemów, ale nie jest przeznaczony do ciągłej inspekcji. Ma duży wpływ na wydajność i powinien być włączany tylko w krótkich przedziałach czasowych. Istnieją inne możliwości użycia tabel performance_schema.events_statements* lub wtyczki audytu.
Kontrola instrukcji PostgreSQL
Dla PostgreSQL, możesz ustawić log_statment na "all". Obsługiwane wartości tego parametru to none (off), ddl, mod i all (wszystkie instrukcje). W przypadku „ddl” rejestrowane są wszystkie instrukcje definicji danych, takie jak instrukcje CREATE, ALTER i DROP. W przypadku „mod” rejestruje wszystkie instrukcje DDL oraz instrukcje modyfikujące dane, takie jak INSERT, UPDATE, DELETE, TRUNCATE i COPY FROM.
Prawdopodobnie musisz skonfigurować powiązane parametry, takie jak log_directory, log_filename, logging_collector i log_rotation_age, jak pokazano w poniższym przykładzie:
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_statement = 'all'
logging_collector = on
log_rotation_age = 10080 # 1 week in minutes Powyższe zmiany wymagają ponownego uruchomienia PostgreSQL, więc prosimy o dokładne zaplanowanie przed zastosowaniem w środowisku produkcyjnym. Następnie możesz znaleźć bieżące logi w katalogu pg_log. W przypadku PostgreSQL 12 lokalizacja to /var/lib/pgsql/12/data/pg_log/ . Zwróć uwagę, że pliki dziennika mają tendencję do znacznego rozrostu w czasie i mogą znacznie zajmować miejsce na dysku. Możesz również użyć log_rotation_size zamiast tego, jeśli masz ograniczoną przestrzeń dyskową.
Kontrola wyciągów MongoDB
W przypadku MongoDB istnieją 3 poziomy rejestrowania, które mogą nam pomóc w kontroli instrukcji (operacji lub operacji w terminie MongoDB):
-
Poziom 0 — jest to domyślny poziom profilera, na którym profiler nie zbiera żadnych danych. Mongod zawsze zapisuje w swoim dzienniku operacje dłuższe niż próg slowOpThresholdMs.
-
Poziom 1 — zbiera dane profilowania tylko dla powolnych operacji. Domyślnie powolne operacje to te, które trwają dłużej niż 100 milisekund. Możesz zmodyfikować próg dla „wolnych” operacji za pomocą opcji środowiska uruchomieniowego slowOpThresholdMs lub polecenia setParameter.
-
Poziom 2 — zbiera dane profilowania dla wszystkich operacji na bazie danych.
Aby rejestrować wszystkie operacje, ustaw db.setProfilingLevel(2, 1000), gdzie powinien profilować wszystkie operacje z operacjami, które trwają dłużej niż zdefiniowane milisekundy, w tym przypadku to 1 sekunda (1000 ms) . Zapytanie do wyszukania w kolekcji profili systemowych wszystkich zapytań, które zajęły więcej niż jedną sekundę, uporządkowanych malejąco według sygnatury czasowej, będzie. Aby odczytać operacje, możemy użyć następującego zapytania:
mongodb> db.system.profile.find( { millis : { $gt:1000 } } ).sort( { ts : -1 } )Ponadto istnieje projekt Mongotail, który upraszcza proces profilowania operacji za pomocą zewnętrznego narzędzia, zamiast kierować zapytania bezpośrednio do kolekcji profili.
Należy pamiętać, że nie jest zalecane przeprowadzanie pełnego audytu instrukcji na produkcyjnych serwerach baz danych, ponieważ często ma to znaczący wpływ na usługę bazy danych przy ogromnej liczbie rejestrów. Zalecanym sposobem jest użycie wtyczki audytu bazy danych (jak pokazano poniżej), która zapewnia standardowy sposób tworzenia dzienników audytu, często wymaganych do zgodności z certyfikatami rządowymi, finansowymi lub ISO.
Kontrola uprawnień dla MySQL, MariaDB i PostgreSQL
Inspekcja uprawnień kontroluje uprawnienia i kontrolę dostępu do obiektów bazy danych. Kontrola dostępu zapewnia, że użytkownicy uzyskujący dostęp do bazy danych są pozytywnie zidentyfikowani i mogą uzyskiwać dostęp, aktualizować lub usuwać dane, do których są uprawnieni. Ten obszar jest często pomijany przez inżynierów DevOps, co sprawia, że nadmierne uprzywilejowanie jest częstym błędem podczas tworzenia i przyznawania użytkownikowi bazy danych.
Przykłady nadmiernie uprzywilejowanych to:
-
Host dostępu użytkownika jest dozwolony z bardzo szerokiego zakresu, na przykład przyznanie hosta użytkownika example@sqldat.com' %', zamiast indywidualnego adresu IP.
-
Uprawnienia administracyjne przypisywane do nieadministracyjnych użytkowników bazy danych, na przykład przypisywany jest użytkownik bazy danych dla aplikacji z uprawnieniami SUPER lub RELOAD.
-
Brak kontroli zasobów przed wszelkiego rodzaju nadmiernym wykorzystaniem, takim jak Maksymalna liczba połączeń użytkowników, Maksymalna liczba zapytań na godzinę lub Maksymalna liczba Połączenia na godzinę.
-
Zezwól określonym użytkownikom bazy danych również na dostęp do innych schematów.
W przypadku MySQL, MariaDB i PostgreSQL można przeprowadzić kontrolę uprawnień za pomocą schematu informacyjnego, odpytując tabele dotyczące przyznania, ról i uprawnień. W przypadku MongoDB użyj następującego zapytania (wymaga działania viewUser dla innych baz danych):
mongodb> db.getUsers( { usersInfo: { forAllDBs: true } } )ClusterControl zapewnia ładne podsumowanie uprawnień przypisanych do użytkownika bazy danych. Przejdź do Zarządzaj -> Schematy i użytkownicy -> Użytkownicy, a otrzymasz raport o uprawnieniach użytkowników wraz z opcjami zaawansowanymi, takimi jak Wymaga SSL, Maksymalna liczba połączeń na godzinę i tak dalej.
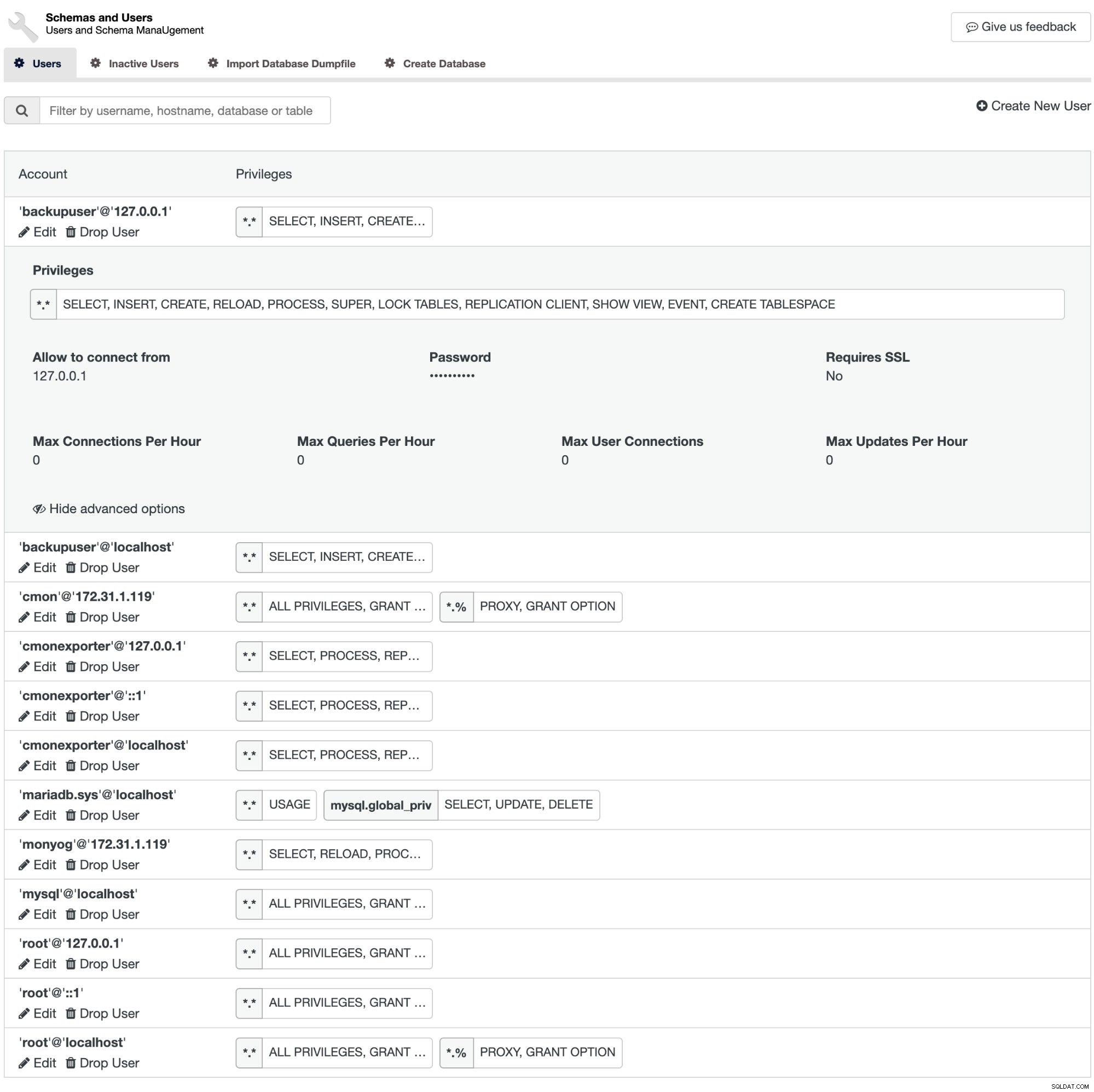
ClusterControl obsługuje kontrolę uprawnień dla MySQL, MariaDB i PostgreSQL dla tego samego użytkownika berło.
Kontrola obiektów schematu
Obiekty schematu to logiczne struktury tworzone przez użytkowników. Przykładami obiektów schematu są tabele, indeksy, widoki, procedury, zdarzenia, procedury, funkcje, wyzwalacze i inne. Zasadniczo są to obiekty, które przechowują dane lub mogą składać się tylko z definicji. Zwykle przeprowadza się audyt uprawnień związanych z obiektami schematu, aby wykryć słabe ustawienia bezpieczeństwa i zrozumieć relacje i zależności między obiektami.
W przypadku MySQL i MariaDB istnieją schematy_informacyjne i schemat_wydajności, których możemy użyć do przeprowadzenia zasadniczo audytu obiektów schematu. Performance_schema to nieco głębia w instrumentacji, jak sama nazwa wskazuje. Jednak MySQL zawiera również schemat sys od wersji 5.7.7, który jest przyjazną dla użytkownika wersją performance_schema. Wszystkie te bazy danych są bezpośrednio dostępne i dostępne dla klientów.
Wtyczki/rozszerzenia audytu bazy danych
Najbardziej zalecanym sposobem przeprowadzania audytu wyciągów jest użycie wtyczki audytu lub rozszerzenia, stworzonego specjalnie dla używanej technologii baz danych. MariaDB i Percona mają własną implementację wtyczki Audit, która nieco różni się od wtyczki Audit MySQL dostępnej w MySQL Enterprise. Rekordy inspekcji zawierają informacje o operacji, która została poddana inspekcji, użytkownik wykonujący operację oraz datę i godzinę operacji. Rekordy mogą być przechowywane w tabeli słownika danych, zwanej ścieżką audytu bazy danych, lub w plikach systemu operacyjnego, zwanej ścieżką audytu systemu operacyjnego.
W przypadku PostgreSQL istnieje pgAudit, rozszerzenie PostgreSQL, które zapewnia szczegółowe rejestrowanie audytu sesji i/lub obiektów za pośrednictwem standardowego narzędzia rejestrowania PostgreSQL. Jest to w zasadzie ulepszona wersja funkcji log_statement PostgreSQL z możliwością łatwego wyszukiwania i wyszukiwania przechwyconych danych do audytu, postępując zgodnie ze standardowym dziennikiem audytu.
MongoDB Enterprise (płatny) i Percona Server dla MongoDB (bezpłatny) zawierają funkcję audytu dla instancji mongod i mongos. Po włączeniu audytu serwer będzie generował komunikaty audytu, które można zalogować do sysloga, konsoli lub pliku (format JSON lub BSON). W większości przypadków lepiej jest logować się do pliku w formacie BSON, gdzie wpływ na wydajność jest mniejszy niż JSON. Ten plik zawiera informacje o różnych zdarzeniach użytkownika, w tym o uwierzytelnianiu, błędach autoryzacji i tak dalej. Sprawdź dokumentację audytu, aby uzyskać szczegółowe informacje.
Ścieżki audytu systemu operacyjnego
Ważne jest również skonfigurowanie ścieżek audytu systemu operacyjnego. W przypadku Linuksa ludzie zwykle używaliby auditd. Auditd jest komponentem przestrzeni użytkownika Linux Auditing System i odpowiada za zapisywanie rekordów kontroli na dysku. Przeglądanie logów odbywa się za pomocą narzędzi ausearch lub aureport. Konfigurowanie reguł audytu odbywa się za pomocą narzędzia auditctl lub bezpośrednio modyfikując pliki reguł.
Poniższe kroki instalacji są naszą powszechną praktyką podczas konfigurowania dowolnego rodzaju serwerów do użytku produkcyjnego:
$ yum -y install audit # apt install auditd python
$ mv /etc/audit/rules.d/audit.rules /etc/audit/rules.d/audit.rules.ori
$ cd /etc/audit/rules.d/
$ wget https://gist.githubusercontent.com/ashraf-s9s/fb1b674e15a5a5b41504faf76a08b4ae/raw/2764bf0e9bf25418bb86e33c13fb80356999d220/audit.rules
$ chmod 640 audit.rules
$ systemctl daemon-reload
$ systemctl start auditd
$ systemctl enable auditd
$ service auditd restartZauważ, że ponowne uruchomienie usługi auditd ostatniej linii jest obowiązkowe, ponieważ audyt nie działa zbyt dobrze podczas ładowania reguł za pomocą systemd. Jednak systemd nadal jest wymagany do monitorowania usługi auditd. Podczas uruchamiania reguły w /etc/audit/audit.rules są odczytywane przez auditctl. Sam demon audytu ma kilka opcji konfiguracyjnych, które administrator może chcieć dostosować. Można je znaleźć w pliku auditd.conf.
Poniższy wiersz jest wynikiem pobranym ze skonfigurowanego dziennika kontroli:
$ ausearch -m EXECVE | grep -i 'password' | head -1
type=EXECVE msg=audit(1615377099.934:11838148): argc=7 a0="mysql" a1="-NAB" a2="--user=appdb1" a3="--password=S3cr3tPassw0rdKP" a4="-h127.0.0.1" a5="-P3306" a6=2D6553484F5720474C4F42414C205641524941424C4553205748455245205641524941424C455F4E414D4520494E20282776657273696F6E272C202776657273696F6E5F636F6D6D656E74272C2027646174616469722729Jak widać z powyższego, łatwo jest wykryć hasło w postaci zwykłego tekstu dla MySQL ("--password=S3cr3tPassw0rdKP") przy użyciu narzędzia ausearch, tak jak zostało to przechwycone przez auditd. Ten rodzaj wykrywania i audytu jest niezbędny do zabezpieczenia naszej infrastruktury baz danych, gdzie hasło w postaci zwykłego tekstu jest niedopuszczalne w bezpiecznym środowisku.
Ostateczne myśli
Dziennik lub ścieżka audytu to istotny aspekt, który często jest pomijany przez inżynierów DevOps podczas zarządzania infrastrukturą i systemami, nie mówiąc już o systemie baz danych, który jest bardzo krytycznym systemem do przechowywania wrażliwych i poufnych danych. Jakiekolwiek ujawnienie lub naruszenie Twoich prywatnych danych może być niezwykle szkodliwe dla firmy i nikt nie chciałby, aby tak się stało w obecnej erze technologii informatycznych.



