Tworzenie prawidłowych kopii zapasowych bazy danych jest zadaniem krytycznym. Oprócz ustawienia architektury wysokiej dostępności MongoDB dla usług baz danych, musisz także mieć kopie zapasowe swoich baz danych, aby zapewnić dostępność danych w przypadku awarii. Na przykład, jeśli przypadkowo usuniesz niektóre dane z produkcyjnej bazy danych, jedynym sposobem na odzyskanie danych z punktu widzenia bazy danych jest przywrócenie z kopii zapasowej.
Niedawno ClusterControl zaczął wspierać nową metodę tworzenia kopii zapasowych o nazwie Percona Backup for MongoDB, opracowaną przez firmę Percona. Może uruchamiać spójne kopie zapasowe zestawów replik MongoDB i klastrów podzielonych na fragmenty.
W tym blogu przyjrzymy się zarządzaniu kopiami zapasowymi zestawów replik MongoDB i klastrów podzielonych na fragmenty.
Kopia zapasowa MongoDB w architekturze o wysokiej dostępności
ClusterControl obsługuje 3 metody tworzenia kopii zapasowych:mongodump, mongodb spójne i Percona Backup for Mongodb. Spójna kopia zapasowa mongodb wykorzystuje narzędzie mongodump jako metodę tworzenia kopii zapasowej, a kopię zapasową można przywrócić za pomocą mongorestore.
Najnowszą obsługiwaną metodą tworzenia kopii zapasowych jest Percona Backup for Mongodb, która zapewnia spójne i punktowe kopie zapasowe zestawów replik i klastrów podzielonych na fragmenty. Wymaga ona uruchomienia agenta na każdym węźle lub zestawie replik lub węzłach fragmentów i węzłach zarządzania dla klastrów odłamków, jak opisano tutaj.
Konfigurowanie i planowanie spójnego tworzenia kopii zapasowych przy użyciu Percona Backup for Mongodb w ClusterControl jest bardzo łatwe. Przejdź do strony Kopia zapasowa, a następnie skonfiguruj kopię zapasową Percona dla Mongodb. Warunkiem wstępnym jest uruchomienie Percona Backup for MongoDB na każdym węźle, który można również zainstalować z ClusterControl.
Musimy najpierw zainstalować agenta Percona Backup for MongoDB, zanim będzie można zaplanować tworzenie kopii zapasowej, jak poniżej:
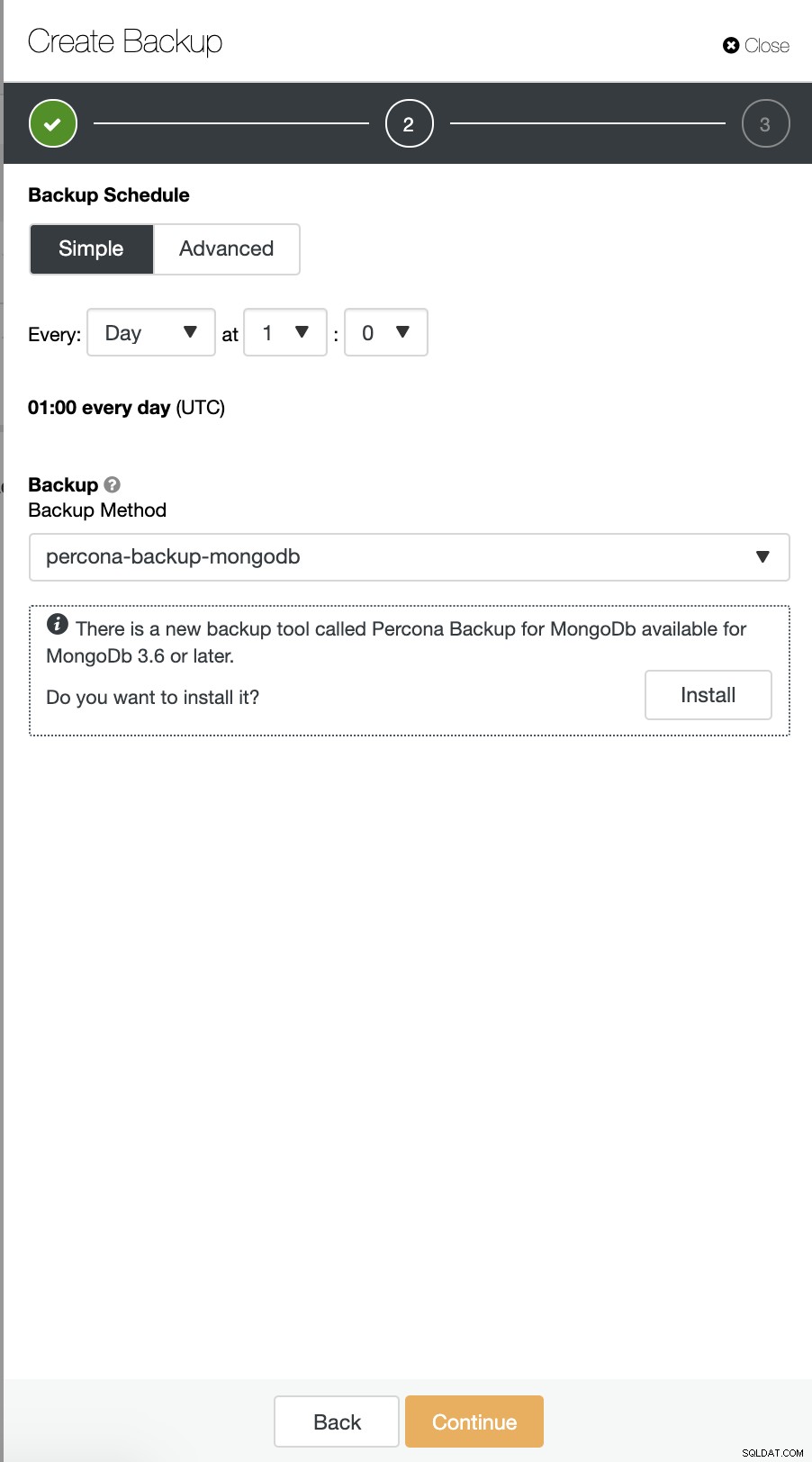
A następnie skonfiguruj katalog kopii zapasowej. Zwróć uwagę, że katalog kopii zapasowej musi być współdzielonym dyskiem, który został zamontowany na wszystkich węzłach z dokładnie taką samą ścieżką jak poniżej:
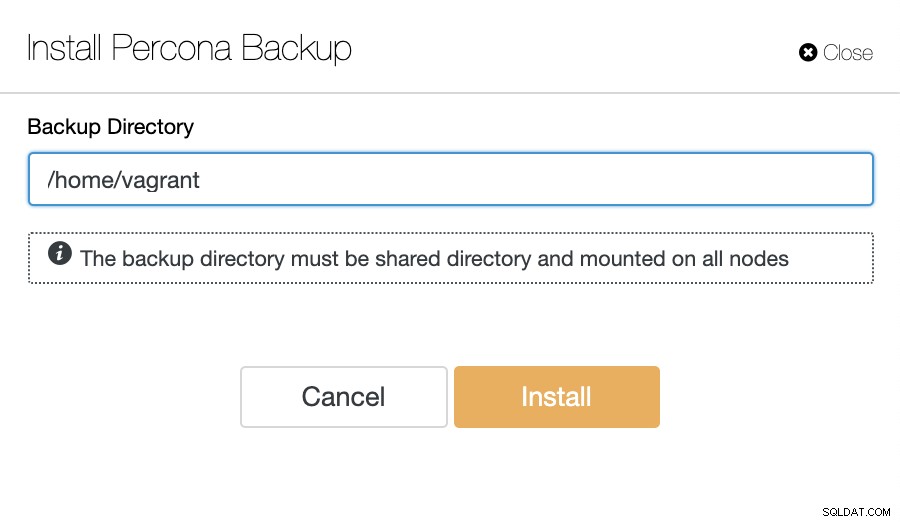
Jeśli nie masz w systemie żadnego udostępnionego dysku, możesz użyć NFS, aby to osiągnąć. Do konfiguracji serwera NFS potrzebujemy dedykowanego serwera / maszyny wirtualnej z wystarczającą ilością wolnego miejsca do przechowywania kopii zapasowej. Zainstaluj bibliotekę nfs-utils i nfs-utils-lib na serwerze jak poniżej (zakładając, że używamy opartego na CentOS):
[example@sqldat.com ~]# yum install nfs-utils nfs-utils-lib
[example@sqldat.com ~]# yum install portmapI uruchom usługi portmap i nfs.
[example@sqldat.com ~]# /etc/init.d/portmap start
[example@sqldat.com ~]# /etc/init.d/nfs startNastępnie dodaj nowe wpisy w /etc/exports, jak pokazano poniżej:
[example@sqldat.com ~]# vi /etc/exports
/backup 10.10.10.11(rw,sync,no_root_squash)W węźle bazy danych wystarczy zamontować dysk pamięci jako pamięć współdzieloną.
Ostatnia rzecz, po prostu kliknij przycisk instalacji i uruchomi nowe zadanie konfiguracji agenta na każdym węźle.

Po zainstalowaniu całego programu PBM ggent możemy skonfigurować metodę tworzenia kopii zapasowej klaster jak poniżej:

Fizyczna a logiczna kopia zapasowa
Kopia zapasowa MongoDB obsługuje logiczną i fizyczną kopię zapasową. Metoda tworzenia logicznej kopii zapasowej przy użyciu narzędzia mongodump jest uwzględniana podczas instalowania pakietu mongodb. Mongodump potrzebuje dostępu do bazy danych mongodb, dlatego wymaga dostępu do poświadczeń dla mongodump z uprawnieniami do tworzenia kopii zapasowych i musi mieć akcję grant find, aby wykonać kopię zapasową bazy danych.
Działa dla formatów zrzutu danych BSON. Mongodump połączy się z Twoją bazą danych z podanymi danymi uwierzytelniającymi, odczyta wszystkie dane w Twojej bazie danych i zrzuci dane do plików. Ponieważ jest to proces jednowątkowy, tworzenie kopii zapasowej zajmie więcej czasu, zwłaszcza w przypadku dużej bazy danych. Mongodump nie zachowuje atomowości transakcji we shardach, dlatego nie może być używany jako strategia tworzenia kopii zapasowych dla mongodb w wersji 4.2 i nowszych w klastrze shardowanym. Percona Backup for MongoDB to logiczna kopia zapasowa, ale obsługuje spójne kopie zapasowe klastrów.
Fizyczna kopia zapasowa w MongoDB działa poprzez migawkę systemów plików mongodb, kopiując podstawowe pliki mongodb do innej lokalizacji jako podstawową kopię zapasową bazy danych mongodb. Migawka systemu plików to system operacyjny, jeśli używasz LVM (Menedżera woluminów logicznych) jako oprogramowania do zarządzania układem dysku i urządzeniem lub urządzeniem programowym, np. Veritas lub NetApp Backup. Musisz włączyć kronikowanie, dziennik aktywności zmian w mongodb przed uruchomieniem migawki systemu plików, aby zapewnić spójność kopii zapasowej.
Oprócz migawki systemu plików, możesz również użyć polecenia cp lub rsync do skopiowania plików danych MongoDB, ale musisz zatrzymać proces zapisu do mongodb, ponieważ proces kopiowania plików danych nie jest operacją niepodzielną. Kopia zapasowa nie może być używana do odzyskiwania punktu w czasie w zestawach replik lub architekturach klastra podzielonego na fragmenty.
Percona Backup for MongoDB składa się z dwóch komponentów:agenta pbm, który należy zainstalować na każdym węźle, oraz pbm jako interfejsu wiersza poleceń do interakcji i uruchamiania kopii zapasowych. Współrzędne agenta pbm między węzły bazy danych oraz uruchomienie procesu tworzenia kopii zapasowej i przywracania. Agent pbm wybierze najlepszy węzeł do wykonania kopii zapasowej.
Kopia zapasowa PITR
W wielu systemach baz danych często używa się punktu kontrolnego w celu umieszczenia danych na dysku. MongoDB wykorzystuje silnik pamięci WiredTiger jako domyślny silnik pamięci, a także wykorzystuje punkty kontrolne, aby zapewnić spójny widok danych. Co więcej, punkt kontrolny w MongoDB może być użyty do odzyskania z ostatniego punktu kontrolnego. Kronikowanie działa między każdym punktem kontrolnym. Kronikowanie jest wymagane w celu odzyskania sprawności po nieoczekiwanych awariach, które mają miejsce w dowolnym momencie między punktami kontrolnymi. Kronikowanie gwarantuje, że operacje zapisu są rejestrowane na dysku, MongoDB utworzy wpis dziennika dla każdej zmiany, w tym zmienionych bajtów i lokalizacji dysku.
Mongodump i mongorestore mogą być używane do tworzenia kopii zapasowych odzyskiwania do punktu w czasie, istnieje możliwość wykorzystania oploga. Oplog to ograniczona kolekcja w MongoDB, która śledzi wszystkie zmiany w kolekcjach dla każdej transakcji zapisu (np. wstawianie, aktualizowanie, usuwanie). Tak więc, jeśli chcesz wykonać odzyskiwanie do określonego momentu, musisz przywrócić dane z ostatniej pełnej kopii zapasowej, a także użyć pliku oplog, aby zastosować zmiany dokładnie w czasie, w którym chcesz odzyskać. Innym narzędziem, którego można użyć, jest Percona Backup for MongoDB, proces jest podobny do mongodump, musimy przywrócić z kopii zapasowej, a następnie zastosować oplog.
Wnioski
Wykonywanie spójnej kopii zapasowej jest ważne, szczególnie w klastrowych konfiguracjach MongoDB (zestaw replik lub klaster sharded). ClusterControl zapewnia łatwy sposób konfiguracji kopii zapasowej Percona dla MongoDB w klastrze i planowania tworzenia kopii zapasowych.



