Wprowadzenie:ten przykład demonstrujestarszą metodę wykorzystania IRI RowGen do generowania i wypełniania dużych lub złożonych prototypów kolekcji do testowania lub pojemności systemu przy użyciu płaskich plików. Jak przeczytasz, RowGen utworzy niezbędne dane testowe i utworzy plik CSV, który zostanie załadowany do MongoDB za pomocą narzędzia importu Mongo.
Aktualizacja 2019:IRI oferuje teraz również Obsługa JSON i bezpośredniego sterownika do przenoszenia danych między kolekcjami MongoDB i kompatybilnymi z SortCL produktami IRI, takimi jak RowGen lub FieldShield. Oznacza to, że możesz użyć RowGen do wygenerowania testowych plików JSON do zaimportowania do MongoDB (podobnie jak metoda pokazana poniżej w tym artykule) lub użyć FieldShield do zamaskowania danych w tabelach Mongo w cele testowe.
Pamiętaj, że zarówno FieldShield, jak i RowGen są zawarte w platformie zarządzania danymi IRI Vorcity, która oferuje cztery sposoby tworzenia danych testowych.
Chociaż MongoDB jest dobrą, wieloplatformową, zorientowaną na dokumenty bazą danych NoSQL, nie ma wygodnego sposobu generowania i wypełniania dużych lub złożonych prototypów kolekcji, które można wykorzystać do testowania zapytań lub planowania wydajności. W tym artykule wyjaśniono, jak tworzyć dane testowe, których MongoDB może używać za pośrednictwem IRI RowGen, określając parametry dla syntetycznego, ale realistycznego pliku CSV, który MongoDB może zaimportować do testów funkcjonalnych i wydajnościowych.
Najpierw musisz wziąć pod uwagę strukturę i zawartość danych testowych na potrzeby swojej kolekcji (tabela MongoDB). Zobacz ten artykuł, aby poznać typowe kwestie związane z planowaniem.
W tym przykładzie wiemy, że nasza kolekcja będzie składać się z klientów, którzy mają nazwy użytkownika , Imię i nazwisko , Adresy e-mail i Numery kart kredytowych .
Aby utworzyć dane testowe, musimy najpierw wygenerować kilka zestawów plików. Plik zestawu to lista jednej lub więcej wartości rozdzielonych tabulatorami, które mogą już istnieć lub muszą być wygenerowane ręcznie lub automatycznie z kolumn bazy danych za pomocą kreatora „Generuj nowy plik zestawu” w IRI RowGen.
Generowanie nazw
1) Utwórz złożoną wartość danych (łącznie imię i nazwisko) skrypt zadania o nazwie „CreateNamesSet.rcl”, który RowGen może wykonać w celu utworzenia pliku zestawu; wywołaj dane wyjściowe „User.set”, ponieważ te nazwy będą również używane jako podstawa naszych nazw użytkowników.
2) Utwórz trzy pola do wygenerowania w Names.set:nazwisko, separator tabulacji i imię. Nazwij pierwsze pole „LastName” i wybierz metodę, która wybierze wartości z dostarczonego przez IRI pliku zestawu o nazwie „names_last.set”. Dodaj wartość literału „\t”, aby dodać separator tabulacji, a następnie powtórz proces używany dla wartości LastName i FirstName, używając names_first.set.
3) Uruchom CreateNamesSet.rcl z RowGen, albo w wierszu poleceń, albo z GUI IRI Workbench, aby utworzyć plik User.set rozdzielony tabulatorami z imionami i nazwiskami, które będą używane w zarówno podczas generowania nazw użytkowników, jak i w końcowej wersji pliku testowego, który wypełnia naszą kolekcję prototypów.

Generowanie nazw użytkowników
W przypadku nazw użytkowników utworzymy plik zestawu, który wykorzystuje wygenerowany powyżej plik Users.set. Nazwy użytkownika w tym przykładzie będą składać się z nazwiska, inicjału imienia i losowo wygenerowanej liczby z zakresu od 100 do 999.
1) Utwórz nowy skrypt zadania RowGen za pomocą Kreatora złożonych danych, nazwij go „CreateUsernamesSet.rcl” i nazwij plik zestawu wyjściowego „Usernames.set”.
2) Utwórz złożone wartości nazwy użytkownika z trzema komponentami o nazwach Part1, Part2 i Part3.
3) W przypadku części 1 wybierz metodę, która wybierze wartości z (przejdź do) wcześniej wygenerowanego pliku User.set i określ „WSZYSTKO” jako typ wyboru, aby zachować powiązanie między użytkownikami. nazwy użytkowników i adresy e-mail. Ustaw rozmiar na 5.
4) W przypadku Części 2 powtórz proces zastosowany dla Części 1, z wyjątkiem typu Zaznaczenie, wybierz „Wiersz” i ustaw Indeks kolumny na 2. Ustaw rozmiar na 1. Gwarantuje to, że zostaną użyte wszystkie nazwiska w generacji, a pierwsza litera imienia w tym samym wierszu jest dołączona do nazwy użytkownika.
5) W przypadku Części 3 określ generowanie wartości liczbowej z zakresu od 100 do 999, aby dodać losową liczbę całkowitą do każdej nazwy użytkownika.
Po wykonaniu CreateUsernamesSet.rcl widzimy, że każda nazwa użytkownika zawiera pięć pierwszych liter jego nazwiska, następnie inicjał pierwszego, a następnie losową 3-cyfrową liczbę:
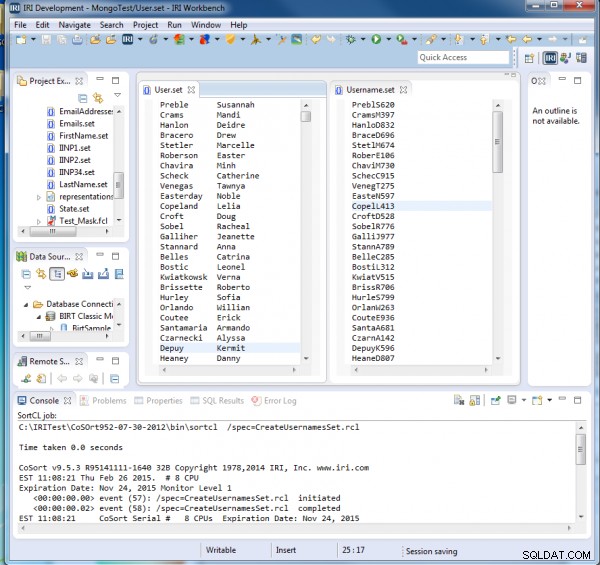
Generowanie e-maili
Następnie utworzymy plik zestawu e-maili, który dołącza wartości nazwy użytkownika do losowo wybranych nazw domen. Ponieważ niektóre usługi poczty e-mail są bardziej popularne niż inne, utworzymy również system wag, aby odzwierciedlić wyższą częstotliwość domen Yahoo i Gmail.
1) Uruchom kreatora zadań „Nowe niestandardowe dane testowe” RowGen, aby utworzyć zadanie o nazwie „CreateEmailsSet”, które tworzy plik zestawu o nazwie „Emails.set”.
2) Utwórz część nazwy użytkownika wiadomości e-mail. W oknie dialogowym Definicja danych testowych kliknij Nowe pole i zmień nazwę pierwszego pola Nazwy użytkowników. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generation Field i „Define …” jego plik Ustaw jako Usernames.set. Ustaw rozmiar na 9 i kliknij OK.
3) Utwórz część wiadomości e-mail dotyczącą domeny (która zawiera symbol @). W oknie dialogowym Pola układu kliknij Nowe pole i zmień jego nazwę na „adres” i kliknij je dwukrotnie. W oknie dialogowym Generation Field określ „ ” z pozycją 10 i rozmiarem 20. W sekcji Data Generation / Data Distribution poniżej kliknij „Define …”, aby nazwać nową dystrybucję danych pozycji „WeightedEmails”.
4) W Kreatorze nowej dystrybucji wybierz „Ważony rozkład elementów” i wprowadź te elementy odpowiednio w polach proporcji i literalnych pól tekstowych, a następnie dodaj je do listy.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
Po wpisaniu tych wartości kliknij Dalej w oryginalnym kreatorze, aby przejść do okna dialogowego Cele danych. Użyj „Dodaj cel danych…”, aby określić plik wyjściowy „Email.set”. Będzie to również używane w czasie budowania kolekcji.
E-mail, dla którego ustawiliśmy najwyższe wagi (gmail i yahoo), pojawia się najczęściej, a inne pojawiają się okresowo.

Generowanie numerów kart kredytowych
Na koniec utworzymy prawidłowe pod względem obliczeniowym numery kart w formacie XXXX-XXXX-XXXX-XXXX. Pierwsze cztery cyfry odzwierciedlają rzeczywiste numery identyfikacyjne (IIN) różnych wystawców kart kredytowych, a ostatnia cyfra weryfikuje autentyczność kart.
W tym celu utwórz i uruchom nowe (puste) zadanie. Nazwij go „CreateCCNSet.rcl” (lub .scl) i wypełnij go poniższym skryptem, aby utworzyć „CCN.set”. Wartość /INCOLLECT w skryptach RowGen określa liczbę wygenerowanych wierszy.

W celu wypełnienia tego pola wywoływana jest specjalna funkcja generowania CCN RowGen, ccn_gen („ANY, „-”). Pamiętaj, że podobne funkcje istnieją dla amerykańskich i koreańskich numerów ubezpieczenia społecznego oraz krajowych dowodów tożsamości Włoch i Holandii.
Tworzenie końcowego pliku testowego
Po zbudowaniu wszystkich zestawów plików nadszedł czas, aby użyć ich w testowym pliku CSV, który utworzymy i wyeksportujemy do kolekcji MongoDB.
1) Uruchom kreatora zadań RowGen „Nowe niestandardowe dane testowe”, aby utworzyć zadanie o nazwie „CreateMongoUserData.rcl”, które wygeneruje plik Customers.csv, który następnie wyeksportujemy do MongoDB.
2) Kliknij „Pola układu…”, aby przejść do okna dialogowego pól układu. Kliknij Nowe pole i zmień nazwę pierwszego pola na Nazwy użytkowników. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generation Field i „Define …” jego plik Ustaw jako Usernames.set; następnie wybierz WSZYSTKIE jako typ wyboru.
3) Kliknij Nowe pole i zmień nazwę drugiego pola na Nazwiska. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generation Field i „Define …” jego plik Ustaw jako Users.set; następnie wybierz WSZYSTKIE jako typ wyboru.
4) Kliknij Nowe pole i zmień nazwę trzeciego pola na Imię. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generation Field i „Define …” jego plik Ustaw jako Users.set; następnie wybierz ROWS jako typ wyboru i ustaw indeks kolumny na 2.
5) Kliknij Nowe pole i zmień nazwę czwartego pola na E-mail. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generowanie pola i „Definiuj…” jego plik Ustaw jako Emails.set; następnie wybierz WSZYSTKIE jako typ wyboru.
6) Kliknij Nowe pole i zmień nazwę piątego pola na CreditCardNumbers. Kliknij go dwukrotnie, aby uruchomić okno dialogowe Generation Field i „Define …” jego plik Set jako CCN.set; następnie wybierz WSZYSTKIE jako typ wyboru.
7) Po wprowadzeniu tych wartości kliknij Dalej w oryginalnym kreatorze, aby przejść do okna dialogowego Cele danych. Użyj opcji „Dodaj miejsce docelowe danych…”, aby określić plik wyjściowy Customers.csv; następnie uruchom skrypt w środowisku roboczym lub w wierszu poleceń, aby wygenerować ten plik:
rowgen /spec=CreateMongoUserData.rcl

Zauważ, że RowGen, oprócz tworzenia tego pliku CSV w czasie wykonywania, mógł również wygenerować wiele innych plików, bazy danych, sformatowanego raportu, nazwanego potoku, proceduralnego, a nawet wyświetlania BIRT w czasie rzeczywistym , z polami z wygenerowanych danych testowych, wszystkie w tym samym czasie.
Importowanie do MongoDB
Aby zaimportować plik CSV do bazy danych Mongo, wywołaj „narzędzie mongoimport” i uruchom następujące polecenie:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Oto rekordy w kolekcji testów (pokazane za pomocą MongoVUE), które MongoDB automatycznie zindeksuje z wygenerowanymi wartościami identyfikatorów dla każdego wpisu:
MongoDB przypisuje unikalny identyfikator do każdego wpisu kolekcji.
Możesz także załadować dane testowe bezpośrednio do bazy danych Mongo za pomocą sterownika DataDirect ODBC firmy Progress Software dla MongoDB. Przed uruchomieniem zadania RowGen w Workbench miałem pustą kolekcję o nazwie CUSTOMERS_CNN w MYDB, aby otrzymać dane.
Najpierw uruchomiłem zadanie używając stdout, aby wyświetlić podgląd moich danych testowych w oknie konsoli:

Po wykonaniu skryptu w środowisku roboczym mogę teraz zobaczyć swoje dane za pomocą Eksploratora źródeł danych i sterownika DataDirect JDBC.

Aby uzyskać więcej informacji na temat dostępnych opcji generowania, zobacz Test File Targets sekcja pod adresem: https://www.iri.com/products/rowgen/technical-details.



