TL;DR:mongoengine spędza wieki na konwersji wszystkich zwróconych tablic na dyktanda
Aby to przetestować, zbudowałem kolekcję z dokumentem z DictField z dużym zagnieżdżonym dict . Dokument jest mniej więcej w twoim zakresie 5-10 MB.
Następnie możemy użyć timeit.timeit
aby potwierdzić różnicę w odczytach za pomocą pymongo i mongoengine.
Następnie możemy użyć pycallgraph i GraphViz żeby zobaczyć, co tak cholernie długo zajmuje mongoengine.
Oto pełny kod:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
Wyniki pokazują, że mongoengine jest bardzo powolny w porównaniu do pymongo:
pymongo took 0.87s
mongoengine took 25.81118331072267
Wynikowy wykres połączeń dość wyraźnie pokazuje, gdzie jest szyjka butelki:
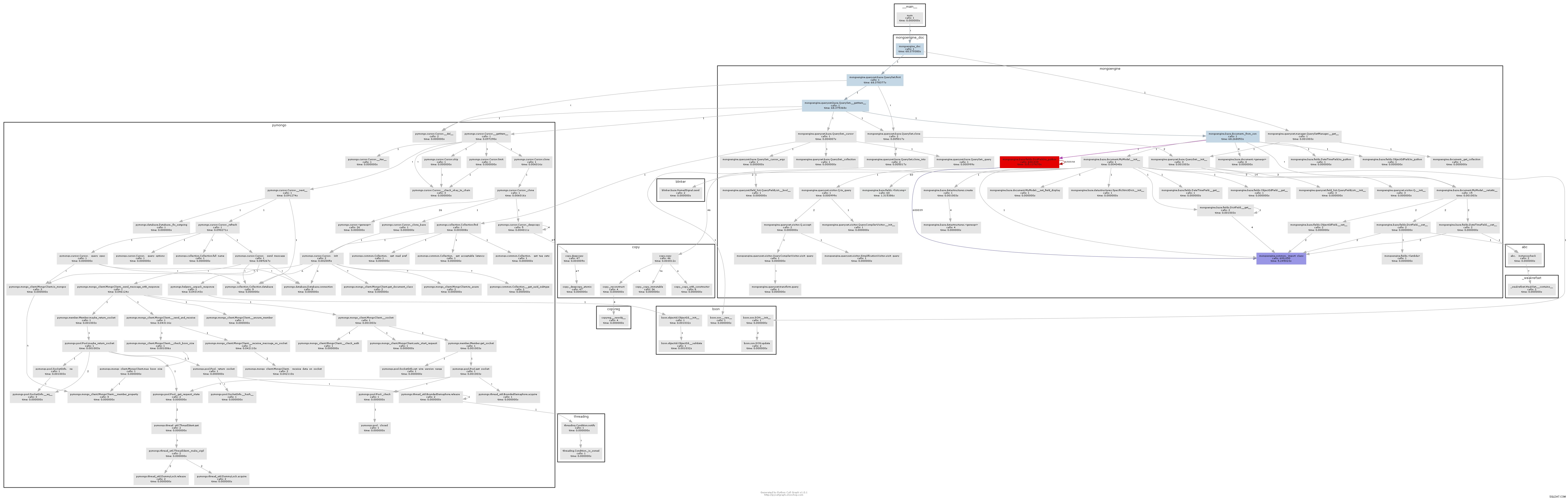
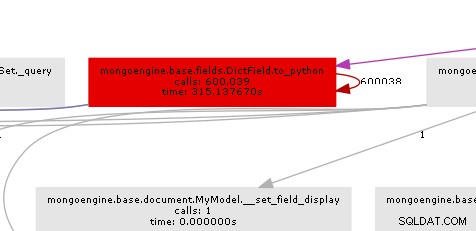
Zasadniczo mongoengine wywoła metodę to_python na każdym DictField że wraca z db. to_python jest dość powolny i w naszym przykładzie jest wywoływany szaloną liczbę razy.
Mongoengine służy do eleganckiego mapowania struktury dokumentu na obiekty Pythona. Jeśli masz bardzo duże nieustrukturyzowane dokumenty (do których mongodb jest świetny), to mongoengine nie jest tak naprawdę właściwym narzędziem i powinieneś po prostu użyć pymongo.
Jeśli jednak znasz strukturę, możesz użyć EmbeddedDocument pola, aby uzyskać nieco lepszą wydajność z mongoengine. Przeprowadziłem podobny, ale nie równoważny test kod w tym tekście
a wynik to:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Możesz więc sprawić, że mongoengine będzie szybszy, ale pymongo jest jeszcze szybszy.
AKTUALIZUJ
Dobrym skrótem do interfejsu pymongo jest użycie struktury agregacji:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]