Gdzie przechowujemy obrazy?
Rozwiązanie nr 1 w MongoDB
Więc pierwszym rozwiązaniem jest przechowywanie obrazów wewnątrz MongoDB. Może pomieścić pliki graficzne lub dowolny typ pliku. Możesz więc wziąć plik i powiązać go z rekordem w MongoDB i zapisać go bezpośrednio w swojej bazie danych.
Dzięki temu podejściu powiązanie strony z opisem konkretnego artykułu odzieżowego z odpowiadającym mu obrazem staje się łatwe, ponieważ możesz umieścić ten obraz bezpośrednio w rozwoju tej strony, a Twój klient byłby zadowolony z takiego podejścia, ponieważ gdy użytkownik pobierze szczegółowy opis strona tego artykułu, na którym znajduje się obraz.
To jedno z możliwych rozwiązań, po prostu weź obraz i zapisz go bezpośrednio w MongoDB.
Zasugeruję jednak, że to złe podejście. Powodem tego jest to, że możesz powiedzieć swojemu klientowi w przypadku odmowy, ponieważ zazwyczaj płaci on za instancję Mongo pod względem ilości pamięci używanej przez jego kopię Mongo.
Im więcej miejsca zużywają, tym więcej płacą miesięcznie.
Na przykład, kiedy ostatnio sprawdzałem użycie MLab, pobierali 15 USD za GB. To 15 USD z kieszeni klientów za przechowywanie obrazów o wartości 1 GB.
W przypadku kolejnej witryny e-commerce mówimy o 3 GB easy, co przekłada się na mniej więcej 330 obrazów, równo 15 USD miesięcznie.
Jeśli więc jeden z kierowników projektu przesyła raz dziennie nowy artykuł odzieżowy, bardzo szybko mówimy o ogromnych kosztach.
Osobiście uważam więc, że przechowywanie wszelkiego rodzaju plików bezpośrednio w MongoDB naprawdę nie jest opcją, ponieważ będzie to bardzo kosztowne.
To tylko jedno z możliwych rozwiązań.
Rozwiązanie nr 2 w jakości HD podłączone do serwera
Spójrzmy więc na drugie rozwiązanie, które może być dla Ciebie dostępne. Możesz użyć dysku twardego, który jest powiązany z serwerem Express. Więc kiedy ta aplikacja zostanie wdrożona w jakimś środowisku chmury, takim jak Heroku, Digital Ocean, Linode lub AWS, zwykle otrzymujesz dysk twardy powiązany z Twoją aplikacją.
Więc może bierzesz obrazy i umieszczasz je na lokalnym dysku twardym. Za takim podejściem będzie opowiadać się zdecydowana większość postów i artykułów online:
Jak przesyłać, wyświetlać i zapisywać obrazy za pomocą node.js i express
https://appdividend. com/2019/02/14/node-express-image-upload-and-resize-tutorial-example/
https://medium.com/@nitinpatel_20236/image-upload -via-nodejs-server-3fe7d3faa642
Tylko z trzema, które zebrałem powyżej, masz całkiem solidny plan na początek.
Każdy mówi, że weź plik i zapisz go na lokalnym dysku twardym. W tym konkretnym artykule:
https://alligator.io/nodejs/uploading-files-multer-express/
pokazują ten kod:
const storage = multer.diskStorage({
destination: 'some-destination',
filename: function (req, file, callback) {
//..
}
});
Używają biblioteki przesyłania obrazów o nazwie multer który zapewnia diskStorage() silnik do przesyłania obrazów na dysk.
Jest to więc jedno podejście, z którym zgadza się cała społeczność programistów.
To dobre podejście w kontekście mapowania jeden do jednego.
Problemy z tym podejściem zaczynają się pojawiać, gdy mamy wiele maszyn.
Przykładem tego jest sytuacja, gdy masz wiele maszyn hostowanych na Digital Ocean lub Linode, gdzie każde środowisko jest osobną instancją.
Jeśli masz wszystkie swoje obrazy przechowywane na dołączonym dysku twardym, a następnie zaczniesz skalować serwer w górę, każdy z nich będzie miał osobny dysk twardy.
Możesz więc otrzymać żądanie, które przychodzi przez system równoważenia obciążenia, a system równoważenia obciążenia decyduje, dokąd wysłać żądanie, aby polubić poniższy diagram:
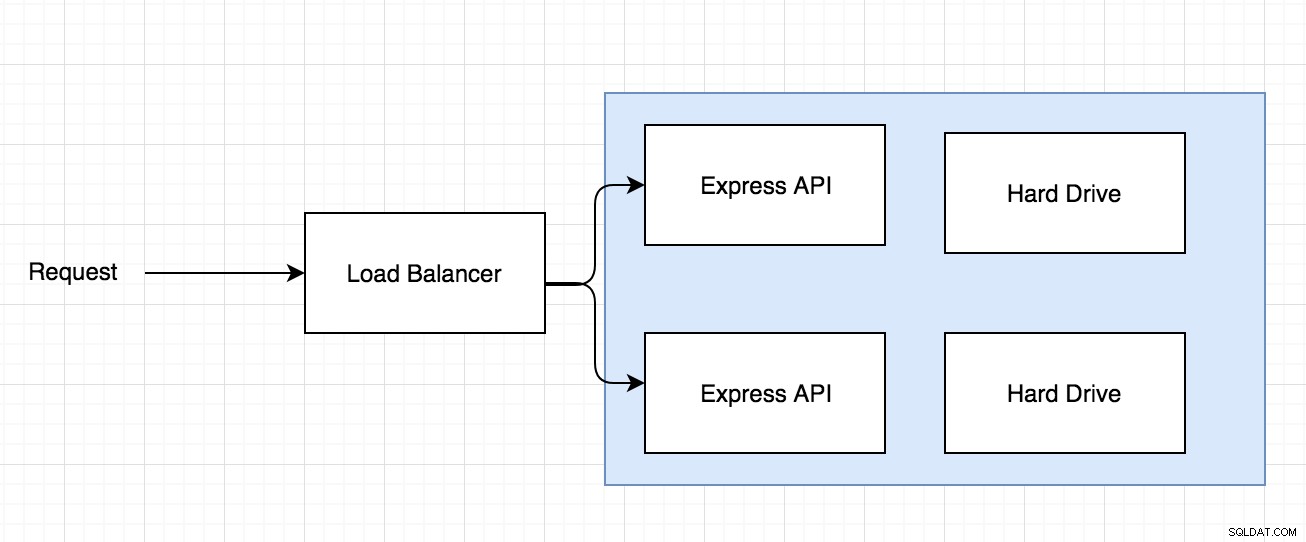
Problem z powyższą architekturą polega na tym, że obraz zostanie zapisany na jednym z dwóch dysków twardych, a następnie pojawi się żądanie dostępu do tego samego obrazu, ale wyobraź sobie, że żądanie jest kierowane do innego serwera Express z innym dyskiem twardym gdzie obraz nie istnieje.
Jest to problem, który pojawia się, gdy zaczynasz korzystać z usług dostawcy takiego jak Linode lub Digital Ocean, gdzie masz mapowanie jeden do jednego między serwerem a dyskiem twardym.
Jest to rozwiązanie krótkoterminowe, jeśli na razie to wszystko, czego potrzebujesz, ale gdy aplikacja zacznie się skalować, będzie to problem.
Rozwiązanie nr 3 poza magazynem danych
To trzecie rozwiązanie jest tym, z którego korzystałem w przeszłości z aplikacjami React with Node i Ruby on Rails. W rzeczywistości moja witryna portfolio Ruby on Rails korzysta z tego rozwiązania i znajduje się na platformie Heroku.
Tak więc, gdy obraz zostanie przesłany, zamiast Express API próbuje przechowywać plik lokalnie, tak jak na własnym dysku twardym, pobierze obraz i użyje zewnętrznego magazynu danych do przechowywania wszystkich różnych obrazów z aplikacji.
Ten, którego używam do mojej strony z portfolio i to, czego używałem do Node z aplikacjami React, to Amazon S3, ale istnieją również Azure File Storage i Google Cloud Storage. Systemy te są stworzone do przechowywania ogromnej ilości danych i mogą być dowolnym typem pliku, jaki możesz sobie wyobrazić. Nie tylko obrazy, takie jak w twoim przypadku, ale pliki wideo, pliki audio itp.
Nie ma ograniczeń co do ilości miejsca, które możesz mieć w S3, ale nie musisz używać S3, ale jest to obecnie postrzegane jako standard branżowy, ale możesz równie dobrze korzystać z Azure i Google Cloud.
Zaletą tego rozwiązania, którą myślę, że Twój klient doceni, Amazon S3 pobiera dwa grosze za gigabajt miesięcznie za przechowywanie.



