To przede wszystkim kwestia wydajności. Masz do czynienia ze źle działającym kodem ze swojej strony i musisz zidentyfikować wąskie gardło i je rozwiązać. Mówię o złych 2 sekundach wydajność teraz. Postępuj zgodnie z wytycznymi na Jak analizować wydajność SQL Server . Po uzyskaniu tego zapytania do wykonania lokalnie akceptowanego dla aplikacji sieci Web (mniej niż 5 ms), możesz zadać pytanie o przeniesienie go do bazy danych SQL Azure. W tej chwili Twoje konto próbne podkreśla tylko istniejące nieefektywności.
Po aktualizacji
...
@iddepartment int
...
iddepartment='+convert(nvarchar(max),@iddepartment)+'
...
więc co to jest? to iddepartment kolumna int lub nvarchar ? I po co używać (max) ?
Oto, co powinieneś zrobić:
- parametryzuj
@iddepartmentw wewnętrznym dynamicznym SQL - przestań robić
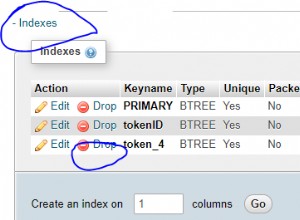
nvarchar(max)konwersja. Utwórziddepartmenti@iddertmenttypy pasują - zapewnij indeksy w
iddepartmenti wszystkieidkpis
Oto jak sparametryzować wewnętrzny SQL:
set @sql =N'
Select * from (
select kpiname, target, ivalues, convert(decimal(18,2),day(idate)) as iDay
from kpi
inner join kpivalues on kpivalues.idkpi=kpi.idkpi
inner join kpitarget on kpitarget.idkpi=kpi.idkpi
inner join departmentbscs on departmentbscs.idkpi=kpi.idkpi
where example@sqldat.com
group by kpiname,target, ivalues,idate)x
pivot
(
avg(ivalues)
for iDay in (' example@sqldat.com + N')
) p'
execute sp_executesql @sql, N'@iddepartment INT', @iddepartment;
Indeksy pokrywające są zdecydowanie najważniejszą poprawką. To oczywiście wymaga więcej informacji niż jest tutaj. Przeczytaj Projektowanie indeksów w tym wszystkie podrozdziały.
Jako bardziej ogólny komentarz:tego rodzaju zapytania pasują do kolumnstores więcej niż rowstore, chociaż uważam, że rozmiar danych jest w zasadzie niewielki. Azure SQL DB obsługuje aktualizowalne klastrowane indeksy magazynu kolumn, możesz z nim eksperymentować w oczekiwaniu na poważny rozmiar danych. Wymagają Enterprise/Development na lokalnym polu, prawda.