Cóż, analiza rozprzestrzeniania się koronawirusa SARS-CoV-2 nie była moim wymarzonym przypadkiem użycia . Ale na podstawie odpowiedzi na artykuł Ferry’ego Djaja dotyczący śledzenia koronawirusa COVID-19 w czasie niemal rzeczywistym za pomocą SAP HANA XSA zdecydowałem się dodać moje dwa grosze.
[Zaktualizowano 20-03-30 ze zmienionymi linkami do danych źródłowych; oraz nowe dane wyjściowe mapy oparte na nowej szczegółowości danych. Dziękuję Douglas Maltby za komentarz!]
W swoim poście na blogu Ferry użył JavaScript w SAP HANA XSA do pobrania danych z plików CSV aktualizowanych codziennie przez Johns Hopkins University.
Chciałbym pokazać, jak można wyciągnąć i załadować te pliki do SAP HANA za pomocą zaledwie kilku linijek kodu dzięki SAP HANA Python Client API for Machine Learning (hana_ml pakiet).
Niektórzy ludzie byli zdezorientowani wizualizacją na mapie na końcu — pamiętaj, że ten artykuł skupia się na technicznych przypadkach użycia łączących różne komponenty, a nie na wykonywaniu głębokiej analizy danych koronawirusa.
Pobierz środowisko Python, np. Jupyter
Wykorzystam do tego Jupyter w kontenerze Docker. Proszę spojrzeć na mój poprzedni post Zrozumienie kontenerów (część 05):współdzielone pliki między hostem a kontenerami, jeśli nie wiesz, jak je uruchomić. Równie dobrze możesz wykonać te same kroki poniżej w dowolnym innym środowisku Pythona.
Mam więc swój kontener myjupyter01 działanie. Jestem połączony z interfejsem użytkownika Jupyter, jak opisano w poprzednim blogu.
Zainstaluj hana_ml
Obraz Jupyter, którego użyłem z rejestru Docker Hub, to jupyter/minimal-notebook . Zawiera już kilka popularnych pakietów przetwarzania danych, takich jak pandas .
Ale dodatkowo muszę zainstalować hana_ml , który — w obecnej wersji 1.0.8 — jest dostępny w repozytorium PyPI:https://pypi.org/project/hana-ml/.
Polecenie do uruchomienia instalacji to python -m pip install hana_ml , ale ponieważ uruchamiam go z notebooka Jupyter z jądrem Python3, muszę go uruchomić z ! na początku:
!python -m pip install hana_ml
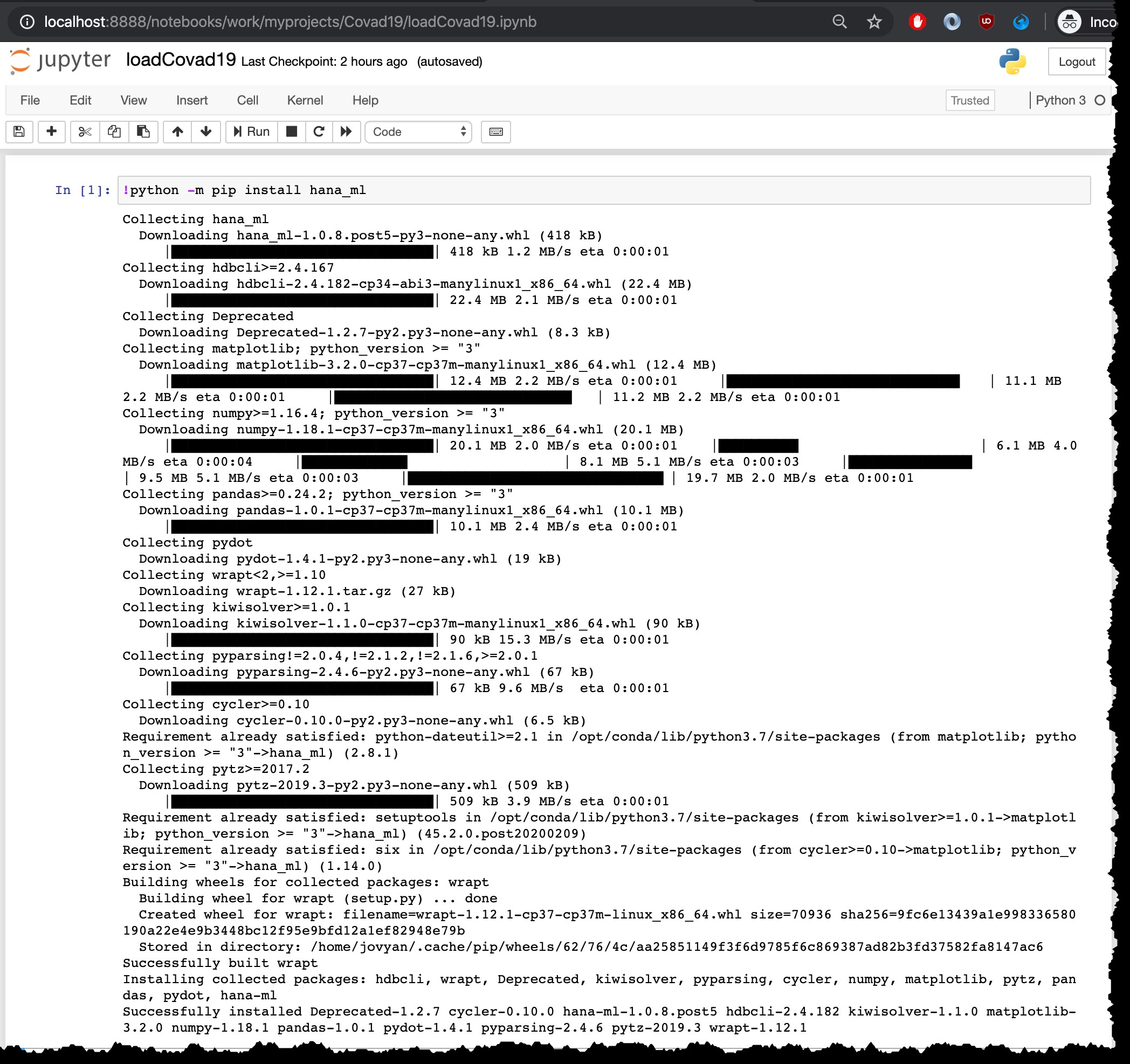
Oczywiście ten etap instalacji należy wykonać tylko raz. Nie trzeba go ponownie uruchamiać w tym samym kontenerze, np. podczas ponownego ładowania najnowszych plików.
Użyj pandas importować pliki z danymi
Zaimportujmy te same trzy pliki (confirmed , deaths , recovered ) z https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series jak Ferry użył w swoim przykładzie.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
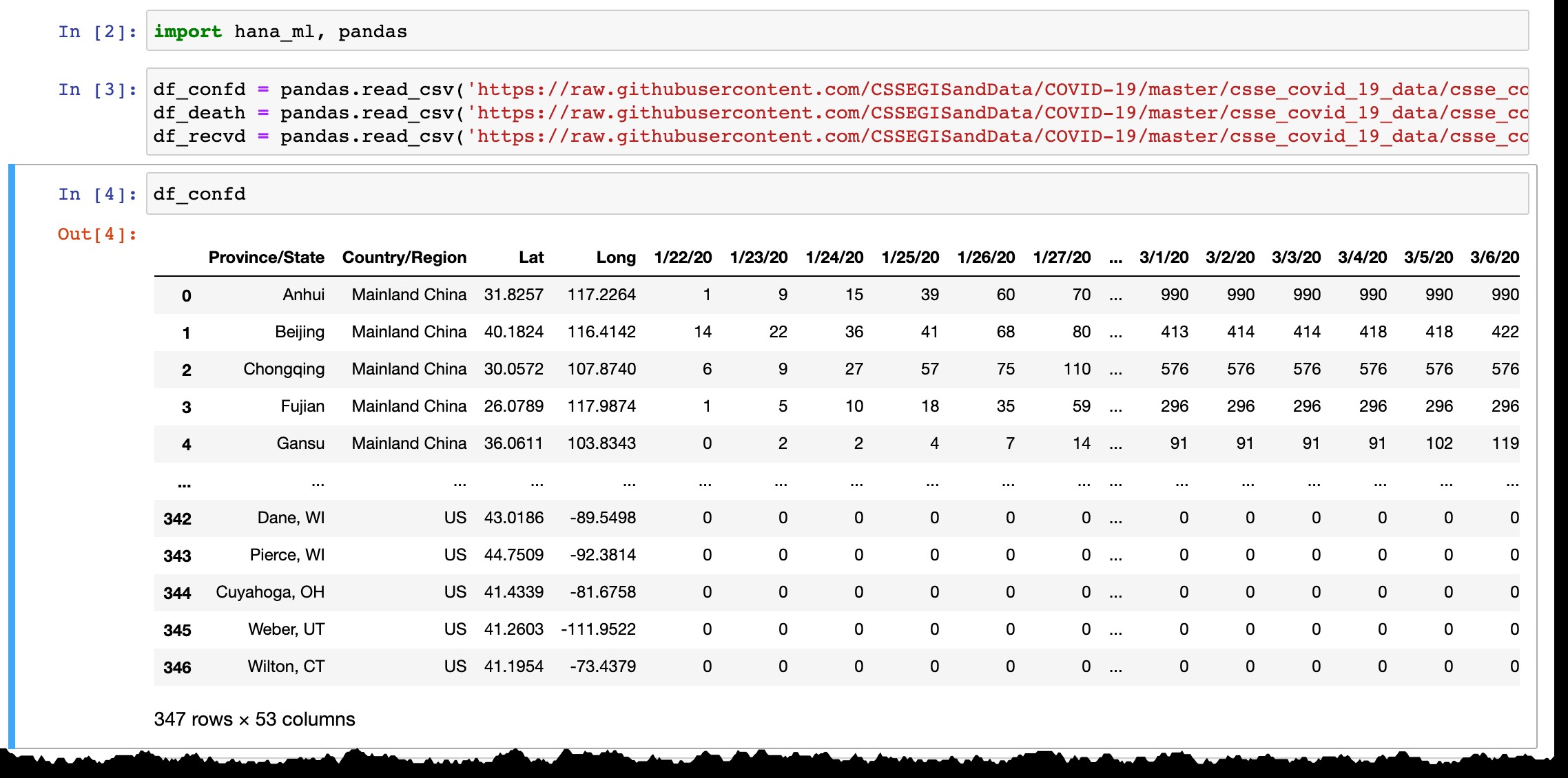
Jak widać na podglądzie ramki danych Pandas, zawiera ona tylko kraje lub prowincje z potwierdzonymi przypadkami, a każdego dnia dodawana jest nowa kolumna z najnowszymi danymi z poprzedniego dnia. Wiersze są dodawane po potwierdzeniu pierwszego przypadku(-ów) w nowym regionie.
Użyj pandas aby ponownie sformatować ramkę danych
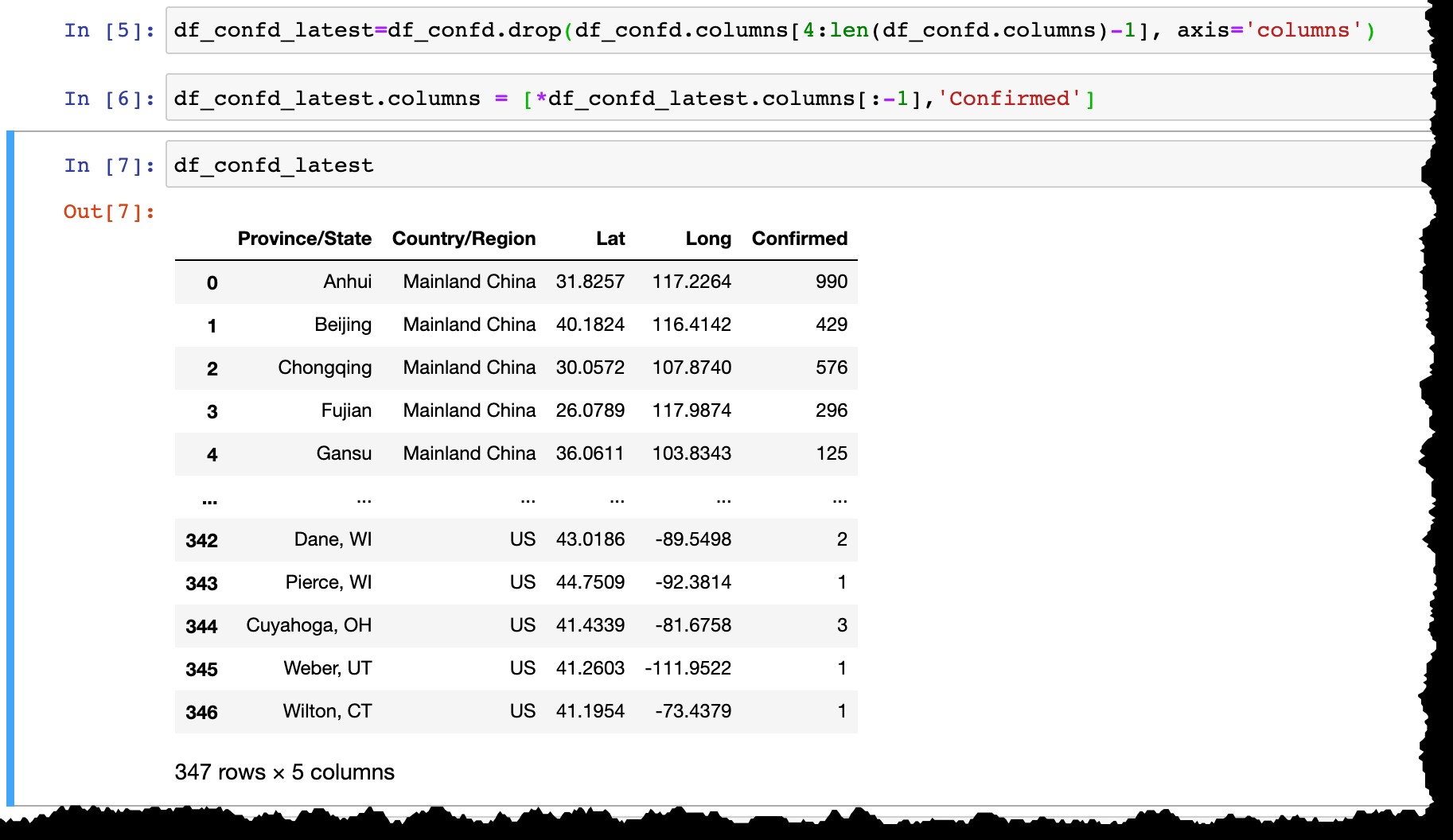
Przed utrwaleniem danych w SAP HANA:
- Usuń wszystkie kolumny dat z wyjątkiem ostatniej,
- Zmień nazwę ostatniej kolumny z rzeczywistej daty (np. dzisiejszy
3/10/20doConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Użyj hana_ml utrwalać dane w tabeli SAP HANA
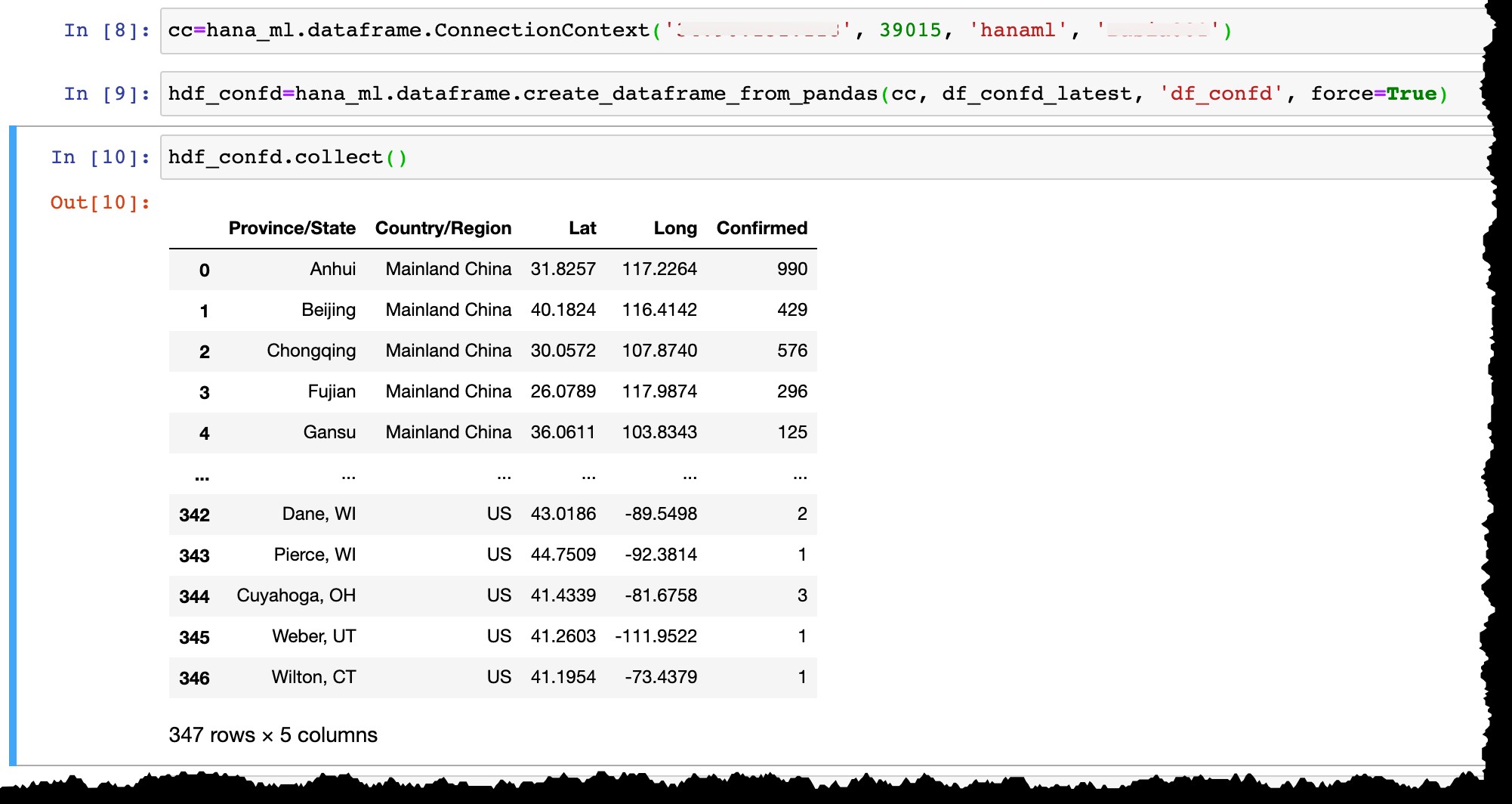
Teraz pozwól mi połączyć się z moją instancją SAP HANA Express za pomocą użytkownika hanaml który już tam istnieje…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…i przekonwertuj ramkę danych Pandas df_confd_latest do ramki danych HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Po utworzeniu ramki danych HANA:
- Fizyczna tabela kolumn jest tworzona w HANA i są tam wstawiane dane z Dataframe Pandy,
- Ramka danych HANA
hdf_confdw Pythonie nie przechowuje żadnych danych w laptopie, a jedynie wskazuje na tabelęHANAML.df_confdw pamięci serwera SAP HANA, a wszystkie operacje Pythona na ramce danych HANA są fizycznie wykonywane w bazie danych HANA bez przenoszenia danych między serwerem a klientem, - Aby wyświetlić wynik dowolnej operacji, musimy zastosować
collect()metoda konwersji HANA dataframe na Pandy (i w rezultacie do przeniesienia danych z serwera HANA db do lokalnego klienta).
Użyj DBeaver, aby sprawdzić dane w SAP HANA…
Być może pamiętasz, że już korzystam z DBeaver — bezpłatnego narzędzia bazodanowego obsługującego SAP HANA — w moim poprzednim poście „GeoArt z SAP HANA i DBeaver”.
Używam go teraz ponownie i rzeczywiście mogę znaleźć tabelę df_confd w schemacie HANAML ze wszystkimi danymi ze źródłowej ramki danych Pandas.
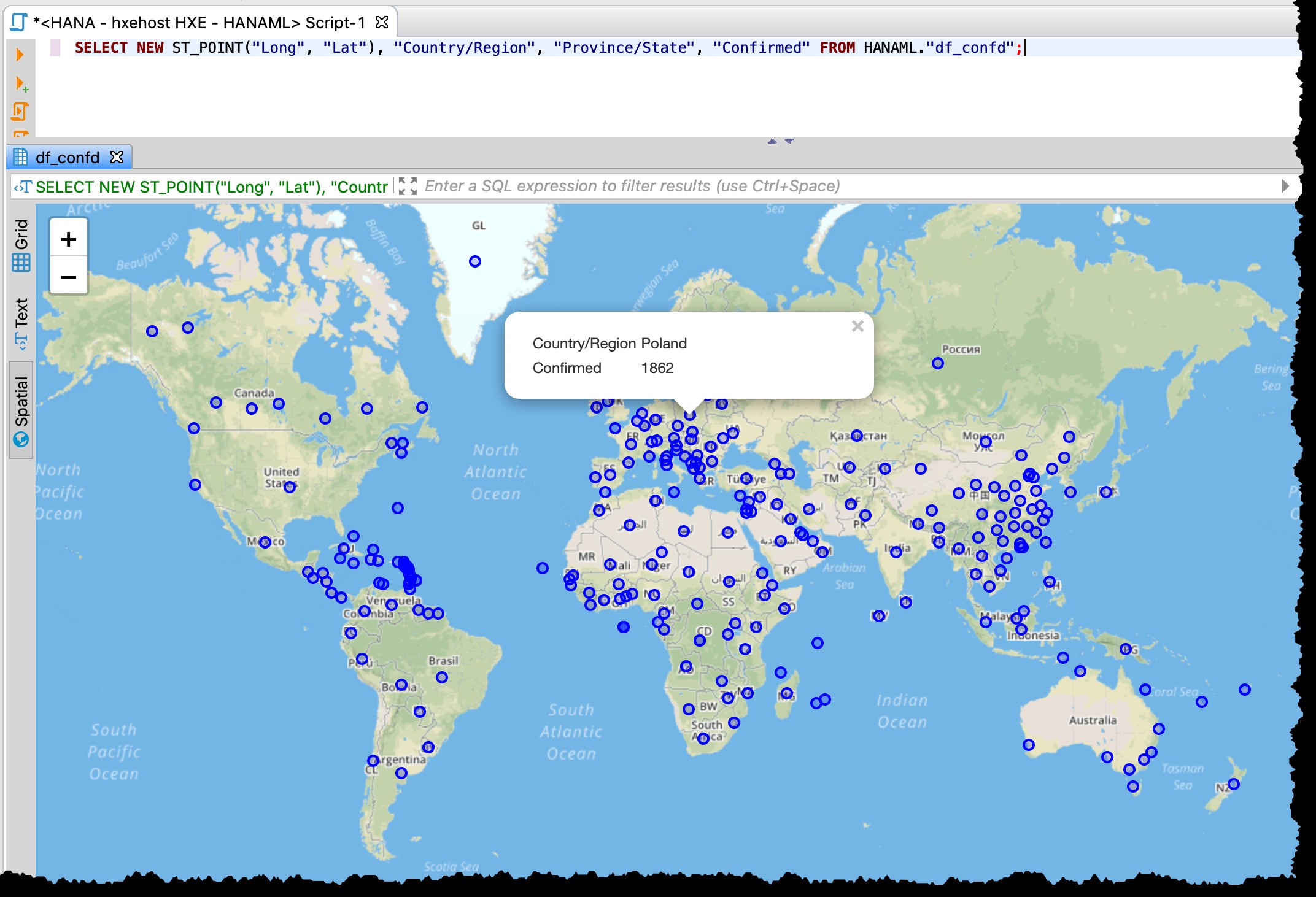
… i zrób podgląd przestrzenny
Ponieważ tabela zawiera kolumny szerokości i długości geograficznej, mogę wizualizować dotknięte kraje/stany bezpośrednio z DBeaver za pomocą następującego kodu SQL przy użyciu podglądu danych przestrzennych.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Musiałem zmienić odwzorowanie mapy na EPSG:4326 aby zdobyć te punkty na mapie. A DBeaver pokazuje mi resztę danych rekordu po kliknięciu dowolnego punktu.
[Poniżej to stary zrzut ekranu z 11.03.2020, który pokazuje również różną szczegółowość m.in. Dane z USA używane w tym czasie]
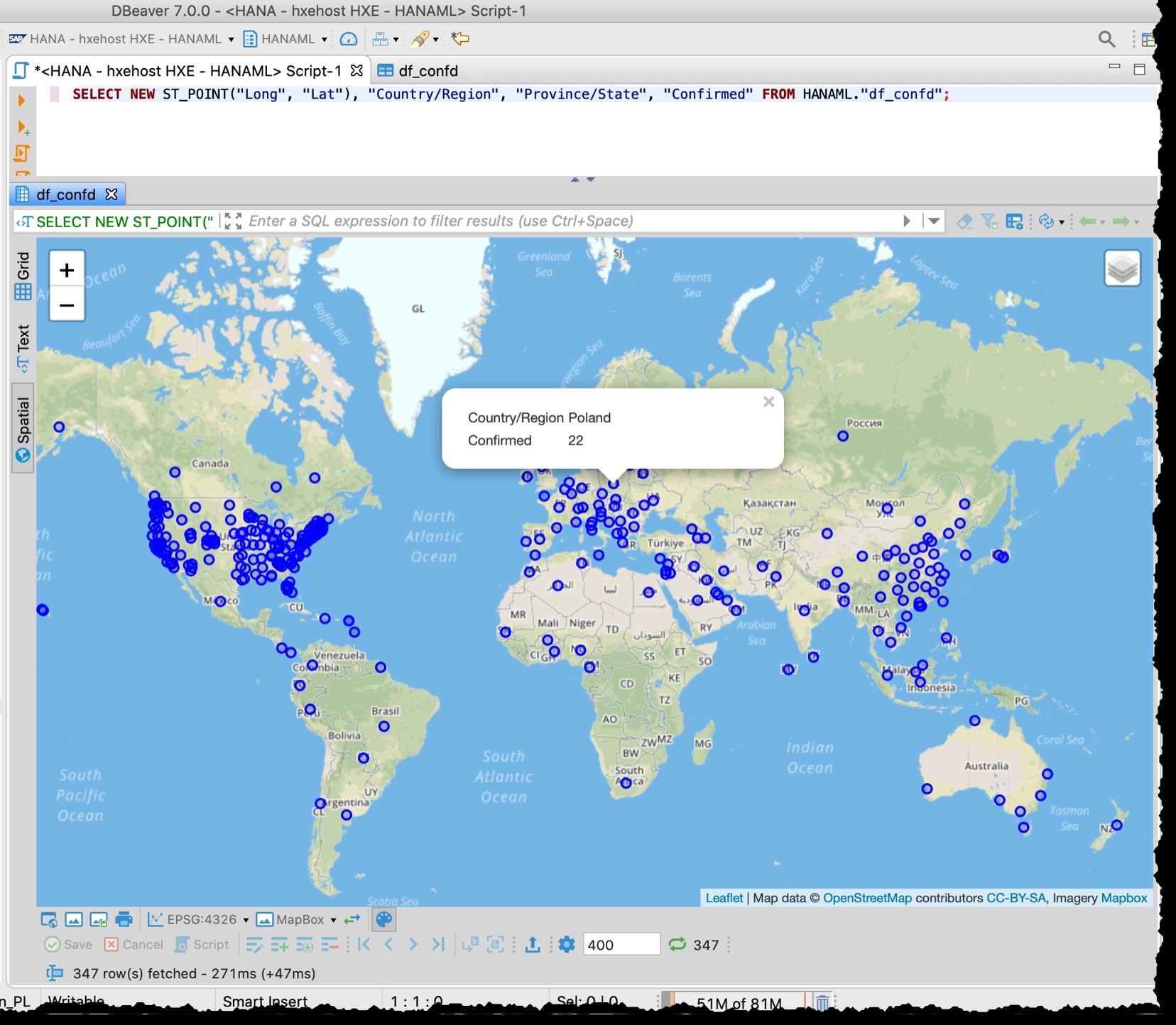
Podgląd przestrzenny DBeaver nie jest w pełni rozwiniętym narzędziem do wizualnej eksploracji geoprzestrzennej. Jednak wystarczająco dobrze jest zobaczyć dotknięte kraje/regiony (w zależności od szczegółowości w plikach źródłowych).
Jeśli chcesz dowiedzieć się więcej o hana_ml …
… w takim razie zdecydowanie polecam sprawdzenie Hands-On Tutorial:Machine Learning push-down do SAP HANA za pomocą Pythona autorstwa Andreasa Forstera.
HANA ML jest częścią nowego tematu „Advanced Analytics with SAP HANA” dla zdarzeń CodeJam. Niestety z powodu sytuacji z koronawirusem musieliśmy odwołać pierwszą w tym miesiącu zorganizowaną przez Jakoba Flamana w Bernie. Kolejną organizuje Ewelina Pękała 27 maja w Katowicach:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Mamy nadzieję, że do tego czasu sytuacja ustabilizuje się i nie będziemy musieli również tego anulować.