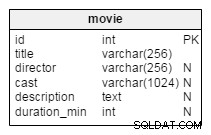
Twoje drugie zapytanie ma postać:
q1 -- PK user_id
LEFT JOIN (...
GROUP BY user_id, t.tag
) AS q2
ON q2.user_id = q1.user_id
LEFT JOIN (...
GROUP BY user_id, c.category
) AS q3
ON q3.user_id = q1.user_id
GROUP BY -- group_concats
Wewnętrzne wyniki GROUP BYs w (user_id, t.tag) &(user_id, c.category) będąc kluczami/UNIKATAMI. Poza tym nie zajmę się tymi GROUP BY.
TL;DR Kiedy dołączasz (q1 JOIN q2) do q3, nie jest to klucz/UNIKAT jednego z nich, więc dla każdego user_id otrzymasz wiersz dla każdej możliwej kombinacji tagu i kategorii. Tak więc ostateczna funkcja GROUP BY wprowadza duplikaty per (identyfikator_użytkownika, tag) i per (identyfikator_użytkownika, kategoria) i niewłaściwie GROUP_CONCAT duplikaty tagów i kategorii na identyfikator_użytkownika. Prawidłowe byłoby (q1 JOIN q2 GROUP BY) JOIN (q1 JOIN q3 GROUP BY), w którym wszystkie złącza są na wspólnym kluczu/UNIKALNY (user_id) i nie ma fałszywej agregacji. Chociaż czasami można cofnąć taką fałszywą agregację.
Prawidłowe podejście symetryczne INNER JOIN:LEFT JOIN q1 &q2-1:many — następnie GROUP BY &GROUP_CONCAT (co zrobiło twoje pierwsze zapytanie); następnie osobno podobnie LEFT JOIN q1 &q3--1:wiele -- następnie GROUP BY &GROUP_CONCAT; następnie INNER JOIN dwa wyniki ON user_id-1:1.
Prawidłowe podejście do symetrycznego podzapytania skalarnego:WYBIERZ GROUP_CONCATs z q1 jako podzapytania skalarne każdy z GROUP BY.
Prawidłowe podejście kumulacyjne LEFT JOIN:LEFT JOIN q1 &q2--1:wiele--następnie GROUP BY &GROUP_CONCAT; następnie LEWY JOIN i q3--1:wiele -- następnie GROUP BY i GROUP_CONCAT.
Prawidłowe podejście, takie jak drugie zapytanie:najpierw LEFT JOIN q1 i q2--1:wiele. Następnie OPUŚCIŁEŚ to i q3--wiele:1:wiele. Daje wiersz dla każdej możliwej kombinacji tagu i kategorii, które pojawiają się z identyfikatorem użytkownika. Następnie po grupowaniu według GROUP_CONCAT--nad zduplikowanymi parami (identyfikator_użytkownika, tag) i zduplikowanymi parami (identyfikator_użytkownika, kategoria). Dlatego masz zduplikowane elementy listy. Ale dodanie DISTINCT do GROUP_CONCAT daje poprawny wynik. (Dla wchiquito komentarz.)
To, co wolisz, jest jak zwykle kompromisem inżynieryjnym, aby być informowanym o planach zapytań i czasie, według rzeczywistych danych/użytkowania/statystyk. dane wejściowe i statystyki dotyczące oczekiwanej ilości duplikacji), czas rzeczywistych zapytań itp. Jednym z problemów jest to, czy dodatkowe wiersze podejścia wiele:1:wiele JOIN zrównoważą zapisanie GROUP BY.
-- cumulative LEFT JOIN approach
SELECT
q1.user_id, q1.user_name, q1.score, q1.reputation,
top_two_tags,
substring_index(group_concat(q3.category ORDER BY q3.category_reputation DESC SEPARATOR ','), ',', 2) AS category
FROM
-- your 1st query (less ORDER BY) AS q1
(SELECT
q1.user_id, q1.user_name, q1.score, q1.reputation,
substring_index(group_concat(q2.tag ORDER BY q2.tag_reputation DESC SEPARATOR ','), ',', 2) AS top_two_tags
FROM
(SELECT
u.id AS user_Id,
u.user_name,
coalesce(sum(r.score), 0) as score,
coalesce(sum(r.reputation), 0) as reputation
FROM
users u
LEFT JOIN reputations r
ON r.user_id = u.id
AND r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
u.id, u.user_name
) AS q1
LEFT JOIN
(
SELECT
r.user_id AS user_id, t.tag, sum(r.reputation) AS tag_reputation
FROM
reputations r
JOIN post_tag pt ON pt.post_id = r.post_id
JOIN tags t ON t.id = pt.tag_id
WHERE
r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
user_id, t.tag
) AS q2
ON q2.user_id = q1.user_id
GROUP BY
q1.user_id, q1.user_name, q1.score, q1.reputation
) AS q1
-- finish like your 2nd query
LEFT JOIN
(
SELECT
r.user_id AS user_id, c.category, sum(r.reputation) AS category_reputation
FROM
reputations r
JOIN post_category ct ON ct.post_id = r.post_id
JOIN categories c ON c.id = ct.category_id
WHERE
r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
user_id, c.category
) AS q3
ON q3.user_id = q1.user_id
GROUP BY
q1.user_id, q1.user_name, q1.score, q1.reputation
ORDER BY
q1.reputation DESC, q1.score DESC ;