Replikacja MySQL jest najpopularniejszym i najczęściej używanym rozwiązaniem zapewniającym wysoką dostępność przez duże organizacje, takie jak Github, Twitter i Facebook. Chociaż rozwiązanie jest łatwe w konfiguracji, podczas korzystania z tego rozwiązania pojawiają się wyzwania związane z konserwacją, w tym aktualizacje oprogramowania, dryf danych lub niespójność danych w węzłach repliki, zmiany topologii, przełączanie awaryjne i odzyskiwanie. Kiedy MySQL wypuścił wersję 5.6, przyniósł szereg znaczących ulepszeń, zwłaszcza w zakresie replikacji, która obejmuje globalne identyfikatory transakcji (GTID), sumy kontrolne zdarzeń, wielowątkowe urządzenia podrzędne i bezpieczne w przypadku awarii urządzenia podrzędne/nadrzędne. Replikacja jest jeszcze lepsza dzięki MySQL 5.7 i MySQL 8.0.
Replikacja umożliwia replikację danych z jednego serwera MySQL (podstawowego/głównego) na jeden lub więcej serwerów MySQL (replika/podrzędne). Replikacja MySQL jest bardzo łatwa w konfiguracji i służy do skalowania obciążeń odczytu, zapewniania wysokiej dostępności i nadmiarowości geograficznej oraz odciążania kopii zapasowych i zadań analitycznych.
Replikacja MySQL w naturze
Przyjrzyjmy się, jak działa replikacja MySQL w naturze. Replikacja MySQL jest szeroka i istnieje wiele sposobów jej konfiguracji i wykorzystania. Domyślnie używa replikacji asynchronicznej, która działa, gdy transakcja jest realizowana w środowisku lokalnym. Nie ma gwarancji, że jakiekolwiek wydarzenie kiedykolwiek dotrze do jakiegokolwiek niewolnika. Jest to luźno powiązana relacja mistrz-niewolnik, gdzie:
-
Główny nie czeka na replikę.
-
Replika określa, ile czytać i od którego punktu w dzienniku binarnym.
-
Replika może być arbitralnie za wzorcem w czytaniu lub stosowaniu zmian.
Jeśli główny ulegnie awarii, transakcje, które popełnił, mogły nie zostać przesłane do żadnej repliki. W konsekwencji przełączenie awaryjne z repliki podstawowej na najbardziej zaawansowaną, w tym przypadku, może spowodować przełączenie awaryjne do żądanej repliki podstawowej, w której faktycznie brakuje transakcji względem poprzedniego serwera.
Replikacja asynchroniczna zapewnia mniejsze opóźnienia zapisu, ponieważ zapis jest potwierdzany lokalnie przez urządzenie nadrzędne, zanim zostanie zapisany do urządzeń podrzędnych. Świetnie nadaje się do skalowania odczytu, ponieważ dodanie większej liczby replik nie wpływa na opóźnienie replikacji. Dobre przypadki użycia replikacji asynchronicznej obejmują wdrażanie replik do odczytu do skalowania odczytu, kopię zapasową na żywo do odzyskiwania po awarii oraz analizy/raportowanie.
Półsynchroniczna replikacja MySQL
MySQL obsługuje również replikację półsynchroniczną, w której master nie potwierdza transakcji klientowi, dopóki co najmniej jeden slave nie skopiuje zmiany do swojego dziennika przekaźnika i opróżni go na dysk. Aby włączyć replikację półsynchroniczną, wymagane są dodatkowe kroki instalacji wtyczki, które należy włączyć na wyznaczonych węzłach nadrzędnym i podrzędnym MySQL.
Semi-synchroniczny wydaje się być dobrym i praktycznym rozwiązaniem w wielu przypadkach, w których ważna jest wysoka dostępność i brak utraty danych. Należy jednak wziąć pod uwagę, że tryb półsynchroniczny ma wpływ na wydajność ze względu na dodatkową podróż w obie strony i nie zapewnia silnych gwarancji przed utratą danych. Gdy zatwierdzenie zostanie pomyślnie zwrócone, wiadomo, że dane znajdują się w co najmniej dwóch miejscach (na urządzeniu głównym i co najmniej jednym podrzędnym). Jeśli master zatwierdzi, ale nastąpi awaria, gdy master czeka na potwierdzenie od slave'a, możliwe jest, że transakcja nie dotarła do żadnego slave'a. Nie jest to duży problem, ponieważ w tym przypadku zatwierdzenie nie zostanie zwrócone do aplikacji. Zadaniem aplikacji jest ponowna próba transakcji w przyszłości. Należy pamiętać, że gdy mistrz ulegnie awarii, a niewolnik zostanie awansowany, stary mistrz nie może dołączyć do łańcucha replikacji. W pewnych okolicznościach może to prowadzić do konfliktów z danymi na urządzeniach podrzędnych, tj. gdy urządzenie nadrzędne uległo awarii po odebraniu przez urządzenie podrzędne zdarzenia dziennika binarnego, ale zanim urządzenie nadrzędne otrzymało potwierdzenie od urządzenia podrzędnego). Dlatego jedynym bezpiecznym sposobem jest odrzucenie danych ze starego mastera i udostępnienie ich od zera przy użyciu danych z nowo promowanego mastera.
Nieprawidłowe użycie formatu replikacji
Od wersji MySQL 5.7.7 domyślny format dziennika binarnego lub zmienna binlog_format używa ROW, który był STATEMENT przed wersją 5.7.7. Różne formaty replikacji odpowiadają metodzie używanej do rejestrowania zdarzeń dziennika binarnego źródła. Replikacja działa, ponieważ zdarzenia zapisywane w dzienniku binarnym są odczytywane ze źródła, a następnie przetwarzane w replice. Zdarzenia są rejestrowane w dzienniku binarnym w różnych formatach replikacji w zależności od typu zdarzenia. Niewiedza na pewno, czego użyć, może stanowić problem. MySQL ma trzy formaty metod replikacji:STATEMENT, ROW i MIXED.
-
Format replikacji opartej na STATEMENT (SBR) jest dokładnie tym, czym jest — strumieniem replikacji każdego uruchomienia instrukcji na urządzeniu głównym, które będzie odtwarzane w węźle podrzędnym. Domyślnie tradycyjna (asynchroniczna) replikacja MySQL nie wykonuje replikowanych transakcji równolegle do urządzeń podrzędnych. Oznacza to, że kolejność instrukcji w strumieniu replikacji może nie być w 100% taka sama. Ponadto powtórzenie instrukcji może dać różne wyniki, jeśli nie zostanie wykonane w tym samym czasie, co w przypadku wykonania ze źródła. Prowadzi to do niespójnego stanu w stosunku do podstawowego i jego replik. Nie było to problemem przez wiele lat, ponieważ niewielu używało MySQL z wieloma jednoczesnymi wątkami. Jednak w przypadku nowoczesnych architektur wieloprocesorowych stało się to bardzo prawdopodobne przy normalnym, codziennym obciążeniu.
-
Format replikacji ROW zapewnia rozwiązania, których brakuje w SBR. W przypadku korzystania z formatu rejestrowania replikacji opartej na wierszach (RBR) źródło zapisuje zdarzenia w dzienniku binarnym, które wskazują, jak zmieniane są poszczególne wiersze tabeli. Replikacja ze źródła do repliki polega na kopiowaniu do repliki zdarzeń reprezentujących zmiany w wierszach tabeli. Oznacza to, że można wygenerować więcej danych, wpływając na ilość miejsca na dysku w replice oraz na ruch sieciowy i dyskowe operacje we/wy. Zastanów się, czy instrukcja zmienia wiele wierszy, powiedzmy z instrukcją UPDATE, RBR zapisuje więcej danych w dzienniku binarnym, nawet w przypadku instrukcji, które są wycofywane. Uruchamianie migawek w określonym momencie może również zająć więcej czasu. Mogą pojawić się problemy ze współbieżnością, biorąc pod uwagę czasy blokady potrzebne do zapisania dużych porcji danych w dzienniku binarnym.
-
Pomiędzy tymi dwoma jest metoda; replikacja w trybie mieszanym. Ten typ replikacji zawsze replikuje instrukcje, z wyjątkiem sytuacji, gdy zapytanie zawiera funkcję UUID(), wyzwalacze, procedury składowane, funkcje UDF i kilka innych wyjątków. Tryb mieszany nie rozwiąże problemu dryfu danych i, wraz z replikacją opartą na instrukcjach, należy go unikać.
Planujesz mieć konfigurację Multi-Master?
Replikacja cykliczna (znana również jako topologia pierścieniowa) to znana i powszechna konfiguracja replikacji MySQL. Służy do uruchamiania konfiguracji z wieloma wzorcami (patrz ilustracja poniżej) i jest często konieczne, jeśli masz środowisko z wieloma centrami danych. Ponieważ aplikacja nie może czekać, aż master w innym centrum danych potwierdzi zapisy, preferowany jest lokalny master. Normalnie przesunięcie auto-inkrementacji służy do zapobiegania kolizjom danych między urządzeniami nadrzędnymi. Szeroko akceptowanym rozwiązaniem jest umożliwienie dwóm mistrzom pisania do siebie nawzajem w ten sposób.
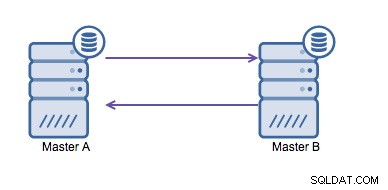
Jednak jeśli musisz pisać w wielu centrach danych w tej samej bazie danych , otrzymujesz wiele wzorców, które muszą zapisywać swoje dane między sobą. Przed MySQL 5.7.6 nie było metody wykonywania replikacji typu mesh, więc alternatywą byłoby użycie zamiast tego replikacji pierścieniowej.
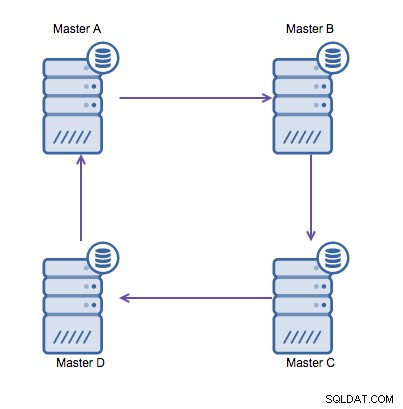
Replikacja pierścienia w MySQL jest problematyczna z następujących powodów:opóźnienia, wysoka dostępność i dryf danych. Zapisanie niektórych danych na serwerze A zajęłoby trzy przeskoki, aby wylądować na serwerze D (przez serwer B i C). Ponieważ (tradycyjna) replikacja MySQL jest jednowątkowa, każde długotrwałe zapytanie w replikacji może zatrzymać cały pierścień. Ponadto, jeśli któryś z serwerów ulegnie awarii, pierścień zostanie przerwany, a obecnie żadne oprogramowanie do przełączania awaryjnego nie jest w stanie naprawić struktur pierścienia. Wtedy może wystąpić dryf danych, gdy dane są zapisywane na serwerze A i jednocześnie zmieniane na serwerze C lub D.
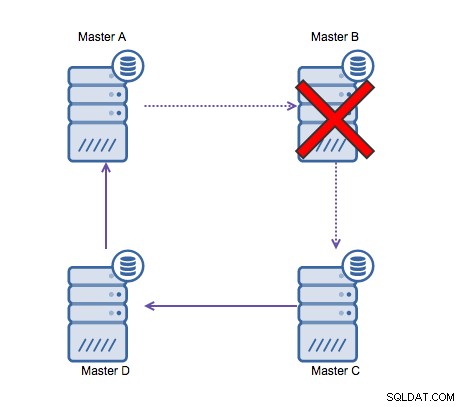
Ogólnie rzecz biorąc, replikacja cykliczna nie pasuje do MySQL i powinna być za wszelką cenę uniknąć. Ponieważ został zaprojektowany z myślą o tym, Galera Cluster byłby dobrą alternatywą dla zapisów w wielu centrach danych.
Zatrzymywanie replikacji z dużymi aktualizacjami
Różne zadania wsadowe porządkowania często wykonują różne zadania, od czyszczenia starych danych po obliczanie średnich „polubień” pobranych z innego źródła. Oznacza to, że zadanie spowoduje dużą aktywność bazy danych w określonych odstępach czasu i najprawdopodobniej zapisze wiele danych z powrotem do bazy danych. Oczywiście oznacza to, że aktywność w strumieniu replikacji wzrośnie równomiernie.
Replikacja oparta na wyciągach będzie replikować dokładnie zapytania używane w zadaniach wsadowych, więc jeśli zapytanie zajęłoby pół godziny na przetworzenie na urządzeniu głównym, wątek podrzędny zostałby zatrzymany na co najmniej taką samą ilość czas. Oznacza to, że żadne inne dane nie mogą się replikować, a węzły podrzędne zaczną pozostawać w tyle za węzłem głównym. Jeśli przekroczy to próg narzędzia do przełączania awaryjnego lub serwera proxy, może usunąć te węzły podrzędne z dostępnych serwerów w klastrze. Jeśli używasz replikacji opartej na instrukcjach, możesz temu zapobiec, dzieląc dane zadania na mniejsze partie.
Możesz teraz sądzić, że nie ma to wpływu na replikację opartą na wierszach, ponieważ będzie ona replikować informacje o wierszu zamiast zapytania. Jest to częściowo prawdziwe, ponieważ w przypadku zmian DDL replikacja powraca do formatu opartego na instrukcjach. Ponadto duża liczba operacji CRUD (tworzenie, odczyt, aktualizacja, usuwanie) wpłynie na strumień replikacji. W większości przypadków jest to nadal operacja jednowątkowa, a zatem każda transakcja będzie oczekiwała na odtworzenie poprzedniej poprzez replikację. Oznacza to, że jeśli masz wysoką współbieżność na urządzeniu głównym, urządzenie podrzędne może zatrzymać się z powodu przeciążenia transakcji podczas replikacji.
Aby obejść ten problem, zarówno MariaDB, jak i MySQL oferują replikację równoległą. Implementacja może się różnić w zależności od dostawcy i wersji. MySQL 5.6 oferuje replikację równoległą, o ile zapytania są oddzielone schematem. MariaDB 10.0 i MySQL 5.7 mogą obsługiwać replikację równoległą w różnych schematach, ale mają inne granice. Wykonywanie zapytań przez równoległe wątki podrzędne może przyspieszyć strumień replikacji, jeśli piszesz dużo. W przeciwnym razie lepiej byłoby trzymać się tradycyjnej replikacji jednowątkowej.
Obsługa zmiany schematu lub DDL
Od czasu wydania wersji 5.7 zarządzanie zmianą schematu lub DDL (Data Definition Language) w MySQL znacznie się poprawiło. Do MySQL 8.0 obsługiwane algorytmy zmian DDL to COPY i INPLACE.
-
KOPIUJ:Ten algorytm tworzy nową tabelę tymczasową ze zmienionym schematem. Po całkowitej migracji danych do nowej tabeli tymczasowej zamienia i usuwa starą tabelę.
-
INPLACE:Ten algorytm wykonuje operacje w miejscu oryginalnej tabeli i unika kopiowania i odbudowywania tabeli, gdy tylko jest to możliwe.
-
INSTANT:Ten algorytm został wprowadzony od wersji MySQL 8.0, ale nadal ma ograniczenia.
W MySQL 8.0 wprowadzono algorytm INSTANT, dokonujący natychmiastowych i na miejscu zmian w tabelach w celu dodawania kolumn oraz umożliwiający współbieżne DML z lepszą responsywnością i dostępnością w ruchliwych środowiskach produkcyjnych. Pomaga to uniknąć ogromnych opóźnień i przestojów w replice, które zwykle były dużymi problemami z perspektywy aplikacji, powodując pobieranie nieaktualnych danych, ponieważ odczyty w urządzeniu podrzędnym nie zostały jeszcze zaktualizowane z powodu opóźnień.
Chociaż jest to obiecujące ulepszenie, nadal istnieją z nimi ograniczenia i czasami nie jest możliwe zastosowanie algorytmów INSTANT i INPLACE. Na przykład dla algorytmów INSTANT i INPLACE zmiana typu danych kolumny jest również zwykłym zadaniem DBA, szczególnie w perspektywie rozwoju aplikacji ze względu na zmianę danych. Takie okazje są nieuniknione; w związku z tym nie można kontynuować algorytmu COPY, ponieważ blokuje on tabelę, powodując opóźnienia w urządzeniu podrzędnym. Wpływa również na serwer główny/główny podczas tego wykonywania, ponieważ gromadzi przychodzące transakcje, które również odwołują się do danej tabeli. Nie możesz wykonać bezpośredniej zmiany lub zmiany schematu na zajętym serwerze, ponieważ towarzyszy to przestojowi lub może uszkodzić bazę danych, jeśli stracisz cierpliwość, zwłaszcza jeśli tabela docelowa jest ogromna.
Prawdą jest, że wprowadzanie zmian w schemacie w działającej konfiguracji produkcyjnej jest zawsze trudnym zadaniem. Często stosowanym obejściem jest zastosowanie zmiany schematu najpierw do węzłów podrzędnych. Działa to dobrze w przypadku replikacji opartej na instrukcjach, ale może działać tylko do pewnego stopnia w przypadku replikacji opartej na wierszach. Replikacja oparta na wierszach pozwala na istnienie dodatkowych kolumn na końcu tabeli, więc dopóki może zapisać pierwsze kolumny, wszystko będzie w porządku. Najpierw zastosuj zmianę do wszystkich urządzeń podrzędnych, a następnie przełącz się do jednego z urządzeń podrzędnych, a następnie zastosuj zmianę do urządzenia nadrzędnego i dołącz go jako podrzędny. Jeśli zmiana obejmuje wstawienie kolumny w środku lub usunięcie kolumny, zadziała to z replikacją opartą na wierszach.
Dostępne są narzędzia, które mogą bardziej niezawodnie przeprowadzać zmiany schematów online. Zmiana schematu online Percona (znana jako pt-osc) i gh-ost autorstwa Schlomi Noach są powszechnie używane przez administratorów baz danych. Te narzędzia skutecznie obsługują zmiany schematu, grupując odpowiednie wiersze w porcje, a te porcje można odpowiednio skonfigurować w zależności od tego, ile chcesz pogrupować.
Jeśli zamierzasz skakać z pt-osc, to narzędzie utworzy tabelę cieni z nową strukturą tabeli, wstawi nowe dane za pomocą wyzwalaczy i wypełni dane w tle. Po zakończeniu tworzenia nowej tabeli po prostu zamieni starą tabelę na nową w ramach transakcji. To nie działa we wszystkich przypadkach, zwłaszcza jeśli istniejąca tabela ma już wyzwalacze.
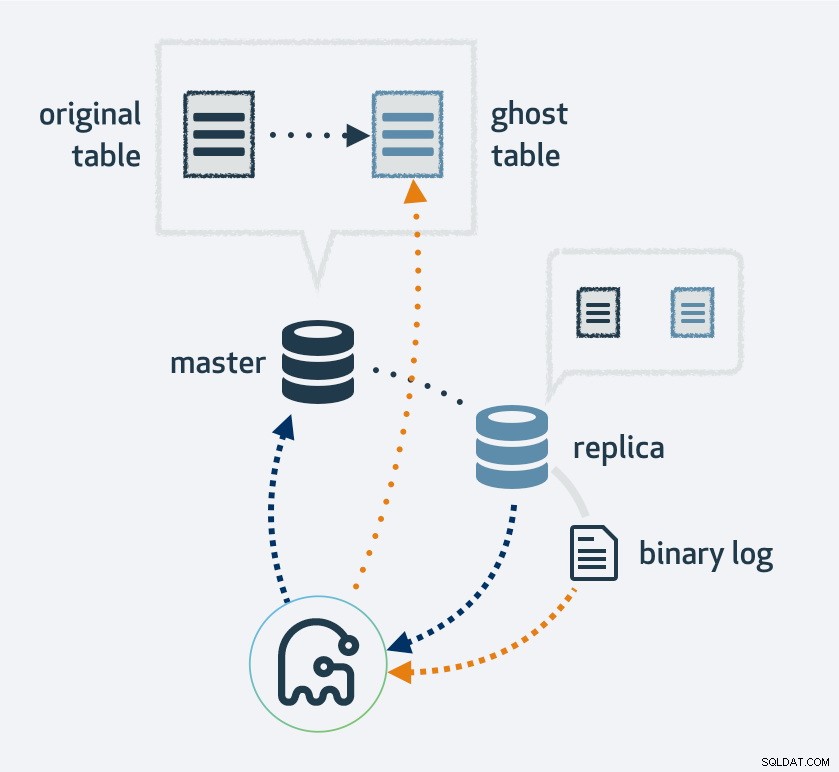
Za pomocą gh-ost najpierw utworzysz kopię istniejącego układu tabeli, zmień tabelę na nowy układ, a następnie podłącz proces jako replikę MySQL. Użyje strumienia replikacji do znalezienia nowych wierszy, które zostały wstawione do oryginalnej tabeli i jednocześnie wypełni tabelę. Gdy zakończy się wypełnianie, oryginalna i nowa tabela zostaną zamienione. Oczywiście wszystkie operacje na nowej tabeli trafią do strumienia replikacji; dlatego w każdej replice migracja odbywa się jednocześnie.
Tabele pamięci i replikacja
Podczas gdy jesteśmy przy temacie DDL, powszechnym problemem jest tworzenie tablic pamięci. Tabele pamięci są tabelami nietrwałymi, ich struktura tabel pozostaje, ale tracą dane po ponownym uruchomieniu MySQL. Tworząc nową tablicę pamięci zarówno na urządzeniu nadrzędnym, jak i podrzędnym, będą mieli pustą tabelę, co będzie działać idealnie. Po ponownym uruchomieniu któregoś z nich tabela zostanie opróżniona i wystąpią błędy replikacji.
Replikacja oparta na wierszach zostanie przerwana, gdy dane w węźle podrzędnym zwrócą różne wyniki, a replikacja oparta na instrukcji zostanie przerwana, gdy spróbuje wstawić dane, które już istnieją. W przypadku tabel pamięci jest to częsty przerywacz replikacji. Naprawa jest łatwa:utwórz nową kopię danych, zmień silnik na InnoDB i powinien być teraz bezpieczny dla replikacji.
Ustawianie tylko do odczytu={True|1}
Jest to oczywiście możliwy przypadek, gdy używasz topologii pierścienia i jeśli to możliwe, odradzamy używanie topologii pierścienia. Opisaliśmy wcześniej, że brak tych samych danych w węzłach podrzędnych może przerwać replikację. Często jest to spowodowane przez coś (lub kogoś) zmieniającego dane w węźle podrzędnym, ale nie w węźle głównym. Gdy dane węzła głównego zostaną zmienione, zostaną one zreplikowane do urządzenia podrzędnego, gdzie nie może zastosować zmiany, co spowoduje przerwanie replikacji. Może to również prowadzić do uszkodzenia danych na poziomie klastra, zwłaszcza jeśli urządzenie podrzędne zostało awansowane lub uległo awarii z powodu awarii. To może być katastrofa.
Łatwym zapobieganiem temu jest upewnienie się, że tylko do_odczytu i tylko do_odczytu (tylko na> 5.6) są ustawione na WŁ. lub 1. Być może zrozumiałeś, jak te dwie zmienne różnią się i jaki mają wpływ na wyłączenie lub włączenie ich. Po wyłączeniu super_read_only (od MySQL 5.7.8) użytkownik root może zapobiec wszelkim zmianom w miejscu docelowym lub replice. Tak więc, gdy oba są wyłączone, uniemożliwi to każdemu wprowadzanie zmian w danych, z wyjątkiem replikacji. Większość menedżerów pracy awaryjnej, takich jak ClusterControl, ustawia tę flagę automatycznie, aby uniemożliwić użytkownikom zapisywanie do używanego systemu głównego podczas przełączania awaryjnego. Niektóre z nich zachowują to nawet po przełączeniu awaryjnym.
Włączanie identyfikatora GTID
W replikacji MySQL, uruchomienie slave'a z właściwej pozycji w logach binarnych jest niezbędne. Uzyskanie tej pozycji może być wykonane podczas tworzenia kopii zapasowej (obsługują to xtrabackup i mysqldump) lub gdy przestałeś korzystać z węzła, którego kopiujesz. Rozpoczęcie replikacji poleceniem ZMIEŃ MASTER NA wyglądałoby tak:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Rozpoczęcie replikacji w złym miejscu może mieć katastrofalne skutki:dane mogą być zapisywane dwukrotnie lub nie być aktualizowane. Powoduje to dryf danych między węzłem głównym a węzłem podrzędnym.
Ponadto przełączenie urządzenia głównego na urządzenie podrzędne obejmuje znalezienie właściwej pozycji i zmianę urządzenia głównego na odpowiedni host. MySQL nie zachowuje logów binarnych i pozycji ze swojego mastera, ale zamiast tego tworzy własne logi binarne i pozycje. Może to stać się poważnym problemem przy ponownym dopasowaniu węzła podrzędnego do nowego węzła nadrzędnego. Dokładną pozycję urządzenia nadrzędnego w trybie przełączania awaryjnego należy znaleźć na nowym urządzeniu głównym, a następnie wyrównać wszystkie urządzenia podrzędne.
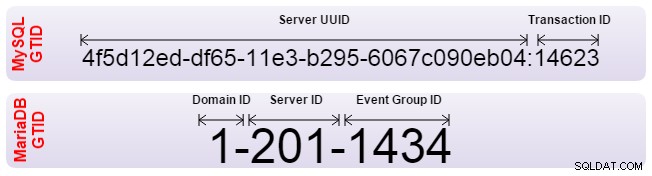
Zarówno Oracle MySQL, jak i MariaDB wdrożyły globalny identyfikator transakcji (GTID) do rozwiązać ten problem. Identyfikatory GTID pozwalają na automatyczne wyrównanie urządzeń podrzędnych, a serwer sam dowiaduje się, jaka jest prawidłowa pozycja. Jednak oba zaimplementowały identyfikator GTID w inny sposób i dlatego są niezgodne. Jeśli musisz skonfigurować replikację między sobą, replikacja powinna być skonfigurowana z tradycyjnym pozycjonowaniem dziennika binarnego. Ponadto oprogramowanie do przełączania awaryjnego powinno mieć świadomość, że nie używa identyfikatorów GTID.
Podręcznik bezpieczny w razie awarii
Bezpieczne w razie awarii oznacza, że nawet jeśli slave MySQL/OS ulegnie awarii, możesz odzyskać slave'a i kontynuować replikację bez przywracania baz danych MySQL na slave. Aby urządzenie podrzędne było bezpieczne w przypadku awarii, musisz użyć tylko silnika pamięci masowej InnoDB, aw wersji 5.6 musisz ustawić relay_log_info_repository=TABLE i relay_log_recovery=1.
Wnioski
Praktyka rzeczywiście czyni mistrza, ale bez odpowiedniego przeszkolenia i znajomości tych kluczowych technik może to być kłopotliwe lub doprowadzić do katastrofy. Te praktyki są powszechnie przestrzegane przez ekspertów MySQL i są adaptowane przez duże branże w ramach ich codziennej rutynowej pracy podczas administrowania replikacją MySQL na produkcyjnych serwerach baz danych.
Jeśli chcesz dowiedzieć się więcej o replikacji MySQL, zapoznaj się z tym samouczkiem dotyczącym replikacji MySQL w celu zapewnienia wysokiej dostępności.
Aby uzyskać więcej informacji na temat rozwiązań do zarządzania bazami danych i najlepszych praktyk dotyczących baz danych opartych na otwartym kodzie źródłowym, śledź nas na Twitterze i LinkedIn oraz zasubskrybuj nasz biuletyn.