Przeniesienie danych do usługi chmury publicznej to poważna decyzja. Wszyscy główni dostawcy usług w chmurze oferują usługi baz danych w chmurze, przy czym prawdopodobnie najbardziej popularny jest Amazon RDS dla MySQL.
Na tym blogu przyjrzymy się bliżej, co to jest, jak działa i porównamy jego zalety i wady.
RDS (Relational Database Service) to oferta Amazon Web Services. Krótko mówiąc, jest to baza danych jako usługa, w której Amazon wdraża i obsługuje Twoją bazę danych. Dba o zadania takie jak tworzenie kopii zapasowych i łatanie oprogramowania bazodanowego, a także wysoką dostępność. Kilka baz danych jest obsługiwanych przez RDS, ale tutaj interesuje nas głównie MySQL - Amazon obsługuje MySQL i MariaDB. Istnieje również Aurora, klon MySQL firmy Amazon, ulepszony, szczególnie w obszarze replikacji i wysokiej dostępności.
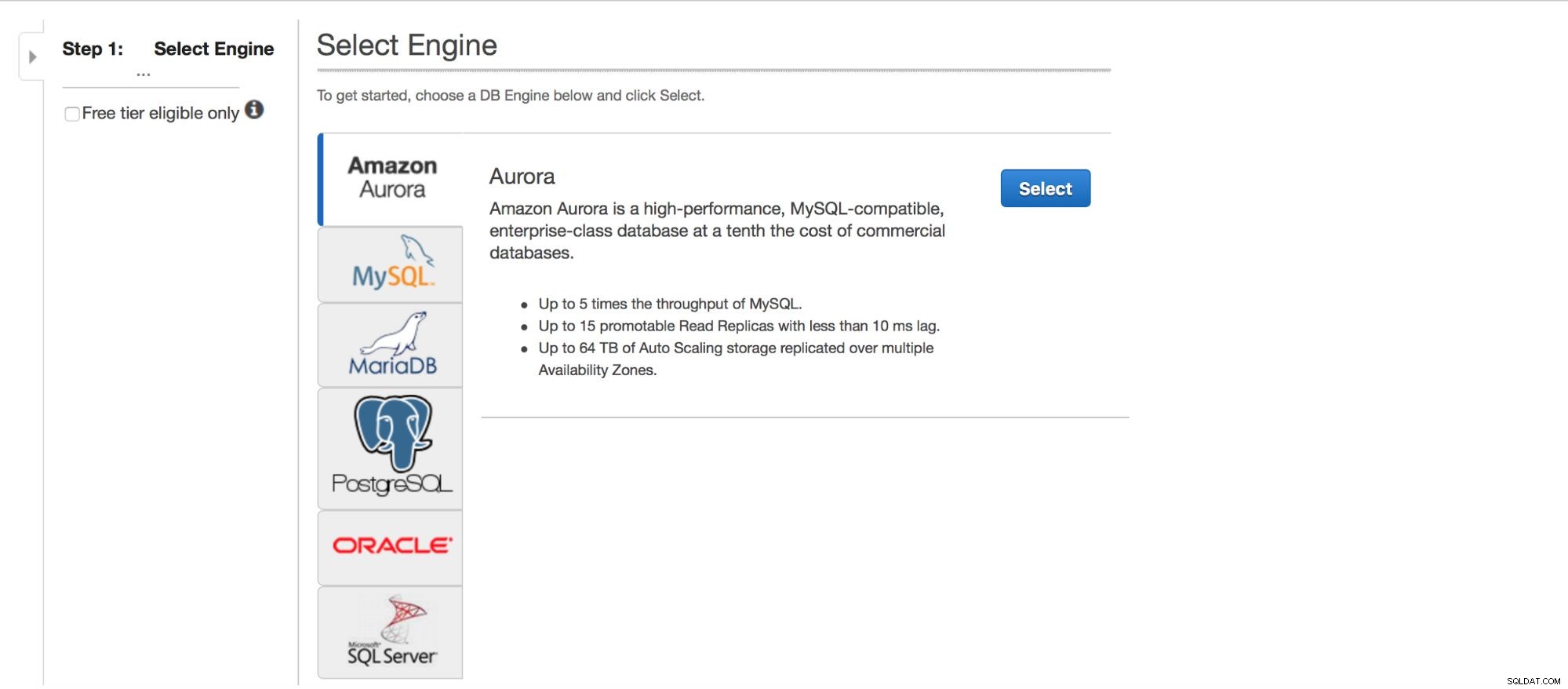
Wdrażanie MySQL przez RDS
Przyjrzyjmy się wdrożeniu MySQL za pośrednictwem RDS. Wybraliśmy MySQL, a następnie przedstawiamy kilka wzorców wdrażania do wyboru.
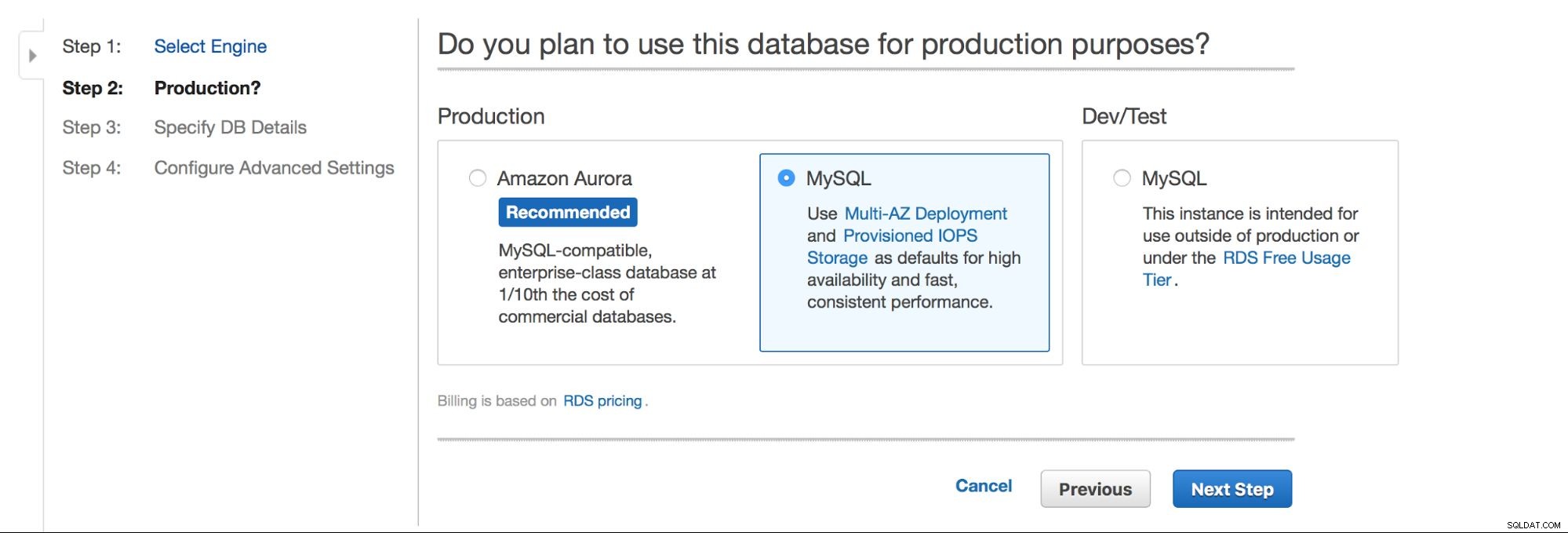
Główny wybór brzmi – czy chcemy mieć wysoką dostępność, czy nie? Promowana jest również Aurora.
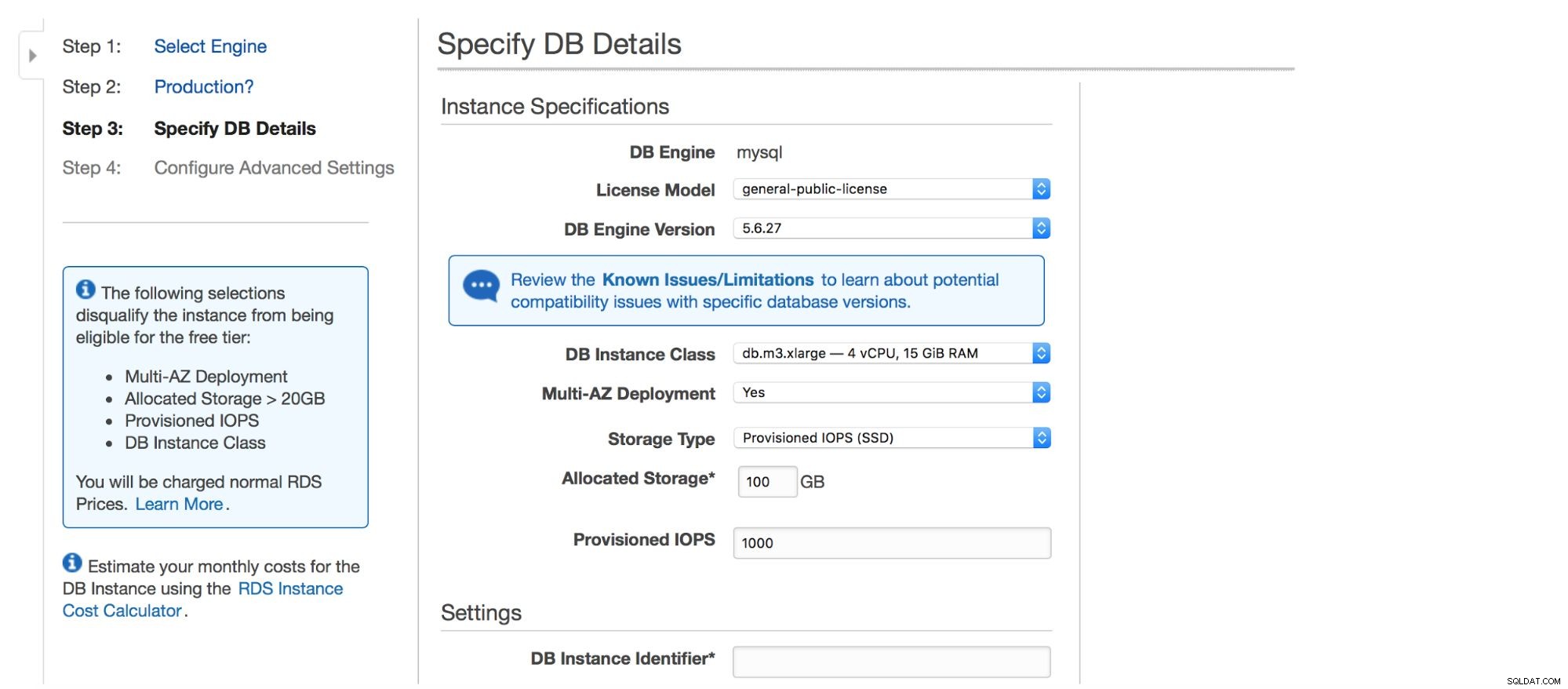
Następne okno dialogowe daje nam kilka opcji do dostosowania. Możesz wybrać jedną z wielu wersji MySQL - dostępnych jest kilka wersji 5.5, 5.6 i 5.7. Instancja bazy danych - możesz wybierać spośród typowych rozmiarów instancji dostępnych w danym regionie.
Następna opcja to dość ważny wybór - chcesz użyć wdrożenia multi-AZ, czy nie? Chodzi o wysoką dostępność. Jeśli nie chcesz korzystać z wdrożenia multi-AZ, zostanie zainstalowane jedno wystąpienie. W przypadku awarii, nowy zostanie uruchomiony, a jego wolumen danych zostanie do niego ponownie podłączony. Ten proces zajmuje trochę czasu, podczas którego Twoja baza danych będzie niedostępna. Oczywiście możesz zminimalizować ten wpływ, używając niewolników i promując jednego z nich, ale nie jest to zautomatyzowany proces. Jeśli chcesz mieć zautomatyzowaną wysoką dostępność, użyj wdrażania wielu AZ. To, co się stanie, to utworzenie dwóch instancji bazy danych. Jeden jest dla ciebie widoczny. Drugie wystąpienie, w oddzielnej strefie dostępności, nie jest widoczne dla użytkownika. Będzie działać jako kopia w tle, gotowa do przejęcia ruchu po awarii aktywnego węzła. Wciąż nie jest to idealne rozwiązanie, ponieważ ruch musi zostać przeniesiony z instancji, która uległa awarii, do instancji shadow. W naszych testach przełączenie awaryjne zajęło około 45 sekund, ale oczywiście może to zależeć od rozmiaru instancji, wydajności we/wy itp. Ale jest to znacznie lepsze niż nieautomatyczne przełączanie awaryjne, w którym zaangażowane są tylko urządzenia podrzędne.
Na koniec mamy ustawienia pamięci - typ, rozmiar, PIOPS (jeśli dotyczy) i ustawienia bazy danych - identyfikator, użytkownik i hasło.
W następnym kroku na dane wejściowe użytkownika czeka jeszcze kilka opcji.
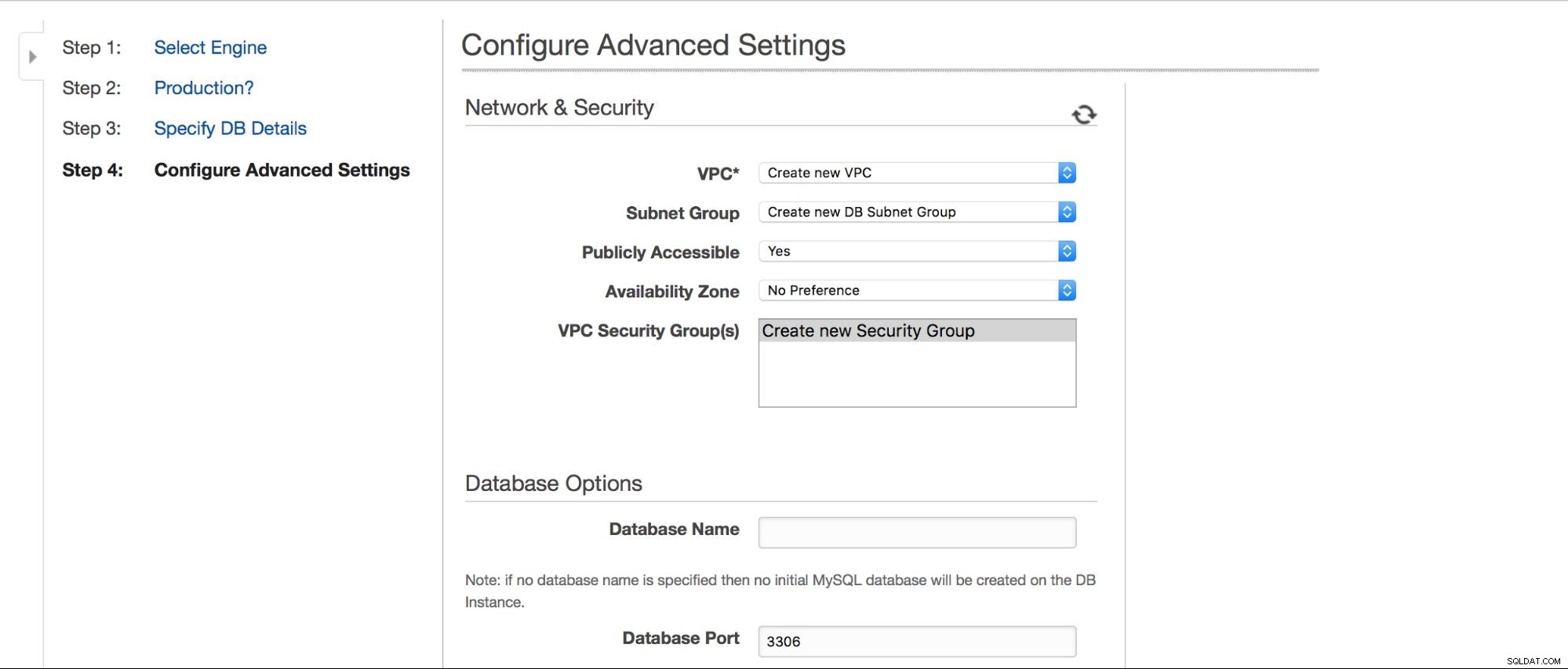
Możemy wybrać, gdzie ma być utworzona instancja:VPC, podsieć, czy ma być publicznie dostępna czy nie (np. - czy publiczne IP powinno być przypisane do instancji RDS), strefa dostępności i VPC Security Group. Następnie mamy opcje bazy danych:pierwszy schemat do utworzenia, port, parametry i grupy opcji, czy tagi metadanych powinny być zawarte w migawkach, czy nie, ustawienia szyfrowania.
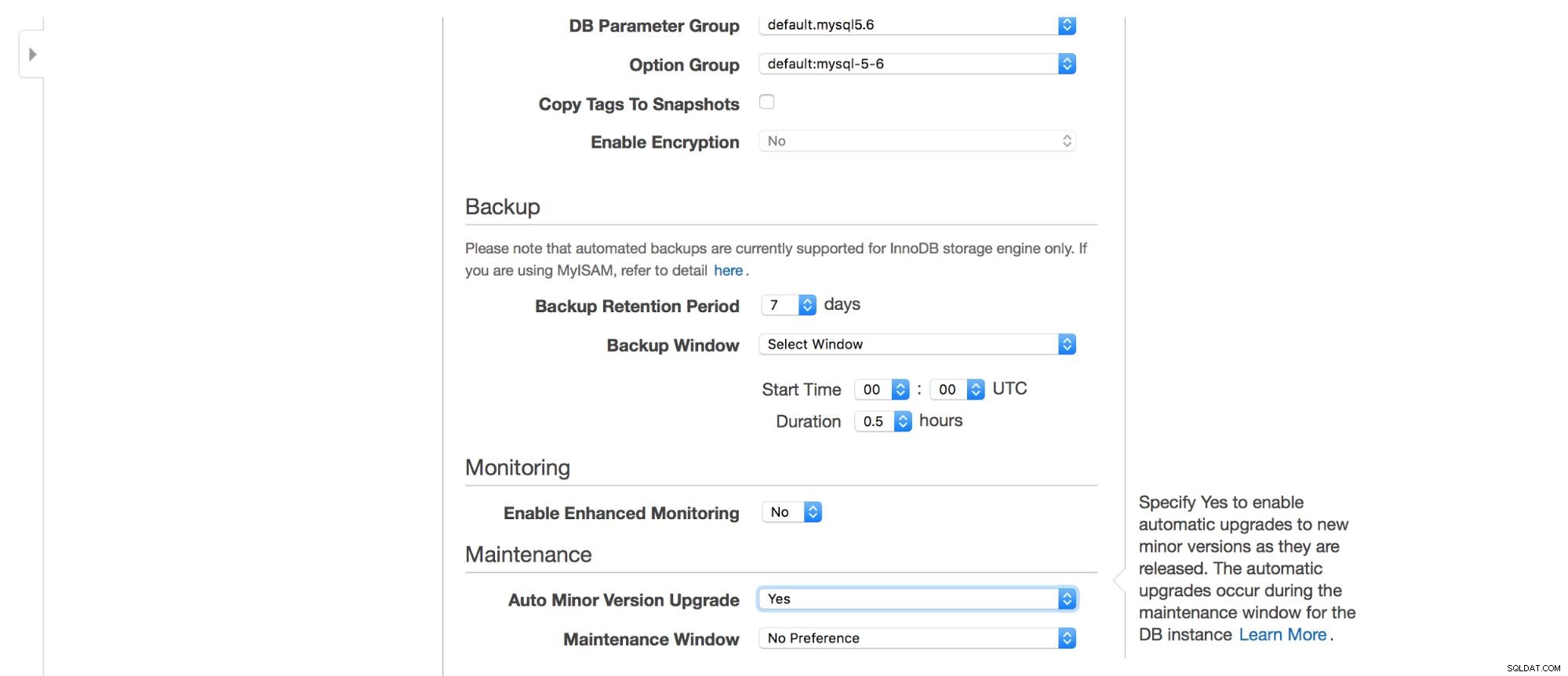
Następnie opcje tworzenia kopii zapasowych — jak długo chcesz przechowywać kopie zapasowe? Kiedy chcesz je zabrać? Podobna konfiguracja jest związana z konserwacjami – czasami administratorzy Amazon muszą przeprowadzać konserwację na Twojej instancji RDS – dzieje się to w ramach predefiniowanego okna, które możesz ustawić tutaj. Należy pamiętać, że nie ma opcji, aby nie wybrać co najmniej 30 minut na okres konserwacji, dlatego posiadanie instancji multi-AZ na produkcji jest naprawdę ważne. Konserwacja może spowodować ponowne uruchomienie węzła lub brak dostępności przez pewien czas. Bez multi-AZ musisz zaakceptować ten przestój. W przypadku wdrożenia multi-AZ następuje przełączenie awaryjne.
Na koniec mamy ustawienia związane z dodatkowym monitorowaniem - czy chcemy je włączyć, czy nie?
Zarządzanie RDS
W tym rozdziale przyjrzymy się bliżej zarządzaniu MySQL RDS. Nie będziemy omawiać wszystkich dostępnych opcji, ale chcielibyśmy podkreślić niektóre funkcje udostępnione przez Amazon.
Migawki
MySQL RDS wykorzystuje woluminy EBS jako pamięć masową, dzięki czemu może używać migawek EBS do różnych celów. Kopie zapasowe, urządzenia podrzędne - wszystko oparte na migawkach. Możesz tworzyć migawki ręcznie lub mogą być one robione automatycznie, gdy zajdzie taka potrzeba. Należy pamiętać, że migawki EBS ogólnie (nie tylko w instancjach RDS) zwiększają obciążenie operacji we/wy. Jeśli chcesz zrobić migawkę, spodziewaj się spadku wydajności we/wy. Chyba że używasz wdrażania wielu AZ. W takim przypadku instancja „shadow” zostanie użyta jako źródło migawek i nie będzie widoczny żaden wpływ na instancję produkcyjną.
Manynines DevOps Przewodnik po zarządzaniu bazami danychDowiedz się, co musisz wiedzieć, aby zautomatyzować i zarządzać bazami danych typu open sourcePobierz za darmoKopie zapasowe
Kopie zapasowe są oparte na migawkach. Jak wspomniano powyżej, podczas tworzenia nowej instancji można zdefiniować harmonogram tworzenia kopii zapasowych i przechowywania. Oczywiście możesz później edytować te ustawienia, korzystając z opcji „modyfikuj instancję”.
W każdej chwili możesz przywrócić migawkę — musisz przejść do sekcji migawek, wybrać migawkę, którą chcesz przywrócić, a zostanie wyświetlone okno dialogowe podobne do tego, które widziałeś podczas tworzenia nowej instancji. Nie jest to niespodzianką, ponieważ migawkę można przywrócić tylko do nowej instancji — nie ma możliwości przywrócenia jej na jednej z istniejących instancji RDS. Może to być zaskoczeniem, ale nawet w środowisku chmury sensowne może być ponowne wykorzystanie sprzętu (i instancji, które już masz). W środowisku współdzielonym wydajność pojedynczej instancji wirtualnej może się różnić — możesz chcieć pozostać przy profilu wydajności, który już znasz. Niestety nie jest to możliwe w RDS.
Inną opcją w RDS jest odzyskiwanie do punktu w czasie - bardzo ważna funkcja, wymagana dla każdego, kto musi dobrze dbać o swoje dane. Tutaj sprawy są bardziej złożone i mniej jasne. Na początek należy pamiętać, że MySQL RDS ukrywa logi binarne przed użytkownikiem. Możesz zmienić kilka ustawień i wyświetlić listę utworzonych binlogów, ale nie masz do nich bezpośredniego dostępu - aby wykonać jakąkolwiek operację, w tym użyć ich do odzyskiwania, możesz użyć tylko interfejsu użytkownika lub CLI. Ogranicza to twoje opcje do tego, co pozwala Amazon, i pozwala przywrócić kopię zapasową do ostatniego „czasu przywracania”, który jest obliczany w odstępach 5 minut. Jeśli więc Twoje dane zostały usunięte o godzinie 9:33a, możesz je przywrócić tylko do stanu o godzinie 9:30a. Odzyskiwanie do określonego momentu działa tak samo, jak przywracanie migawek — tworzona jest nowa instancja.
Skalowanie, replikacja
MySQL RDS umożliwia skalowanie w poziomie poprzez dodawanie nowych urządzeń podrzędnych. Po utworzeniu urządzenia podrzędnego wykonywana jest migawka urządzenia nadrzędnego, która służy do tworzenia nowego hosta. Ta część działa całkiem dobrze. Niestety nie można utworzyć bardziej złożonej topologii replikacji, jak ta z udziałem wzorców pośrednich. Nie jesteś w stanie stworzyć konfiguracji master - master, co pozostawia wszelkie HA w rękach Amazon (i wdrożeń multi-AZ). Z tego, co możemy powiedzieć, nie ma możliwości włączenia GTID (nie, żebyś mógł z niego skorzystać, ponieważ nie masz żadnej kontroli nad replikacją, nie ma CHANGE MASTER w RDS), tylko zwykłe, staromodne pozycje binlogów.
Brak GTID uniemożliwia korzystanie z replikacji wielowątkowej - o ile można ustawić liczbę pracowników za pomocą grup parametrów RDS, o tyle bez GTID jest to bezużyteczne. Główny problem polega na tym, że nie ma możliwości zlokalizowania pojedynczej pozycji dziennika binarnego w przypadku awarii – niektórzy pracownicy mogli być w tyle, inni mogą być bardziej zaawansowani. Jeśli użyjesz ostatnio zastosowanego zdarzenia, utracisz dane, które nie zostały jeszcze zastosowane przez tych „opóźnionych” pracowników. Jeśli użyjesz najstarszego zdarzenia, najprawdopodobniej skończysz z błędami „duplikatu klucza” spowodowanymi zdarzeniami zastosowanymi przez tych pracowników, którzy są bardziej zaawansowani. Oczywiście istnieje sposób na rozwiązanie tego problemu, ale nie jest to trywialne i czasochłonne - zdecydowanie nie jest to coś, co można łatwo zautomatyzować.
Użytkownicy stworzeni na MySQL RDS nie mają uprawnień SUPER, więc operacje, które są proste w samodzielnym MySQL, nie są trywialne w RDS. Amazon zdecydował się na użycie procedur składowanych, aby umożliwić użytkownikowi wykonanie niektórych z tych operacji. Z tego, co możemy powiedzieć, uwzględniono wiele potencjalnych problemów, chociaż nie zawsze tak było – pamiętamy, kiedy nie można było przejść do następnego dziennika binarnego na masterze. Awaria mastera + uszkodzenie binloga może spowodować uszkodzenie wszystkich slave'ów - teraz jest na to procedura:rds_next_master_log .
Slave można ręcznie awansować na mastera. Pozwoliłoby to na stworzenie pewnego rodzaju HA na szczycie mechanizmu multi-AZ (lub ominięcie go), ale stało się to bezcelowe, ponieważ nie możesz przełączyć żadnego z istniejących niewolników do nowego mastera. Pamiętaj, że nie masz żadnej kontroli nad replikacją. To sprawia, że całe ćwiczenie jest daremne - chyba że twój mistrz może obsłużyć cały ruch. Po wypromowaniu nowego mistrza nie jesteś w stanie przejść na niego awaryjnie, ponieważ nie ma żadnych niewolników do obsługi twojego ładunku. Rozkręcenie nowych urządzeń podrzędnych zajmie trochę czasu, ponieważ najpierw trzeba utworzyć migawki EBS, co może zająć godziny. Następnie musisz rozgrzać infrastrukturę, zanim będziesz mógł ją obciążać.
Brak SUPER przywileju
Jak wspomnieliśmy wcześniej, RDS nie przyznaje użytkownikom uprawnień SUPER, co staje się irytujące dla kogoś, kto jest przyzwyczajony do posiadania go na MySQL. Przyjmij za pewnik, że w pierwszych tygodniach dowiesz się, jak często wymagane jest robienie rzeczy, które robisz dość często – takich jak zabijanie zapytań lub obsługa schematu wydajności. W RDS będziesz musiał trzymać się predefiniowanej listy procedur składowanych i używać ich zamiast robić rzeczy bezpośrednio. Możesz je wszystkie wyświetlić za pomocą następującego zapytania:
SELECT specific_name FROM information_schema.routines;Podobnie jak w przypadku replikacji, wiele zadań jest objętych, ale jeśli znalazłeś się w sytuacji, która nie została jeszcze opisana, to nie masz szczęścia.
Interoperacyjność i konfiguracje chmury hybrydowej
Jest to kolejny obszar, w którym RDS brakuje elastyczności. Załóżmy, że chcesz zbudować mieszaną konfigurację chmurową/lokalną — masz infrastrukturę RDS i chcesz utworzyć kilka urządzeń podrzędnych lokalnie. Głównym problemem, z którym się zmierzysz, jest to, że nie ma możliwości przeniesienia danych z RDS, z wyjątkiem wykonania logicznego zrzutu. Możesz robić migawki danych RDS, ale nie masz do nich dostępu i nie możesz ich przenieść z AWS. Nie masz również fizycznego dostępu do instancji, aby korzystać z xtrabackup, rsync, a nawet cp. Jedyną opcją dla Ciebie jest użycie mysqldump, mydumper lub podobnych narzędzi. Zwiększa to złożoność (zestaw znaków i ustawienia sortowania mogą potencjalnie powodować problemy) i jest czasochłonne (zrzucanie i ładowanie danych za pomocą logicznych narzędzi do tworzenia kopii zapasowych zajmuje dużo czasu).
Możliwe jest skonfigurowanie replikacji między RDS a instancją zewnętrzną (w obie strony, więc migracja danych do RDS jest również możliwa), ale może to być bardzo czasochłonny proces.
Z drugiej strony, jeśli chcesz pozostać w środowisku RDS i rozciągać swoją infrastrukturę na całym Atlantyku lub od wschodniego do zachodniego wybrzeża Stanów Zjednoczonych, RDS pozwala to zrobić – możesz łatwo wybrać region podczas tworzenia nowego niewolnika.
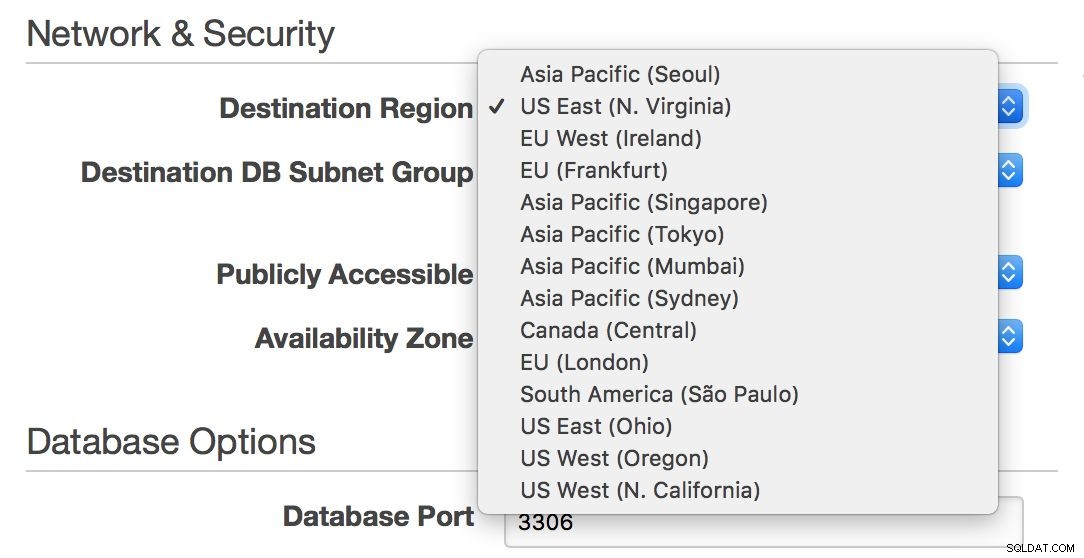
Niestety, jeśli chcesz przenieść swojego mastera z jednego regionu do drugiego, jest to praktycznie niemożliwe bez przestoju – chyba że Twój pojedynczy węzeł może obsłużyć cały ruch.
Bezpieczeństwo
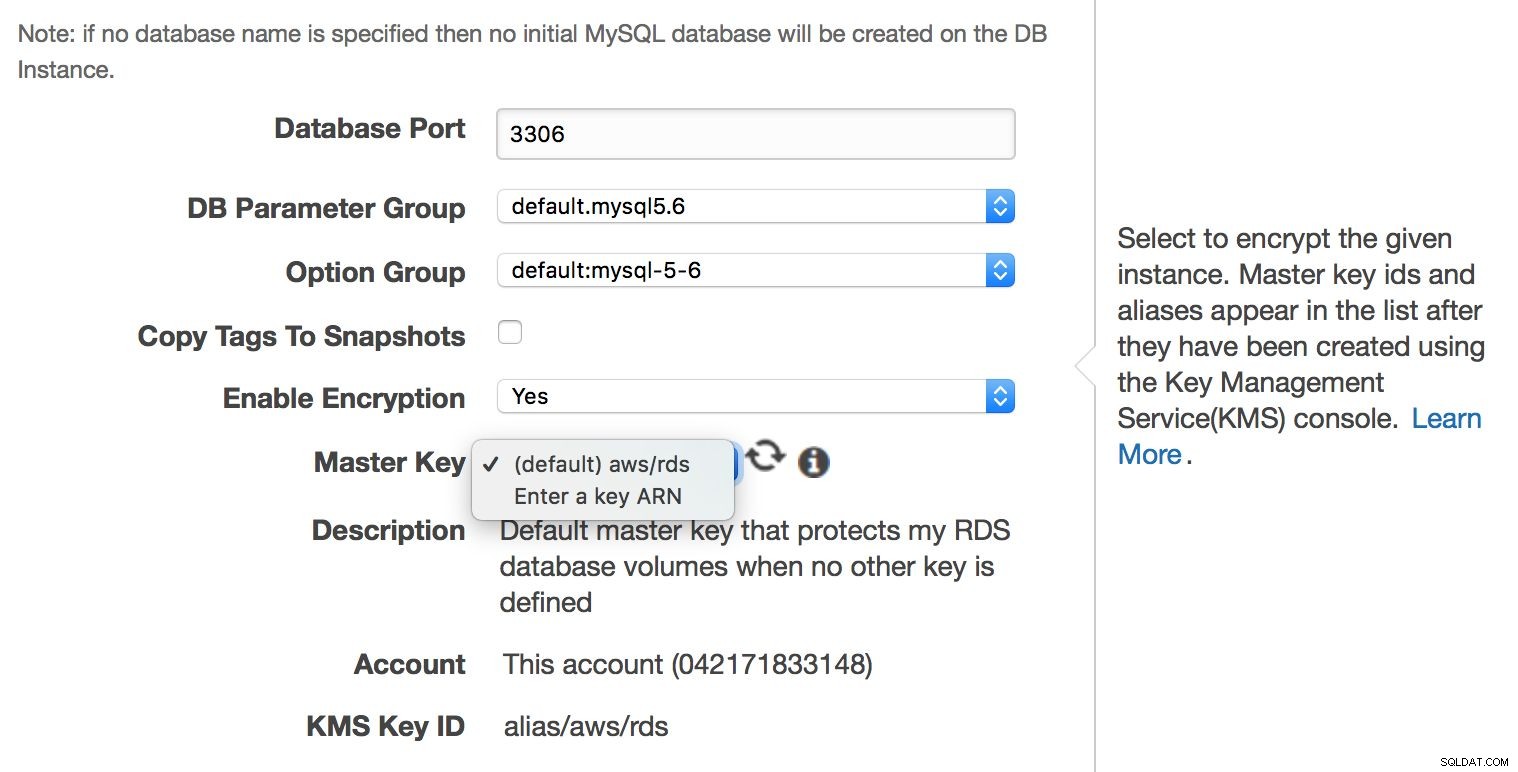
O ile MySQL RDS jest usługą zarządzaną, to inżynierowie Amazona nie zajmują się każdym aspektem związanym z bezpieczeństwem. Amazon nazywa to „Modelem wspólnej odpowiedzialności”. W skrócie Amazon dba o bezpieczeństwo warstwy sieciowej i przechowywania (aby dane były przesyłane w bezpieczny sposób), systemu operacyjnego (łatki, poprawki bezpieczeństwa). Z drugiej strony użytkownik musi zadbać o resztę modelu bezpieczeństwa. Upewnij się, że ruch do i z instancji RDS jest ograniczony w ramach VPC, upewnij się, że uwierzytelnianie na poziomie bazy danych jest wykonane prawidłowo (brak kont użytkowników MySQL bez hasła), sprawdź, czy zapewnione jest bezpieczeństwo API (AMI są ustawione poprawnie i z minimalnymi wymaganymi uprawnieniami). Użytkownik powinien również zadbać o ustawienia zapory (grupy bezpieczeństwa), aby zminimalizować ekspozycję RDS i VPC na sieci zewnętrzne. Obowiązkiem użytkownika jest również zaimplementowanie szyfrowania danych w stanie spoczynku - na poziomie aplikacji lub na poziomie bazy danych, tworząc w pierwszej kolejności zaszyfrowaną instancję RDS.
Szyfrowanie na poziomie bazy danych można włączyć tylko podczas tworzenia instancji, nie można zaszyfrować istniejącej, już działającej bazy danych.
Ograniczenia RDS
Jeśli planujesz korzystać z RDS lub już z niego korzystasz, musisz zdawać sobie sprawę z ograniczeń związanych z MySQL RDS.
Brak SUPER przywilejów może być, jak wspomnieliśmy, bardzo irytujące. Chociaż procedury składowane zajmują się wieloma operacjami, jest to krzywa uczenia się, ponieważ musisz nauczyć się robić rzeczy w inny sposób. Brak uprawnień SUPER może również stwarzać problemy w korzystaniu z zewnętrznych narzędzi do monitorowania i wyznaczania trendów - wciąż istnieją narzędzia, które mogą wymagać tego uprawnienia dla pewnej części swojej funkcjonalności.
Brak bezpośredniego dostępu do katalogu danych i dzienników MySQL utrudnia wykonywanie działań co ich dotyczy. Od czasu do czasu zdarza się, że administrator DBA musi przeanalizować logi binarne lub błąd ogona, wolne zapytanie lub dziennik ogólny. Chociaż możliwy jest dostęp do tych dzienników w RDS, jest to bardziej kłopotliwe niż robienie czegokolwiek przez zalogowanie się do powłoki na hoście MySQL. Pobieranie ich lokalnie również zajmuje trochę czasu i dodaje dodatkowe opóźnienie do wszystkiego, co robisz.
Brak kontroli nad topologią replikacji, wysoka dostępność tylko we wdrożeniach multi-AZ. Biorąc pod uwagę, że nie masz kontroli nad replikacją, nie możesz zaimplementować żadnego mechanizmu wysokiej dostępności w warstwie bazy danych. Nie ma znaczenia, że masz kilku niewolników, nie możesz użyć niektórych z nich jako kandydatów na mistrza, ponieważ nawet jeśli awansujesz niewolnika na mistrza, nie ma możliwości zniewolenia pozostałych niewolników z tego nowego mistrza. Zmusza to użytkowników do korzystania z wdrożeń multi-AZ i zwiększa koszty (instancja „cienia” nie jest bezpłatna, użytkownik musi za nią zapłacić).
Zmniejszona dostępność z powodu planowanych przestojów. Podczas wdrażania wystąpienia RDS jesteś zmuszony wybrać tygodniowy przedział czasowy 30 minut, podczas którego operacje konserwacyjne mogą być wykonywane na wystąpieniu RDS. Z jednej strony jest to zrozumiałe, ponieważ RDS jest bazą danych jako usługą, więc aktualizacje sprzętu i oprogramowania instancji RDS są zarządzane przez inżynierów AWS. Z drugiej strony zmniejsza to dostępność, ponieważ nie można zapobiec wyłączeniu bazy danych master w okresie konserwacji. Ponownie, w tym przypadku użycie konfiguracji multi-AZ zwiększa dostępność, ponieważ zmiany zachodzą najpierw w wystąpieniu cienia, a następnie wykonywane jest przełączanie awaryjne. Jednak samo przełączanie awaryjne nie jest przejrzyste, więc w taki czy inny sposób tracisz czas pracy bez przestojów. Zmusza to do zaprojektowania aplikacji z myślą o nieoczekiwanych awariach wzorca MySQL. Nie znaczy to, że jest to zły wzorzec projektowy — bazy danych mogą ulec awarii w dowolnym momencie, a Twoja aplikacja powinna być zbudowana w taki sposób, aby wytrzymała nawet najtrudniejszy scenariusz. Po prostu dzięki RDS masz ograniczone możliwości wysokiej dostępności.
Ograniczone opcje implementacji wysokiej dostępności. Biorąc pod uwagę brak elastyczności w zarządzaniu topologią replikacji, jedyną możliwą metodą wysokiej dostępności jest wdrażanie multi-AZ. Ta metoda jest dobra, ale istnieją narzędzia do replikacji MySQL, które jeszcze bardziej zminimalizują przestoje. Na przykład, MHA lub ClusterControl, gdy są używane w połączeniu z ProxySQL, mogą zapewnić (w pewnych warunkach, takich jak brak długotrwałych transakcji) przejrzysty proces przełączania awaryjnego dla aplikacji. Podczas korzystania z RDS nie będziesz mógł korzystać z tej metody.
Zredukowany wgląd w wydajność Twojej bazy danych. Chociaż możesz uzyskać metryki z samego MySQL, czasami nie wystarczy uzyskać pełny obraz sytuacji z 10 tys. stóp. W pewnym momencie większość użytkowników będzie musiała zmierzyć się z naprawdę dziwnymi problemami spowodowanymi przez wadliwy sprzęt lub wadliwą infrastrukturę - utracone pakiety sieciowe, nagle zrywane połączenia lub nieoczekiwanie wysokie wykorzystanie procesora. Gdy masz dostęp do swojego hosta MySQL, możesz skorzystać z wielu narzędzi, które pomogą Ci zdiagnozować stan serwera Linux. Korzystając z RDS, ograniczasz się do tego, jakie metryki są dostępne w Cloudwatch, narzędziu Amazon do monitorowania i wyznaczania trendów. Każda bardziej szczegółowa diagnoza wymaga skontaktowania się z pomocą techniczną i poproszenia o sprawdzenie i naprawienie problemu. Może to być szybkie, ale może być również bardzo długim procesem z dużą ilością komunikacji e-mail w obie strony.
Blokada dostawcy spowodowana złożonym i czasochłonnym procesem pobierania danych z MySQL RDS. RDS nie zapewnia dostępu do katalogu danych MySQL, więc nie ma możliwości wykorzystania standardowych narzędzi branżowych, takich jak xtrabackup, do przenoszenia danych w sposób binarny. Z drugiej strony RDS pod maską to MySQL utrzymywany przez Amazon, trudno powiedzieć, czy jest w 100% kompatybilny z upstreamem, czy nie. RDS jest dostępny tylko w AWS, więc nie będziesz w stanie przeprowadzić konfiguracji hybrydowej.
Podsumowanie
MySQL RDS ma zarówno mocne, jak i słabe strony. To bardzo dobre narzędzie dla tych, którzy chcą skupić się na aplikacji bez martwienia się o obsługę bazy danych. Wdrażasz bazę danych i zaczynasz wysyłać zapytania. Nie ma potrzeby tworzenia skryptów do tworzenia kopii zapasowych ani konfigurowania rozwiązania do monitorowania, ponieważ zostało to już zrobione przez inżynierów AWS – wystarczy, że z niego skorzystasz.
Istnieje również ciemna strona MySQL RDS. Brak opcji budowania bardziej złożonych konfiguracji i skalowania poza dodawaniem większej liczby niewolników. Brak wsparcia dla lepszej wysokiej dostępności niż to, co jest proponowane w przypadku wdrożeń multi-AZ. Uciążliwy dostęp do logów MySQL. Brak bezpośredniego dostępu do katalogu danych MySQL i brak obsługi fizycznych kopii zapasowych, co utrudnia przeniesienie danych poza instancję RDS.
Podsumowując, RDS może działać dobrze, jeśli cenisz łatwość obsługi nad szczegółową kontrolę bazy danych. Musisz pamiętać, że w przyszłości możesz wyrosnąć z MySQL RDS. Niekoniecznie mówimy tu tylko o wydajności. Chodzi bardziej o potrzeby organizacji w zakresie bardziej złożonej topologii replikacji lub o lepszy wgląd w operacje bazy danych, aby szybko radzić sobie z różnymi pojawiającymi się od czasu do czasu problemami. W takim przypadku, jeśli Twój zestaw danych już się rozrósł, może okazać się trudne wyjście z RDS. Przed podjęciem jakiejkolwiek decyzji o przeniesieniu danych do RDS, menedżerowie informacji muszą wziąć pod uwagę wymagania i ograniczenia swojej organizacji w określonych obszarach.
W kilku następnych wpisach na blogu pokażemy, jak przenieść swoje dane z RDS do osobnej lokalizacji. Omówimy zarówno migrację do EC2, jak i do infrastruktury lokalnej.