Budowanie wysokiej dostępności, krok po kroku
Jeśli chodzi o infrastrukturę bazodanową, wszyscy jej chcemy. Wszyscy staramy się zbudować wysoce dostępny zestaw. Kluczem jest redundancja. Rozpoczynamy wdrażanie redundancji na najniższym poziomie i kontynuujemy w górę stosu. Zaczyna się od sprzętu — nadmiarowych zasilaczy, nadmiarowego chłodzenia, dysków hot-swap. Warstwa sieciowa — wiele kart sieciowych połączonych ze sobą i podłączonych do różnych przełączników korzystających z routerów nadmiarowych. Do przechowywania używamy dysków ustawionych w RAID, co zapewnia lepszą wydajność, ale także redundancję. Następnie na poziomie oprogramowania wykorzystujemy technologie klastrowania:wiele węzłów baz danych współpracujących ze sobą w celu wdrożenia redundancji:MySQL Cluster, Galera Cluster.
Wszystko to nie jest dobre, jeśli masz wszystko w jednym centrum danych:gdy centrum danych ulegnie awarii lub część usług (ale ważnych) przejdzie w tryb offline, a nawet jeśli utracisz łączność z centrum danych, Twoja usługa przestanie działać – bez względu na ilość nadmiarowości na niższych poziomach. I tak, takie rzeczy się zdarzają.
- Zakłócenia w usługach S3 spowodowały spustoszenie w regionie USA-Wschód-1 w lutym 2017 r.
- Zakłócenia usług EC2 i RDS w regionie wschodnim USA w kwietniu 2011 r.
- EC2, EBS i RDS zostały zakłócone w regionie UE-Zachód w sierpniu 2011 r.
- Awaria zasilania spowodowała awarię Rackspace Texas DC w czerwcu 2009 r.
- Awaria UPS spowodowała wyłączenie setek serwerów w Rackspace London DC w styczniu 2010 r.
To bynajmniej nie jest pełna lista niepowodzeń, to tylko wynik szybkiego wyszukiwania w Google. Służą one jako przykłady tego, że wszystko może i pójdzie nie tak, jeśli włożysz wszystkie jajka do tego samego koszyka. Innym przykładem może być huragan Sandy, który spowodował ogromny exodus danych ze wschodu USA do zachodnich DC – w tym czasie trudno było uruchomić instancje na zachodzie USA, ponieważ wszyscy w oczekiwaniu pospieszyli z przeniesieniem swojej infrastruktury na drugie wybrzeże. że pogoda w Północnej Wirginii będzie poważnie ucierpiała.
Tak więc konfiguracje z wieloma centrami danych są koniecznością, jeśli chcesz zbudować środowisko o wysokiej dostępności. W tym poście na blogu omówimy, jak zbudować taką infrastrukturę przy użyciu Galera Cluster for MySQL/MariaDB.
Koncepcje Galery
Zanim przyjrzymy się konkretnym rozwiązaniom, poświęćmy trochę czasu na wyjaśnienie dwóch koncepcji, które są bardzo ważne w wysoce dostępnych konfiguracjach multi-DC Galera.
Kworum
Wysoka dostępność wymaga zasobów — a mianowicie, aby zapewnić wysoką dostępność, potrzebujesz kilku węzłów w klastrze. Klaster może tolerować utratę części swoich członków, ale tylko do pewnego stopnia. Poza pewnym wskaźnikiem niepowodzeń możesz patrzeć na scenariusz z rozszczepionym mózgiem.
Weźmy przykład z konfiguracją 2 węzłów. Jeśli jeden z węzłów ulegnie awarii, skąd drugi może wiedzieć, że jego peer uległ awarii i nie jest to awaria sieci? W takim przypadku drugi węzeł może równie dobrze działać i obsługiwać ruch. Nie ma dobrego sposobu na poradzenie sobie z takim przypadkiem… Dlatego odporność na awarie zwykle zaczyna się od trzech węzłów. Galera używa obliczenia kworum, aby określić, czy klaster może bezpiecznie obsługiwać ruch, czy też powinien zaprzestać działania. Po awarii wszystkie pozostałe węzły próbują połączyć się ze sobą i określić, ile z nich działa. Następnie jest porównywany z poprzednim stanem klastra i dopóki działa ponad 50% węzłów, klaster może nadal działać.
Skutkuje to następującymi efektami:
Klaster z 2 węzłami - brak odporności na błędy
Klaster z 3 węzłami - do 1 awarii
Klaster z 4 węzłami - do 1 awarii (w przypadku awarii dwóch węzłów, tylko 50% klastra byłoby dostępne, potrzebujesz ponad 50% węzłów, aby przetrwać)
Klaster z 5 węzłami — do 2 awarii
Klaster z 6 węzłami — do 2 awarii
Prawdopodobnie widzisz wzorzec — chcesz, aby Twój klaster miał nieparzystą liczbę węzłów — pod względem wysokiej dostępności nie ma sensu przenosić się z 5 do 6 węzłów w klastrze. Jeśli chcesz mieć lepszą odporność na awarie, powinieneś wybrać 7 węzłów.
Segmenty
Zazwyczaj w klastrze Galera wszelka komunikacja przebiega według wzorca „wszystko do wszystkich”. Każdy węzeł komunikuje się ze wszystkimi pozostałymi węzłami w klastrze.
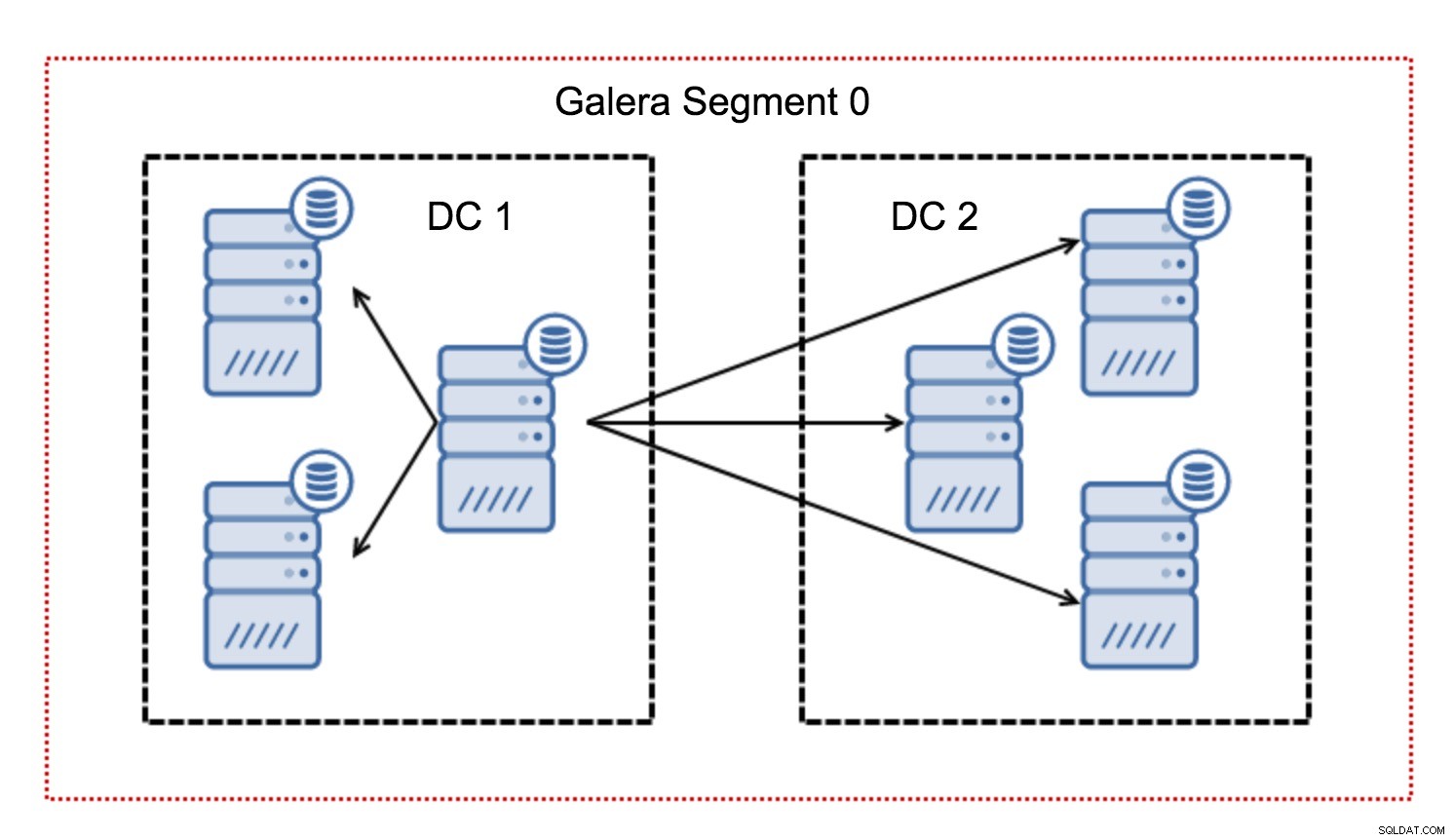
Jak być może wiesz, każdy zapis w Galerze musi być certyfikowany przez wszystkie węzły w klastrze - dlatego każdy zapis, który miał miejsce na węźle, musi zostać przeniesiony do wszystkich węzłów w klastrze. Działa to dobrze w środowisku o niskich opóźnieniach. Ale jeśli mówimy o konfiguracjach multi-DC, musimy wziąć pod uwagę znacznie większe opóźnienia niż w sieci lokalnej. Aby uczynić go bardziej znośnym w klastrach obejmujących sieci rozległe, Galera wprowadziła segmenty.
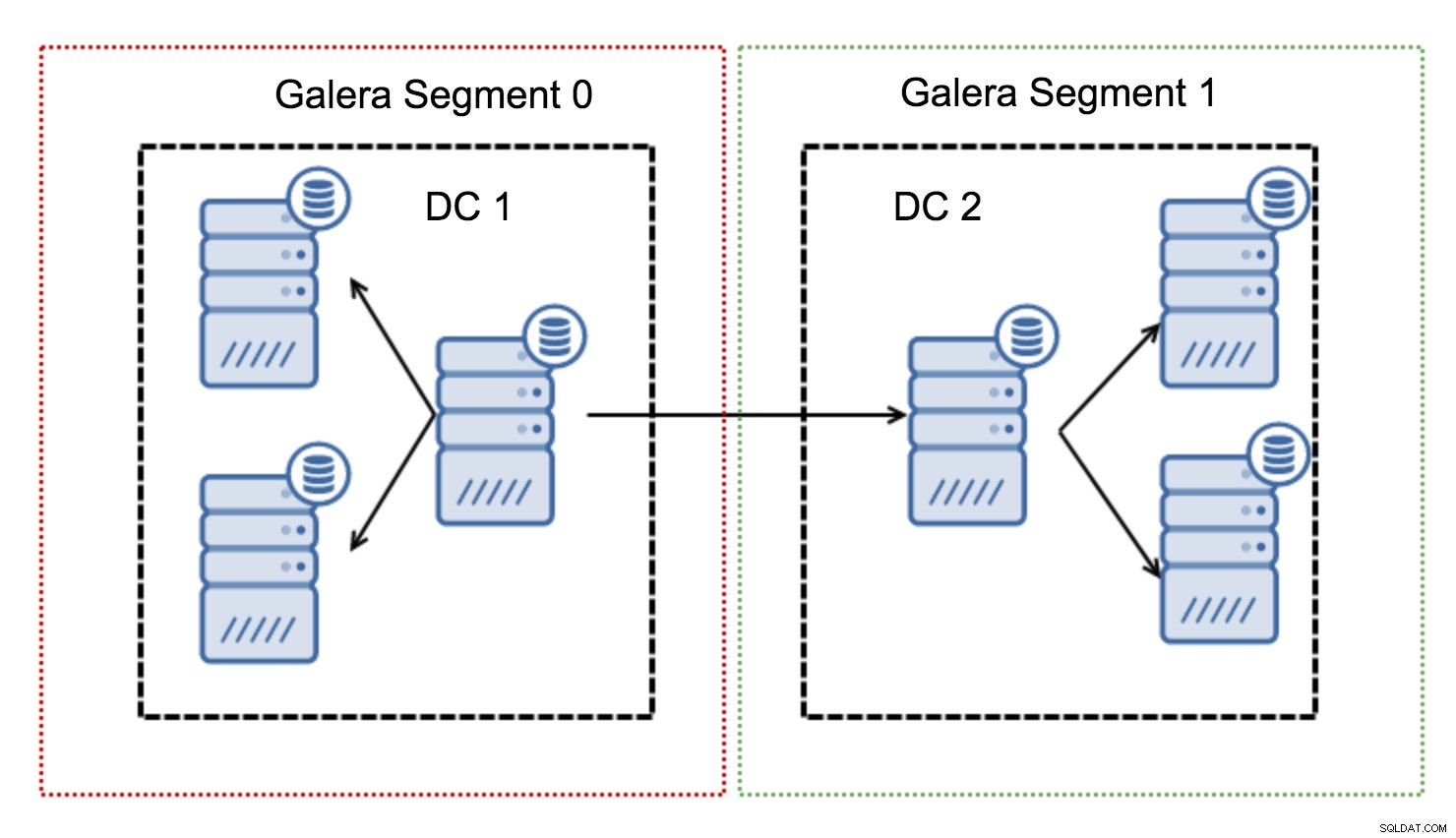
Działają poprzez blokowanie ruchu Galera w grupie węzłów (segmentu). Wszystkie węzły w ramach jednego segmentu działają tak, jakby znajdowały się w sieci lokalnej – zakładają komunikację jeden do wszystkich. W przypadku ruchu międzysegmentowego sytuacja wygląda inaczej – w każdym z segmentów wybierany jest jeden węzeł „przekaźnikowy”, cały ruch międzysegmentowy przechodzi przez te węzły. Kiedy węzeł przekaźnikowy ulegnie awarii, wybierany jest inny węzeł. Nie zmniejsza to znacząco opóźnień — w końcu opóźnienia WAN pozostaną takie same bez względu na to, czy nawiążesz połączenie z jednym zdalnym hostem, czy z wieloma zdalnymi hostami, ale biorąc pod uwagę, że łącza WAN mają zwykle ograniczoną przepustowość i może wystąpić opłata za ilość przesłanych danych, takie podejście pozwala ograniczyć ilość danych wymienianych pomiędzy segmentami. Inną opcją pozwalającą na oszczędność czasu i kosztów jest to, że węzły w tym samym segmencie mają priorytet, gdy potrzebny jest dawca - ponownie ogranicza to ilość danych przesyłanych przez WAN i najprawdopodobniej przyspiesza SST jako sieć lokalna prawie zawsze będzie szybsze niż łącze WAN.
Teraz, gdy już usunęliśmy niektóre z tych koncepcji, przyjrzyjmy się innym ważnym aspektom konfiguracji multi-DC dla klastra Galera.
Problemy, z którymi się zmierzysz
Podczas pracy w środowiskach obejmujących sieć WAN należy wziąć pod uwagę kilka kwestii podczas projektowania środowiska.
Obliczanie kworum
W poprzedniej sekcji opisaliśmy, jak wygląda obliczanie kworum w klastrze Galera — w skrócie, chcesz mieć nieparzystą liczbę węzłów, aby zmaksymalizować przeżywalność. Wszystko to jest nadal prawdziwe w konfiguracjach multi-DC, ale do miksu dodano kilka dodatkowych elementów. Przede wszystkim musisz zdecydować, czy Galera ma automatycznie obsługiwać awarię centrum danych. To określi, z ilu centrów danych będziesz korzystać. Wyobraźmy sobie dwa kontrolery domeny – jeśli podzielisz swoje węzły 50% - 50%, jeśli jedno centrum danych ulegnie awarii, drugie nie ma 50% + 1 węzłów, aby utrzymać swój stan „podstawowy”. Jeśli podzielisz węzły w nierówny sposób, używając większości z nich w „głównym” centrum danych, gdy to centrum danych ulegnie awarii, „zapasowy” kontroler domeny nie będzie miał 50% + 1 węzłów, aby utworzyć kworum. Możesz przypisać różne wagi do węzłów, ale wynik będzie dokładnie taki sam – nie ma możliwości automatycznego przełączania awaryjnego między dwoma kontrolerami domeny bez ręcznej interwencji. Aby wdrożyć automatyczne przełączanie awaryjne, potrzebujesz więcej niż dwóch kontrolerów domeny. Ponownie, idealnie nieparzysta liczba - trzy centra danych to idealnie dobra konfiguracja. Następnie pytanie brzmi - ile węzłów musisz mieć? Chcesz, aby były równomiernie rozłożone w centrach danych. Reszta to tylko kwestia tego, ile uszkodzonych węzłów musi obsłużyć Twoja konfiguracja.
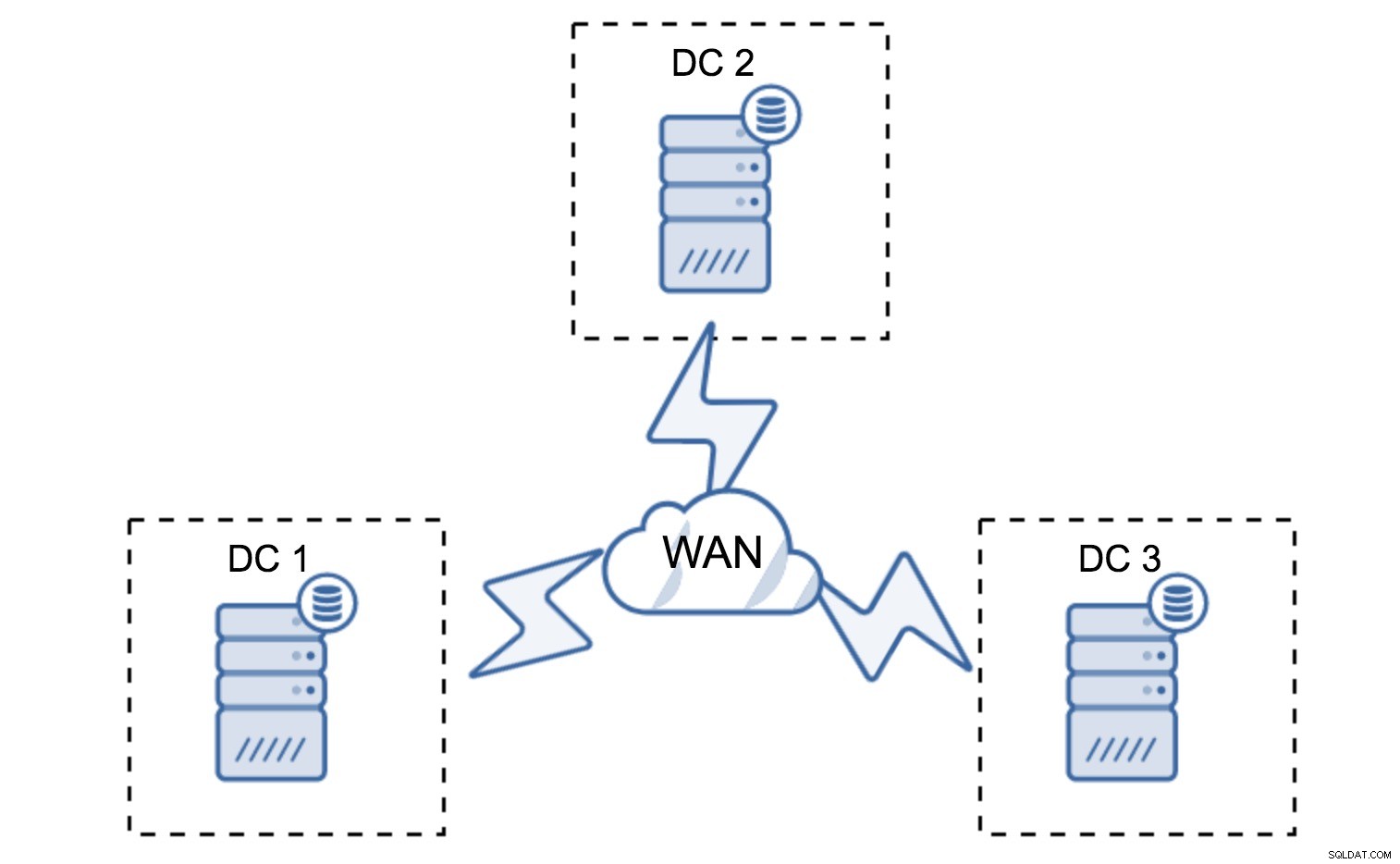
Minimalna konfiguracja będzie wykorzystywać jeden węzeł na centrum danych - ma jednak poważne wady. Każdy transfer stanu będzie wymagał przeniesienia danych przez sieć WAN, co skutkuje dłuższym czasem potrzebnym na ukończenie SST lub wyższymi kosztami.
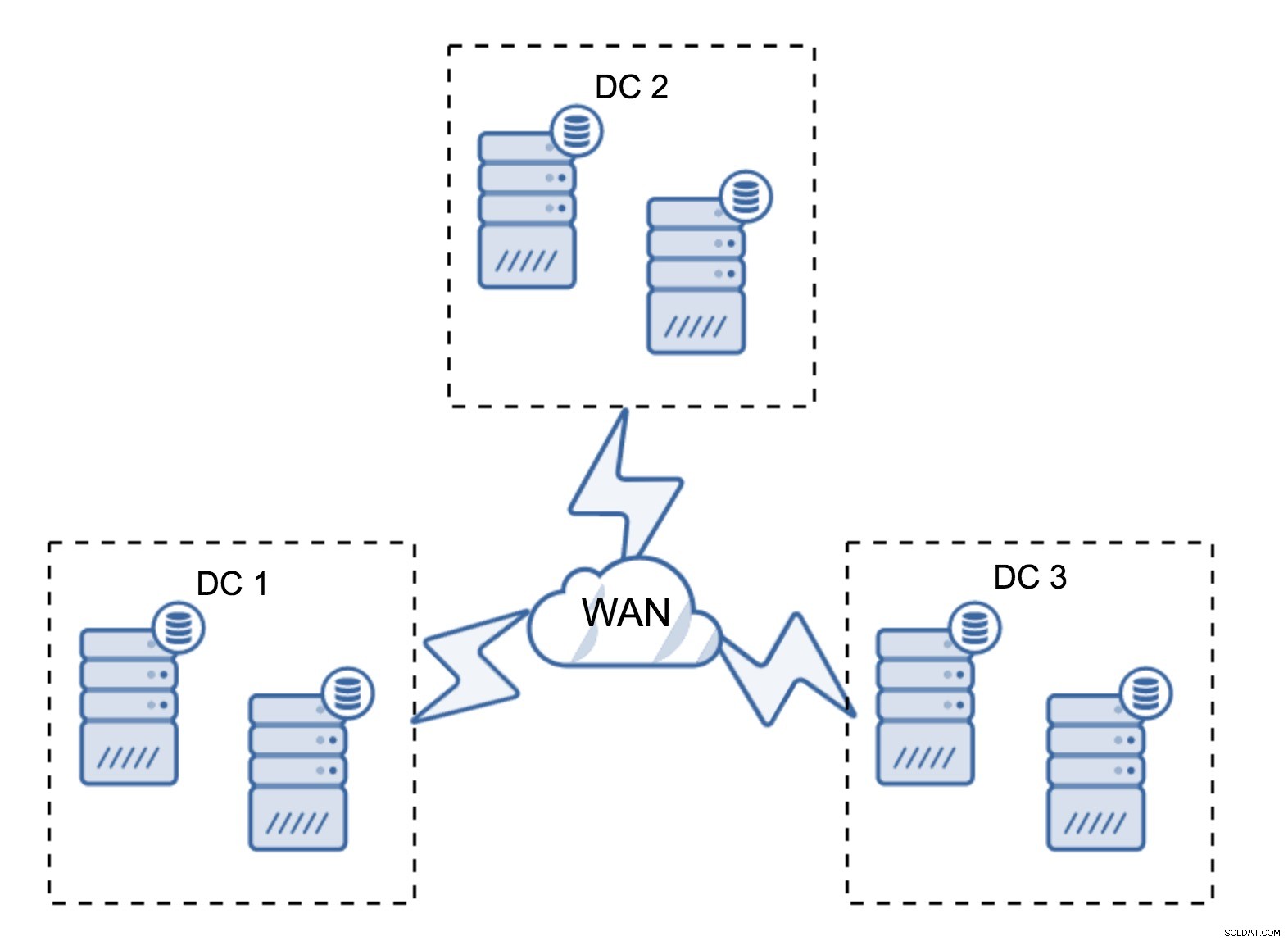
Całkiem typowa konfiguracja to sześć węzłów, po dwa na centrum danych. Ta konfiguracja wydaje się nieoczekiwana, ponieważ ma parzystą liczbę węzłów. Ale kiedy się nad tym zastanowisz, może to nie być aż tak duży problem:jest mało prawdopodobne, że trzy węzły ulegną awarii jednocześnie, a taka konfiguracja przetrwa awarię do dwóch węzłów. Całe centrum danych może przejść w tryb offline, a dwa pozostałe DC będą kontynuować swoją działalność. Ma również ogromną przewagę nad minimalną konfiguracją — gdy węzeł przechodzi w tryb offline, w centrum danych zawsze znajduje się drugi węzeł, który może służyć jako dawca. W większości przypadków sieć WAN nie będzie używana do SST.
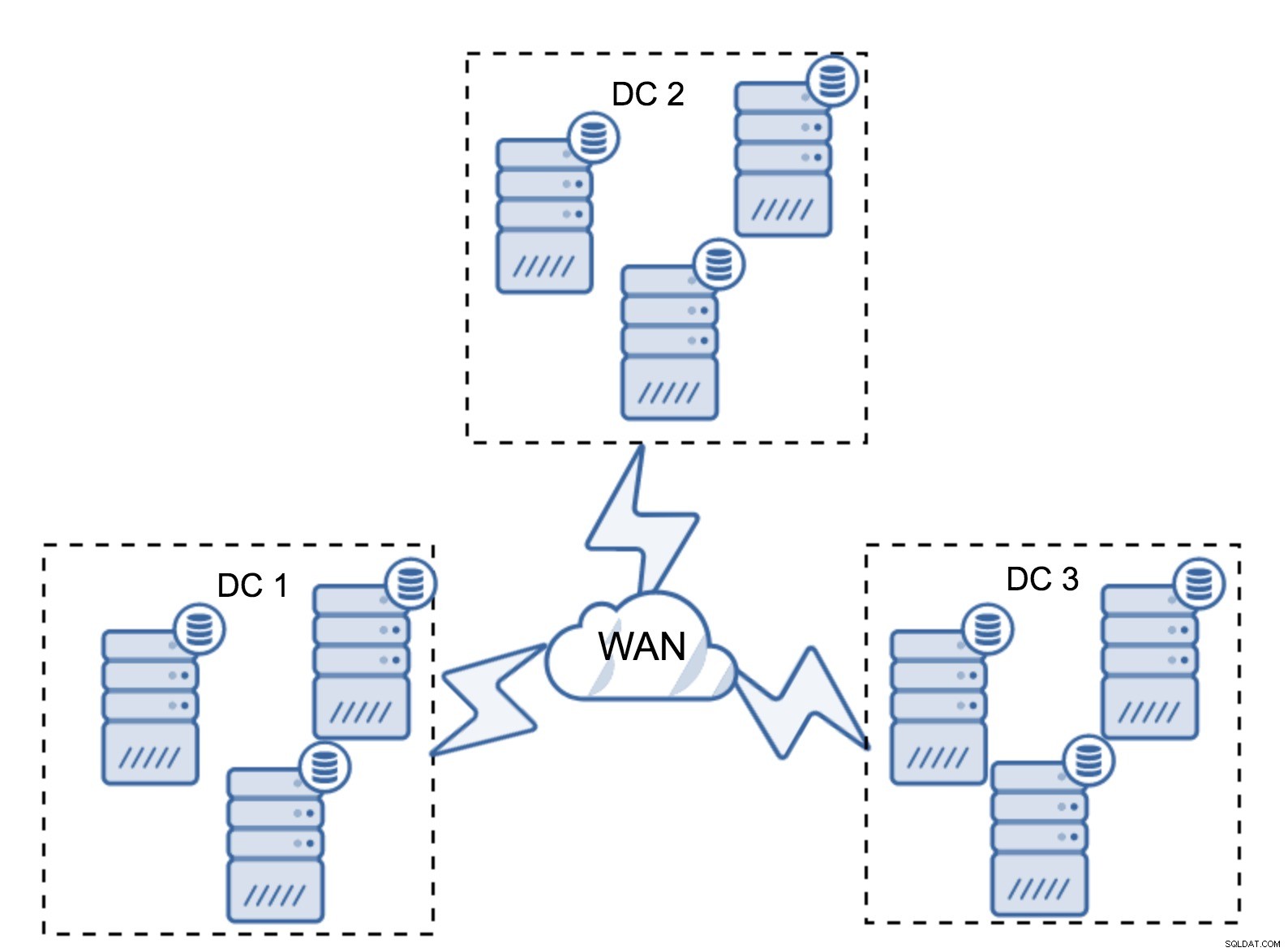
Oczywiście możesz zwiększyć liczbę węzłów do trzech na klaster, łącznie do dziewięciu. Zapewnia to jeszcze lepszą przeżywalność:do czterech węzłów może ulec awarii, a klaster nadal przetrwa. Z drugiej strony musisz pamiętać, że nawet przy użyciu segmentów, więcej węzłów oznacza wyższe koszty operacyjne i możesz skalować klaster Galera tylko do pewnego stopnia.
Może się zdarzyć, że nie będzie potrzebne trzecie centrum danych, ponieważ powiedzmy, że Twoja aplikacja znajduje się tylko w dwóch z nich. Oczywiście wymóg trzech centrów danych jest nadal ważny, więc nie będziesz go obchodzić, ale całkowicie w porządku jest użycie Galera Arbitrator (garbd) zamiast w pełni obciążonych serwerów baz danych.
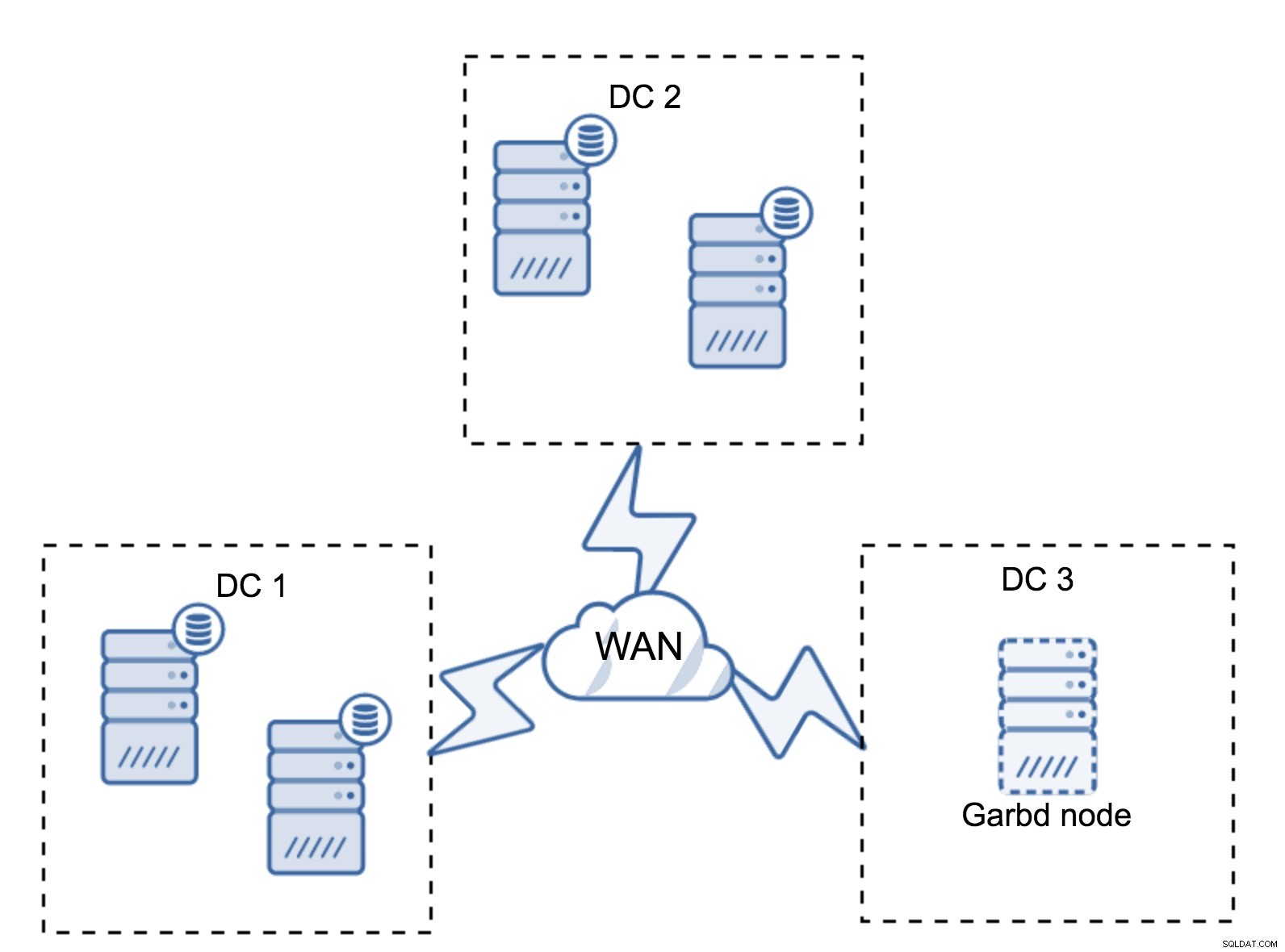
Garbd można zainstalować na mniejszych węzłach, nawet na serwerach wirtualnych. Nie wymaga wydajnego sprzętu, nie przechowuje żadnych danych ani nie stosuje żadnego zestawu zapisów. Ale widzi cały ruch związany z replikacją i bierze udział w obliczaniu kworum. Dzięki niemu możesz wdrożyć takie konfiguracje jak cztery węzły, dwa na DC + garbd w trzecim - w sumie masz pięć węzłów, a taki klaster może przyjąć do dwóch awarii. Oznacza to, że może zaakceptować całkowite zamknięcie jednego z centrów danych.
Która opcja jest dla Ciebie lepsza? Nie ma najlepszego rozwiązania dla wszystkich przypadków, wszystko zależy od wymagań Twojej infrastruktury. Na szczęście są różne opcje do wyboru:mniej lub więcej węzłów, pełne 3 DC lub 2 DC i garbd w trzecim - całkiem prawdopodobne, że znajdziesz coś odpowiedniego dla siebie.
Opóźnienie sieci
Podczas pracy z konfiguracjami multi-DC należy pamiętać, że opóźnienie sieci będzie znacznie wyższe niż to, czego można oczekiwać od lokalnego środowiska sieciowego. Może to poważnie obniżyć wydajność klastra Galera w porównaniu z samodzielną instancją MySQL lub konfiguracją replikacji MySQL. Wymóg, że wszystkie węzły muszą certyfikować zestaw zapisów, oznacza, że wszystkie węzły muszą go otrzymać, bez względu na to, jak daleko się znajdują. Dzięki replikacji asynchronicznej nie trzeba czekać na zatwierdzenie. Oczywiście replikacja ma inne problemy i wady, ale opóźnienie nie jest najważniejszą z nich. Problem jest szczególnie widoczny, gdy w Twojej bazie znajdują się hot spoty - wiersze, które są często aktualizowane (liczniki, kolejki itp.). Te wiersze nie mogą być aktualizowane częściej niż raz na podróż w obie strony przez sieć. W przypadku klastrów na całym świecie może to łatwo oznaczać, że nie będziesz w stanie aktualizować jednego wiersza częściej niż 2-3 razy na sekundę. Jeśli stanie się to dla Ciebie ograniczeniem, może to oznaczać, że klaster Galera nie jest odpowiedni dla Twojego konkretnego obciążenia.
Warstwa proxy w klastrze Multi-DC Galera
Nie wystarczy mieć klaster Galera obejmujący wiele centrów danych, nadal potrzebujesz swojej aplikacji, aby uzyskać do nich dostęp. Jedną z popularnych metod ukrywania przed aplikacją złożoności warstwy bazy danych jest wykorzystanie proxy. Serwery proxy są używane jako punkt wejścia do baz danych, śledzą stan węzłów bazy danych i powinny zawsze kierować ruch tylko do dostępnych węzłów. W tej sekcji postaramy się zaproponować projekt warstwy proxy, który można wykorzystać w klastrze multi-DC Galera. Użyjemy ProxySQL, który daje ci dość dużą elastyczność w obsłudze węzłów bazy danych, ale możesz użyć innego proxy, o ile może śledzić stan węzłów Galera.
Gdzie znaleźć proxy?
W skrócie, istnieją tutaj dwa typowe wzorce:możesz wdrożyć ProxySQL na osobnych węzłach lub możesz wdrożyć je na hostach aplikacji. Rzućmy okiem na zalety i wady każdej z tych konfiguracji.
Warstwa proxy jako oddzielny zestaw hostów
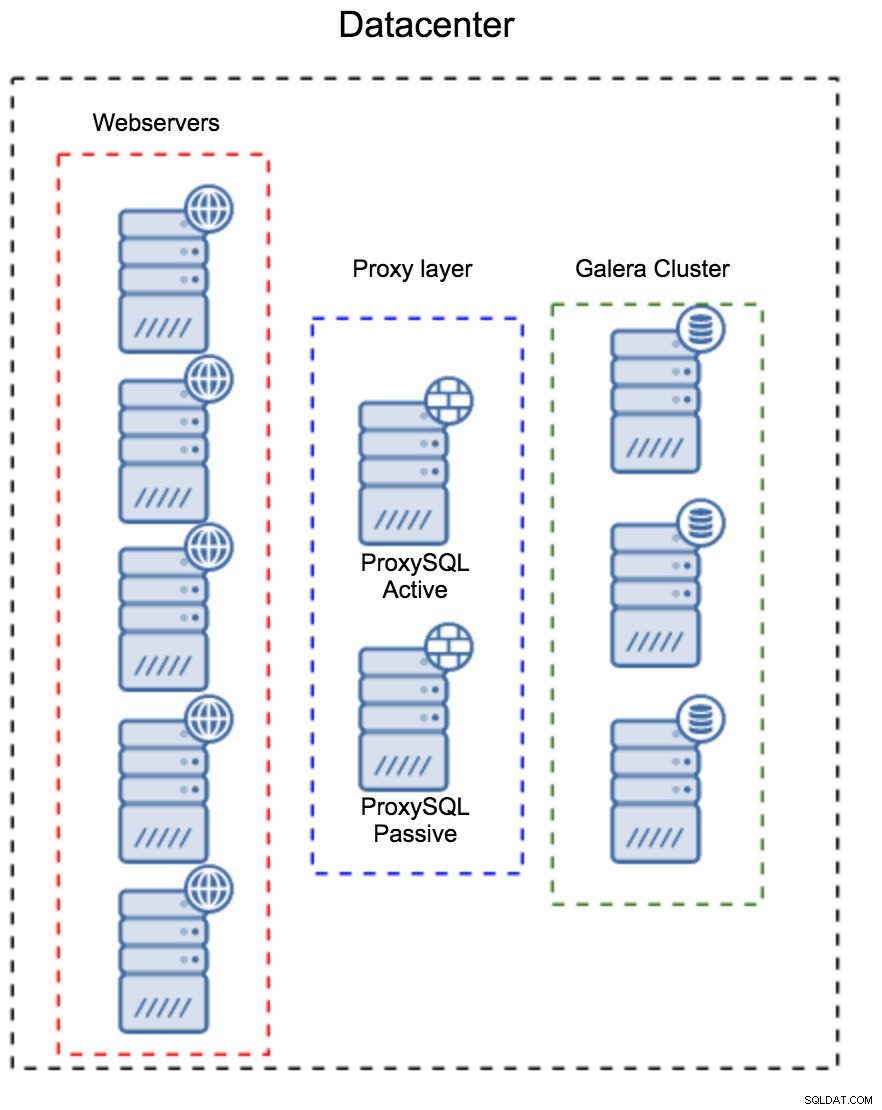
Pierwszym wzorcem jest zbudowanie warstwy proxy przy użyciu oddzielnych, dedykowanych hostów. Możesz wdrożyć ProxySQL na kilku hostach oraz używać wirtualnego adresu IP i utrzymywania aktywności w celu utrzymania wysokiej dostępności. Aplikacja będzie używać adresu VIP do łączenia się z bazą danych, a adres VIP zapewni, że żądania będą zawsze kierowane do dostępnego serwera ProxySQL. Głównym problemem związanym z tą konfiguracją jest to, że używasz co najwyżej jednej instancji ProxySQL — wszystkie węzły rezerwowe nie są używane do kierowania ruchu. Może to zmusić Cię do użycia mocniejszego sprzętu niż zwykle. Z drugiej strony łatwiej jest utrzymać konfigurację - będziesz musiał zastosować zmiany w konfiguracji na wszystkich węzłach ProxySQL, ale będzie ich tylko kilka. Możesz także wykorzystać opcję ClusterControl do synchronizacji węzłów. Taka konfiguracja będzie musiała zostać zduplikowana w każdym używanym centrum danych.
Proxy zainstalowane w instancjach aplikacji
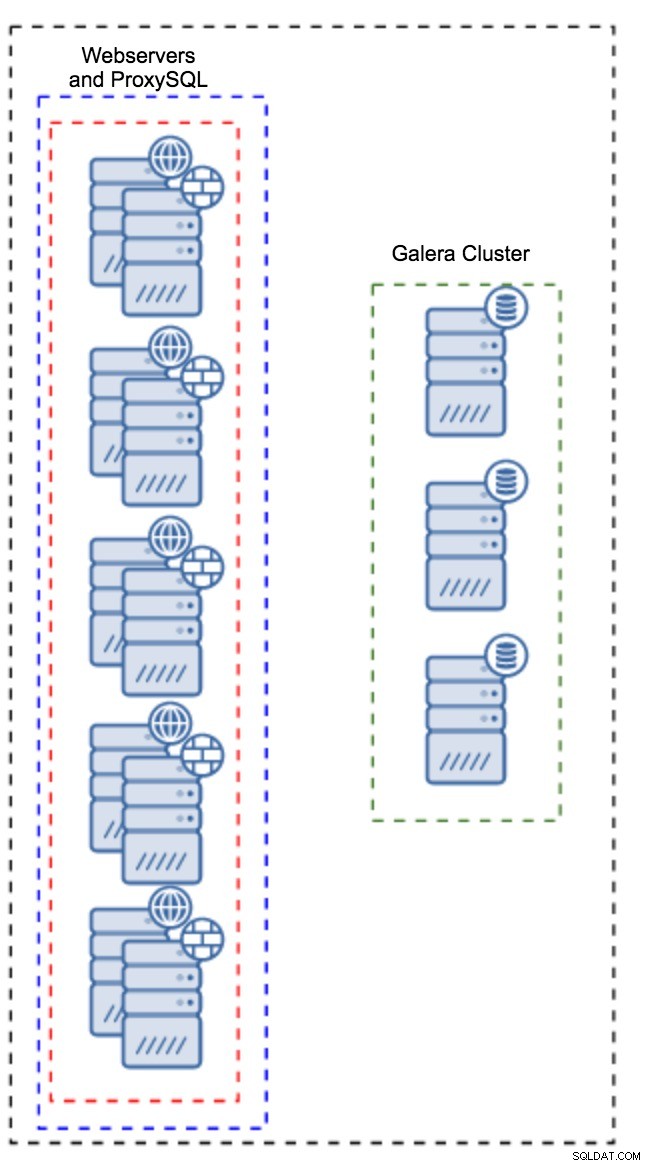
Zamiast posiadania oddzielnego zestawu hostów, ProxySQL można również zainstalować na hostach aplikacji. Aplikacja połączy się bezpośrednio z ProxySQL na lokalnym hoście, może nawet użyć gniazda unix, aby zminimalizować obciążenie połączenia TCP. Główną zaletą takiej konfiguracji jest to, że masz dużą liczbę instancji ProxySQL, a obciążenie jest na nie równomiernie rozłożone. Jeśli któryś ulegnie awarii, tylko ten host aplikacji zostanie naruszony. Pozostałe węzły będą nadal działać. Najpoważniejszym problemem, z którym trzeba się zmierzyć, jest zarządzanie konfiguracją. Przy dużej liczbie węzłów ProxySQL kluczowe znaczenie ma wymyślenie zautomatyzowanej metody utrzymywania synchronizacji ich konfiguracji. Możesz użyć ClusterControl lub narzędzia do zarządzania konfiguracją, takiego jak Puppet.
Dostrajanie Galera w środowisku WAN
Domyślne ustawienia Galera są przeznaczone dla sieci lokalnej i jeśli chcesz używać jej w środowisku WAN, wymagane jest pewne dostrojenie. Omówmy niektóre z podstawowych poprawek, które możesz wprowadzić. Należy pamiętać, że precyzyjne dostrojenie wymaga danych produkcyjnych i ruchu — nie można po prostu wprowadzić pewnych zmian i założyć, że są dobre, należy przeprowadzić odpowiednie testy porównawcze.
Konfiguracja systemu operacyjnego
Zacznijmy od konfiguracji systemu operacyjnego. Nie wszystkie proponowane tu modyfikacje są związane z siecią WAN, ale zawsze dobrze jest przypomnieć sobie, jaki jest dobry punkt wyjścia dla każdej instalacji MySQL.
vm.swappiness = 1Swappiness kontroluje, jak agresywnie system operacyjny będzie używał wymiany. Nie powinno być ustawione na zero, ponieważ w nowszych jądrach uniemożliwia systemowi korzystanie z wymiany i może powodować poważne problemy z wydajnością.
/sys/block/*/queue/scheduler = deadline/noopHarmonogram urządzenia blokowego, którego używa MySQL, powinien być ustawiony na termin lub noop. Dokładny wybór zależy od testów porównawczych, ale oba ustawienia powinny zapewniać podobną wydajność, lepszą niż domyślny harmonogram, CFQ.
W przypadku MySQL powinieneś rozważyć użycie EXT4 lub XFS, w zależności od jądra (wydajność tych systemów plików zmienia się w zależności od wersji jądra). Wykonaj kilka testów porównawczych, aby znaleźć lepszą opcję dla siebie.
Oprócz tego możesz zajrzeć do ustawień sieciowych sysctl. Nie będziemy ich szczegółowo omawiać (dokumentację można znaleźć tutaj), ale ogólną ideą jest zwiększenie buforów, zaległości i limitów czasu, aby ułatwić uwzględnienie przestojów i niestabilnego łącza WAN.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Oprócz dostrajania systemu operacyjnego należy rozważyć dostosowanie ustawień związanych z siecią Galera.
evs.suspect_timeout
evs.inactive_timeoutMożesz rozważyć zmianę domyślnych wartości tych zmiennych. Oba limity czasu określają, w jaki sposób klaster eksmituje uszkodzone węzły. Podejrzany limit czasu ma miejsce, gdy wszystkie węzły nie mogą dotrzeć do nieaktywnego członka. Limit czasu nieaktywności określa sztywny limit czasu, przez jaki węzeł może pozostać w klastrze, jeśli nie odpowiada. Zwykle przekonasz się, że wartości domyślne działają dobrze. Jednak w niektórych przypadkach, zwłaszcza jeśli używasz klastra Galera przez sieć WAN (na przykład między regionami AWS), zwiększenie tych zmiennych może skutkować bardziej stabilną wydajnością. Sugerujemy ustawienie obu z nich na PT1M, aby zmniejszyć prawdopodobieństwo, że niestabilność łącza WAN wyrzuci węzeł z klastra.
evs.send_window
evs.user_send_windowTe zmienne, evs.send_window i evs.user_send_window , określ, ile pakietów może być jednocześnie wysłanych przez replikację (evs.send_window ) i ile z nich może zawierać dane (evs.user_send_window ). W przypadku połączeń o dużym opóźnieniu warto znacznie zwiększyć te wartości (na przykład 512 lub 1024).
evs.inactive_check_periodPowyższa zmienna może również ulec zmianie. evs.inactive_check_period domyślnie jest ustawiona na jedną sekundę, co może być zbyt częste w przypadku konfiguracji sieci WAN. Sugerujemy ustawienie go na PT30S.
gcs.fc_factor
gcs.fc_limitTutaj chcemy zminimalizować szanse na uruchomienie kontroli przepływu, dlatego sugerujemy ustawienie gcs.fc_factor do 1 i zwiększ gcs.fc_limit na przykład do 260.
gcs.max_packet_sizePonieważ pracujemy z łączem WAN, gdzie opóźnienia są znacznie większe, chcemy zwiększyć rozmiar pakietów. Dobrym punktem wyjścia byłby 2097152.
Jak wspomnieliśmy wcześniej, podanie prostego przepisu na ustawienie tych parametrów jest praktycznie niemożliwe, ponieważ zależy to od zbyt wielu czynników - przed rozpoczęciem pracy będziesz musiał wykonać własne testy porównawcze, używając danych jak najbardziej zbliżonych do Twoich danych produkcyjnych. można powiedzieć, że twój system jest dostrojony. To powiedziawszy, te ustawienia powinny dać ci punkt wyjścia do bardziej precyzyjnego strojenia.
Na razie to wszystko. Galera działa całkiem dobrze w środowiskach WAN, więc spróbuj i daj nam znać, jak sobie radzisz.