Biorąc pod uwagę obecny główny przypadek użycia bazy danych do pobierania danych, bardzo ważne staje się, aby jej wydajność była bardzo wysoka i można to osiągnąć tylko wtedy, gdy dane są pobierane z pamięci w najbardziej efektywny sposób. Dokonano wielu udanych wynalazków i wdrożeń, aby osiągnąć to samo. Jednym z dobrze znanych podejść stosowanych przez większość baz danych jest posiadanie indeksu w tabeli.
Co to jest indeks bazy danych?
Indeks bazy danych, jak sama nazwa wskazuje, utrzymuje indeks do rzeczywistych danych, a tym samym poprawia wydajność pobierania danych z rzeczywistej tabeli. W terminologii bardziej bazodanowej indeks umożliwia pobieranie strony zawierającej zindeksowane dane przy bardzo minimalnym przechodzeniu, ponieważ dane są sortowane w określonej kolejności. Korzyść z indeksu wiąże się z kosztem dodatkowej przestrzeni dyskowej w celu zapisania dodatkowych danych. Indeksy są specyficzne dla tabeli bazowej i składają się z co najmniej jednego klucza (tj. co najmniej jednej kolumny określonej tabeli). Istnieją przede wszystkim dwa rodzaje architektury indeksów
- Indeks klastrowy — dane indeksu są przechowywane wraz z inną częścią danych, a dane są sortowane na podstawie klucza indeksu. Co najwyżej może być tylko jeden indeks w tej kategorii dla określonej tabeli.
- Indeks nieklastrowany — dane indeksu są przechowywane osobno i mają wskaźnik do miejsca, w którym przechowywana jest inna część danych. Jest to również znane jako indeks wtórny. W określonej tabeli może znajdować się tyle indeksów tej kategorii, ile chcesz.
Istnieją różne struktury danych używane do implementacji indeksów, niektóre z powszechnie stosowanych w większości baz danych to B-Tree i Hash.
Co to jest indeks PostgreSQL?
PostgreSQL obsługuje tylko indeks nieklastrowy. Oznacza to indeksowanie danych i pełne dane (tutaj dalej określane jako dane sterty ) są przechowywane w oddzielnym magazynie. Indeksy nieklastrowane są jak „spis treści” w każdym dokumencie, w którym najpierw sprawdzamy numer strony, a następnie sprawdzamy te numery stron, aby przeczytać całą treść. Aby uzyskać pełne dane na podstawie indeksu, utrzymuje wskaźnik do odpowiednich danych sterty. To tak samo, jak po poznaniu numeru strony, musi przejść do tej strony i uzyskać rzeczywistą zawartość strony.
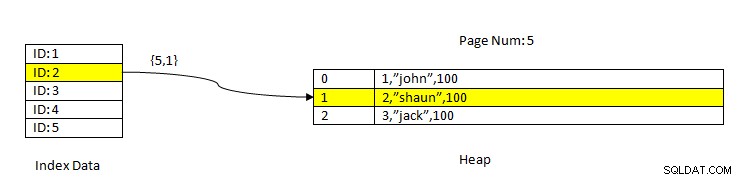 PostgreSQL:dane odczytywane za pomocą indeksu
PostgreSQL:dane odczytywane za pomocą indeksu Rozważmy na przykład tabelę z trzema kolumnami i indeksem w kolumnie ID . W celu ODCZYTU danych na podstawie klucza ID=2, najpierw przeszukiwane są dane indeksowane o wartości ID 2. Zawiera wskaźnik (zwany wskaźnikiem elementu) pod względem numeru strony (tj. numeru bloku) i przesunięcia danych na tej stronie. W obecnym przykładzie indeks wskazuje na stronę numer 5 i drugą pozycję na stronie, która z kolei zachowuje przesunięcie do całych danych (2, „Shaun”, 100). Zwróć uwagę, że całe dane zawierają również dane zindeksowane, co oznacza, że te same dane są powtarzane w dwóch magazynach.
Jak INDEX pomaga poprawić wydajność? Cóż, aby wybrać dowolny rekord INDEX, nie skanuje on wszystkich stron sekwencyjnie, a jedynie częściowo skanuje niektóre strony przy użyciu podstawowej struktury danych Index. Ale jest pewna niespodzianka, ponieważ każdy rekord znaleziony na podstawie danych indeksu musi szukać całych danych w danych sterty, co powoduje wiele losowych operacji we/wy i uważa się, że działa wolniej niż sekwencyjne operacje we/wy. Tak więc tylko wtedy, gdy wybierany jest niewielki procent rekordów (co zadecydowano na podstawie kosztu optymalizatora PostgreSQL), wtedy tylko PostgreSQL wybiera skanowanie indeksu, w przeciwnym razie, nawet jeśli w tabeli znajduje się indeks, nadal używa skanowania sekwencji.
Podsumowując, chociaż tworzenie indeksu przyspiesza wydajność, należy go starannie dobierać, ponieważ wiąże się z obciążeniem pamięcią i obniżoną wydajnością INSERT.
Teraz możemy się zastanawiać, czy w przypadku, gdy potrzebujemy tylko części indeksowej danych, możemy pobrać tylko ze strony przechowywania indeksów? Cóż, odpowiedź na to pytanie jest bezpośrednio związana z tym, jak MVCC działa w magazynie indeksów, jak wyjaśniono dalej.
Korzystanie z MVCC do indeksowania
Podobnie jak strony sterty, strona indeksu zachowuje wiele wersji krotki indeksu, ale nie zachowuje informacji o widoczności. Jak wyjaśniono w moim poprzednim MVCC blog, aby wybrać odpowiednią widoczną wersję krotek, wymaga porównania transakcji. Transakcja, która wstawiła/zaktualizowała/usunęła krotkę jest utrzymywana wraz z krotką sterty, ale to samo nie jest utrzymywane z krotką indeksową. Ma to na celu wyłącznie zaoszczędzenie miejsca i jest to kompromis między przestrzenią a wydajnością.
Wracając do pierwotnego pytania, ponieważ nie ma tam informacji o widoczności w krotce Index, należy sprawdzić odpowiednią krotkę sterty, aby sprawdzić, czy wybrane dane są widoczne. Więc nawet jeśli inne części danych z krotki sterty nie są wymagane, nadal trzeba uzyskać dostęp do stron sterty, aby sprawdzić widoczność. Ale znowu, pojawia się zwrot w przypadku, gdy wszystkie krotki na danej stronie (strona wskazywana przez indeks, tj. ItemPointer) są widoczne, wtedy nie trzeba odnosić się do każdego elementu strony Heap w celu „sprawdzenia widoczności”, a zatem dane mogą zostać zwrócone tylko ze strony Indeks. Ten szczególny przypadek nosi nazwę „Skanowanie tylko z indeksem”. Aby to wspierać, PostgreSQL utrzymuje mapę widoczności dla każdej strony, aby sprawdzić widoczność na poziomie strony.
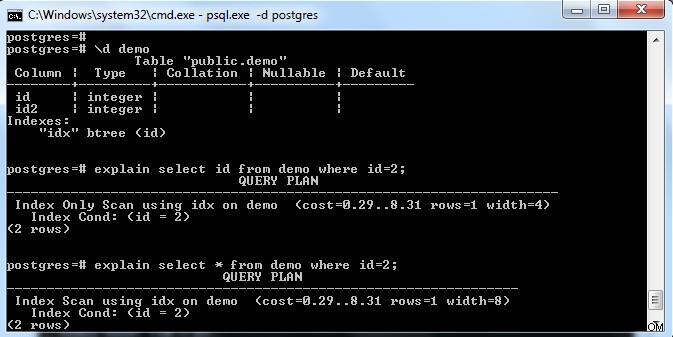
Jak pokazano na powyższym obrazku, w tabeli „demo” znajduje się indeks z kluczem w kolumnie „id”. Jeśli spróbujemy wybrać tylko pole indeksu (tj. id), to wybierze „Skanowanie tylko indeksu” (biorąc pod uwagę, że strona odsyłająca jest w pełni widoczna).
Indeks klastrowy
Nie ma obsługi bezpośredniego indeksu klastrowego w PostgreSQL, ale istnieje pośredni sposób, aby częściowo osiągnąć to samo. Osiąga się to za pomocą poniższych poleceń SQL:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Pierwsze polecenie nakazuje bazie danych klastrowanie tabeli (tj. sortowanie tabeli) przy użyciu podanego indeksu. Ten indeks powinien już zostać utworzony. To grupowanie jest tylko jednorazową operacją, a jego wpływ nie pozostaje po kolejnej operacji na tej tabeli, tj. jeśli zostanie wstawionych/zaktualizowanych więcej rekordów, tabela może nie pozostać uporządkowana. Jeśli użytkownik potrzebuje, aby nadal utrzymywać tabele w klastrach (w kolejności), może użyć pierwszego polecenia bez podawania nazwy indeksu.
Drugie polecenie jest przydatne tylko do ponownego klastrowania tabeli (tj. tabeli, która została już zgrupowana przy użyciu jakiegoś indeksu). To polecenie ponownie grupuje wszystkie tabele w bieżącej bazie danych widoczne dla aktualnie podłączonego użytkownika.
Na przykład na poniższym rysunku pierwszy SELECT zwraca rekordy w nieposortowanej kolejności, ponieważ nie ma indeksu klastrowanego. Nawet jeśli istnieje już indeks nieklastrowany, ale rekordy są wybierane z obszaru sterty, w którym rekordy nie są sortowane.
Drugi SELECT zwraca rekordy posortowane według kolumny „id”, ponieważ zostały pogrupowane przy użyciu indeksu zawierającego kolumnę „id”.
Trzecia SELECT zwraca rekordy częściowe w posortowanej kolejności, ale nowo wstawione rekordy nie są sortowane. Czwarty SELECT ponownie zwraca wszystkie rekordy w posortowanej kolejności, ponieważ tabela została ponownie pogrupowana
 Polecenie klastra PostgreSQL
Polecenie klastra PostgreSQL Typ indeksu
PostgreSQL udostępnia kilka typów indeksów, jak poniżej:
- B-drzewo
- Hasz
- GiST
- GIN
- BRIN
Każdy typ indeksu implementuje różne rodzaje podstawowej struktury danych, która najlepiej nadaje się do różnych typów zapytań. Domyślnie tworzony jest indeks B-Tree, który jest powszechnie używanymi indeksami. Szczegóły każdego typu indeksu zostaną omówione w przyszłym blogu.
Różne:Indeks częściowy i wyrażeń
Omówiliśmy tylko indeksy w jednej lub kilku kolumnach tabeli, ale istnieją inne dwa sposoby tworzenia indeksów w PostgreSQL
- Indeks częściowy: Indeks częściowy to indeks zbudowany przy użyciu podzbioru kolumny kluczowej dla określonej tabeli. Podzbiór jest zdefiniowany przez wyrażenie warunkowe podane podczas tworzenia indeksu. Tak więc dzięki indeksowi częściowemu zostaje zapisana przestrzeń do przechowywania danych indeksowych. Użytkownik powinien więc dobrać warunek w taki sposób, aby nie były to zbyt częste wartości, gdyż dla częstszych (wspólnych) wartości i tak nie zostanie wybrany skan indeksu. Reszta funkcjonalności pozostaje taka sama jak w przypadku normalnego indeksu. Przykład:indeks częściowy
- Indeks wyrażeń: Indeksy wyrażeń dają inny rodzaj elastyczności w PostgreSQL. Wszystkie omówione do tej pory indeksy, w tym indeksy częściowe, znajdują się na określonym zestawie kolumn. Ale co, jeśli zapytanie obejmuje dostęp do tabeli opartej na wyrażeniu (wyrażeniu obejmującym jedną lub więcej kolumn), bez indeksu wyrażenia nie wybierze skanowania indeksu. Aby więc szybko uzyskać dostęp do tego rodzaju zapytań, PostgreSQL umożliwia utworzenie indeksu na wyrażeniu. Reszta funkcjonalności pozostaje taka sama jak w przypadku normalnego indeksu.
 Przykład:indeks wyrażeń
Przykład:indeks wyrażeń
Przechowywanie indeksów w InnoDB
Użycie i funkcjonalność indeksu jest w większości taka sama jak w PostgreSQL, z zasadniczą różnicą pod względem indeksu klastrowego.
InnoDB obsługuje dwie kategorie indeksów:
- Indeks klastrowy
- Indeks dodatkowy
Indeks klastrowy
Clustered Index to specjalny rodzaj indeksu w InnoDB. W tym przypadku zindeksowane dane nie są przechowywane oddzielnie, a stanowią część danych w całym wierszu. Innymi słowy, indeks klastrowy po prostu wymusza fizyczne sortowanie danych tabeli przy użyciu kolumny klucza indeksu. Można go uznać za „Słownik”, w którym dane są sortowane według alfabetu.
Ponieważ indeks klastrowany sortuje wiersze przy użyciu klucza indeksu, może istnieć tylko jeden indeks klastrowany. Ponadto musi istnieć jeden indeks klastrowy, ponieważ InnoDB używa go do optymalnego manipulowania danymi podczas różnych operacji na danych.
Indeksy klastrowe są tworzone automatycznie (w ramach tworzenia tabeli) przy użyciu jednej z kolumn tabeli zgodnie z poniższym priorytetem:
- Używanie klucza podstawowego, jeśli klucz podstawowy jest wymieniony jako część tworzenia tabeli.
- Wybiera dowolną unikalną kolumnę, w której wszystkie kluczowe kolumny NIE są NULL.
- W przeciwnym razie wewnętrznie generuje ukryty indeks klastrowy w kolumnie systemowej, która zawiera identyfikator każdego wiersza.
W przeciwieństwie do indeksu nieklastrowego PostgreSQL, InnoDB szybciej uzyskuje dostęp do wiersza za pomocą indeksu klastrowego, ponieważ wyszukiwanie indeksu prowadzi bezpośrednio do strony ze wszystkimi danymi wiersza, a tym samym unika losowych operacji we/wy.
Również uzyskanie danych z tabeli w posortowanej kolejności przy użyciu indeksu klastrowego jest bardzo szybkie, ponieważ wszystkie dane są już posortowane, a także dostępne są całe dane.
Indeks dodatkowy
Indeks utworzony jawnie w InnoDB jest uważany za indeks pomocniczy, który jest podobny do indeksu nieklastrowego PostgreSQL. Każdy rekord w magazynie indeksów pomocniczych zawiera kolumny klucza podstawowego wierszy (które zostały użyte do utworzenia indeksu klastrowego), a także kolumny określone w celu utworzenia indeksu pomocniczego.
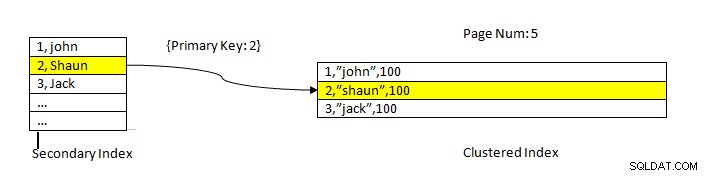 InnoDB:dane odczytywane przy użyciu indeksu
InnoDB:dane odczytywane przy użyciu indeksu Pobieranie danych za pomocą indeksu pomocniczego jest podobne jak w przypadku PostgreSQL, z tym wyjątkiem, że wyszukiwanie indeksu pomocniczego InnoDB podaje klucz główny jako wskaźnik do pobrania pozostałych danych z indeksu klastrowego.
Na przykład, jak pokazano na powyższym obrazku, indeks klastrowy znajduje się w kolumnie ID, więc dane tabeli są sortowane według tego samego. Drugi indeks znajduje się w kolumnie „nazwa ”, tak jak widzimy, indeks wtórny ma zarówno wartość ID, jak i nazwę. Po wyszukaniu przy użyciu indeksu dodatkowego znajduje on odpowiedni slot z odpowiednią wartością klucza. Następnie odpowiedni klucz główny jest używany do odwoływania się do pozostałej części danych z indeksu klastrowego.
MVCC dla indeksu
Indeks klastrowy MVCC używa tradycyjnego modelu InnoDB Undo (właściwie tak samo jak MVCC dla całych danych, ponieważ indeks klastrowy to tylko całe dane).
Ale wtórny indeks MVCC używa nieco innego podejścia do utrzymania MVCC. Podczas aktualizacji indeksu wtórnego stary wpis indeksu jest oznaczony jako usunięty, a nowe rekordy są wstawiane do tego samego magazynu, tj. UPDATE nie jest na miejscu. Wreszcie, stare wpisy indeksu są usuwane. Do tej pory mogłeś zauważyć, że indeks wtórny MVCC InnoDB jest prawie taki sam jak w modelu PostgreSQL MVCC.
Typ indeksu
InnoDB obsługuje tylko indeksy typu B-Tree i dlatego nie jest wymagane określanie podczas tworzenia indeksu.
Różne:Adaptacyjne indeksy haszujące
Jak wspomniano w poprzedniej sekcji, że tylko indeks typu B-Tree jest obsługiwany przez InnoDB, ale jest pewien skręt. InnoDB ma funkcję automatycznego wykrywania, czy zapytanie może skorzystać na zbudowaniu indeksu mieszającego, a także czy całe dane z tabeli mogą zmieścić się w pamięci, a następnie robi to automatycznie.
Indeks mieszający jest budowany przy użyciu istniejącego indeksu B-Tree w zależności od zapytania. Jeśli istnieje wiele drugorzędnych indeksów B-Tree, wybierze ten, który kwalifikuje się zgodnie z zapytaniem. Zbudowany indeks mieszający nie jest kompletny, po prostu buduje indeks częściowy zgodnie ze wzorcem wykorzystania danych.
Jest to jedna z naprawdę potężnych funkcji, które dynamicznie poprawiają wydajność zapytań.
Wniosek
Użycie dowolnego indeksu w dowolnej bazie danych jest naprawdę pomocne w poprawie wydajności ODCZYTU, ale jednocześnie obniża wydajność INSERT/UPDATE, ponieważ wymaga zapisania dodatkowych danych. Tak więc indeks powinien być wybierany bardzo mądrze i powinien być tworzony tylko wtedy, gdy klucze indeksu są używane jako predykat do pobierania danych.
InnoDB zapewnia bardzo dobrą funkcję pod względem indeksu klastrowego, co może być bardzo przydatne w zależności od przypadków użycia. Ponadto jego adaptacyjne indeksowanie skrótów jest bardzo wydajne.
Podczas gdy PostgreSQL zapewnia różne rodzaje indeksów, które naprawdę dają opcje zasięgu funkcji i jeden lub wszystkie mogą być używane w zależności od biznesowego przypadku użycia. W zależności od przypadku użycia przydatne są również indeksy częściowe i wyrażeń.



