ProxySQL to dedykowany system równoważenia obciążenia dla MySQL, który zawiera wiele funkcji, w tym między innymi przekierowywanie zapytań, buforowanie zapytań lub kształtowanie ruchu. Może być używany do łatwego konfigurowania podziału odczytu i zapisu oraz przekierowywania zapytań do oddzielnych węzłów zaplecza. W rezultacie zapewnia wiele przekonujących powodów do użycia. Z drugiej strony, HAProxy jest świetnym load balancerem, ale nie jest dedykowany dla baz danych i chociaż może być używany, nie można go naprawdę porównać pod względem funkcji z ProxySQL. Może to być powodem, dla którego środowiska, które nadal opierają się na HAProxy, podejmują próbę migracji do ProxySQL.
W tym krótkim poście na blogu podzielimy się kilkoma sugestiami dotyczącymi procesu migracji.
Planowanie uaktualnienia
Jest to dość oczywiste i powinno być bez wątpienia, ale nadal chcielibyśmy mieć to na piśmie. Zaplanuj aktualizację. Upewnij się, że znasz ten proces, że wszystko dokładnie przetestowałeś. Skonfiguruj środowisko testowe, w którym możesz zweryfikować różne podejścia do uaktualnienia i zdecydować, które będzie dla Ciebie najlepsze.
Przetestuj podział odczytu/zapisu w ProxySQL, jeśli rozważysz jego użycie
W zależności od wymagań, możesz rozważyć użycie podziału odczytu/zapisu w ProxySQL. Jest to prawdopodobnie jeden z najważniejszych powodów aktualizacji. Zamiast implementować go po stronie aplikacji (lub nie implementować go w ogóle, jeśli nie możesz tego zrobić w aplikacji), możesz polegać na ProxySQL, aby wykonać za Ciebie podział odczytu/zapisu. Konfiguracja jest bardzo łatwa, zwłaszcza jeśli wdrażasz ProxySQL za pomocą ClusterControl - dzieje się to prawie automatycznie.
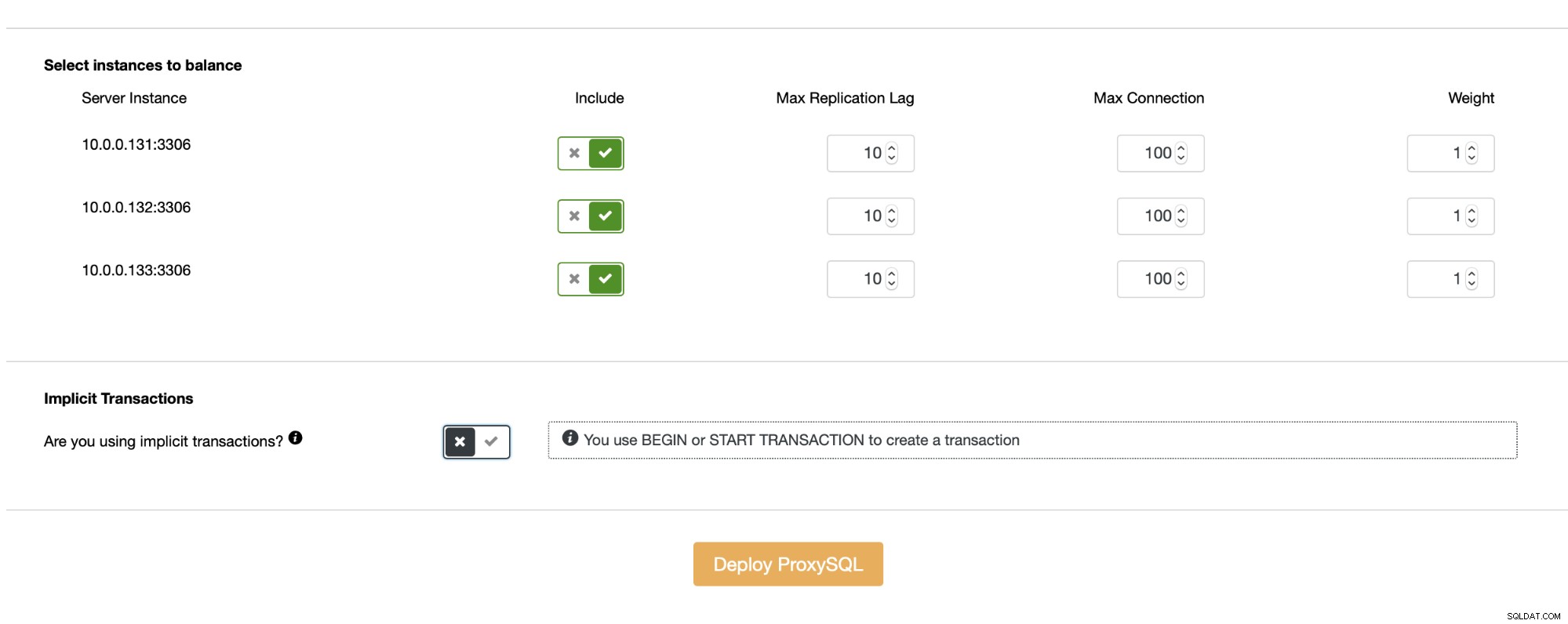
Dopóki nie używasz transakcji niejawnych, ClusterControl skonfiguruje podział odczytu/zapisu za Ciebie przy użyciu zestawu reguł zapytań:
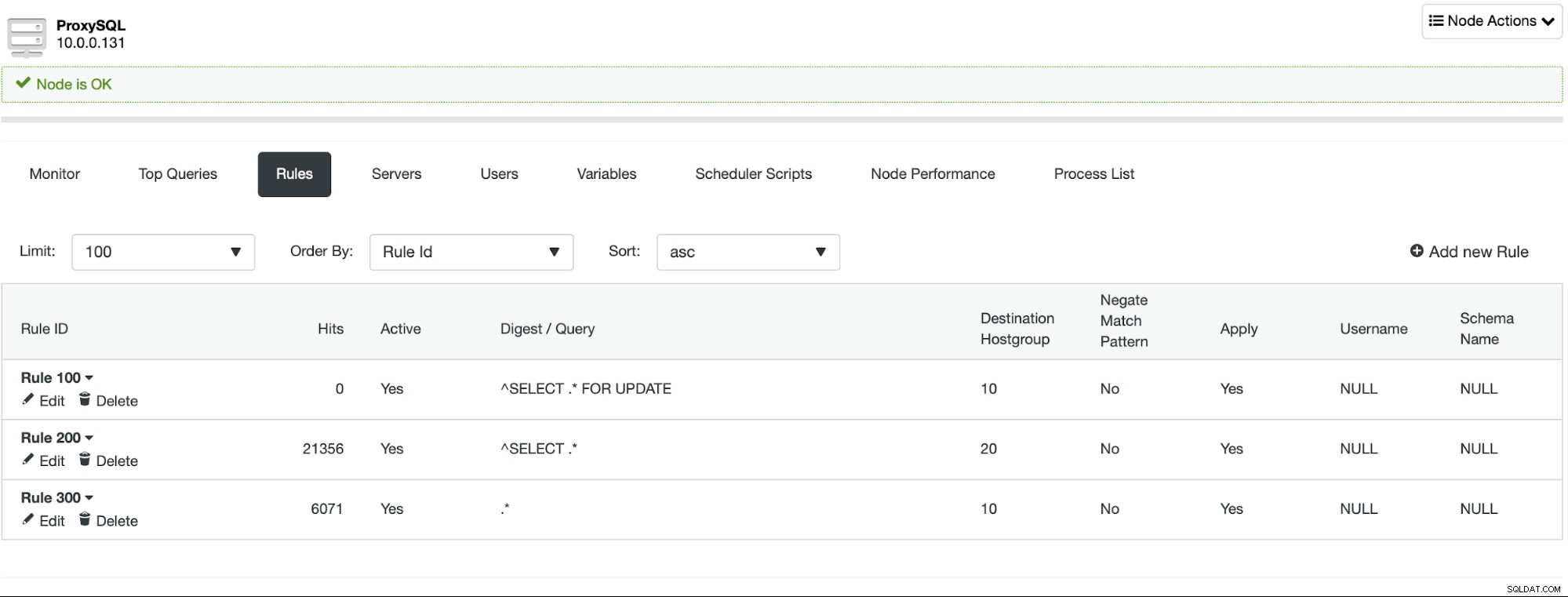
Nawet jeśli zaimplementowanie podziału odczytu/zapisu jest bardzo proste, powinieneś zachowaj ostrożność, kiedy planujesz to zrobić. Aplikacje mogą polegać na niektórych funkcjach, które tak naprawdę nie działają od razu w ProxySQL. W większości przypadków dodatkowa konfiguracja pozwoli Ci skorzystać z tej funkcji, ale podczas fazy testowej bardzo ważne jest, aby określić, czy Twoja aplikacja po prostu będzie działać, czy też musisz dodać niestandardową konfigurację. Szczególnie trudne części to problemy z odczytem po zapisie - w takim przypadku może być konieczne ponowne skonfigurowanie ProxySQL, aby wyłączyć multipleksowanie połączenia dla niektórych zapytań.
Zapomnij o pliku konfiguracyjnym w ProxySQL
Jest to jedna z rzeczy, które zaskakują nowych użytkowników ProxySQL. Tak naprawdę nie używa plików konfiguracyjnych. Jest jeden, tak, ale w zasadzie działa jako sposób na załadowanie ProxySQL podczas pierwszego uruchomienia. ProxySQL korzysta z bazy danych SQLite, która zawiera jej konfigurację, a prawidłowym sposobem wprowadzania zmian w konfiguracji jest klient MySQL podłączony do portu administracyjnego ProxySQL. Stamtąd możesz dokonać zmian konfiguracyjnych w czasie wykonywania, prawie bez potrzeby ponownego uruchamiania ProxySQL.
Oczywiście interfejs użytkownika ClusterControl umożliwia również rekonfigurację ProxySQL:
Wzorce wdrażania ProxySQL
Istnieją dwa główne sposoby wdrożenia ProxySQL. Możesz użyć dedykowanych serwerów do wdrożenia ProxySQL na:
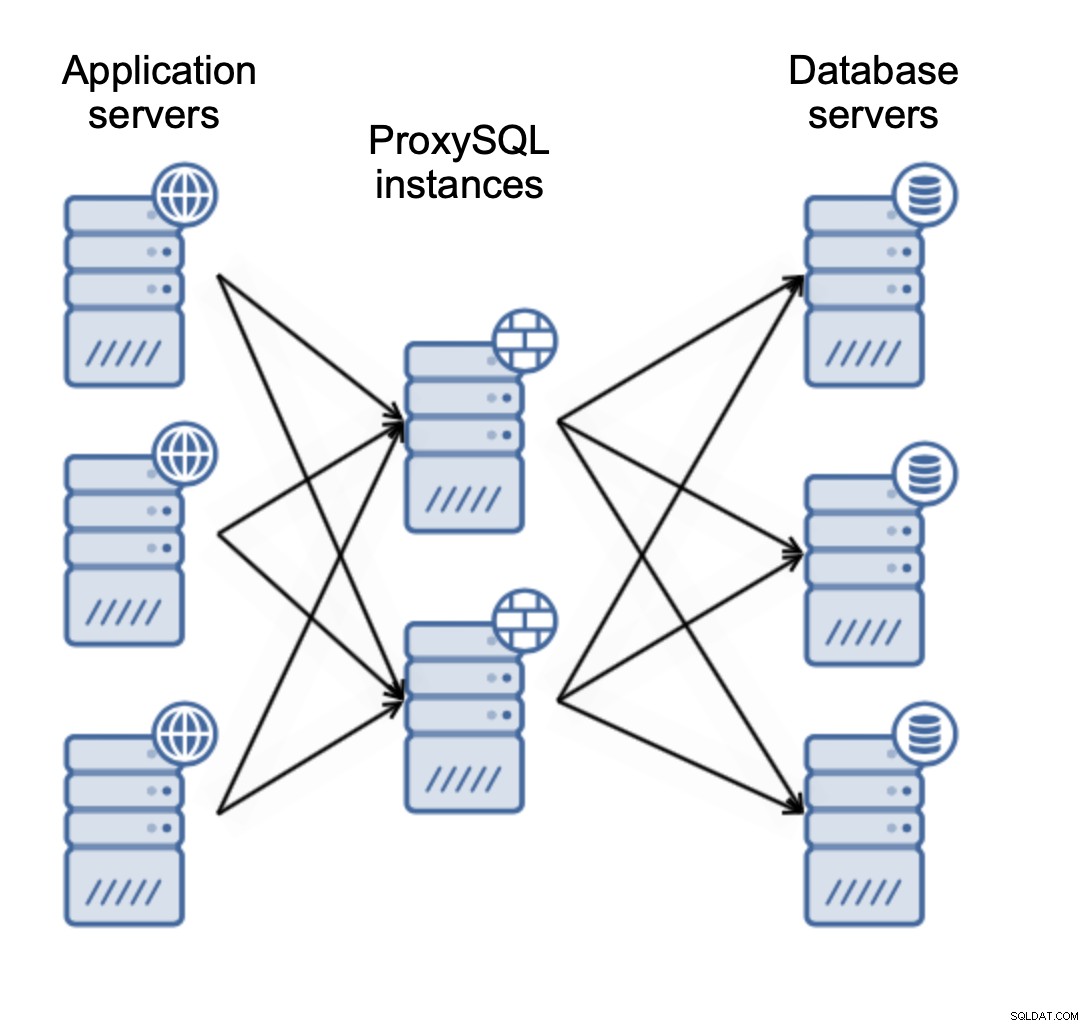
Lub możesz kolokować ProxySQL z serwerami aplikacji:
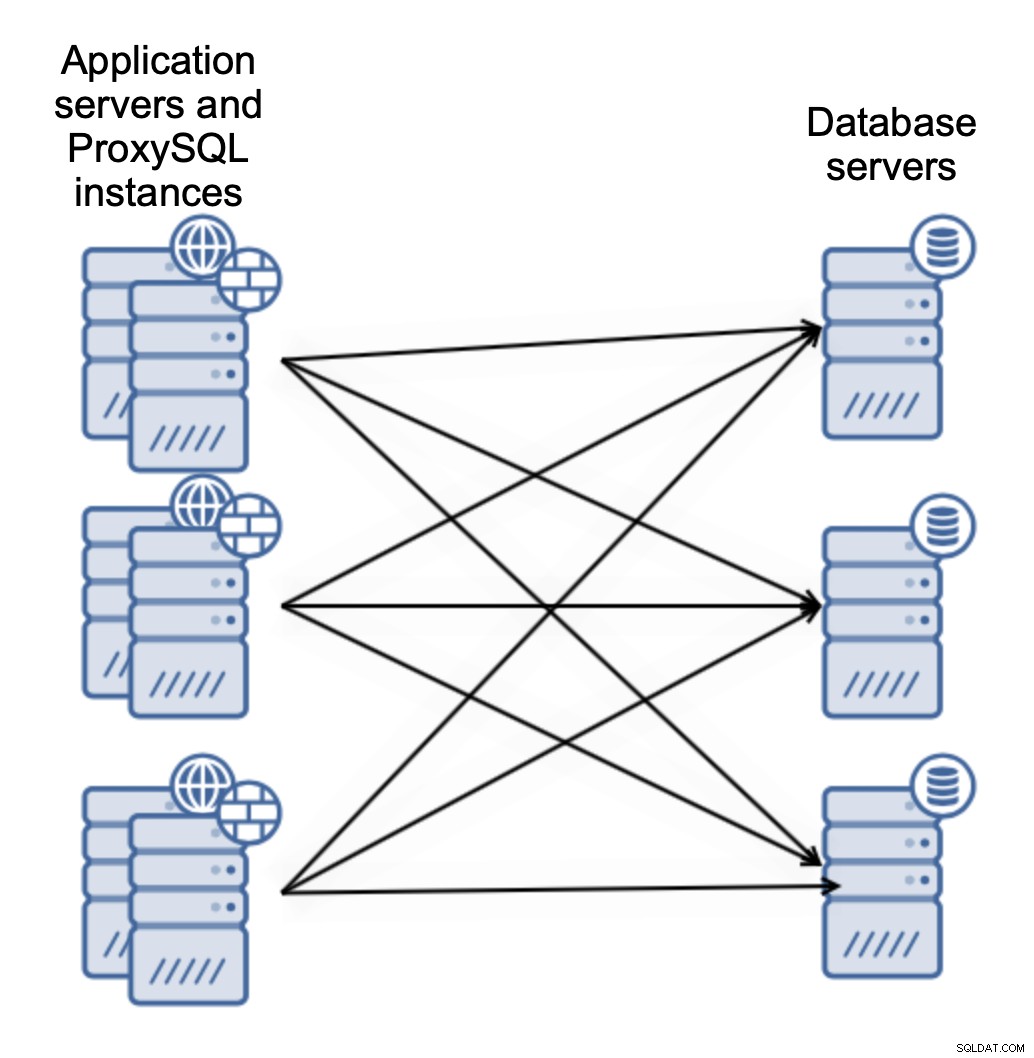
Dzięki temu aplikacja może łączyć się z lokalną instancją ProxySQL za pomocą gniazda Unix, które jest lepszy pod względem wydajności niż korzystanie ze zdalnego połączenia TCP. Upraszcza również konfigurację — nie ma potrzeby wdrażania Keepalived ani innego dostawcy wirtualnego adresu IP, aby równoważyć obciążenie między instancjami ProxySQL. Aplikacja łączy się tylko z lokalnym serwerem ProxySQL i to prawie wszystko.
Użyj klastrów ProxySQL do większych wdrożeń
Upewnienie się, że instancje ProxySQL zawierają przez cały czas tę samą konfigurację, może być trudne, zwłaszcza jeśli ich liczba jest duża. Istnieje wiele sposobów radzenia sobie z takimi wyzwaniami - Ansible/Chef/Puppet, skrypty powłoki i tak dalej. Sugerujemy skorzystanie z wbudowanego rozwiązania - ProxySQL Cluster. Wystarczy kilka zmian w konfiguracji, aby skonfigurować węzły ProxySQL, aby utworzyć klaster, w którym zmiana konfiguracji na jednym z węzłów będzie propagowana na wszystkich członków klastra.
Tinker z SO_REUSEPORT do płynnego przełączania systemu równoważenia obciążenia
Jedną z trudniejszych części może być zapewnienie przełączenia ruchu z HAProxy na ProxySQL w sposób, który zminimalizuje wpływ na aplikację. Zazwyczaj należałoby zmienić co najmniej jedno ustawienie — nazwę hosta lub port, z którym aplikacja powinna się łączyć. W zależności od środowiska może to nie być idealne, zwłaszcza jeśli konfiguracja połączenia z bazą danych jest wbudowana w aplikację. Wymagałoby to w zasadzie zmiany bazy kodu i wrzucenia nowego kodu do produkcji. Nie jest to największa z ofert, ale możesz zrobić coś lepszego.
Ciekawe jest to, że zarówno ProxySQL, jak i najnowsze wersje HAProxy (poczynając od 1.8) mogą korzystać z SO_REUSEPORT. Ta opcja gniazda jest dostępna w Linuksie począwszy od jądra 3.9 i umożliwia wielu procesom współużytkowanie tego samego portu. ProxySQL może go używać do płynnych aktualizacji między wersjami ProxySQL, HAProxy używa go do przeładowania konfiguracji bez żadnego wpływu na aplikację. Co ciekawe, możliwe jest skonfigurowanie ProxySQL do współdzielenia portu z HAProxy w celu płynnej migracji między tymi dwoma systemami równoważenia obciążenia.
Jest kilka rzeczy, które należy wziąć pod uwagę, próbując to zrobić - po pierwsze, ProxySQL domyślnie nie używa tej opcji, musisz dodać flagę -r do ProxySQL podczas uruchamiania. Możesz to zrobić, edytując plik jednostki systemowej ProxySQL:
example@sqldat.com:~# systemctl edit proxysql --fulli zmiana dyrektywy ExecStart na:
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rKolejnym ograniczeniem, o którym należy pamiętać w Linuksie, jest to, że tylko procesy uruchomione przez ten sam identyfikator użytkownika mogą współdzielić port. Oznacza to, że będziesz musiał ponownie skonfigurować ProxySQL, aby był uruchamiany jako użytkownik „haproxy”.
Jak zwykle, możesz chcieć przeprowadzić testy przed próbą wykonania tej operacji w środowisku produkcyjnym. Osiągnięcie tego jest zdecydowanie możliwe, ale należy zachować ostrożność i dwukrotnie sprawdzić, czy nie wpłynie to na produkcję z powodu jakiejś niestandardowej konfiguracji związanej z Twoim środowiskiem.
Mamy nadzieję, że ten krótki blog przybliży Wam proces migracji z HAProxy do ProxySQL. W przypadku zaplecza bazy danych zmiana ta będzie bardzo korzystna, nawet jeśli część przygotowawcza może być czasochłonna. Jeśli przejdziesz odpowiednie testy, ostateczna migracja powinna być dość prosta i bezpieczna.