W tym poście na blogu przyjrzymy się niektórym kluczowym metrykom i statusowi podczas monitorowania serwera Percona Server pod kątem MySQL, aby pomóc nam dostroić konfigurację serwera MySQL na dłuższą metę. Na wszelki wypadek, Percona Server ma pewne metryki monitorowania, które są dostępne tylko w tej kompilacji. W porównaniu z wersją 8.0.20, następujące 51 statusów jest dostępnych tylko na Percona Server for MySQL, które nie są dostępne w starszym serwerze Oracle MySQL Community Server:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_split
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Sprawdź stronę Extended InnoDB Status, aby uzyskać więcej informacji na temat każdej z powyższych metryk monitorowania. Zauważ, że niektóre dodatkowe statusy, takie jak pula wątków, są dostępne tylko w Oracle MySQL Enterprise. Zapoznaj się z dokumentacją Percona Server for MySQL 8.0, aby zobaczyć wszystkie ulepszenia opracowane specjalnie dla tej wersji w stosunku do Oracle MySQL Community Server 8.0.
Aby pobrać globalny status MySQL, po prostu użyj jednej z następujących instrukcji:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Stan i przegląd bazy danych
Zaczniemy od statusu uptime, czyli liczby sekund działania serwera.
Wszystkie statusy com_* to zmienne licznika instrukcji, które wskazują, ile razy każda instrukcja została wykonana. Dla każdego typu instrukcji istnieje jedna zmienna statusu. Na przykład com_delete i com_update liczą odpowiednio instrukcje DELETE i UPDATE. com_delete_multi i com_update_multi są podobne, ale mają zastosowanie do instrukcji DELETE i UPDATE, które używają składni wielotabelowej.
Aby wyświetlić wszystkie procesy uruchomione przez MySQL, po prostu uruchom jedną z następujących instrukcji:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Połączenia i wątki
Obecne połączenia
Stosunek aktualnie otwartych połączeń (wątek połączenia). Jeśli współczynnik jest wysoki, oznacza to, że istnieje wiele jednoczesnych połączeń z serwerem MySQL i może to prowadzić do błędu „Zbyt wiele połączeń”. Aby uzyskać procent połączenia:
Current connections(%) = (threads_connected / max_connections) x 100Dobra wartość powinna wynosić 80% i mniej. Spróbuj zwiększyć zmienną max_connections lub sprawdź połączenia za pomocą POKAŻ PEŁNĄ LISTĘ PROCESÓW. Gdy wystąpi błąd „Zbyt wiele połączeń”, serwer bazy danych MySQL stanie się niedostępny dla użytkownika innego niż superużytkownik, dopóki niektóre połączenia nie zostaną zwolnione. Zwróć uwagę, że zwiększenie zmiennej max_connections może również potencjalnie zwiększyć zużycie pamięci MySQL.
Maksymalna liczba połączeń, jakie kiedykolwiek widziano
Stosunek maksymalnej liczby połączeń do serwera MySQL, jaki kiedykolwiek zaobserwowano. Prosta kalkulacja to:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Dobra wartość powinna wynosić poniżej 80%. Jeśli współczynnik jest wysoki, oznacza to, że MySQL osiągnął kiedyś dużą liczbę połączeń, co doprowadziłoby do błędu „zbyt wielu połączeń”. Sprawdź aktualny współczynnik połączeń, aby zobaczyć, czy rzeczywiście utrzymuje się na niskim poziomie. W przeciwnym razie zwiększ zmienną max_connections. Sprawdź stan max_used_connections_time, aby wskazać, kiedy stan max_used_connections osiągnął swoją aktualną wartość.
Współczynnik trafień w pamięci podręcznej wątków
Status threads_created jest liczbą wątków utworzonych do obsługi połączeń. Jeśli threads_created jest duży, możesz zwiększyć wartość thread_cache_size. Współczynnik trafień/chybień w pamięci podręcznej można obliczyć jako:
Threads cache hit rate (%) = (threads_created / connections) x 100Jest to ułamek określający wskaźnik trafień w pamięci podręcznej wątków. Im bliżej mniej niż 50%, tym lepiej. Jeśli twój serwer widzi setki połączeń na sekundę, powinieneś normalnie ustawić wartość thread_cache_size na tyle, aby większość nowych połączeń używała wątków z pamięci podręcznej.
Wydajność zapytań
Pełne skanowanie tabeli
Stosunek pełnych skanów tabeli, operacja, która wymaga odczytania całej zawartości tabeli, a nie tylko wybranych części przy użyciu indeksu. Ta wartość jest wysoka, jeśli wykonujesz wiele zapytań, które wymagają sortowania wyników lub skanowania tabel. Ogólnie rzecz biorąc, sugeruje to, że tabele nie są odpowiednio indeksowane lub że zapytania nie są napisane w celu wykorzystania posiadanych indeksów. Aby obliczyć procent pełnych skanów tabeli:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Dobra wartość powinna wynosić poniżej 25%. Sprawdź wynik powolnego dziennika zapytań MySQL, aby znaleźć nieoptymalne zapytania.
Wybierz pełne dołączenie
Status select_full_join to liczba złączeń, które wykonują skanowanie tabel, ponieważ nie używają indeksów. Jeśli ta wartość nie jest równa 0, powinieneś dokładnie sprawdzić indeksy swoich tabel.
Wybierz sprawdzenie zakresu
Stan select_range_check to liczba złączeń bez kluczy, które sprawdzają użycie klucza po każdym wierszu. Jeśli to nie jest 0, powinieneś dokładnie sprawdzić indeksy swoich tabel.
Sortuj karty
Stosunek przejść scalających, które musiał wykonać algorytm sortowania. Jeśli ta wartość jest wysoka, powinieneś rozważyć zwiększenie wartości sort_buffer_size i read_rnd_buffer_size. Prosta kalkulacja współczynnika to:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Wartość współczynnika niższa niż 3 powinna być dobrą wartością. Jeśli chcesz zwiększyć sort_buffer_size lub read_rnd_buffer_size, spróbuj zwiększać je małymi krokami, aż osiągniesz akceptowalny współczynnik.
Wydajność InnoDB
Współczynnik trafień puli buforów InnoDB
Stosunek częstotliwości pobierania stron z pamięci zamiast z dysku. Jeśli wartość jest niska podczas wczesnego uruchamiania MySQL, poczekaj trochę, aż pula buforów się rozgrzeje. Aby uzyskać wskaźnik trafień puli buforów, użyj instrukcji SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Najlepszą wartością jest współczynnik trafień 1000/10000. Dla niższej wartości, na przykład, hit rate 986 / 1000 wskazuje, że na 1000 odczytów strony był w stanie odczytać strony w pamięci RAM 986 razy. Pozostałe 14 razy MySQL musiał odczytać strony z dysku. Mówiąc najprościej, 1000 / 1000 to najlepsza wartość, jaką staramy się tutaj osiągnąć, co oznacza, że często używane dane mieszczą się w całości w pamięci RAM.
Zwiększenie wartości zmiennej innodb_buffer_pool_size bardzo pomoże w uzyskaniu większej przestrzeni dla MySQL. Jednak wcześniej upewnij się, że masz wystarczające zasoby pamięci RAM. Pomocne może być również usunięcie zbędnych indeksów. Jeśli masz wiele instancji puli buforów, upewnij się, że współczynnik trafień dla każdej instancji wynosi 1000 / 1000.
Brudne strony InnoDB
Stosunek częstotliwości opróżniania InnoDB. Podczas obciążenia z dużym obciążeniem zapisem normalnym jest wzrost tego procentu.
Proste obliczenie to:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Dobra wartość powinna wynosić 75% i mniej. Jeśli procent brudnych stron pozostaje wysoki przez długi czas, możesz zwiększyć pulę buforów lub uzyskać szybsze dyski, aby uniknąć wąskich gardeł wydajności.
InnoDB czeka na punkt kontrolny
Stosunek tego, jak często InnoDB musi czytać lub tworzyć stronę, na której nie są dostępne żadne czyste strony. Zwykle zapisy do puli buforów InnoDB odbywają się w tle. Jeśli jednak konieczne jest odczytanie lub utworzenie strony, a nie ma dostępnych czystych stron, konieczne jest również poczekanie na pierwsze opróżnienie stron. Licznik innodb_buffer_pool_wait_free zlicza, ile razy to się zdarzyło. Aby obliczyć stosunek czasu oczekiwania InnoDB na punkt kontrolny, możemy użyć następującego obliczenia:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsJeśli wartość innodb_buffer_pool_wait_free jest większa niż 0, jest to silny wskaźnik, że pula buforów InnoDB jest zbyt mała i operacje musiały czekać w punkcie kontrolnym. Zwiększenie innodb_buffer_pool_size zwykle zmniejsza innodb_buffer_pool_wait_free, jak również ten współczynnik. Dobra wartość współczynnika powinna pozostać poniżej 1.
InnoDB czeka na ponowne logowanie
Stosunek redo log rywalizacji. Zaznacz innodb_log_waits i jeśli nadal rośnie, zwiększ innodb_log_buffer_size. Może to również oznaczać, że dyski są zbyt wolne i nie mogą utrzymać operacji we/wy dysku, być może z powodu szczytowego obciążenia zapisu. Użyj następującego obliczenia, aby obliczyć współczynnik oczekiwania na ponowne logowanie:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesDobra wartość współczynnika powinna wynosić poniżej 1. W przeciwnym razie zwiększ innodb_log_buffer_size.
Tabele
Wykorzystanie pamięci podręcznej tabeli
Stosunek wykorzystania pamięci podręcznej tabeli dla wszystkich wątków. Prosta kalkulacja to:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Dobra wartość powinna być mniejsza niż 80%. Zwiększaj zmienną table_open_cache, aż wartość procentowa osiągnie dobrą wartość.
Współczynnik trafień w pamięci podręcznej stołu
Stosunek wykorzystania trafień w pamięci podręcznej tabeli. Prosta kalkulacja to:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Dobra wartość współczynnika trafień powinna wynosić 90% i więcej. W przeciwnym razie zwiększ zmienną table_open_cache, aż współczynnik trafień osiągnie dobrą wartość.
Monitorowanie wskaźników za pomocą ClusterControl
ClusterControl obsługuje Percona Server for MySQL i zapewnia zagregowany widok wszystkich węzłów w klastrze na stronie ClusterControl -> Wydajność -> Stan bazy danych. Zapewnia to scentralizowane podejście do wyszukiwania wszystkich stanów na wszystkich hostach z możliwością filtrowania stanu, jak pokazano na poniższym zrzucie ekranu:
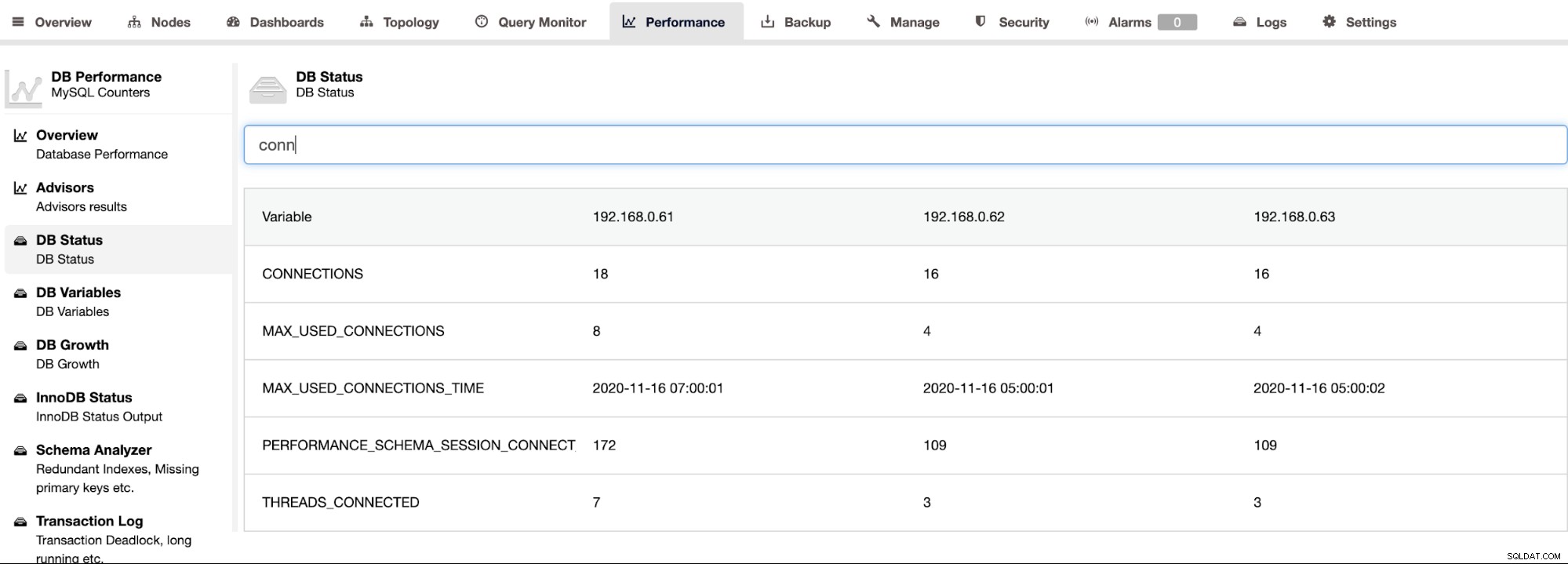
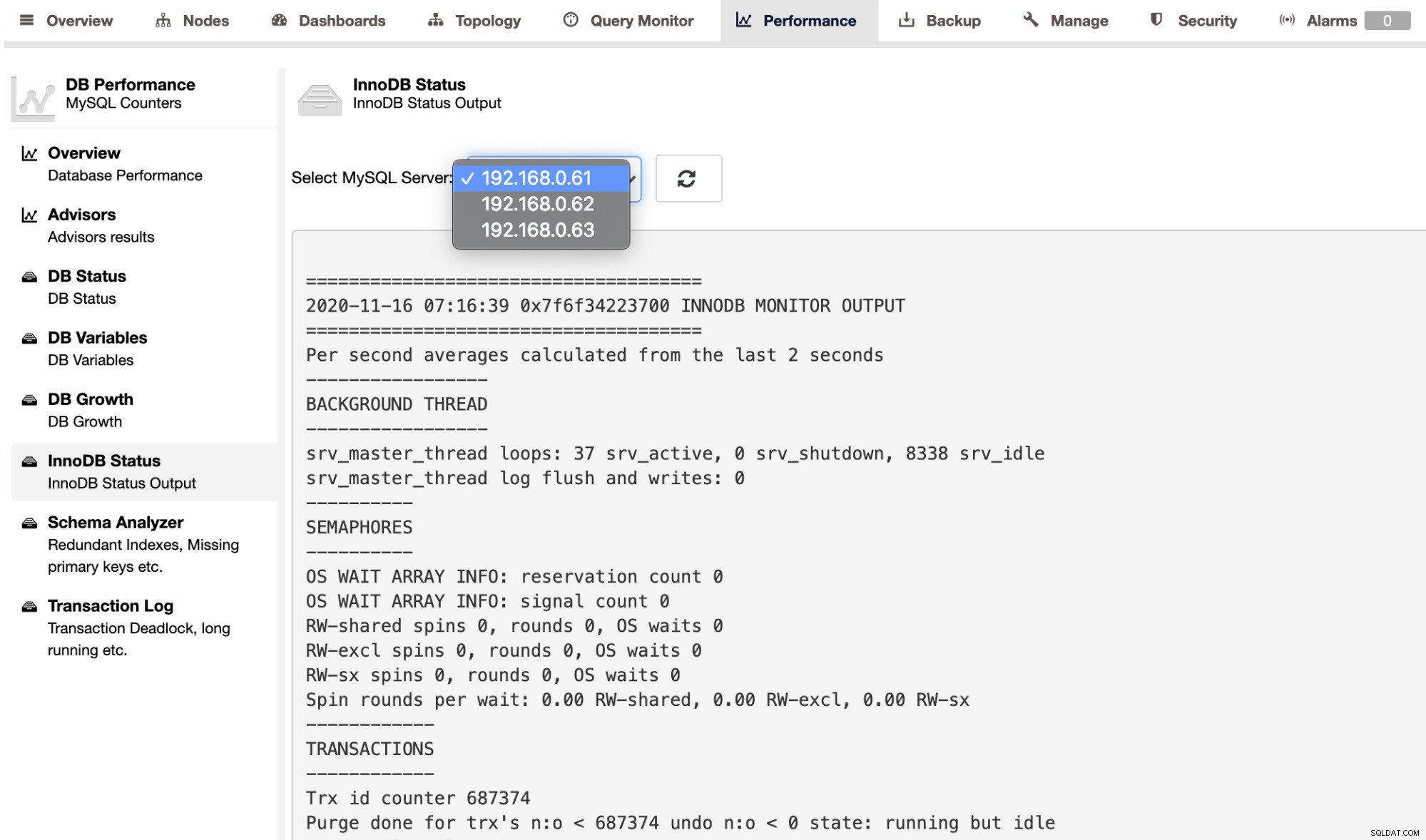
Aby pobrać dane wyjściowe SHOW ENGINE INNODB STATUS dla pojedynczego serwera, możesz użyj strony Wydajność -> Stan InnoDB, jak pokazano poniżej:
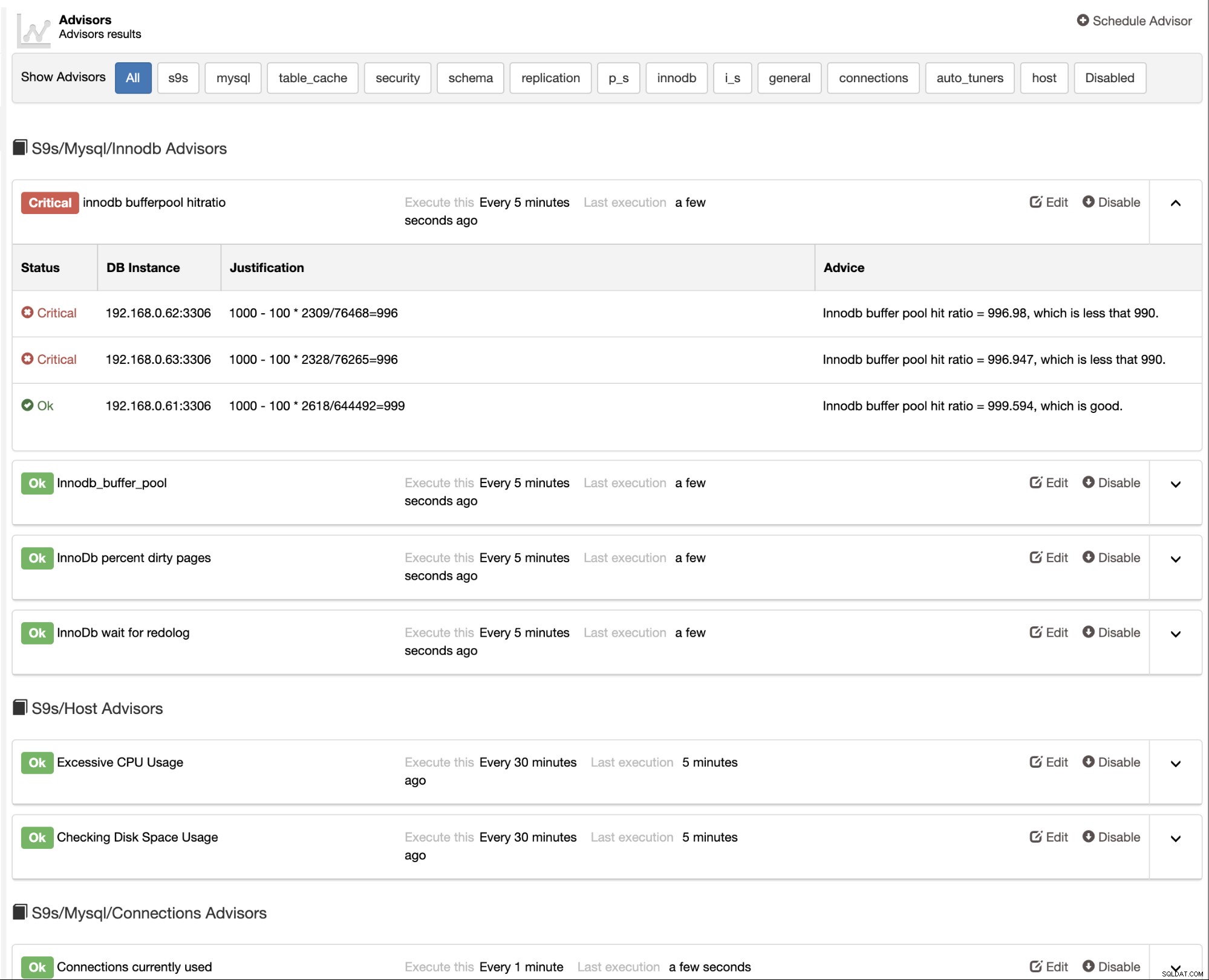
ClusterControl udostępnia również wbudowane doradcy, których można użyć do śledzenia bazy danych występ. Ta funkcja jest dostępna w ClusterControl -> Wydajność -> Doradcy:
Doradcy to w zasadzie mini-programy wykonywane przez ClusterControl w zaplanowanym czasie, jak cron Oferty pracy. Możesz zaplanować doradcę, klikając przycisk „Zaplanuj doradcę” i wybierając dowolnego istniejącego doradcę z drzewa obiektów Developer Studio:
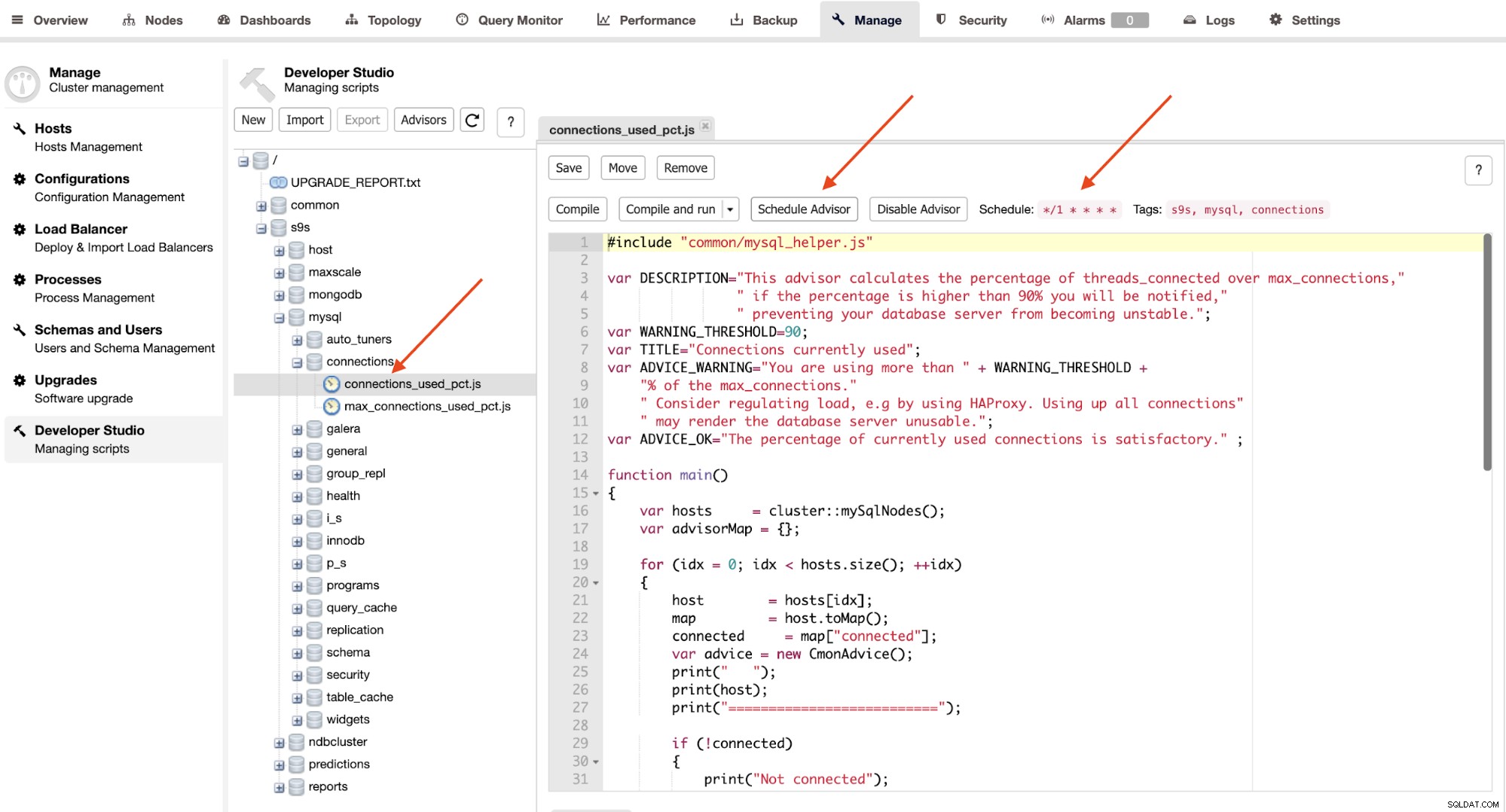
Kliknij przycisk „Doradca harmonogramu”, aby ustawić argument harmonogramu na pass, a także tagi doradcy. Możesz również skompilować doradcę, aby natychmiast wyświetlić dane wyjściowe, klikając przycisk „Skompiluj i uruchom”, w którym pod „Wiadomościami” powinien pojawić się następujący wynik:

Możesz stworzyć własnego doradcę, odwołując się do tego Przewodnika programisty, napisanego w ClusterControl Domain Specific Language (bardzo podobny do Javascript) lub dostosuj istniejącego doradcę, aby pasował do Twoich zasad monitorowania. Krótko mówiąc, obowiązek monitorowania ClusterControl można rozszerzyć o nieograniczone możliwości dzięki doradcom ClusterControl.



