W poprzednim blogu omawialiśmy migrację samodzielnej konfiguracji Moodle do konfiguracji skalowalnej opartej na bazie danych w klastrach. Następnym krokiem, o którym musisz pomyśleć, jest mechanizm przełączania awaryjnego - co zrobisz, jeśli i kiedy twoja usługa bazy danych przestanie działać.
Awaria serwera bazy danych nie jest niczym niezwykłym, jeśli posiadasz MySQL Replication jako wewnętrzną bazę danych Moodle, a jeśli tak się stanie, będziesz musiał znaleźć sposób na odzyskanie swojej topologii, na przykład promując serwer zapasowy do stać się nowym serwerem głównym. Automatyczne przełączanie awaryjne bazy danych Moodle MySQL ułatwia przestoje aplikacji. Wyjaśnimy, jak działają mechanizmy przełączania awaryjnego i jak wbudować automatyczne przełączanie awaryjne w konfiguracji.
Architektura wysokiej dostępności dla bazy danych MySQL
Architekturę wysokiej dostępności można osiągnąć poprzez klastrowanie bazy danych MySQL na kilka różnych sposobów. Możesz użyć replikacji MySQL, skonfigurować wiele replik, które będą ściśle podążać za twoją podstawową bazą danych. Ponadto można umieścić moduł równoważenia obciążenia bazy danych, aby podzielić ruch odczytu/zapisu i rozdzielić ruch między węzły odczytu-zapisu i tylko do odczytu. Architekturę bazy danych o wysokiej dostępności wykorzystującą replikację MySQL można opisać w następujący sposób:
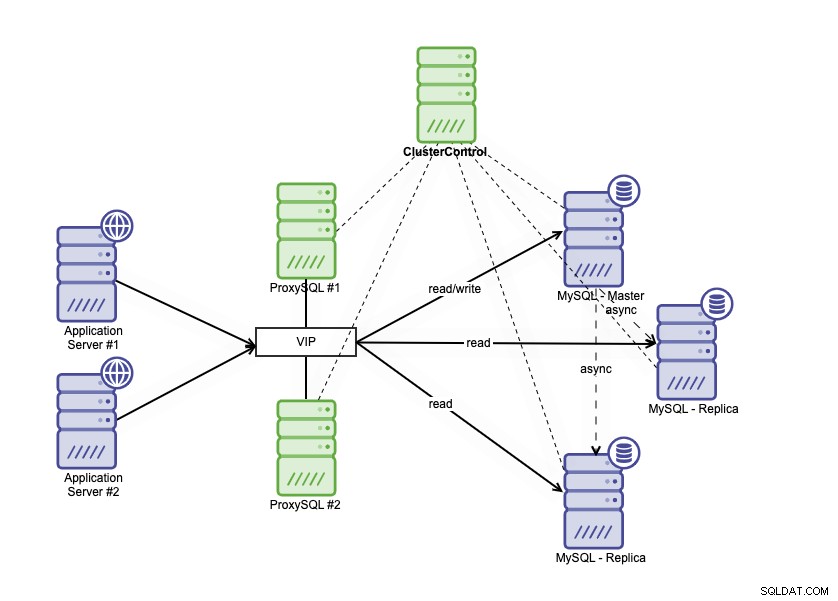
Składa się z jednej podstawowej bazy danych, dwóch replik bazy danych i systemów równoważenia obciążenia bazy danych (w tym blogu używamy ProxySQL jako równoważenia obciążenia bazy danych) i keepalive jako usługa do monitorowania procesów ProxySQL. Używamy wirtualnego adresu IP jako pojedynczego połączenia z aplikacji. Ruch będzie dystrybuowany do aktywnego systemu równoważenia obciążenia na podstawie flagi roli w keepalive.
ProxySQL jest w stanie analizować ruch i rozumieć, czy żądanie jest odczytem czy zapisem. Następnie prześle żądanie do odpowiedniego hosta (ów).
Przełączanie awaryjne na replikację MySQL
Replikacja MySQL wykorzystuje logowanie binarne do replikacji danych z bazy podstawowej do replik. Repliki łączą się z węzłem podstawowym, a każda zmiana jest replikowana i zapisywana w dziennikach przekaźnikowych węzłów repliki przez IO_THREAD. Po zapisaniu zmian w dzienniku przekaźnika, proces SQL_THREAD będzie kontynuował wprowadzanie danych do bazy danych replik.
Domyślne ustawienie parametru tylko do odczytu w replice jest włączone. Służy do ochrony samej repliki przed bezpośrednim zapisem, więc zmiany zawsze będą pochodzić z podstawowej bazy danych. Jest to ważne, ponieważ nie chcemy, aby replika odbiegała od serwera podstawowego. Scenariusz przełączania awaryjnego w replikacji MySQL ma miejsce, gdy podstawowy jest nieosiągalny. Powodów może być wiele; np. awarie serwera lub problemy z siecią.
Musisz promować jedną z replik do podstawowej, wyłączyć parametr tylko do odczytu promowanej repliki, aby można było do niej zapisywać. Musisz również zmienić drugą replikę, aby połączyć się z nową podstawową. W trybie GTID nie trzeba zapisywać nazwy dziennika binarnego ani pozycji, z której można wznowić replikację. Jednak w tradycyjnej replikacji opartej na dziennikach binarnych zdecydowanie musisz znać nazwę ostatniego dziennika binarnego i pozycję, od której chcesz kontynuować. Przełączanie awaryjne w replikacji opartej na binlogach jest dość złożonym procesem, ale nawet przełączanie awaryjne w replikacji opartej na GTID nie jest trywialne, ponieważ trzeba zwracać uwagę na takie rzeczy, jak błędne transakcje. Wykrycie awarii to jedno, a następnie zareagowanie na awarię z krótkim opóźnieniem prawdopodobnie nie jest możliwe bez automatyzacji.
Jak ClusterControl włącza automatyczne przełączanie awaryjne
ClusterControl umożliwia automatyczne przełączanie awaryjne bazy danych Moodle MySQL. Istnieje funkcja automatycznego odzyskiwania klastra i węzła, która uruchamia proces przełączania awaryjnego w przypadku awarii podstawowej bazy danych.
Będziemy symulować, jak przebiega automatyczne przełączanie awaryjne w ClusterControl. Dokonamy awarii podstawowej bazy danych i po prostu zobaczymy na desce rozdzielczej ClusterControl. Poniżej znajduje się aktualna topologia klastra:
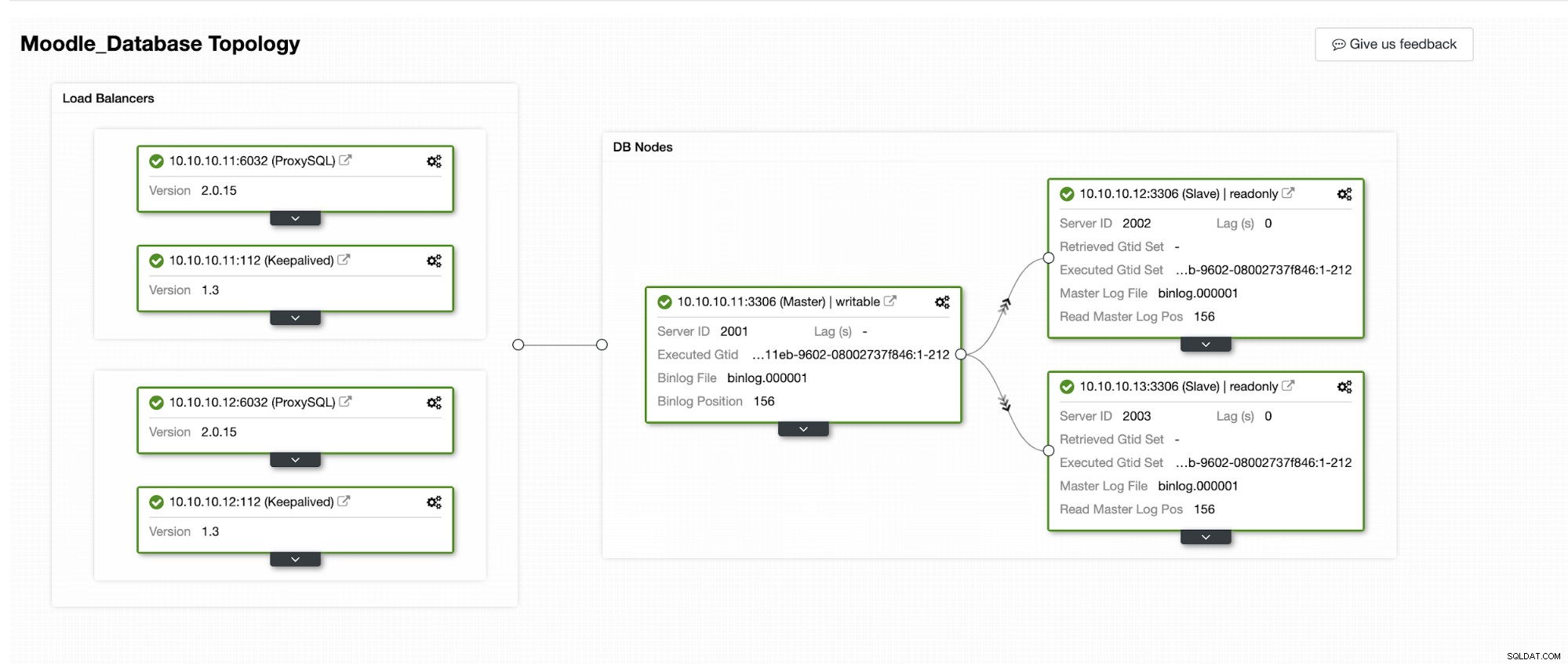
Podstawowa baza danych używa adresu IP 10.10.10.11, a repliki to:10.10.10.12 i 10.10.10.13. Kiedy awaria nastąpi na podstawowym, ClusterControl wyzwala alert i rozpoczyna się przełączenie awaryjne, jak pokazano na poniższym obrazku:
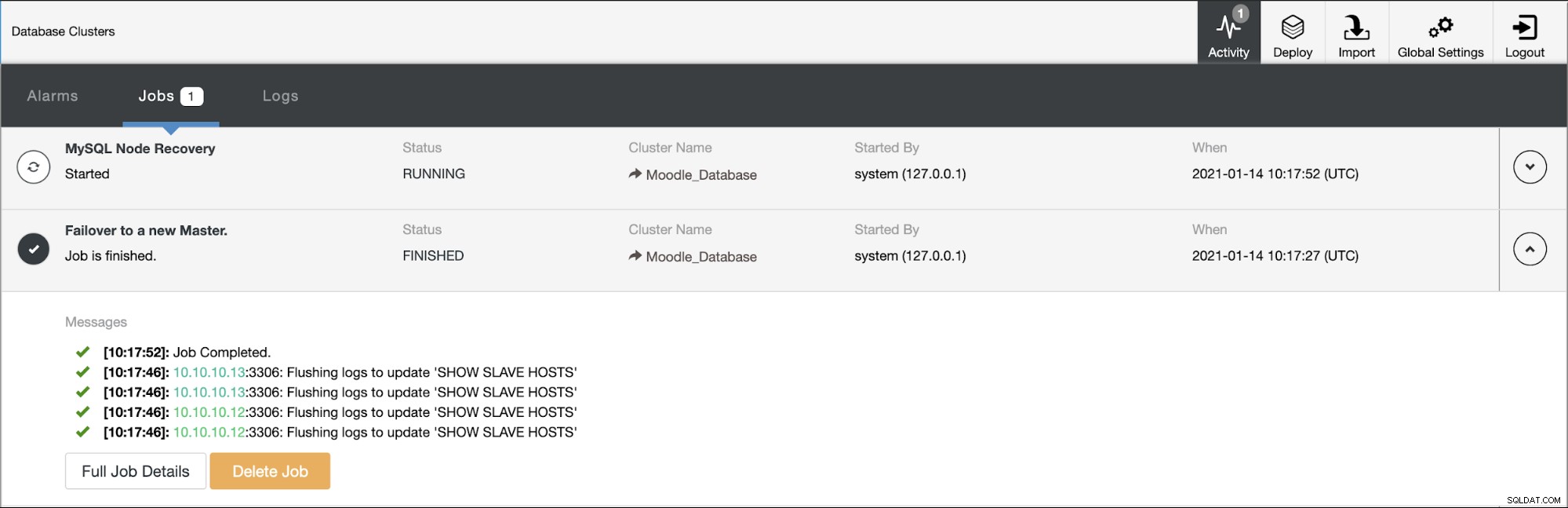
Jedna z replik zostanie podniesiona do poziomu podstawowego, w wyniku czego Topologia będzie na poniższym obrazku:
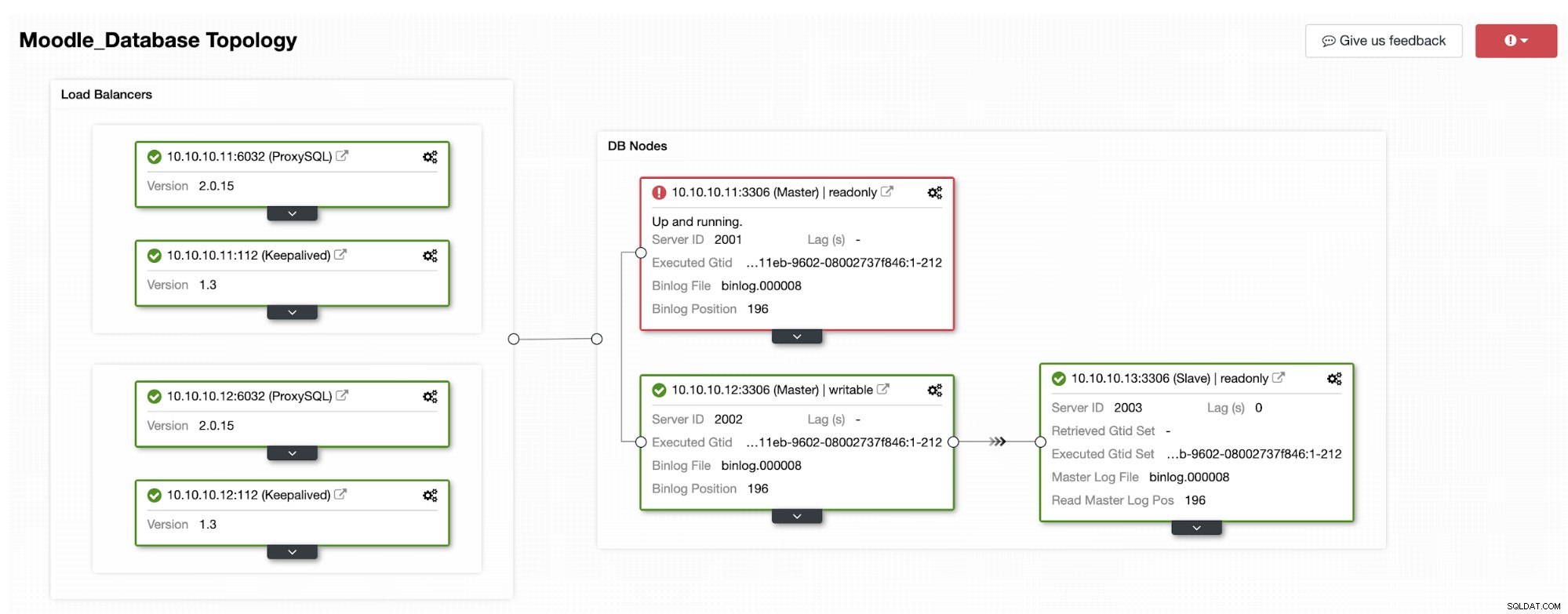
Adres IP 10.10.10.12 obsługuje teraz ruch zapisu jako podstawowy, a także pozostaje nam tylko jedna replika, która ma adres IP 10.10.10.13. Po stronie ProxySQL proxy automatycznie wykryje nowy serwer podstawowy. Grupa hostów (HG10) nadal obsługuje ruch zapisu, który ma członka 10.10.10.12, jak pokazano poniżej:

Hostgroup (HG20) nadal może obsługiwać ruch odczytu, ale jak widać węzeł 10.10.10.11 jest offline z powodu awarii :
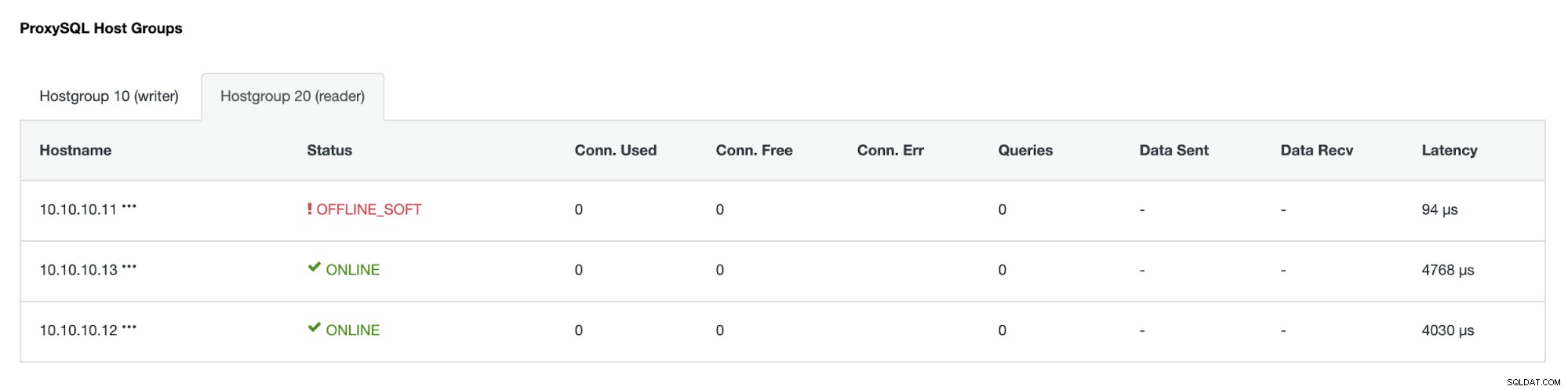
Gdy podstawowy uszkodzony serwer wróci do trybu online, nie zostanie automatycznie - wprowadzono w topologii bazy danych. Ma to na celu uniknięcie utraty informacji dotyczących rozwiązywania problemów, ponieważ ponowne wprowadzenie węzła jako repliki może wymagać zastąpienia niektórych dzienników lub innych informacji. Ale możliwe jest skonfigurowanie automatycznego ponownego dołączania do uszkodzonego węzła.