Testy wersji są zazwyczaj jednym z etapów całego procesu wdrażania. Piszesz kod, a następnie weryfikujesz, jak zachowuje się w środowisku przejściowym, a na koniec wdrażasz nowy kod na produkcji. Bazy danych są wewnętrzne dla każdego rodzaju aplikacji, dlatego ważne jest, aby zweryfikować, w jaki sposób zmiany związane z bazą danych zmieniają aplikację. Można to zweryfikować na kilka sposobów; jednym z nich byłoby użycie dedykowanej repliki. Zobaczmy, jak można to zrobić.
Oczywiście nie chcesz, aby ten proces był ręczny — powinien być częścią procesów CI/CD Twojej firmy. W zależności od konkretnej aplikacji, środowiska i procesów, które posiadasz, możesz używać replik utworzonych ad hoc lub replik, które zawsze są częścią środowiska bazy danych.
Sposób działania Galera Cluster polega na tym, że obsługuje on zmiany schematu w określony sposób. Możliwe jest wykonanie zmiany schematu na pojedynczym węźle w klastrze, ale jest to trudne, ponieważ nie obsługuje wszystkich możliwych zmian schematu i wpłynie na produkcję, jeśli coś pójdzie nie tak. Taki węzeł musiałby zostać w pełni przebudowany za pomocą SST, co oznacza, że jeden z pozostałych węzłów Galera będzie musiał pełnić rolę dawcy i przekazywać wszystkie swoje dane przez sieć.
Alternatywą będzie użycie repliki lub nawet całego dodatkowego klastra Galera działającego jako replika. Oczywiście proces musi zostać zautomatyzowany, aby można go było podłączyć do potoku rozwoju. Można to zrobić na wiele sposobów:skrypty lub liczne narzędzia do orkiestracji infrastruktury, takie jak Ansible, Chef, Puppet lub Salt stack. Nie będziemy ich szczegółowo opisywać, ale chcielibyśmy, abyś pokazał kroki wymagane do prawidłowego działania całego procesu, a implementację w jednym z narzędzi pozostawiamy Tobie.
Automatyczne testy wersji
Przede wszystkim chcemy mieć możliwość łatwego wdrażania nowej bazy danych. Powinien być zaopatrzony w najnowsze dane, a można to zrobić na wiele sposobów - możesz skopiować dane z produkcyjnej bazy danych na serwer testowy; to najprostsza rzecz do zrobienia. Alternatywnie można użyć najnowszej kopii zapasowej — takie podejście ma dodatkowe korzyści z testowania przywracania kopii zapasowej. Weryfikacja kopii zapasowej jest niezbędna w każdym poważnym wdrożeniu, a odbudowanie konfiguracji testowych to świetny sposób na dwukrotne sprawdzenie działania procesu przywracania. Pomaga również w określeniu czasu procesu przywracania — wiedza, ile czasu zajmuje przywrócenie kopii zapasowej, pomaga prawidłowo ocenić sytuację w scenariuszu odzyskiwania po awarii.
Po udostępnieniu danych w bazie danych można skonfigurować ten węzeł jako replikę podstawowego klastra. Ma swoje plusy i minusy. Byłoby idealnie, gdybyś mógł ponownie wykonać cały ruch do węzła autonomicznego - w takim przypadku nie ma potrzeby konfigurowania replikacji. Niektóre z równoważników obciążenia, takie jak ProxySQL, umożliwiają dublowanie ruchu i wysyłanie jego kopii w inne miejsce. Z drugiej strony, następną najlepszą rzeczą jest replikacja. Tak, nie możesz wykonywać zapisów bezpośrednio w tym węźle, co zmusza Cię do zaplanowania ponownego wykonania zapytań, ponieważ najprostsze podejście polegające na odpowiedzi na nie nie zadziała. Z drugiej strony, wszystkie zapisy zostaną ostatecznie wykonane przez wątek SQL, więc musisz tylko zaplanować, jak radzić sobie z zapytaniami SELECT.
W zależności od dokładnej zmiany, możesz przetestować proces zmiany schematu. Zmiany schematu są dość powszechne i mogą mieć nawet poważny wpływ na wydajność bazy danych. Dlatego ważne jest, aby zweryfikować je przed zastosowaniem do produkcji. Chcemy przyjrzeć się czasowi potrzebnemu na wykonanie zmiany i zweryfikować, czy zmiana może być zastosowana na węzłach oddzielnie, czy jest wymagana do wykonania zmiany w całej topologii jednocześnie. To powie nam, jakiego procesu powinniśmy użyć dla danej zmiany schematu.
Korzystanie z ClusterControl do poprawy automatyzacji testów wydań
ClusterControl zawiera zestaw funkcji, które mogą pomóc w zautomatyzowaniu testów wersji. Przyjrzyjmy się, co oferuje. Aby było jasne, funkcje, które pokażemy, są dostępne na kilka sposobów. Najprostszym sposobem jest użycie interfejsu użytkownika, ale nie jest konieczne to, co chcesz robić, jeśli masz na myśli automatyzację. Są jeszcze dwa sposoby, aby to zrobić:Interfejs wiersza poleceń do ClusterControl i RPC API. W obu przypadkach zadania mogą być wyzwalane z zewnętrznych skryptów, co pozwala na podłączenie ich do istniejących procesów CI/CD. Zaoszczędzi to również mnóstwo czasu, ponieważ wdrożenie klastra może być tylko kwestią wykonania jednego polecenia zamiast ręcznego konfigurowania.
Wdrażanie klastra testowego
Przede wszystkim ClusterControl oferuje opcję wdrożenia nowego klastra i udostępnienia mu danych z istniejącej bazy danych. Sama ta funkcja umożliwia łatwe wdrożenie udostępniania serwera pomostowego.
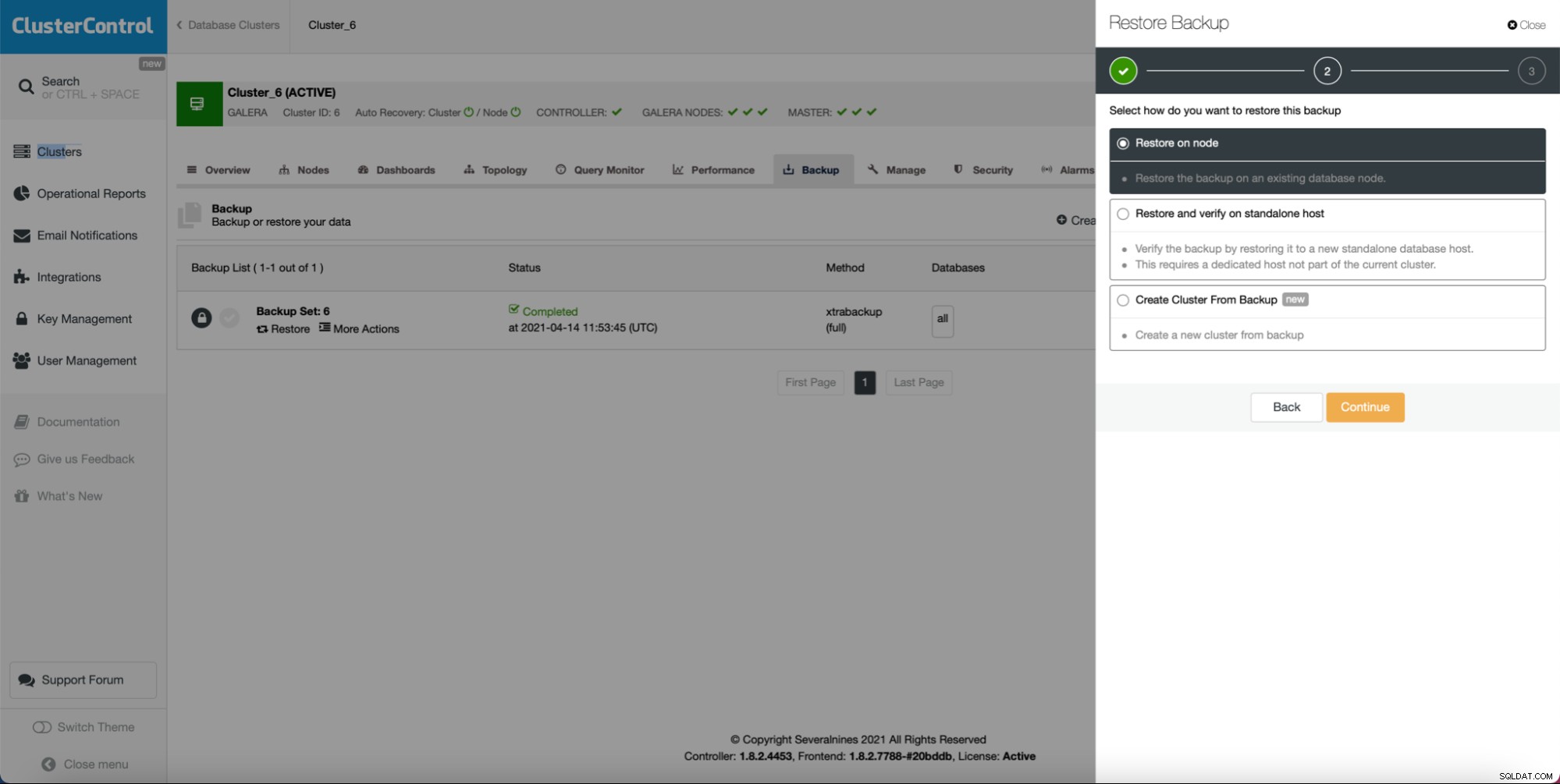
Jak widać, jeśli masz utworzoną kopię zapasową, może utworzyć nowy klaster i udostępnić go przy użyciu danych z kopii zapasowej:
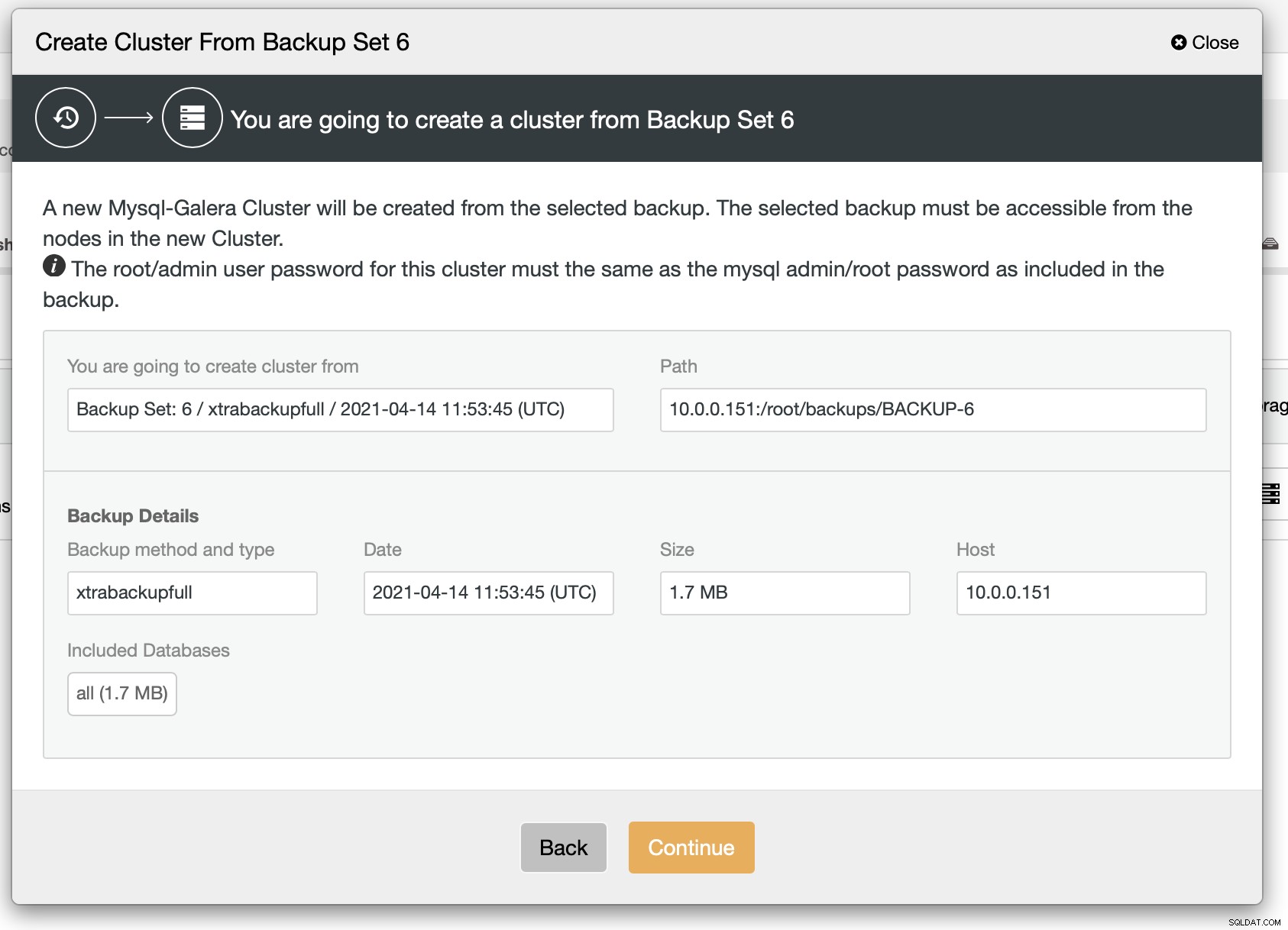
Jak widać, istnieje krótkie podsumowanie tego, co się wydarzy. Jeśli klikniesz Kontynuuj, przejdziesz dalej.
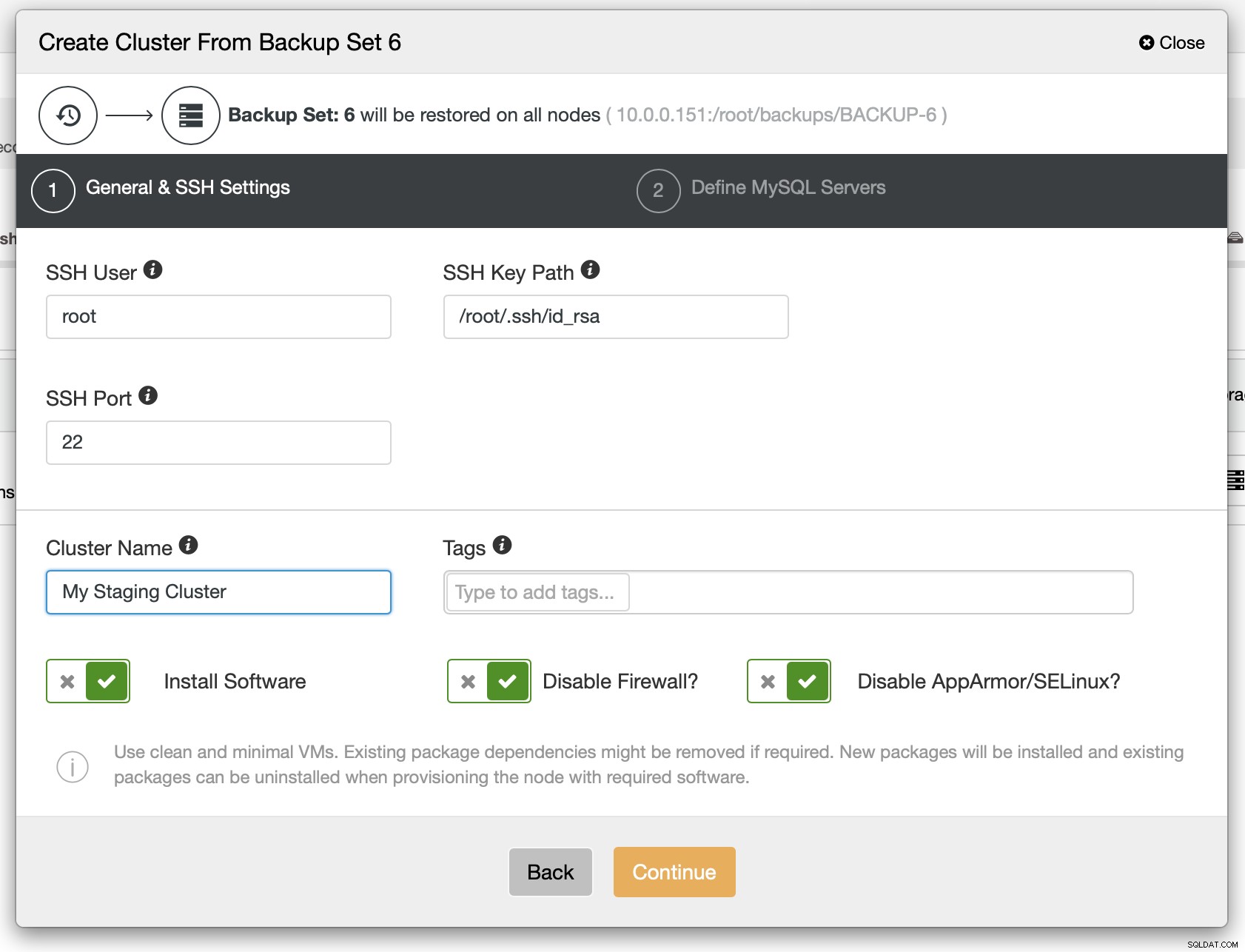
W następnym kroku należy zdefiniować łączność SSH — musi ona istnieć, zanim ClusterControl będzie mógł wdrożyć węzły.
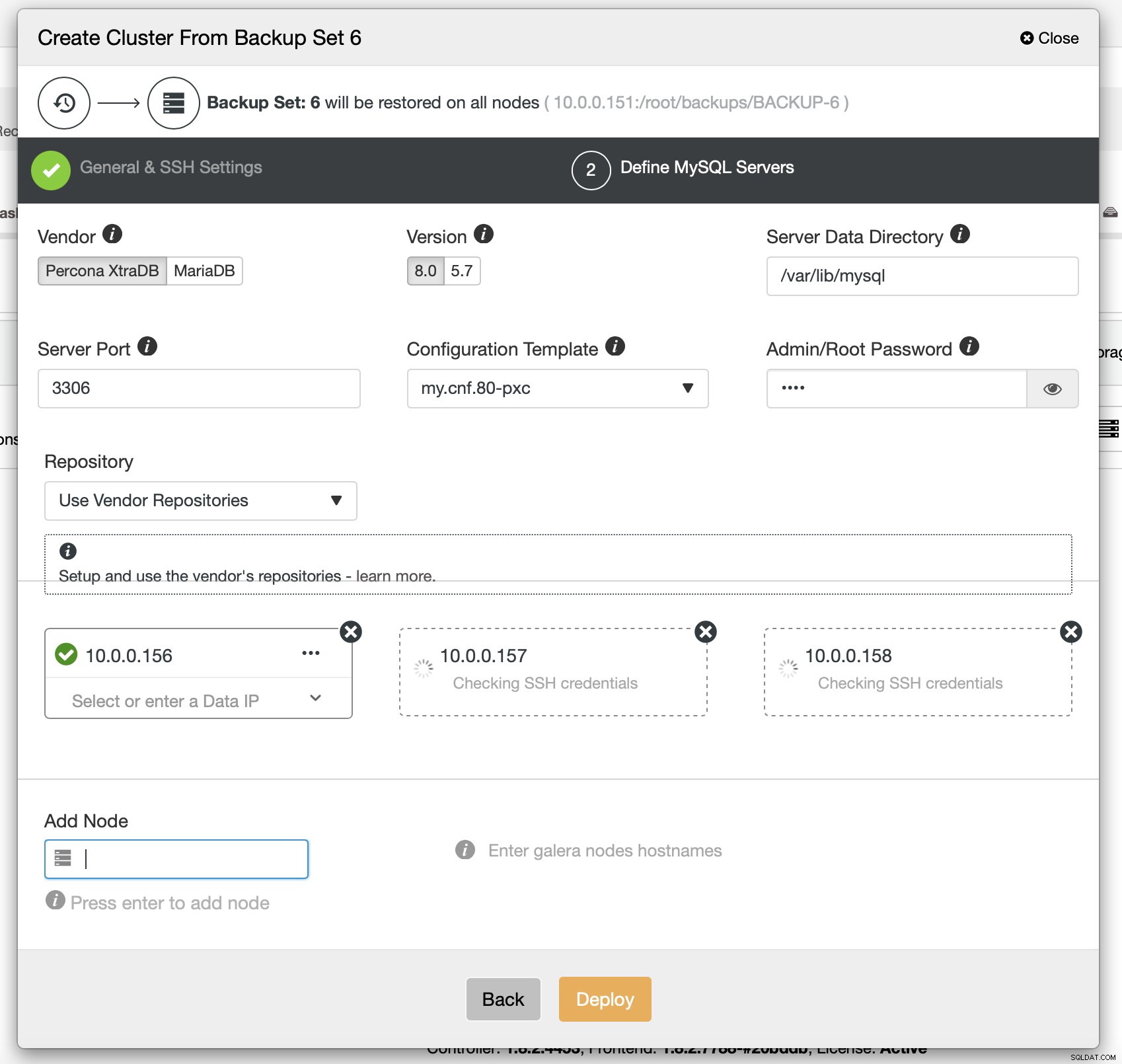
Na koniec musisz wybrać (między innymi) dostawcę, wersję i nazwy hostów węzłów, których chcesz używać w klastrze. To po prostu.
Polecenie CLI, które wykona to samo, wygląda tak:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Konfigurowanie ProxySQL w celu odzwierciedlenia ruchu
Jeśli mamy wdrożony klaster, możemy chcieć wysłać do niego ruch produkcyjny, aby zweryfikować, jak nowy schemat obsługuje istniejący ruch. Jednym ze sposobów na to jest użycie ProxySQL.
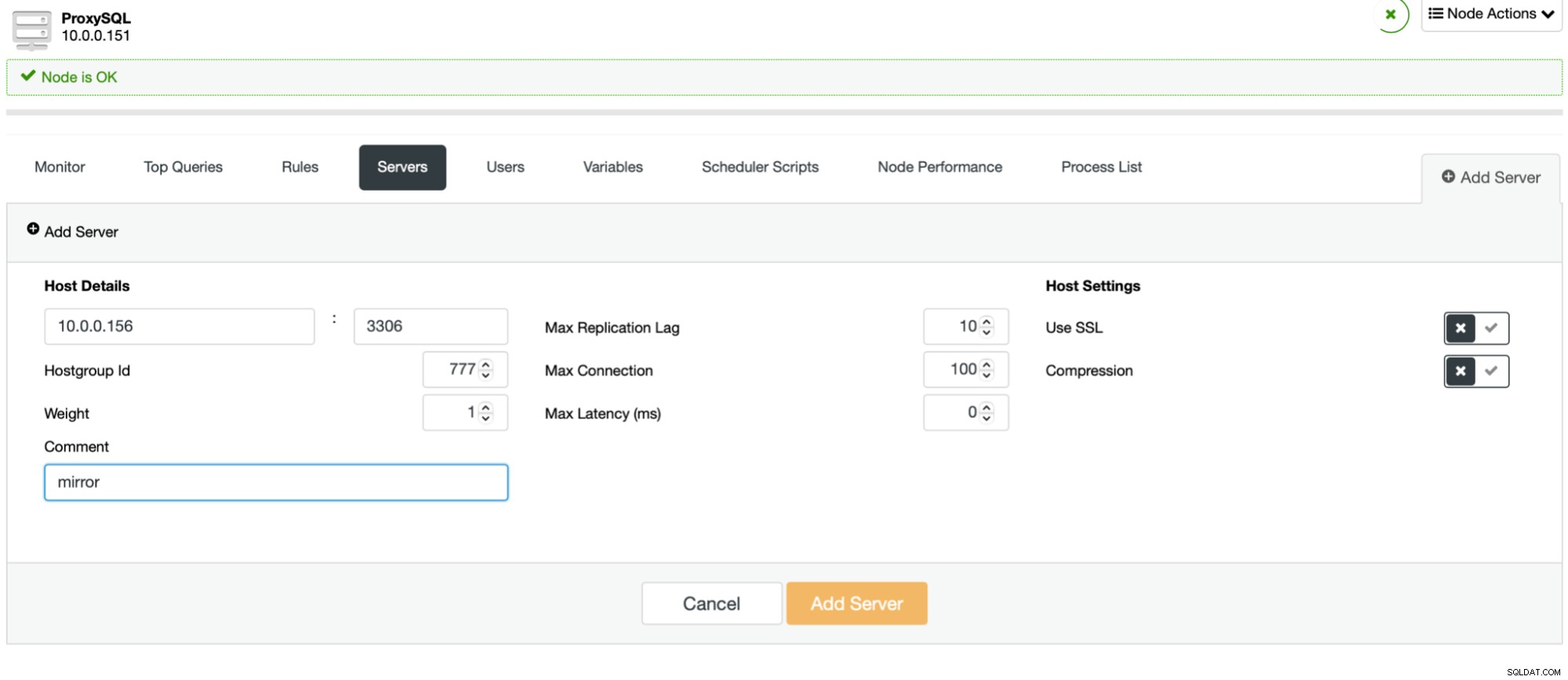
Proces jest łatwy. Najpierw powinieneś dodać węzły do ProxySQL. Powinny należeć do oddzielnej grupy hostów, która nie jest jeszcze używana. Upewnij się, że użytkownik monitora ProxySQL będzie miał do nich dostęp.
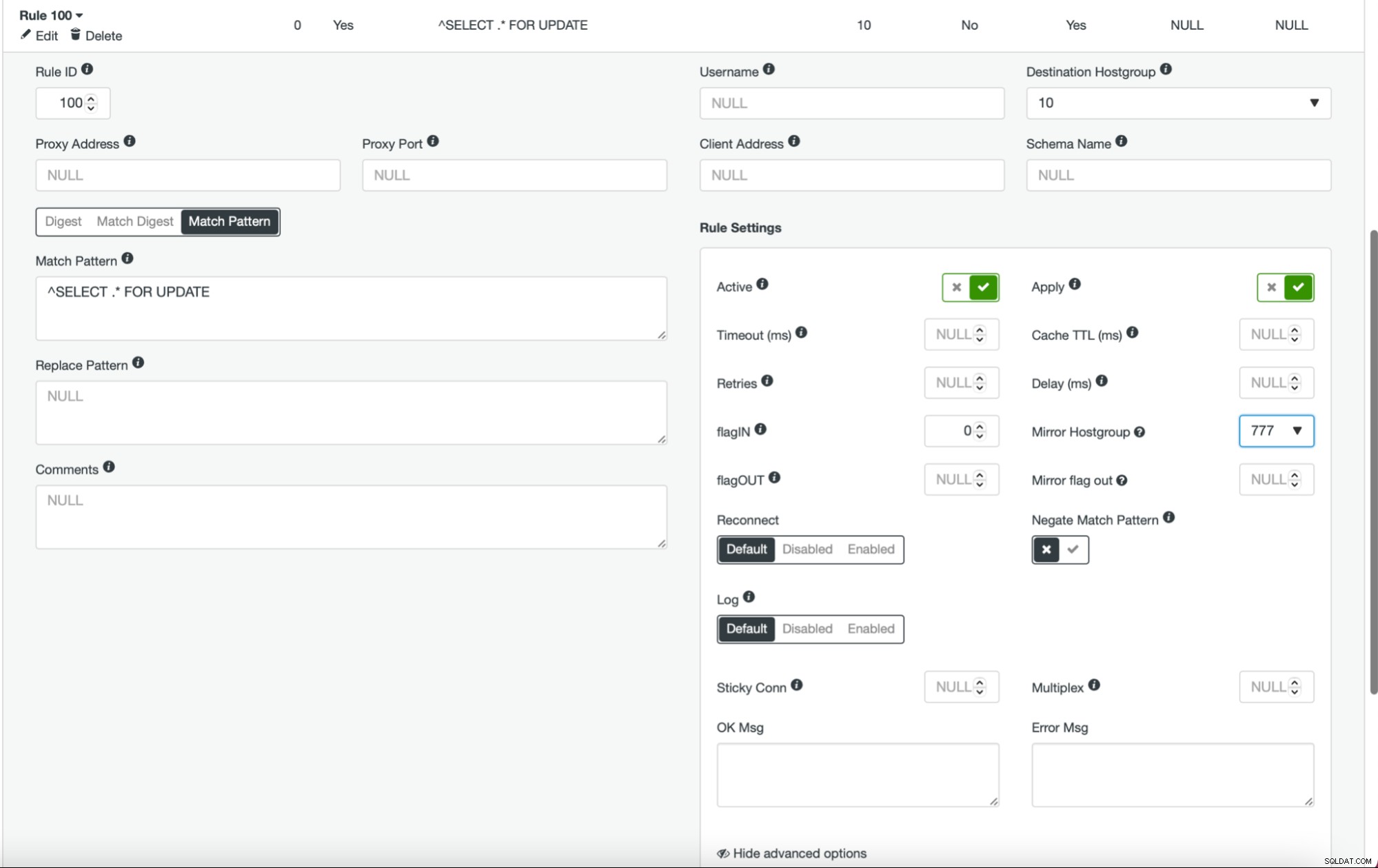
Po wykonaniu tej czynności i skonfigurowaniu wszystkich (lub niektórych) węzłów w grupie hostów, możesz edytować reguły zapytań i zdefiniować Mirror Hostgroup (jest to dostępne w opcjach zaawansowanych). Jeśli chcesz to zrobić dla całego ruchu, prawdopodobnie chcesz w ten sposób edytować wszystkie reguły zapytań. Jeśli chcesz dublować tylko zapytania SELECT, powinieneś edytować odpowiednie reguły zapytań. Po wykonaniu tej czynności Twój klaster pomostowy powinien zacząć odbierać ruch produkcyjny.
Wdrażanie klastra jako urządzenia podrzędnego
Jak omówiliśmy wcześniej, alternatywnym rozwiązaniem byłoby utworzenie nowego klastra, który będzie działał jako replika istniejącej konfiguracji. Dzięki takiemu podejściu możemy automatycznie testować wszystkie zapisy, korzystając z replikacji. SELECTy mogą być testowane przy użyciu podejścia, które opisaliśmy powyżej - dublowanie poprzez ProxySQL.
Wdrożenie klastra slave jest dość proste.
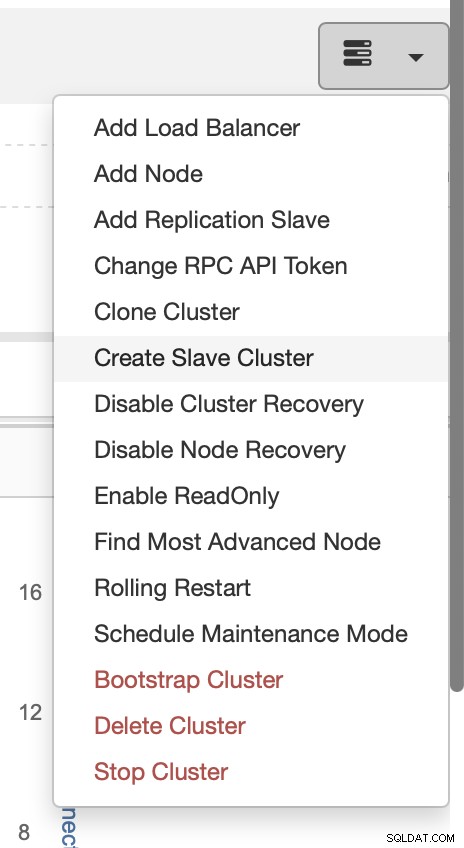
Wybierz zadanie Utwórz klaster podrzędny.
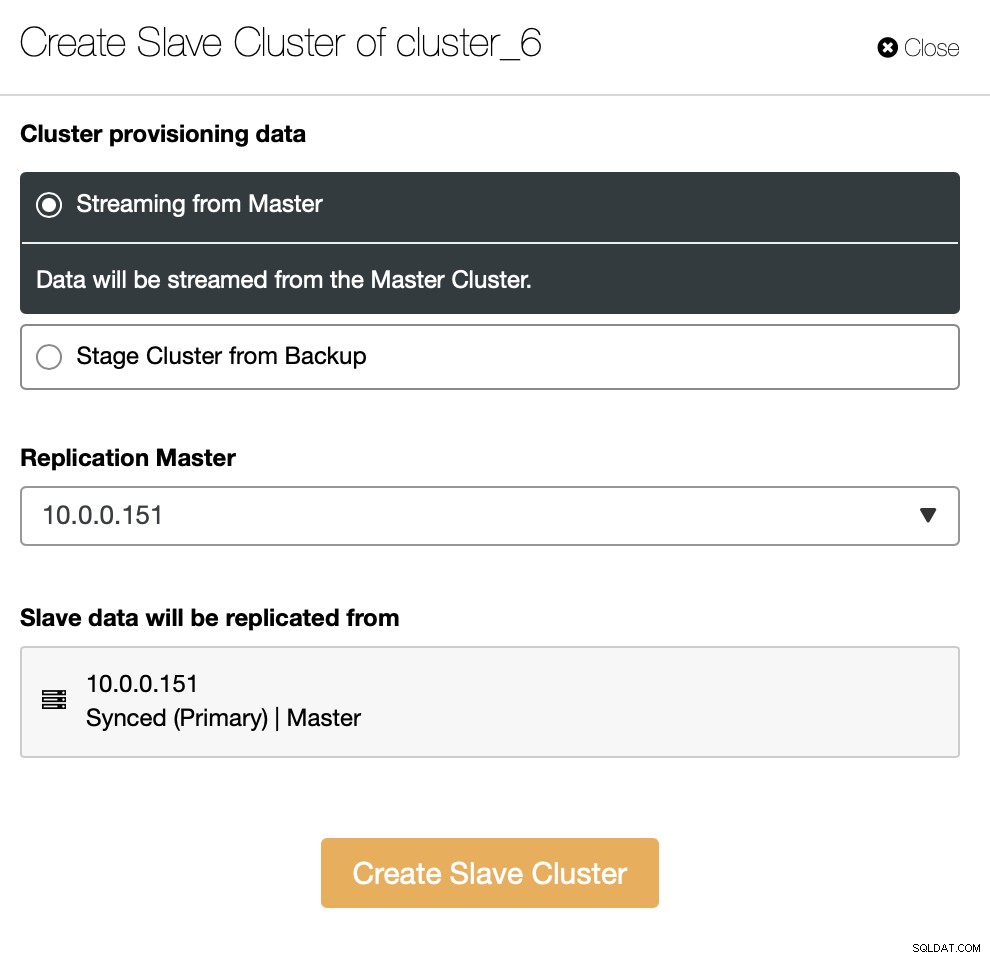
Musisz zdecydować, jak chcesz ustawić replikację. Możesz przenieść wszystkie dane z urządzenia nadrzędnego do nowych węzłów.
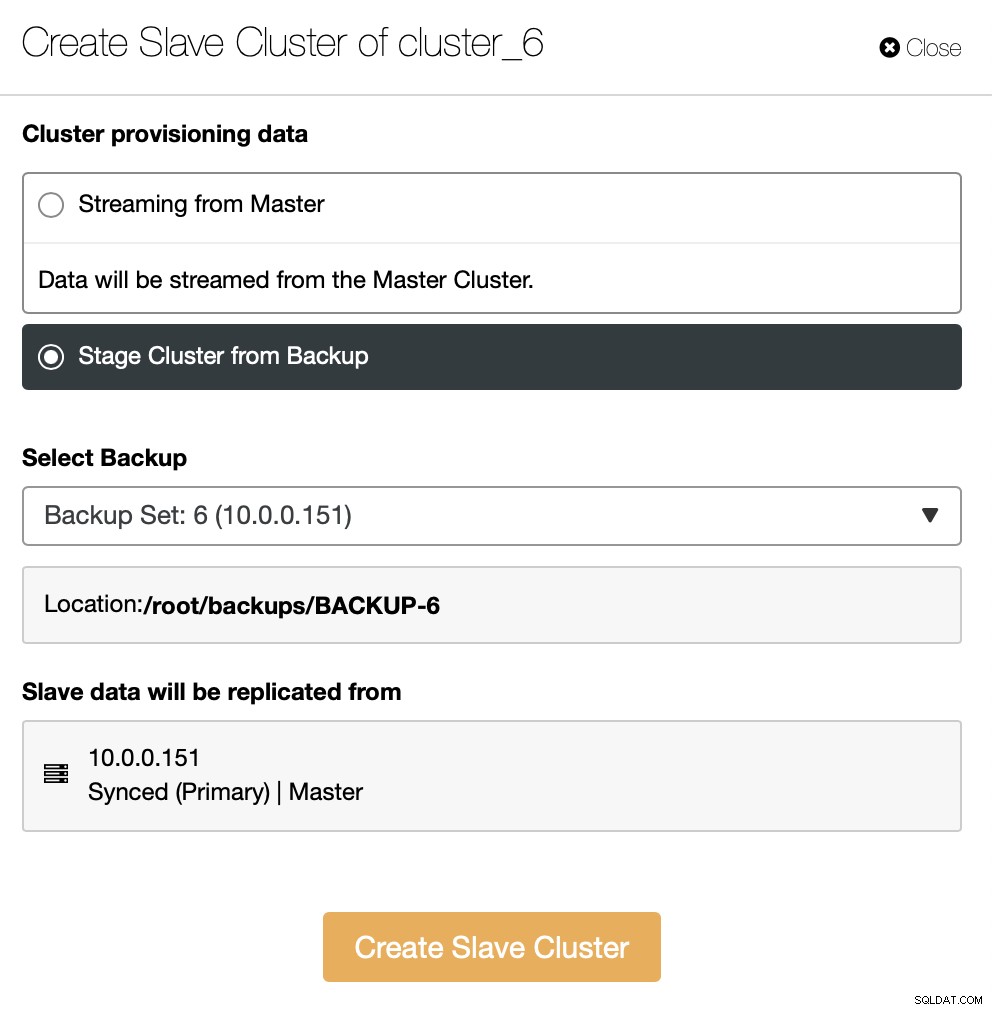
Alternatywnie możesz użyć istniejącej kopii zapasowej do udostępnienia nowego klastra. Pomoże to zmniejszyć obciążenie w węźle nadrzędnym - zamiast przesyłać wszystkie dane, tylko transakcje, które zostały wykonane między utworzeniem kopii zapasowej a konfiguracją replikacji, będą musiały zostać przeniesione.
Reszta polega na wykonaniu standardowego kreatora wdrażania, definiując łączność SSH, wersję, dostawcę, hosty i tak dalej. Po wdrożeniu zobaczysz klaster na liście.
Alternatywnym rozwiązaniem dla interfejsu użytkownika jest wykonanie tego za pomocą RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Naprzód
Jeśli chcesz dowiedzieć się więcej o sposobach integracji procesów z ClusterControl, chcielibyśmy skierować Cię do dokumentacji, w której mamy całą sekcję dotyczącą opracowywania rozwiązań, w których ClusterControl odgrywa rolę znacząca rola:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Mamy nadzieję, że ten krótki blog okazał się przydatny i pouczający. Jeśli masz jakiekolwiek pytania związane z integracją ClusterControl ze swoim środowiskiem, skontaktuj się z nami, a my dołożymy wszelkich starań, aby Ci pomóc.