Przykład można znaleźć tutaj:https://github.com/afedulov/routing-data- źródło .
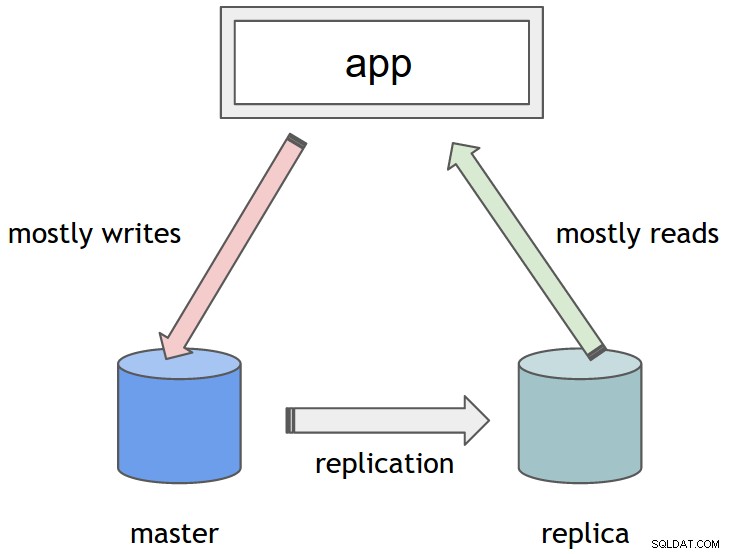
Spring udostępnia odmianę DataSource o nazwie AbstractRoutingDatasource . Może być używany zamiast standardowych implementacji DataSource i umożliwia mechanizmowi określania, którego konkretnego DataSource należy użyć dla każdej operacji w czasie wykonywania. Wszystko, co musisz zrobić, to go rozszerzyć i dostarczyć implementację abstrakcyjnego determineCurrentLookupKey metoda. To jest miejsce na zaimplementowanie niestandardowej logiki w celu określenia konkretnego DataSource. Zwrócony obiekt służy jako klucz wyszukiwania. Zazwyczaj jest to String lub en Enum, używany jako kwalifikator w konfiguracji Spring (szczegóły poniżej).
package website.fedulov.routing.RoutingDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DbContextHolder.getDbType();
}
}
Być może zastanawiasz się, co to jest ten obiekt DbContextHolder i skąd wie, który identyfikator DataSource ma zwrócić? Pamiętaj, że determineCurrentLookupKey Metoda będzie wywoływana za każdym razem, gdy TransactionsManager zażąda połączenia. Należy pamiętać, że każda transakcja jest „skojarzona” z osobnym wątkiem. Dokładniej, TransactionsManager wiąże połączenie z bieżącym wątkiem. Dlatego, aby wysłać różne transakcje do różnych docelowych DataSource, musimy upewnić się, że każdy wątek może wiarygodnie zidentyfikować, który DataSource jest przeznaczony do użycia. Dzięki temu naturalne jest wykorzystanie zmiennych ThreadLocal do powiązania określonego DataSource z wątkiem, a tym samym z transakcją. Tak to się robi:
public enum DbType {
MASTER,
REPLICA1,
}
public class DbContextHolder {
private static final ThreadLocal<DbType> contextHolder = new ThreadLocal<DbType>();
public static void setDbType(DbType dbType) {
if(dbType == null){
throw new NullPointerException();
}
contextHolder.set(dbType);
}
public static DbType getDbType() {
return (DbType) contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}
Jak widzisz, możesz również użyć enum jako klucza, a Spring zajmie się jego prawidłowym rozwiązaniem na podstawie nazwy. Powiązana konfiguracja i klucze DataSource mogą wyglądać tak:
....
<bean id="dataSource" class="website.fedulov.routing.RoutingDataSource">
<property name="targetDataSources">
<map key-type="com.sabienzia.routing.DbType">
<entry key="MASTER" value-ref="dataSourceMaster"/>
<entry key="REPLICA1" value-ref="dataSourceReplica"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSourceMaster"/>
</bean>
<bean id="dataSourceMaster" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.master.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
<bean id="dataSourceReplica" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.replica.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
W tym momencie może się okazać, że robisz coś takiego:
@Service
public class BookService {
private final BookRepository bookRepository;
private final Mapper mapper;
@Inject
public BookService(BookRepository bookRepository, Mapper mapper) {
this.bookRepository = bookRepository;
this.mapper = mapper;
}
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
...//other methods
Teraz możemy kontrolować, który DataSource będzie używany i przekazywać żądania według własnego uznania. Wygląda dobrze!
...czy to prawda? Po pierwsze, te statyczne wywołania metod do magicznego DbContextHolder naprawdę się wyróżniają. Wygląda na to, że nie należą do logiki biznesowej. A oni nie. Nie tylko nie informują o celu, ale wydają się kruche i podatne na błędy (może zapomnieć o wyczyszczeniu dbType). A co, jeśli zostanie zgłoszony wyjątek między setDbType a cleanDbType? Nie możemy tego po prostu zignorować. Musimy być absolutnie pewni, że zresetowaliśmy dbType, w przeciwnym razie wątek zwrócony do puli wątków może być w stanie „przerwanym”, próbując zapisać do repliki w następnym wywołaniu. Potrzebujemy tego:
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
try{
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
} catch (Exception e){
throw new RuntimeException(e);
} finally {
DbContextHolder.clearDbType(); // <----- make sure ThreadLocal setting is cleared
}
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
Ups >_< ! To zdecydowanie nie wygląda na coś, co chciałbym umieścić w każdej metodzie tylko do odczytu. Czy możemy zrobić lepiej? Oczywiście! Ten wzorzec „zrób coś na początku metody, a następnie zrób coś na końcu” powinien zabrzmieć. Aspekty na ratunek!
Niestety ten post jest już za długi, by poruszyć temat niestandardowych aspektów. Możesz śledzić szczegóły korzystania z aspektów, korzystając z tego link .



