Pracując z imionami osób i wykonując ich rozmyte wyszukiwania, zadziałało dla mnie stworzenie drugiej tabeli słów. Utwórz również trzecią tabelę, która jest tabelą przecięcia dla relacji wiele do wielu między tabelą zawierającą tekst a tabelą słów. Gdy do tabeli tekstu dodawany jest wiersz, dzielisz tekst na słowa i odpowiednio wypełniasz tabelę przecięcia, dodając w razie potrzeby nowe słowa do tabeli słów. Gdy ta struktura jest już na miejscu, możesz wykonać wyszukiwania nieco szybciej, ponieważ wystarczy wykonać funkcję damlev na tabeli unikalnych słów. Proste sprzężenie dostarcza tekst zawierający pasujące słowa. 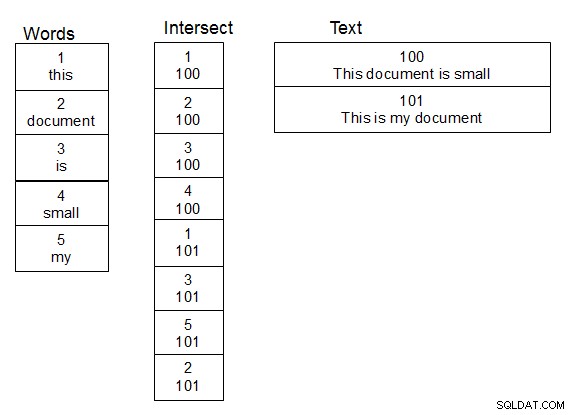
Zapytanie o dopasowanie pojedynczego słowa wyglądałoby mniej więcej tak:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
i dwa słowa wyglądałyby tak (poza czubkiem głowy, więc mogą nie być do końca poprawne):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Zaletą w tym przypadku, kosztem pewnej ilości miejsca w bazie danych, jest to, że wystarczy zastosować czasochłonną funkcję damlev do unikalnych słów, które prawdopodobnie będą liczyć tylko dziesiątki tysięcy, niezależnie od rozmiaru tabeli tekstu. Ma to znaczenie, ponieważ funkcja damlev UDF nie będzie używać indeksów — będzie skanować całą tabelę, na której jest zastosowana, w celu obliczenia wartości dla każdego wiersza. Skanowanie tylko unikalnych słów powinno być znacznie szybsze. Inną zaletą jest to, że damlev jest stosowany na poziomie słowa, o co prosisz. Kolejną zaletą jest to, że możesz rozszerzyć zapytanie, aby obsługiwało wyszukiwanie wielu słów, i możesz uszeregować wyniki, grupując pasujące przecinające się wiersze na TextId i oceniając liczbę dopasowań.