Przygotowałem próbkę (kliknij prawym przyciskiem myszy i wybierz zapisz link) na podstawie tego, co podałeś. Jedyny krok, co do którego czuję się trochę niepewny, to ostatnie dane wejściowe tabeli. Zasadniczo zapisuję dane łączenia w tabeli i pozwalam im się nie powieść, jeśli określona relacja już istnieje.
uwaga:
To rozwiązanie tak naprawdę nie spełnia zasady „Wszystkie podejścia powinny obejmować niektóre z walidacji i strategii wycofania w przypadku niepowodzenia wstawiania lub niemożności zachowania integralności referencyjnej”. kryteria, choć prawdopodobnie nie zawiedzie. Jeśli naprawdę chcesz skonfigurować coś złożonego, możemy, ale to zdecydowanie powinno pomóc w tych przekształceniach.

Przepływ danych według kroków
1. Zaczynamy od wczytania Twojego pliku. W moim przypadku przekonwertowałem go do CSV, ale karta też jest w porządku. 
2. Teraz wstawimy nazwiska pracowników do tabeli Pracownicy za pomocą combination lookup/update . Po wstawieniu do naszego strumienia danych dołączamy worker_id jako id i usuń EmployeeName ze strumienia danych.

3. Tutaj używamy tylko kroku Wybierz wartości, aby zmienić nazwę id pole do identyfikatora pracownika 
4. Wstaw tytuły stanowisk, tak jak zrobiliśmy to dla pracowników, i dołącz identyfikator tytułu do naszego strumienia danych, usuwając również JobLevelHistory ze strumienia danych.

5. Prosta zmiana nazwy id tytułu na id_tytułu (patrz krok 3) 
6. Wstaw biura, zdobądź identyfikatory, usuń OfficeHistory ze strumienia.

7. Prosta zmiana nazwy identyfikatora biura na office_id (patrz krok 3)

8. Skopiuj dane z ostatniego kroku do dwóch strumieni o wartościach employee_id,office_id i employee_id,title_id odpowiednio.

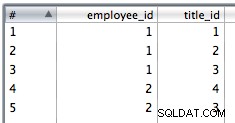
9. Użyj wstawiania tabeli, aby wstawić dane łączenia. Wybrałem tę opcję, aby ignorować błędy wstawiania, ponieważ mogą występować duplikaty, a ograniczenia PK spowodują, że niektóre wiersze zakończą się niepowodzeniem.
Tabele wyjściowe