Jest to możliwe, ale wymaga wielu wysiłków konserwacyjnych, Wyjaśnienie -
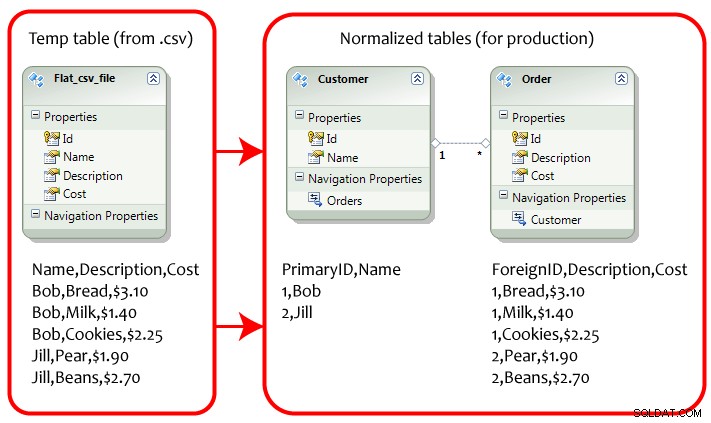
Pionowe skalowanie danych (jednoznaczne z normalizacją w bazach danych SQL) jest określany jako dzielenie kolumn danych na wiele tabel w celu zmniejszenia nadmiarowości miejsca. Przykład tabeli użytkowników -
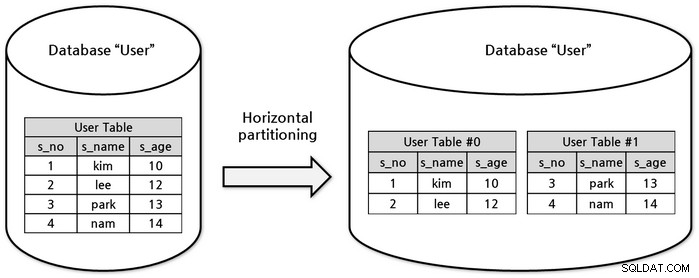
Skalowanie danych w poziomie (jednoznaczne z shardingiem) jest określany jako dzielenie wierszy na wiele tabel w celu skrócenia czasu potrzebnego na pobranie danych. Przykład tabeli użytkowników -
Kluczowym punktem, na który należy zwrócić uwagę, jest jak widzimy tabele w bazach danych SQL są znormalizowane do wielu tabel powiązanych danych. Aby dokonać fragmentacji danych z takiej tabeli na wielu komputerach, należałoby odpowiednio dokonać fragmentacji znormalizowanych danych powiązanych z fragmentami, co z kolei zwiększyłoby nakłady na konserwację. Jak w powyższym przykładzie bazy danych SQL,
Jeśli przeniesiesz kilka wierszy danych klientów na inną maszynę (nazywane shardingiem), będziesz musiał również przenieść powiązane dane zamówienia na tę samą maszynę, co byłoby kłopotliwym zadaniem w przypadku wielu powiązanych tabel.
Wygodne jest dzielenie baz danych NOSQL, ponieważ są one zgodne z płaską strukturą tabeli (dane są przechowywane w formie zagregowanej, a nie znormalizowanej).