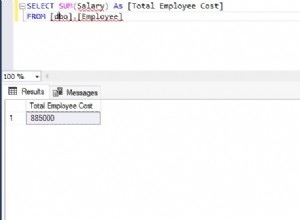
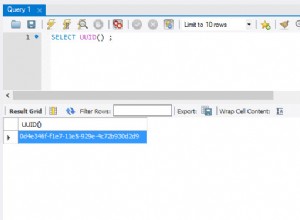
Dużo łatwiej jest przechowywać każdy rekord w całości niż przechowywać jego pliki różnicowe. Następnie, jeśli chcesz porównać dwie wersje, możesz wygenerować jedną w razie potrzeby, używając kodu PECL> Text_Diff biblioteka .
Lubię przechowywać wszystkie wersje rekordu w jednej tabeli i pobierać najnowszą za pomocą MAX(revision) , „bieżący” atrybut logiczny lub podobny. Inni wolą denormalizować i mieć tabelę lustrzaną, która przechowuje nieaktualne wersje.
Jeśli zamiast tego przechowujesz różnice, Twój schemat i algorytmy stają się znacznie bardziej złożone. Następnie musisz przechowywać co najmniej jedną „pełną” wersję i wiele wersji „diff”, a także zrekonstruować pełną wersję z zestawu różnic, gdy tylko potrzebujesz pełnej wersji. (W ten sposób SVN przechowuje rzeczy. Git przechowuje pełną kopię każdej wersji, a nie różnice.)
Czas programisty jest drogi, ale miejsce na dysku jest zwykle tanie. Zastanów się, czy przechowywanie każdej wersji w całości nie stanowi problemu.