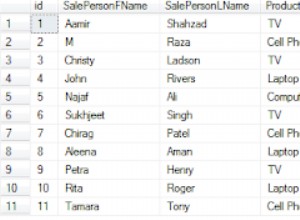
Różnica w wydajności jest prawdopodobnie ze względu na e.id_dernier_fichier będąc w indeksie używanym do JOIN, ale e.codega nie przebywanie w tym indeks.
Bez pełnej definicji obu tabel i wszystkich ich indeksów nie można stwierdzić na pewno. Pomogłoby również uwzględnienie dwóch PLANÓW WYJAŚNIENIA dla dwóch zapytań.
Na razie jednak mogę omówić kilka rzeczy...
Jeśli INDEKS jest CLASTRAROWANY (dotyczy to również KLUCZY PODSTAWOWYCH), dane są faktycznie fizycznie przechowywane w kolejności INDEKSU. Oznacza to, że wiedząc, że chcesz pozycję x w INDEKSIE również niejawność oznacza, że chcesz pozycję x w TABELI.
Jeśli jednak INDEKS nie jest zgrupowany, INDEKS zapewnia tylko wyszukiwanie. Skutecznie mówiąc pozycja x w INDEKSIE odpowiada pozycji y w TABELI.
Ważny jest tutaj dostęp do pól, które nie są określone w INDEKSIE. Oznacza to, że musisz przejść do TABELI, aby uzyskać dane. W przypadku CLOSTERED INDEX już tam jesteś, koszty znalezienia tego pola są dość niskie. Jeśli jednak INDEKS nie jest zgrupowany, faktycznie musisz ZŁĄCZYĆ TABELĘ z INDEKSEM, a następnie znaleźć interesujące Cię pole.
Notatka; Posiadanie złożonego indeksu na (id_dernier_fichier, codega) bardzo różni się od posiadania jednego indeksu tylko na (id_dernier_fichier) i oddzielny indeks tylko (codega) .
W przypadku Twojego zapytania, nie sądzę, abyś w ogóle musiał zmieniać kod. Ale możesz skorzystaj ze zmiany indeksów.
Wspominasz, że chcesz uzyskać dostęp do wielu pola. Umieszczenie wszystkich tych pól w indeksie złożonym prawdopodobnie nie jest najlepszym rozwiązaniem. Zamiast tego możesz utworzyć CLASTERED INDEX na (id_dernier_fichier) . Oznacza to, że po zlokalizowaniu *id_dernier_fichier* jesteś już we właściwym miejscu, aby uzyskać również wszystkie inne pola.
EDYTUJ Uwaga na temat MySQL i CLUSTERED INDEX
13.2.10.1. Indeksy klastrowe i dodatkowe
Każda tabela InnoDB ma specjalny indeks zwany indeksem klastrowym, w którym przechowywane są dane dla wierszy:
- Jeśli zdefiniujesz KLUCZ PODSTAWOWY w tabeli, InnoDB użyje go jako indeksu klastrowego.
- Jeśli nie zdefiniujesz klucza PRIMARY dla swojej tabeli, MySQL wybierze pierwszy indeks UNIQUE, który zawiera tylko kolumny NOT NULL jako klucz podstawowy, a InnoDB użyje go jako indeksu klastrowego.
- Jeśli tabela nie ma klucza PRIMARY lub odpowiedniego indeksu UNIQUE, InnoDB wewnętrznie generuje ukryty indeks klastrowy w kolumnie syntetycznej zawierającej wartości identyfikatora wiersza. Wiersze są uporządkowane według identyfikatora, który InnoDB przypisuje do wierszy w takiej tabeli. Identyfikator wiersza to 6-bajtowe pole, które zwiększa się monotonicznie w miarę wstawiania nowych wierszy. W ten sposób wiersze uporządkowane według identyfikatora wiersza są fizycznie w kolejności wstawiania.