„Ale na naszym serwerze programistycznym działało dobrze!”
Ile razy słyszałem, gdy tu i tam wystąpiły problemy z wydajnością zapytań SQL? Powiedziałem to sam kiedyś. Założyłem, że zapytanie uruchomione w mniej niż sekundę będzie działać dobrze na serwerach produkcyjnych. Ale myliłem się.
Czy możesz odnieść się do tego doświadczenia? Jeśli z jakiegoś powodu nadal jesteś na tej łodzi, ten post jest dla Ciebie. Zapewni to lepszą metrykę dostrajania wydajności zapytań SQL. Porozmawiamy o trzech najbardziej krytycznych danych w STATISTICS IO.
Jako przykład użyjemy przykładowej bazy danych AdventureWorks.
Zanim zaczniesz uruchamiać poniższe zapytania, włącz STATISTICS IO. Oto jak to zrobić w oknie zapytania:
USE AdventureWorks
GO
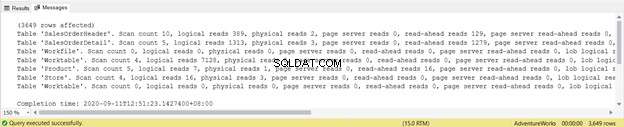
SET STATISTICS IO ONPo uruchomieniu zapytania z włączonym STATISTICS IO ON, pojawią się różne komunikaty. Możesz je zobaczyć w zakładce Wiadomości w oknie zapytania w SQL Server Management Studio (patrz Rysunek 1):
Teraz, gdy skończyliśmy z krótkim wprowadzeniem, zajmijmy się głębiej.
1. Wysokie odczyty logiczne
Pierwszy punkt na naszej liście to najczęstszy winowajca – wysokie odczyty logiczne.
Odczyty logiczne to liczba stron odczytanych z pamięci podręcznej danych. Strona ma rozmiar 8 KB. Z drugiej strony pamięć podręczna danych odnosi się do pamięci RAM używanej przez SQL Server.
Odczyty logiczne mają kluczowe znaczenie dla dostrajania wydajności. Ten czynnik określa, ile SQL Server potrzebuje do wygenerowania wymaganego zestawu wyników. Dlatego jedyną rzeczą do zapamiętania jest to, że im wyższe są odczyty logiczne, tym dłużej SQL Server musi działać. Oznacza to, że Twoje zapytanie będzie wolniejsze. Zmniejsz liczbę odczytów logicznych, a zwiększysz wydajność zapytań.
Ale po co używać odczytów logicznych zamiast czasu, który upłynął?
- Czas, który upłynął, zależy od innych czynności wykonywanych przez serwer, nie tylko od samego zapytania.
- Upływający czas może zmienić się z serwera deweloperskiego na serwer produkcyjny. Dzieje się tak, gdy oba serwery mają różne pojemności oraz konfiguracje sprzętu i oprogramowania.
Poleganie na upływającym czasie spowoduje, że powiesz:„Ale na naszym serwerze programistycznym działało dobrze!” prędzej czy później.
Po co używać odczytów logicznych zamiast odczytów fizycznych?
- Odczyty fizyczne to liczba stron odczytanych z dysków do pamięci podręcznej danych (w pamięci). Gdy strony potrzebne w zapytaniu znajdą się w pamięci podręcznej danych, nie ma potrzeby ponownego odczytywania ich z dysków.
- Gdy to samo zapytanie zostanie ponownie uruchomione, fizyczne odczyty wyniosą zero.
Odczyty logiczne są logicznym wyborem do dostrajania wydajności zapytań SQL.
Aby zobaczyć to w akcji, przejdźmy do przykładu.
Przykład odczytów logicznych
Załóżmy, że musisz uzyskać listę klientów z zamówieniami wysłanymi 11 lipca 2011 r. Poniżej przedstawiasz dość proste zapytanie:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'To proste. To zapytanie będzie miało następujący wynik:

Następnie sprawdzasz wynik STATISTICS IO tego zapytania:

Dane wyjściowe przedstawiają odczyty logiczne każdej z czterech tabel użytych w zapytaniu. W sumie suma odczytów logicznych wynosi 729. Możesz również zobaczyć odczyty fizyczne z łączną sumą 21. Spróbuj jednak ponownie uruchomić zapytanie, a wyniesie zero.
Przyjrzyj się logicznym odczytom SalesOrderHeader . Zastanawiasz się, dlaczego ma 689 logicznych odczytów? Być może myślałeś o sprawdzeniu poniższego planu wykonania zapytania:
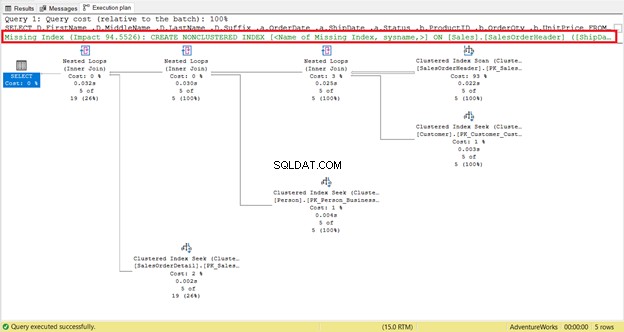
Po pierwsze, istnieje skanowanie indeksu, które miało miejsce w SalesOrderHeader z 93% kosztem. Co się może dziać? Załóżmy, że sprawdziłeś jego właściwości:
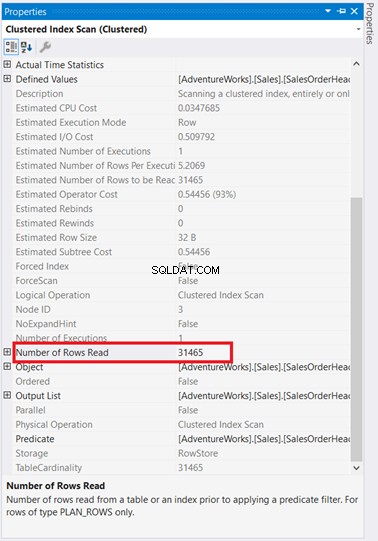
Łał! 31 465 wierszy przeczytanych, a zwróconych tylko 5 wierszy? To absurd!
Zmniejszanie liczby odczytów logicznych
Nie jest tak trudno zmniejszyć te 31 465 przeczytanych wierszy. SQL Server już dał nam wskazówkę. Przejdź do następujących czynności:
KROK 1:Postępuj zgodnie z zaleceniami SQL Server i dodaj brakujący indeks
Czy zauważyłeś brakującą rekomendację indeksu w planie realizacji (Rysunek 4)? Czy to rozwiąże problem?
Jest jeden sposób, aby się tego dowiedzieć:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Uruchom ponownie zapytanie i zobacz zmiany w odczytach logicznych STATISTICS IO.

Jak widać w STATISTICS IO (Rysunek 6), nastąpił ogromny spadek odczytów logicznych z 689 do 17. Nowe ogólne odczyty logiczne to 57, co stanowi znaczną poprawę w porównaniu z 729 odczytami logicznymi. Ale dla pewności ponownie sprawdźmy plan wykonania.
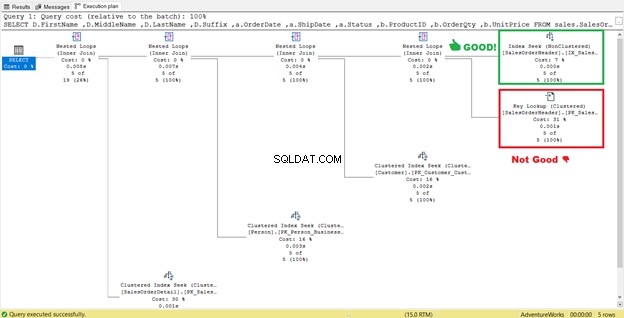
Wygląda na to, że plan uległ ulepszeniu, powodując zmniejszenie odczytów logicznych. Skanowanie indeksu jest teraz wyszukiwaniem indeksu. SQL Server nie będzie już musiał sprawdzać wiersz po wierszu, aby uzyskać rekordy z Shipdate=’07/11/2011′ . Ale coś wciąż czai się w tym planie i nie jest w porządku.
Potrzebujesz kroku 2.
KROK 2:Zmień indeks i dodaj do uwzględnionych kolumn:OrderDate, Status i CustomerID
Czy widzisz ten operator Key Lookup w planie wykonania (Rysunek 7)? Oznacza to, że utworzony indeks nieklastrowy nie wystarczy – procesor zapytań musi ponownie użyć indeksu klastrowego.
Sprawdźmy jego właściwości.
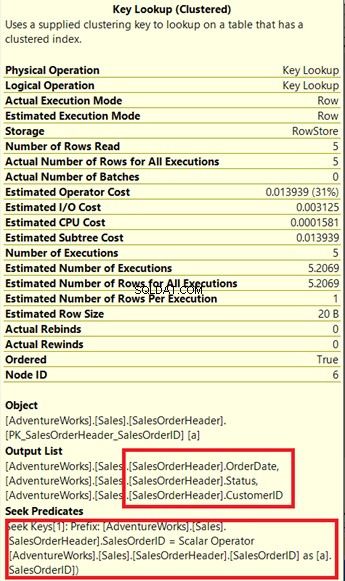
Zwróć uwagę na dołączone pole pod Listą wyników . Zdarza się, że potrzebujemy DataZamówienia , Stan i Identyfikator klienta w zestawie wyników. Aby uzyskać te wartości, procesor zapytań użył indeksu klastrowego (patrz Predykaty wyszukiwania ), aby dostać się do stołu.
Musimy usunąć to Key Lookup. Rozwiązaniem jest uwzględnienie DataZamówienia , Stan i Identyfikator klienta kolumny do utworzonego wcześniej indeksu.
- Kliknij prawym przyciskiem myszy IX_SalesOrderHeader_ShipDate w SSMS.
- Wybierz Właściwości .
- Kliknij Kolumny uwzględnione zakładka.
- Dodaj datę zamówienia , Stan i Identyfikator klienta .
- Kliknij OK .
Po ponownym utworzeniu indeksu uruchom ponownie zapytanie. Czy spowoduje to usunięcie Key Lookup? i zmniejszyć logiczne odczyty?

Zadziałało! Od 17 logicznych odczytów do 2 (Rysunek 9).
Oraz Wyszukiwanie klucza ?
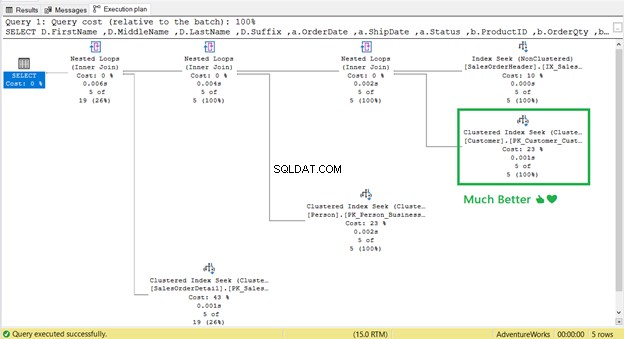
Odeszło! Przeszukiwanie indeksu klastrowego zastąpił Key Lookup.
Na wynos
Czego więc się nauczyliśmy?
Jednym z podstawowych sposobów ograniczenia odczytów logicznych i poprawy wydajności zapytań SQL jest utworzenie odpowiedniego indeksu. Ale jest pewien haczyk. W naszym przykładzie zmniejszyło to odczyty logiczne. Czasami będzie odwrotnie. Może to również wpłynąć na wydajność innych powiązanych zapytań.
Dlatego po utworzeniu indeksu zawsze sprawdzaj STATISTICS IO i plan wykonania.
2. Logiczne odczyty wysokiego lobu
Jest bardzo podobny do punktu 1, ale dotyczy typów danych tekst , ntekst , obraz , warcha (maks. ), nvarchar (maks. ), zmienna (maks. ) lub sklep z kolumnami strony indeksu.
Odwołajmy się do przykładu:generowanie logicznych odczytów lob.
Przykład logicznych odczytów Lob
Załóżmy, że chcesz wyświetlić produkt z jego ceną, kolorem, miniaturą i większym obrazem na stronie internetowej. W ten sposób pojawia się wstępne zapytanie, jak pokazano poniżej:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorNastępnie uruchamiasz go i widzisz wynik taki jak ten poniżej:

Jako, że jesteś takim facetem o wysokich osiągach (lub gal), natychmiast sprawdzasz STATISTICS IO. Oto on:

Czujesz jak brud w twoich oczach. 665 logicznych odczytów lobów? Nie możesz tego zaakceptować. Nie wspominając o 194 logicznych odczytach, każdy z ProductPhoto i ProductPhoto tabele. Naprawdę uważasz, że to zapytanie wymaga pewnych zmian.
Zmniejszanie logicznych odczytów lobby
Poprzednie zapytanie zwróciło 97 wierszy. Wszystkie 97 rowerów. Czy uważasz, że dobrze jest wyświetlać to na stronie internetowej?
Indeks może pomóc, ale dlaczego najpierw nie uprościć zapytania? W ten sposób możesz decydować o tym, co zwróci SQL Server. Możesz zmniejszyć logiczne odczyty lob.
- Dodaj filtr dla podkategorii produktu i pozwól klientowi dokonać wyboru. Następnie uwzględnij to w klauzuli WHERE.
- Usuń podkategorię produktu kolumnę, ponieważ dodasz filtr dla podkategorii produktu.
- Usuń Duże zdjęcie kolumna. Zapytaj o to, gdy użytkownik wybierze określony produkt.
- Użyj stronicowania. Klient nie będzie mógł wyświetlić wszystkich 97 rowerów jednocześnie.
Na podstawie tych operacji opisanych powyżej zmieniamy zapytanie w następujący sposób:
- Usuń podkategorię produktu i Duże zdjęcie kolumny ze zbioru wyników.
- Użyj opcji OFFSET i FETCH, aby uwzględnić stronicowanie w zapytaniu. Zapytaj tylko 10 produktów na raz.
- Dodaj ID podkategorii produktu w klauzuli WHERE na podstawie wyboru klienta.
- Usuń podkategorię produktu kolumna w klauzuli ORDER BY.
Zapytanie będzie teraz podobne do tego:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Czy po wprowadzeniu zmian odczyty logiczne lobów ulegną poprawie? STATISTICS IO teraz zgłasza:

Zdjęcie produktu tabela ma teraz 0 logicznych odczytów loba — od 665 logicznych odczytów loba do żadnego. To jest pewna poprawa.
Na wynos
Jednym ze sposobów zmniejszenia logicznych odczytów lob jest przepisanie zapytania w celu jego uproszczenia.
Usuń niepotrzebne kolumny i zmniejsz zwracane wiersze do najmniej wymaganej. W razie potrzeby użyj funkcji OFFSET i FETCH do stronicowania.
Aby upewnić się, że zmiany w zapytaniu poprawiły odczyty logiczne lob i wydajność zapytań SQL, zawsze sprawdzaj STATISTICS IO.
3. Wysokie odczyty logiczne tabeli roboczej/pliku roboczego
Wreszcie, to logiczne odczyty Worktable i Plik roboczy . Ale czym są te stoły? Dlaczego pojawiają się, gdy nie używasz ich w zapytaniu?
Posiadanie Stół roboczy i Plik roboczy pojawiające się w STATISTICS IO oznacza, że SQL Server potrzebuje dużo więcej pracy, aby uzyskać pożądane rezultaty. Wykorzystuje tabele tymczasowe w tempdb , czyli Stoły robocze i Pliki robocze . Niekoniecznie szkodliwe jest posiadanie ich na wyjściu STATISTICS IO, o ile odczyty logiczne wynoszą zero i nie powoduje to problemów dla serwera.
Te tabele mogą pojawiać się między innymi, gdy występuje ORDER BY, GROUP BY, CROSS JOIN lub DISTINCT.
Przykład odczytów logicznych z tabeli roboczej/pliku roboczego
Załóżmy, że musisz wysłać zapytanie do wszystkich sklepów bez sprzedaży niektórych produktów.
Początkowo wymyślasz następujące rzeczy:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDTo zapytanie zwróciło 3649 wierszy:
Sprawdźmy, co mówi IO STATYSTYKI:

Warto zauważyć, że Stół roboczy odczyty logiczne to 7128. Ogólny odczyt logiczny to 8853. Jeśli sprawdzisz plan wykonania, zobaczysz wiele paralelizmów, dopasowań haszujących, buforowania i skanowania indeksów.
Zmniejszanie logicznych odczytów z tabeli roboczej/pliku roboczego
Nie mogłem skonstruować pojedynczej instrukcji SELECT z satysfakcjonującym wynikiem. Zatem jedynym wyjściem jest rozbicie instrukcji SELECT na wiele zapytań. Zobacz poniżej:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsJest o kilka wierszy dłuższy i używa tabel tymczasowych. Zobaczmy teraz, co ujawnia IO STATISTICS:
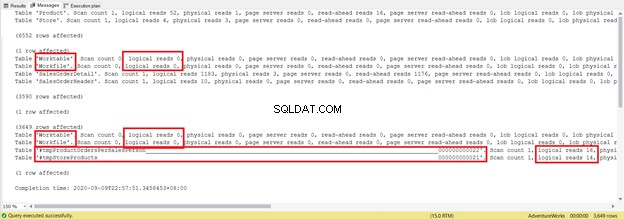
Staraj się nie skupiać na długości tego statystycznego raportu – to tylko frustrujące. Zamiast tego dodaj logiczne odczyty z każdej tabeli.
Łącznie 1279 oznacza znaczny spadek, ponieważ było to 8853 logicznych odczytów z pojedynczej instrukcji SELECT.
Nie dodaliśmy żadnego indeksu do tabel tymczasowych. Możesz go potrzebować, jeśli do SalesOrderHeader zostanie dodanych dużo więcej rekordów i Szczegóły zamówienia sprzedaży . Ale rozumiesz.
Na wynos
Czasami wyrażenie 1 SELECT wydaje się dobre. Jednak za kulisami jest odwrotnie. Stoły robocze i Pliki robocze z wysokimi odczytami logicznymi opóźniają wydajność zapytań SQL.
Jeśli nie możesz wymyślić innego sposobu na zrekonstruowanie zapytania, a indeksy są bezużyteczne, wypróbuj podejście „dziel i rządź”. Stoły robocze i Pliki robocze może nadal pojawiać się na karcie Wiadomość programu SSMS, ale odczyty logiczne będą wynosić zero. Dlatego ogólny wynik będzie mniej logiczny.
Konkluzja wydajności zapytań SQL i IO STATISTICS
O co chodzi z tymi 3 paskudnymi statystykami I/O?
Różnica w wydajności zapytań SQL będzie jak w dzień iw nocy, jeśli zwrócisz uwagę na te liczby i je zmniejszysz. Przedstawiliśmy tylko kilka sposobów na ograniczenie odczytów logicznych, takich jak:
- tworzenie odpowiednich indeksów;
- uproszczenie zapytań – usunięcie zbędnych kolumn i zminimalizowanie zestawu wyników;
- podział zapytania na wiele zapytań.
Jest to bardziej jak aktualizowanie statystyk, defragmentowanie indeksów i ustawianie właściwego FILLFACTORa. Czy możesz dodać więcej do tego w sekcji komentarzy?
Jeśli podoba Ci się ten post, udostępnij go w swoich ulubionych mediach społecznościowych.