Czy Twój wybór typów danych serwera SQL i ich rozmiarów ma znaczenie?
Odpowiedź leży w otrzymanym wyniku. Czy Twoja baza danych rozwinęła się w krótkim czasie? Czy Twoje zapytania są wolne? Czy miałeś złe wyniki? A co z błędami w czasie wykonywania podczas wstawiania i aktualizacji?
Nie jest to aż tak zniechęcające zadanie, jeśli wiesz, co robisz. Dzisiaj poznasz 5 najgorszych wyborów, jakich można dokonać z tymi typami danych. Jeśli stały się twoim nawykiem, jest to rzecz, którą powinniśmy naprawić ze względu na ciebie i twoich użytkowników.
Wiele typów danych w SQL, dużo zamieszania
Kiedy po raz pierwszy dowiedziałem się o typach danych SQL Server, wybór był przytłaczający. Wszystkie typy są pomieszane w mojej głowie, jak ta chmura słów na rysunku 1:

Możemy jednak podzielić go na kategorie:
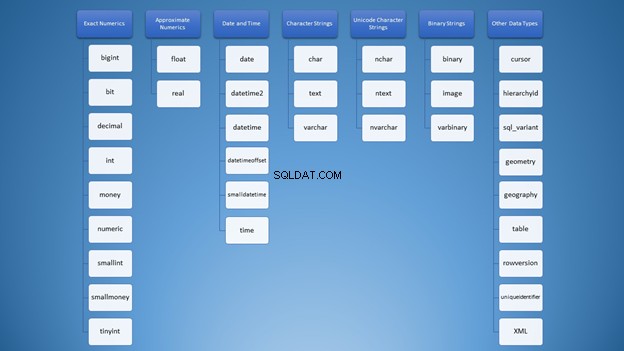
Mimo to, używając ciągów, masz wiele opcji, które mogą prowadzić do niewłaściwego użycia. Na początku myślałem, że varchar i nvarchar były takie same. Poza tym oba są typami łańcuchów znaków. Używanie liczb nie różni się. Jako programiści musimy wiedzieć, jakiego typu użyć w różnych sytuacjach.
Ale możesz się zastanawiać, jaka jest najgorsza rzecz, jaka może się wydarzyć, jeśli dokonam złego wyboru? Pozwól, że ci powiem!
1. Wybór niewłaściwych typów danych SQL
Ten element użyje ciągów i liczb całkowitych do udowodnienia tego.
Używanie niewłaściwego typu danych SQL ciągu znaków
Najpierw wróćmy do strun. Jest coś takiego, jak ciągi Unicode i inne niż Unicode. Oba mają różne rozmiary pamięci. Często definiujesz to w kolumnach i deklaracjach zmiennych.
Składnia to varchar (n)/znak (n) lub nvarchar (n)/nchar (n) gdzie n to rozmiar.
Pamiętaj, że n nie jest liczbą znaków, ale liczbą bajtów. To powszechne nieporozumienie, które pojawia się, ponieważ w varchar , liczba znaków jest taka sama jak rozmiar w bajtach. Ale nie w nvarchar .
Aby to udowodnić, stwórzmy 2 tabele i umieść w nich trochę danych.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
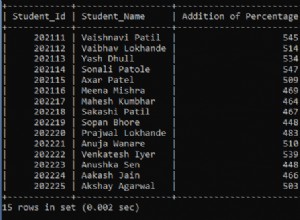
Teraz sprawdźmy ich rozmiary wierszy za pomocą DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Rysunek 3 pokazuje, że różnica jest dwojaka. Sprawdź to poniżej.
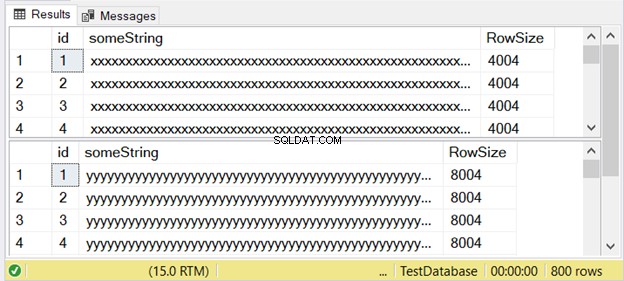
Zwróć uwagę na drugi zestaw wyników z rozmiarem wiersza 8004. Używa on nvarchar typ danych. Jest również prawie dwa razy większy niż rozmiar wiersza pierwszego zestawu wyników. A to wykorzystuje varchar typ danych.
Widzisz wpływ na pamięć masową i we/wy. Rysunek 4 pokazuje logiczne odczyty 2 zapytań.
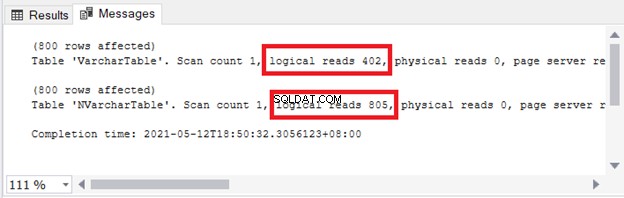
Widzieć? Odczyty logiczne są również dwojakie przy użyciu nvarchar w porównaniu do varchara .
Nie można więc po prostu używać każdego z nich zamiennie. Jeśli potrzebujesz przechowywać wielojęzyczne znaków, użyj nvarchar . W przeciwnym razie użyj varchar .
Oznacza to, że jeśli używasz nvarchar tylko dla znaków jednobajtowych (takich jak angielskie) rozmiar pamięci jest wyższy . Wydajność zapytań jest również wolniejsza przy wyższych odczytach logicznych.
W SQL Server 2019 (i nowszych) możesz przechowywać pełny zakres danych znaków Unicode za pomocą varchar lub znak z dowolną opcją sortowania UTF-8.
Używanie nieprawidłowego liczbowego typu danych SQL
Ta sama koncepcja dotyczy bigint a int – ich rozmiary mogą oznaczać noc i dzień. Jak nvarchar i varchar , duży jest dwukrotnie większy od int (8 bajtów dla duży .) i 4 bajty dla int ).
Możliwy jest jednak inny problem. Jeśli nie masz nic przeciwko ich rozmiarom, mogą wystąpić błędy. Jeśli używasz int kolumny i zapisz liczbę większą niż 2147483647, wystąpi przepełnienie arytmetyczne:
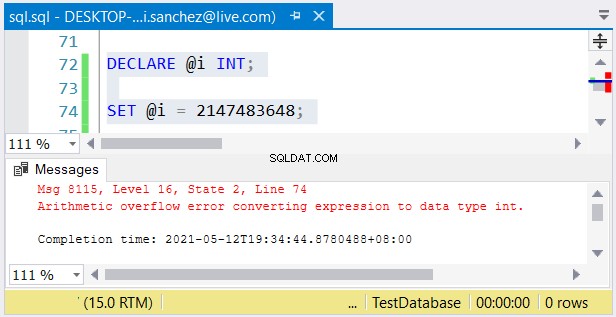
Wybierając typy liczb całkowitych, upewnij się, że dane o maksymalnej wartości będą pasować . Na przykład możesz projektować tabelę z danymi historycznymi. Planujesz użyć liczb całkowitych jako wartości klucza podstawowego. Czy uważasz, że nie osiągnie 2 147 483 647 wierszy? Następnie użyj int zamiast duży jako typ kolumny klucza podstawowego.
Najgorsza rzecz, jaka może się wydarzyć
Wybranie niewłaściwych typów danych może wpłynąć na wydajność zapytań lub spowodować błędy w czasie wykonywania. Dlatego wybierz typ danych odpowiedni dla danych.
2. Tworzenie dużych wierszy w tabeli przy użyciu typów Big Data dla SQL
Nasz następny punkt jest powiązany z pierwszym, ale jeszcze bardziej rozszerzy ten punkt o przykłady. Ma też coś wspólnego ze stronami i dużymi varcharem lub nvarchar kolumny.
Co jest ze stronami i rozmiarami wierszy?
Koncepcję stron w SQL Server można porównać ze stronami spiralnego notatnika. Każda strona w notatniku ma ten sam rozmiar fizyczny. Piszesz słowa i rysujesz na nich obrazki. Jeśli strona nie wystarczy na zestaw akapitów i obrazów, kontynuuj na następnej stronie. Czasami też wyrywasz stronę i zaczynasz od nowa.
Podobnie dane tabel, wpisy indeksu i obrazy w SQL Server są przechowywane na stronach.
Strona ma ten sam rozmiar 8 KB. Jeśli wiersz danych jest bardzo duży, nie zmieści się na stronie o wielkości 8 KB. Co najmniej jedna kolumna zostanie zapisana na innej stronie pod jednostką alokacji ROW_OVERFLOW_DATA. Zawiera wskaźnik do oryginalnego wiersza na stronie pod jednostką alokacji IN_ROW_DATA.
Na tej podstawie nie można po prostu zmieścić wielu kolumn w tabeli podczas projektowania bazy danych. Będą konsekwencje dla I/O. Ponadto jeśli dużo zapytasz o te dane dotyczące przepełnienia wierszy, czas wykonania jest wolniejszy . To może być koszmar.
Problem pojawia się, gdy zmaksymalizujesz wszystkie kolumny o różnych rozmiarach. Następnie dane przejdą na następną stronę pod ROW_OVERFLOW_DATA. zaktualizuj kolumny danymi o mniejszych rozmiarach i należy je usunąć na tej stronie. Nowy mniejszy wiersz danych zostanie zapisany na stronie pod IN_ROW_DATA wraz z innymi kolumnami. Wyobraź sobie zaangażowane we/wy.
Przykład dużego wiersza
Przygotujmy najpierw nasze dane. Użyjemy typów danych typu ciąg znaków o dużych rozmiarach.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Pobieranie rozmiaru wiersza
Na podstawie wygenerowanych danych sprawdźmy ich rozmiary wierszy na podstawie DŁUGOŚCI DANYCH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Pierwsze 300 rekordów zmieści się na stronach IN_ROW_DATA, ponieważ każdy wiersz ma mniej niż 8060 bajtów lub 8 KB. Ale ostatnie 100 rzędów jest za duże. Sprawdź zestaw wyników na rysunku 6.
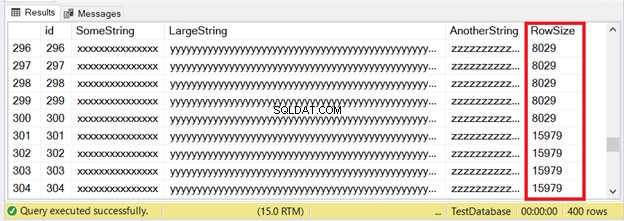
Widzisz część pierwszych 300 rzędów. Następne 100 przekracza limit rozmiaru strony. Skąd wiemy, że ostatnie 100 wierszy znajduje się w jednostce alokacji ROW_OVERFLOW_DATA?
Sprawdzanie ROW_OVERFLOW_DATA
Użyjemy sys.dm_db_index_physical_stats . Zwraca informacje o stronie dotyczące wpisów w tabeli i indeksie.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Zestaw wyników znajduje się na rysunku 7.

Tu jest. Rysunek 7 pokazuje 100 wierszy pod ROW_OVERFLOW_DATA. Jest to zgodne z rysunkiem 6, gdy istnieją duże rzędy zaczynające się od rzędów od 301 do 400.
Następnym pytaniem jest, ile odczytów logicznych otrzymujemy, gdy wysyłamy zapytanie do tych 100 wierszy. Spróbujmy.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Widzimy 102 odczyty logiczne i 100 odczytów logicznych lob w LargeTable . Na razie zostaw te liczby – porównamy je później.
Zobaczmy teraz, co się stanie, jeśli zaktualizujemy 100 wierszy mniejszymi danymi.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Ta instrukcja aktualizacji używała tych samych odczytów logicznych i odczytów logicznych lobów, co na rysunku 8. Z tego wiemy, że wydarzyło się coś większego, ponieważ odczyty logiczne lobów wynoszą 100 stron.
Ale dla pewności sprawdźmy to za pomocą sys.dm_db_index_physical_stats tak jak wcześniej. Rysunek 9 pokazuje wynik:

Odszedł! Strony i wiersze z ROW_OVERFLOW_DATA zmieniły się na zero po zaktualizowaniu 100 wierszy mniejszymi danymi. Teraz wiemy, że przesunięcie danych z ROW_OVERFLOW_DATA do IN_ROW_DATA ma miejsce, gdy zmniejsza się duże wiersze. Wyobraź sobie, że zdarza się to często w przypadku tysięcy, a nawet milionów rekordów. Szalone, prawda?
Na rysunku 8 widzieliśmy 100 logicznych odczytów lobów. Teraz zobacz Rysunek 10 po ponownym uruchomieniu zapytania:

Stało się zero!
Najgorsza rzecz, jaka może się wydarzyć
Niska wydajność zapytań jest produktem ubocznym danych przepełnienia wierszy. Rozważ przeniesienie dużych kolumn do innej tabeli, aby tego uniknąć. Lub, jeśli to możliwe, zmniejsz rozmiar varchar lub nvarchar kolumna.
3. Na ślepo za pomocą niejawnej konwersji
SQL nie pozwala nam na użycie danych bez określenia typu. Ale to wybacza, jeśli dokonamy złego wyboru. Próbuje przekonwertować wartość na oczekiwany typ, ale z karą. Może się to zdarzyć w klauzuli WHERE lub JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Numer karty kolumna nie jest typem liczbowym. To nvarchar . Tak więc pierwszy SELECT spowoduje niejawną konwersję. Jednak oba będą działać dobrze i dadzą ten sam zestaw wyników.
Sprawdźmy plan wykonania na rysunku 11.
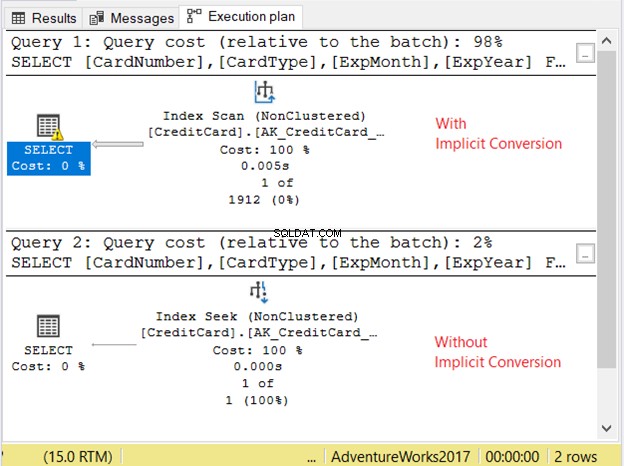
2 zapytania przebiegły bardzo szybko. Na rysunku 11 to zero sekund. Ale spójrz na 2 plany. Ten z niejawną konwersją miał skanowanie indeksu. Jest też ikona ostrzegawcza i gruba strzałka wskazująca na operator SELECT. Mówi nam, że jest źle.
Ale to nie koniec. Jeśli najedziesz kursorem myszy na operator SELECT, zobaczysz coś jeszcze:

Ikona ostrzeżenia w operatorze SELECT dotyczy niejawnej konwersji. Ale jak duży jest wpływ? Sprawdźmy odczyty logiczne.
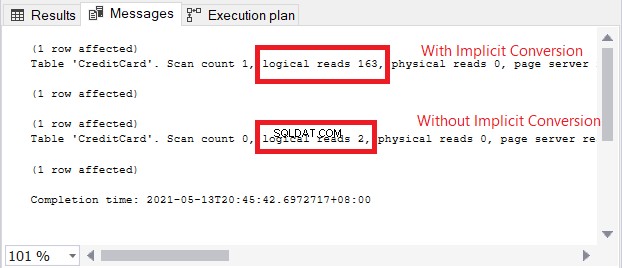
Porównanie odczytów logicznych na rysunku 13 jest jak niebo i ziemia. W zapytaniu o informacje o karcie kredytowej niejawna konwersja spowodowała ponad stukrotne odczyty logiczne. Bardzo źle!
Najgorsza rzecz, jaka może się wydarzyć
Jeśli niejawna konwersja spowodowała wysokie odczyty logiczne i zły plan, spodziewaj się niskiej wydajności zapytań w dużych zestawach wyników. Aby tego uniknąć, użyj dokładnego typu danych w klauzuli WHERE i JOIN w dopasowaniu do porównywanych kolumn.
4. Korzystanie z przybliżonych liczb i zaokrąglanie
Sprawdź ponownie rysunek 2. Typy danych serwera SQL należące do przybliżonych liczb to float i prawdziwe . Kolumny i utworzone z nich zmienne przechowują bliskie przybliżenie wartości liczbowej. Jeśli planujesz zaokrąglić te liczby w górę lub w dół, możesz spotkać wielką niespodziankę. Mam artykuł, który szczegółowo omówił to tutaj. Zobacz, jak 1 + 1 daje 3 i jak radzić sobie z zaokrąglaniem liczb.
Najgorsza rzecz, jaka może się wydarzyć
Zaokrąglanie liczby zmiennoprzecinkowej lub prawdziwe może mieć szalone wyniki. Jeśli chcesz uzyskać dokładne wartości po zaokrągleniu, użyj dziesiętnego lub liczbowo zamiast tego.
5. Ustawianie typów danych ciągu o stałej wielkości na NULL
Zwróćmy naszą uwagę na typy danych o stałym rozmiarze, takie jak char i nchar . Oprócz spacji dopełnionych, ustawienie ich na NULL nadal będzie miało rozmiar pamięci równy rozmiarowi znaku kolumna. Tak więc ustawienie znaku (500) kolumna na NULL będzie miała rozmiar 500, a nie zero lub 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
W powyższym kodzie dane są maksymalizowane na podstawie rozmiaru znaku i varchar kolumny. Sprawdzanie rozmiaru wiersza za pomocą DATALENGTH pokaże również sumę rozmiarów każdej kolumny. Teraz ustawmy kolumny na NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Następnie odpytujemy wiersze za pomocą DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Jak myślisz, jakie będą rozmiary danych w każdej kolumnie? Sprawdź rysunek 14.
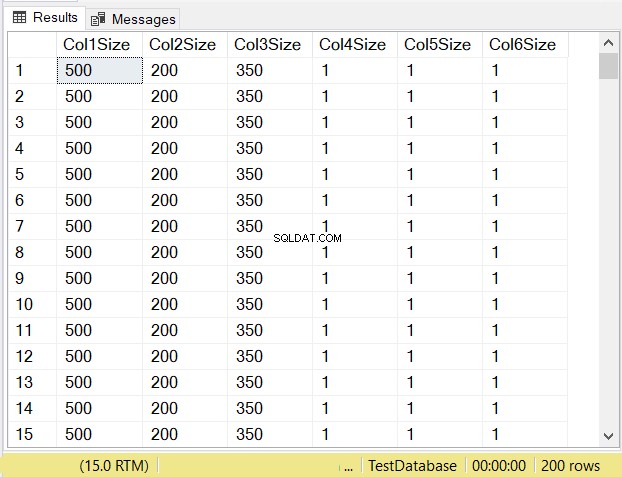
Spójrz na rozmiary kolumn w pierwszych 3 kolumnach. Następnie porównaj je z powyższym kodem podczas tworzenia tabeli. Rozmiar danych kolumn NULL jest równy rozmiarowi kolumny. Tymczasem varchar kolumny, gdy NULL mają rozmiar danych równy 1.
Najgorsza rzecz, jaka może się wydarzyć
Podczas projektowania tabel wartość nullable char kolumny, gdy są ustawione na NULL, będą nadal miały ten sam rozmiar pamięci. Zużywają również te same strony i pamięć RAM. Jeśli nie wypełniasz całej kolumny znakami, rozważ użycie varchar zamiast tego.
Co dalej?
Czy zatem Twoje wybory dotyczące typów danych serwera SQL i ich rozmiarów mają znaczenie? Przedstawione tutaj punkty powinny wystarczyć, aby wyrazić rację. Co więc możesz teraz zrobić?
- Poświęć czas na przejrzenie obsługiwanej bazy danych. Zacznij od najłatwiejszego, jeśli masz ich kilka na talerzu. I tak, znajdź czas, a nie znajdź czas. W naszej branży znalezienie czasu jest prawie niemożliwe.
- Przejrzyj tabele, procedury składowane i wszystko, co dotyczy typów danych. Zwróć uwagę na pozytywny wpływ przy identyfikowaniu problemów. Będziesz tego potrzebować, gdy twój szef zapyta, dlaczego musisz nad tym pracować.
- Zaplanuj zaatakowanie każdego z problematycznych obszarów. Postępuj zgodnie z metodami lub politykami, które Twoja firma ma w radzeniu sobie z problemami.
- Gdy problemy znikną, świętuj.
Brzmi łatwo, ale wszyscy wiemy, że tak nie jest. Wiemy również, że na końcu podróży jest jasna strona. Dlatego nazywa się je problemami – bo jest rozwiązanie. Więc rozchmurz się.
Czy masz coś jeszcze do dodania na ten temat? Daj nam znać w sekcji Komentarze. A jeśli ten post dał ci świetny pomysł, udostępnij go na swoich ulubionych platformach społecznościowych.