IRI zapewnia teraz również funkcje wyszukiwania rozmytego, zarówno w bezpłatnej bazie danych, jak i narzędziach do profilowania plików płaskich, a także jako dostępne biblioteki funkcji polowych w IRI CoSort, FieldShield i Vorality w celu poprawy jakości danych, bezpieczeństwa i możliwości MDM. To pierwszy z serii artykułów poświęconych rozwiązaniom wyszukiwania rozmytego IRI, obejmującym ich zastosowanie do poprawy jakości danych.
Wprowadzenie
Wiarygodność lub wiarygodność danych jednego z dużych słów „V” (wraz z objętością, różnorodnością, szybkością i wartością), o których mówi IRI i wsp. w kontekście zarządzania danymi i informacjami w przedsiębiorstwie. Ogólnie rzecz biorąc, IRI definiuje wątpliwe dane jako posiadające jeden lub więcej z tych atrybutów:
- Niska jakość, ponieważ jest niespójna, niedokładna lub niekompletna
- Niejednoznaczne (myśl o MDM), nieprecyzyjne (nieustrukturyzowane) lub zwodnicze (media społecznościowe)
- Skobiety (pytanie ankietowe), głośne (nadmierne lub zanieczyszczone) lub nienormalne (odstające)
- Nieważne z jakiegokolwiek innego powodu (czy dane są prawidłowe i dokładne zgodnie z ich przeznaczeniem?)
- Niebezpieczne – czy zawiera informacje umożliwiające identyfikację osoby lub tajemnice i czy jest to odpowiednio zamaskowane, odwracalne itp.?
Ten artykuł skupia się tylko na nowych rozwiązaniach wyszukiwania rozmytego pierwszego problemu, jakim jest jakość danych. Inne artykuły na tym blogu omawiają, w jaki sposób oprogramowanie IRI rozwiązuje pozostałe cztery problemy z prawdziwością; poproś o pomoc w ich znalezieniu, jeśli nie możesz.
Informacje o wyszukiwaniu rozmytym
Wyszukiwanie rozmyte znajduje słowa lub wyrażenia (wartości), które są podobne do innych słów lub wyrażeń (wartości), ale niekoniecznie identyczne. Ten typ wyszukiwania ma wiele zastosowań, takich jak znajdowanie błędów sekwencji, błędów ortograficznych, transponowanych znaków i innych, które omówimy później.
Wyszukiwanie rozmyte przybliżonych słów lub fraz może pomóc w znalezieniu danych, które mogą być duplikatami wcześniej zapisanych danych. Jednak dane wprowadzone przez użytkownika lub autokorekta mogły w jakiś sposób zmienić dane, tak aby zapisy wydawały się niezależne.
W dalszej części artykułu omówimy cztery funkcje wyszukiwania rozmytego obsługiwane przez IRI, jak ich używać do przeszukiwania danych i zwracania tych rekordów w przybliżeniu z wartością wyszukiwania.
1. Levenshtein
Algorytm Levenshteina działa, biorąc dwa słowa lub frazy i zliczając, ile kroków edycyjnych trzeba wykonać, aby zamienić jedno słowo lub frazę w drugie. Im mniej kroków wykona, tym większe prawdopodobieństwo, że słowo lub fraza będzie pasować. Kroki, jakie może wykonać funkcja Levenshtein, to:
- Wstawienie znaku do słowa lub wyrażenia
- Usunięcie znaku ze słowa lub wyrażenia
- Zastąpienie jednego znaku w słowie lub wyrażeniu innym
Poniżej znajduje się program CoSort SortCL (skrypt zadania) demonstrujący, jak korzystać z funkcji wyszukiwania rozmytego Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Istnieją dwie części, których należy użyć do uzyskania pożądanego wyniku.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Ta linia wywołuje funkcję fs_levenshtein i przechowuje wynik w polu FS_RESULT. Funkcja przyjmuje dwa parametry wejściowe:
- Pole do uruchomienia wyszukiwania rozmytego (w naszym przykładzie NAZWA)
- Ciąg, z którym będzie porównywane pole wejściowe („Barney Oakley” w naszym przykładzie).
/INCLUDE WHERE FS_RESULT GT 50
Ta linia porównuje pole FS_RESULT i sprawdza, czy jest większe niż 50, a następnie wyprowadzane są tylko rekordy z FS_RESULT większym niż 50. Poniżej przedstawiono dane wyjściowe z naszego przykładu.

Jak pokazują wyniki, ten typ wyszukiwania jest przydatny do znajdowania:
- Połączone nazwy
- Hałas
- Błędy ortograficzne
- Znaki transponowane
- Błędy w transkrypcji
- Błędy w pisowni
Funkcja Levenshteina jest zatem przydatna również do identyfikowania typowych błędów wprowadzania danych. Jednak wykonanie z czterech algorytmów trwa najdłużej, ponieważ porównuje każdy znak w jednym ciągu ze wszystkimi znakami w drugim.
2. Współczynnik kości
Współczynnik kostek lub algorytm kostek dzieli słowa lub frazy na pary znaków, porównuje te pary i zlicza dopasowania. Im więcej dopasowań mają słowa, tym bardziej prawdopodobne jest, że samo słowo jest dopasowaniem.
Poniższy skrypt SortCL demonstruje funkcję wyszukiwania rozmytego współczynnika kości.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Istnieją dwie części, których należy użyć, aby uzyskać pożądany wynik.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Ta linia wywołuje funkcję fs_dice i przechowuje wynik w polu FS_RESULT. Funkcja przyjmuje dwa parametry wejściowe:
- Pole do uruchomienia wyszukiwania rozmytego (w naszym przykładzie NAZWA).
- Ciąg, z którym będzie porównywane pole wejściowe (w naszym przykładzie „Robert Thomas Smith”).
/INCLUDE WHERE FS_RESULT GT 50
Ta linia porównuje pole FS_RESULT i sprawdza, czy jest większe niż 50, a następnie wyprowadzane są tylko rekordy z FS_RESULT większym niż 50. Poniżej przedstawiono dane wyjściowe z naszego przykładu.
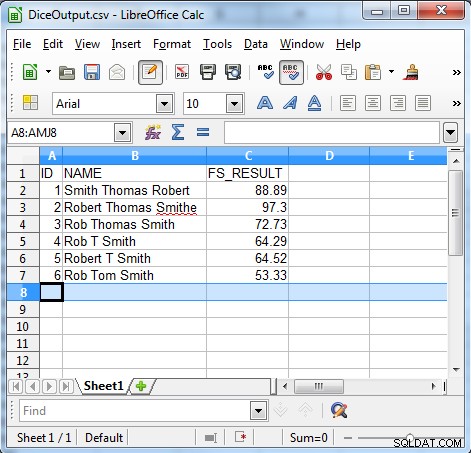
Jak pokazują wyniki, algorytm współczynnika kości jest przydatny do znajdowania niespójnych danych, takich jak:
- Błędy sekwencji
- Poprawki mimowolne
- Pseudonimy
- Inicjały i pseudonimy
- Nieprzewidywalne użycie inicjałów
- Lokalizacja
Algorytm kości jest szybszy niż Levenshtein, ale może stać się mniej dokładny, gdy pojawi się wiele prostych błędów, takich jak literówki.
3. Metafon i 4. Soundex
algorytmy Metaphone i Soundex porównują słowa lub frazy na podstawie ich dźwięków fonetycznych. Soundex robi to, czytając słowo lub frazę i patrząc na poszczególne znaki, podczas gdy Metaphone analizuje zarówno pojedyncze znaki, jak i grupy znaków. Następnie obaj podają kody na podstawie pisowni i wymowy słowa.
Poniższy skrypt SortCL demonstruje funkcje wyszukiwania Soundex i Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
W każdym przypadku istnieją trzy części, których należy użyć, aby uzyskać pożądany wynik.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Linia wywołuje funkcję i przechowuje wynik w polu RESULT. Obie funkcje przyjmują dwa parametry wejściowe:
- Pole do uruchomienia wyszukiwania rozmytego (w naszym przykładzie NAZWA)
- String, z którym będzie porównywane pole wejściowe („Jan” w naszym przykładzie)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Ten wiersz porównuje pola SE_RESULT i MP_RESULT oraz sprawdza i zwraca wiersz, jeśli któreś z nich jest większe niż 0.
Soundex zwraca 100 dla dopasowania lub 0, jeśli nie jest to dopasowanie. Metaphone ma bardziej szczegółowe wyniki i zwraca 100 dla silnego dopasowania, 66 dla normalnego dopasowania i 33 dla mniejszego dopasowania.
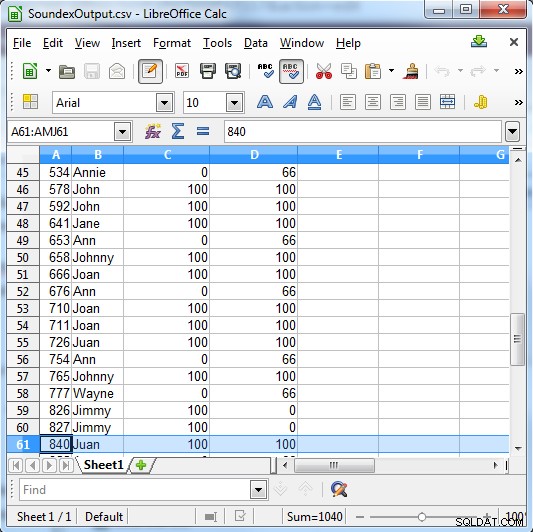
Kolumna C pokazuje wyniki Soundex. Ckolumna D pokazuje wyniki Metaphone
Jak pokazują wyniki, ten typ wyszukiwania jest przydatny do znajdowania:
- Błędy fonetyczne
Prześlij opinię na temat tego artykułu poniżej, a jeśli chcesz korzystać z tych funkcji, skontaktuj się z przedstawicielem IRI. Zobacz nasz następny artykuł na temat korzystania z tych algorytmów w kreatorze konsolidacji danych (jakości) IRI Workbench.