Jeśli istnieje sposób na zamawianie artykułów spożywczych online, dlaczego z niego nie skorzystać? W tym artykule przyjrzymy się modelowi danych stojącemu za systemem dostaw w sklepie spożywczym.
Nadal mamy wyjątkowe uczucie, gdy wybieramy coś z ogrodu, a następnie przygotowujemy to od razu – ale nie jest to coś, co często możemy robić. Dzisiejsze szybkie tempo na to nie pozwala. W rzeczywistości czasami nie pozwala nam to nawet iść do sklepu, aby „zbierać” nasze artykuły spożywcze. Warto więc zaoszczędzić trochę czasu i skorzystać z aplikacji, aby zamówić to, czego potrzebujemy. Nasze zamówienie po prostu pojawi się w naszym domu. Może nie dostaniemy tego wyjątkowego uczucia świeżości, ale na naszym stole będzie jedzenie.
Model danych stojący za taką aplikacją jest tematem dzisiejszego artykułu.
Czego potrzebujemy do modelu danych dostaw artykułów spożywczych?
Ideą tego modelu jest to, że aplikacja (internetowa, mobilna lub obie) umożliwi zarejestrowanym klientom tworzenie zamówienia (składającego się z produktów z naszego sklepu). Następnie to zamówienie zostanie dostarczone do klienta. Oczywiście będziemy przechowywać dane klientów i listę wszystkich dostępnych produktów, aby to wspierać.
Klienci mogą składać wiele zamówień, które obejmują różne pozycje w różnych ilościach. Po otrzymaniu zamówienia klienta należy powiadomić pracowników sklepu, aby mogli znaleźć i spakować potrzebne artykuły. (Może to wymagać jednego lub więcej kontenerów). Na koniec kontenery zostaną dostarczone razem lub osobno.
W samej aplikacji klienci i pracownicy powinni mieć możliwość wstawiania notatek i oceniania drugiej strony po zrealizowaniu dostawy.
Model danych
Model danych składa się z trzech obszarów tematycznych:
Items & unitsCustomers & employeesOrders
Zaprezentujemy każdy obszar tematyczny w kolejności, w jakiej jest wymieniony.
Sekcja 1:Przedmioty i jednostki
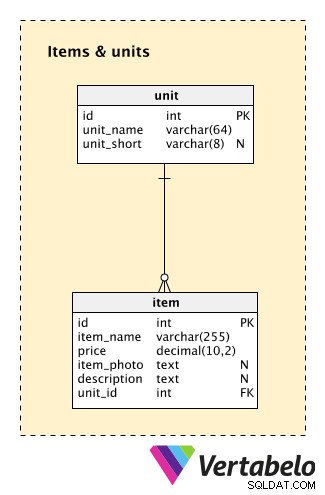
Zaczniemy od Items & units Tematyka. Chociaż jest to niewielka część naszego modelu, zawiera dwie bardzo ważne tabele.
unit tabela przechowuje informacje o jednostkach, które przypiszemy do dowolnego przedmiotu w naszym ekwipunku. Dla każdej wartości w tej tabeli będziemy przechowywać dwie UNIKALNE wartości:unit_name (np. „kilogram”) i unit_short (np. „kg”). Zauważ, że unit_short to skrót od unit_name .
Druga tabela w tym obszarze tematycznym to item . Zawiera listę wszystkich przedmiotów, które mamy w ekwipunku. Dla każdego przedmiotu przechowujemy:
item_name– UNIKALNA nazwa, której będziemy używać dla tego przedmiotu.price– Aktualna cena tego przedmiotu.item_photo– Link do zdjęcia tego przedmiotu.description– Dodatkowy opis tekstowy przedmiotu.unit_id– Odwołuje się dounitsłownika i oznacza jednostkę używaną do pomiaru tego elementu.
Proszę zauważyć, że pominąłem tutaj kilka rzeczy. Najważniejszą z nich jest flaga, która informuje, czy dany przedmiot z inwentarza jest aktualnie wystawiony na sprzedaż. Dlaczego tego nie mamy? Wymagałoby to co najmniej jednego dodatkowego pola (flagi) oraz kolejnej tabeli (do przechowywania zmian historycznych dla każdego elementu). Aby uprościć sprawę, założyłem, że wszystkie przedmioty, które mamy w ekwipunku, są również dostępne do sprzedaży.
Drugą ważną rzeczą, którą pominąłem, jest śledzenie stanu magazynu. Wychodzę z założenia, że wysyłamy wszystko z jednego centralnego magazynu i zawsze będziemy mieć dostępne pozycje. Jeśli nie mamy przedmiotu, po prostu powiadomimy klienta i zaproponujemy mu podobny przedmiot w zamian.
Sekcja 2:Klienci i pracownicy

Customers & employees obszar tematyczny zawiera wszystkie tabele potrzebne do przechowywania danych klientów i pracowników. Wykorzystamy te informacje w centralnej części naszego modelu.
employee tabela zawiera listę wszystkich odpowiednich pracowników (np. pakowaczy i doręczycieli). Dla każdego pracownika przechowamy jego first_name i last_name i UNIKALNY employee_code wartość. Chociaż kolumna id jest również UNIQUE (i klucz podstawowy tej tabeli), lepiej użyć innej, rzeczywistej wartości (np. numeru VAT) jako identyfikatora pracownika. W ten sposób mamy employee_code pole.
Zauważ, że nie uwzględniłem danych logowania pracowników, ról pracowników i sposobu śledzenia historii ról. Można je łatwo dodać, jak opisano w tym artykule.
Teraz dodamy klientów do naszego modelu. Zajmie to jeszcze dwa stoliki.
Klienci będą podzieleni geograficznie, więc będziemy potrzebować city słownik. Dla każdego miasta, w którym oferujemy dostawę artykułów spożywczych, przechowujemy city_name i postal_code . Razem tworzą one klucz alternatywny tej tabeli.
Klienci są zdecydowanie najważniejszą częścią tego modelu; to oni inicjują cały proces. Przechowamy pełną listę naszych klientów w customer stół. Dla każdego klienta przechowujemy następujące informacje:
first_name– Imię klienta.last_name– Nazwisko klienta.user_name– Nazwa użytkownika wybrana przez klienta podczas zakładania konta.password– Hasło wybrane przez klienta podczas zakładania konta.time_inserted– Moment, w którym ten rekord został umieszczony w bazie danych.confirmation_code– Kod, który został wygenerowany podczas kodu rejestracyjnego. Ten kod zostanie użyty do zweryfikowania ich adresu e-mail.time_confirmed– Kiedy nastąpiło potwierdzenie e-mailem.contact_email– Adres e-mail klienta, który jest również używany jako wiadomość e-mail z potwierdzeniem.contact_phone– Numer telefonu klienta.city_id– Identyfikatorcitygdzie mieszka klient.address– Adres domowy klienta.delivery_city_id– Identyfikatorcitygdzie zamówienie klienta powinno zostać dostarczone.delivery_address– Preferowany adres dostawy. Pamiętaj, że może to być (ale nie musi) to samo co adres domowy klienta.
Sekcja 3:Zamówienia
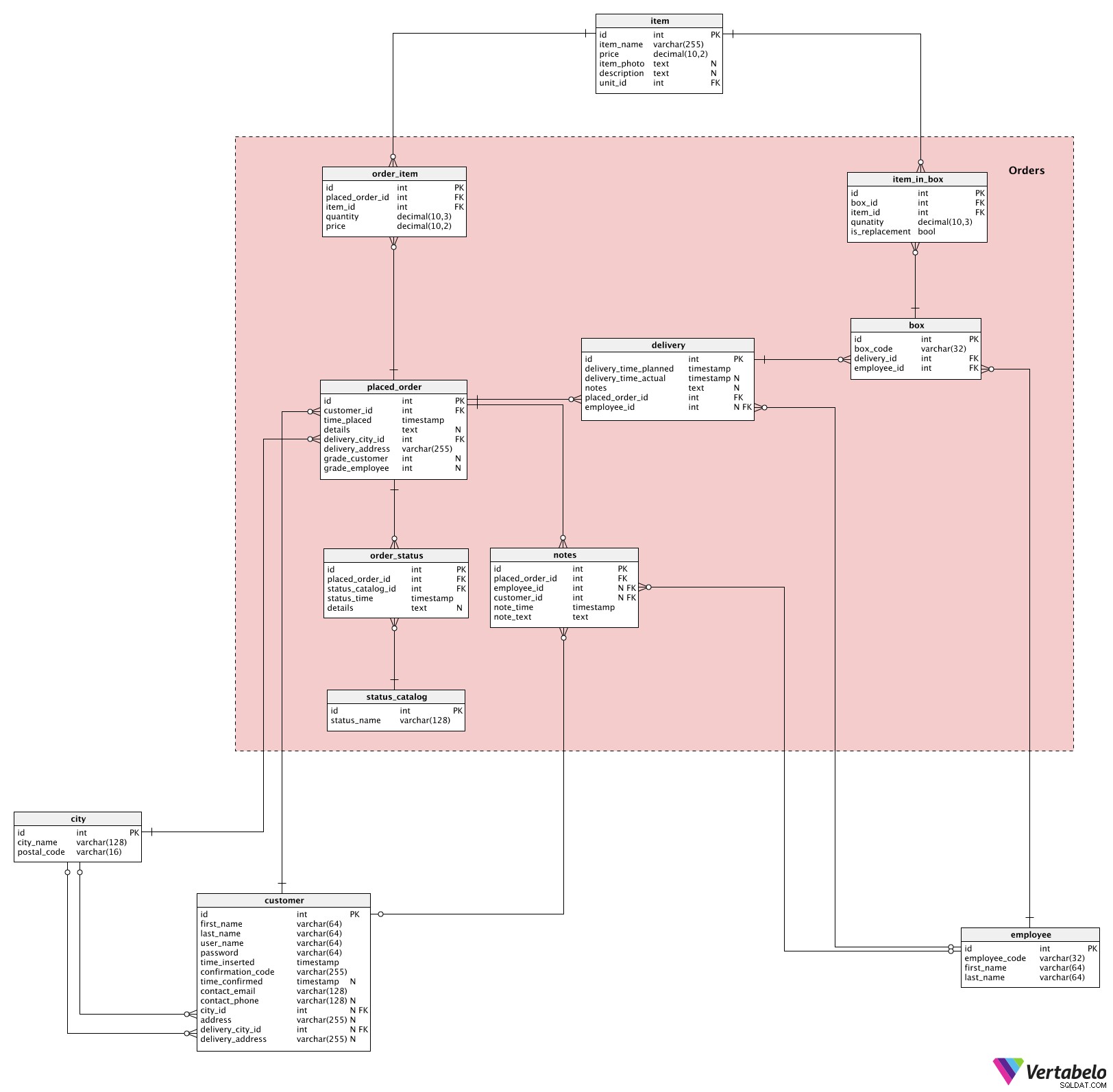
Centralną i najważniejszą częścią tego modelu są Orders Tematyka. Tutaj znajdziemy wszystkie tabele potrzebne do złożenia zamówienia i śledzenia produktów do momentu ich dostarczenia do klientów.
Cały proces rozpoczyna się w momencie złożenia przez klienta zamówienia. Lista każdego kiedykolwiek złożonego zamówienia znajduje się w placed_order stół. Celowo użyłem tej nazwy, a nie „zamówienie”, ponieważ zamówienie jest zastrzeżonym słowem kluczowym SQL. Dla każdego zamówienia przechowujemy:
customer_id– Identyfikatorcustomerktóry złożył to zamówienie.time_placed– Sygnatura czasowa złożenia zamówienia.details– Wszystkie szczegóły związane z tym zamówieniem, w nieustrukturyzowanym formacie tekstowym.delivery_city_id– Odniesienie docitygdzie to zamówienie powinno zostać dostarczone.delivery_address– Adres, pod który zamówienie powinno zostać dostarczone.grade_customer&grade_employee– Oceny wystawione przez pracownika i klienta po zrealizowaniu zamówienia. Do tego momentu ten atrybut zawiera wartość NULL. Ocena klienta wskazuje, jak bardzo był zadowolony z naszej usługi; ocena pracownika daje nam informacje o tym, czego możemy się spodziewać następnym razem, gdy klient złoży zamówienie.
W trakcie procesu składania zamówienia Klient wybierze jeden lub więcej artykułów. Dla każdego przedmiotu określą pożądaną ilość. Lista wszystkich przedmiotów związanych z każdym zamówieniem jest przechowywana w order_item stół. Dla każdego rekordu w tej tabeli będziemy przechowywać identyfikatory powiązanego zamówienia (placed_order_id ), przedmiot (item_id ), żądaną ilość i price kiedy to zamówienie zostało złożone.
Oprócz co chcą dostarczyć, klienci określą również żądany czas dostawy czas . Dla każdego zamówienia utworzymy jeden rekord w delivery stół. Spowoduje to zarejestrowanie delivery_time_planned i wstawiaj dodatkowe notatki tekstowe. placed_order_id atrybut zostanie również zdefiniowany po wstawieniu tego rekordu. Pozostałe dwa atrybuty zostaną zdefiniowane, gdy przypiszemy tę dostawę pracownikowi (employee_id ) i kiedy zamówienie zostało dostarczone (delivery_time_actual ).
Chociaż może się wydawać, że będziemy mieć tylko jedną dostawę na zamówienie, nie zawsze tak jest. Być może będziemy musieli wykonać dwie lub więcej dostaw na zamówienie i to jest główny powód, dla którego zdecydowałem się umieścić dane dostawy w nowej tabeli.
Kiedy zaczynamy realizację zamówienia, pracownicy pakują towar w jedno lub więcej pudełek. Każde box będzie zdefiniowany WYJĄTKOWO przez jego box_code i zostanie przypisany do dostawy (delivery_id ). Przechowamy również identyfikator pracownika, który przygotował to pudełko.
Każde pudełko będzie zawierać jeden lub więcej elementów. Dlatego w item_in_box tabeli, będziemy musieli przechowywać odniesienia do box tabela (box_id ) i item tabela (item_id ), a także ilość umieszczoną w tym pudełku. Ostatni atrybut, is_replacement , wskazuje, czy przedmiot zastępuje inny przedmiot. Możemy oczekiwać, że pracownik skontaktuje się z klientem przed włożeniem towaru zastępczego do pudełka. Jednym z wyników tego działania może być to, że klient zgadza się na produkt zastępczy; innym może być anulowanie całego zamówienia.
Pozostałe trzy tabele w modelu są ściśle powiązane ze statusami i komentarzami.
Najpierw będziemy przechowywać wszystkie możliwe statusy w status_catalog . Każdy status jest JEDYNIE zdefiniowany przez jego status_name . Możemy spodziewać się statusów takich jak „zamówienie utworzone”, „zamówienie złożone”, „przedmioty zapakowane”, „w tranzycie” i „dostarczone”.
Statusy będą nadawane do zamówień automatycznie (po zakończeniu niektórych etapów procesu) lub, w niektórych przypadkach, ręcznie (np. w przypadku problemu z zamówieniem). Wszystkie dostępne statusy zamówień są przechowywane w order_status stół. Oprócz kluczy obcych z dwóch tabel (status_catalog i placed_order ), będziemy przechowywać rzeczywisty znacznik czasu, kiedy ten status został przypisany (status_time ) i wszelkie dodatkowe details w formacie tekstowym.
Ostatnia tabela w tym modelu to notes stół. Ideą tej tabeli jest wstawienie wszystkich dodatkowych komentarzy związanych z danym zamówieniem (placed_order_id ). Komentarze mogą być wstawiane przez pracowników lub klientów. Dla każdego rekordu tylko jeden z employee_id lub customer_id pola będą zawierały wartość; drugi będzie NULL. Przechowamy moment, w którym ta notatka została wstawiona do systemu (note_time ) i note_text .
Jakie zmiany wprowadziłbyś w modelu danych dostaw artykułów spożywczych?
Dzisiaj omówiliśmy model danych, który mógłby obsługiwać aplikacje webowe i mobilne do dostarczania produktów spożywczych – zarówno z perspektywy klienta, jak i pracownika. Jak już wspomniano w tym artykule, sposobów na ulepszenie tego modelu jest wiele. Zapraszam do dodawania swoich sugestii. Powiedz nam, co chciałbyś dodać do tego modelu lub z niego usunąć. A może zorganizowałbyś tę strukturę zupełnie inaczej. Daj nam znać w sekcji komentarzy!