Bez względu na to, po której stronie równania się znajdujesz, czasami trudno jest znaleźć wykwalifikowaną osobę do określonej pracy. W tym poście przyjrzymy się modelowi danych, który pomoże rekruterom i działom HR zachować porządek podczas procesu rekrutacji.
Większość z nas była zaangażowana w proces rekrutacji – najczęściej jako osoba ubiegająca się o pracę. Jednak możemy również zaangażować się po stronie zatrudniania, być może testując wiedzę techniczną kandydata. Proces rekrutacji zajmuje określoną ilość czasu, a grono kandydatów stale się zmniejsza w miarę zbliżania się do ostatecznej decyzji. Rezultatem powinien być wybór najlepszej osoby do pracy.
Rekrutacja sama w sobie jest dość skomplikowana, więc omówimy dość wszechstronny model danych obejmujący wszystkie aspekty procesu. Usiądź wygodnie na krześle i ciesz się dzisiejszym artykułem!
Jak działa proces rekrutacji
Większość części procesu rekrutacji jest powszechnie znana, ale omówimy dokładnie, jak to działa, zanim przejdziemy do modelu danych.
-
Wykrywanie potrzeby
Jest to absolutna konieczność w procesie rekrutacji; nie będzie procesu, jeśli kierownictwo nie będzie świadome potrzeby zatrudnienia nowego pracownika. Taka potrzeba może wynikać z założenia nowej firmy, rozwoju w istniejącej firmie lub odejścia obecnego pracownika.
O ile firma nie ma ściśle określonych stanowisk (np. banki), nie zawsze łatwo jest określić, kiedy zatrudnić nowego pracownika. Rozmowa z pracownikami i oglądanie wielu nadgodzin może zachęcić nowego pracownika. Przepisy wewnętrzne lub zewnętrzne mogą również wymagać, aby określone stanowiska były przyznawane tylko osobom o określonym zestawie umiejętności i odpowiednim doświadczeniu zawodowym (np. weryfikator wewnętrzny).
-
Określenie stanowiska i wymaganych umiejętności
Aby zorientować się w tym kroku, pomyśl o naprawdę dobrze napisanym opisie stanowiska. Zawiera:
- Lista wszystkich zadań związanych z pracą
- Minimalne kwalifikacje w zakresie wykształcenia i doświadczenia zawodowego
- Konkretne umiejętności niezbędne do pełnienia funkcji zawodowych
- Dodatkowe lub preferowane umiejętności
- Podsumowanie tego, czego pracodawca oczekuje od kandydata i czego kandydat może oczekiwać od tej pracy
- Zakres wynagrodzenia i być może pakiet świadczeń
Ta informacja jest ważna zarówno dla rekruterów, jak i kandydatów. Nie ma sensu zapraszać do selekcji dziesięciu kandydatów, jeśli żaden z nich nie będzie zadowolony z oferty finansowej. A im bardziej szczegółowy opis stanowiska, tym łatwiej będzie przyciągnąć wykwalifikowanych kandydatów.
-
Określanie, kto będzie zarządzał procesem i kiedy każde zadanie powinno się odbyć
Następnym krokiem jest określenie konkretnych dat, w których nastąpi każda część procesu. Ponadto firmy mogą przypisywać pracowników do każdego kroku. Jeśli firma posiada dział HR, prawdopodobnie będzie zarządzał każdą częścią procesu rekrutacji, chociaż inni pracownicy mogą w razie potrzeby wnieść swoją specyficzną wiedzę (np. jeśli zatrudniamy specjalistę IT, kierownik działu IT powinien oceniać kandydatów ' umiejętności techniczne).
Jeśli nie ma działu HR, możemy oczekiwać, że za proces będzie odpowiadać kadra kierownicza. W małych i średnich firmach jest to nie tylko potrzebne, ale wręcz pożądane.
-
Publikowanie oferty
Teraz jesteśmy gotowi, aby opublikować opis stanowiska na naszej stronie, na tablicach ogłoszeń lub agregatorach lub w gazecie. Stanowisko pracy powinno zawierać punkty wymienione w kroku 2. Pomoże to potencjalnym kandydatom zdecydować, czy chcą ubiegać się o dane stanowisko. Bardzo ważne jest, aby opis stanowiska był dokładny; wszyscy zmarnowaliśmy czas na rozmowę kwalifikacyjną w poszukiwaniu pracy, która nie odpowiadała jej opisowi lub naszym oczekiwaniom.
-
Wybieranie, testowanie i przeprowadzanie rozmów kwalifikacyjnych
Po zakończeniu okresu składania wniosków kandydaci posiadający najbardziej odpowiednie umiejętności i doświadczenie zostaną zaproszeni do wstępnej fazy oceny (zwykle rozmowa kwalifikacyjna lub test). Pozostali kandydaci zostaną poinformowani, że nie zostali wybrani do pracy. Duża firma powinna zaprosić ustaloną z góry minimalną liczbę kandydatów do wstępnej oceny. Oszczędza to czas zarówno dla wnioskodawców, jak i dla firmy.
Małe i średnie firmy mogą zdecydować się na kontynuację tego procesu, dopóki nie znajdą najlepszego dopasowania. W takich przypadkach okres składania wniosków pozostanie otwarty do momentu znalezienia odpowiedniego kandydata, a wszystkie inne terminy zostaną określone po drodze.
Rozmowa kwalifikacyjna i proces testowania będą się różnić w zależności od wielkości firmy i organizacji. W dużych firmach z działami HR prawdopodobnie pojawi się zestaw testów sprawdzających umiejętności zawodowe kandydatów. Inne testy mogą mierzyć cechy psychologiczne i osobowości w celu określenia dopasowania kandydata do stanowiska pracy, dopasowania kandydata do firmy, a nawet poczytalności kandydata.
Testy te są zwykle podzielone na kilka etapów, a każdy z nich zmniejszy liczbę kandydatów.
-
Ostateczny wywiad
Ten krok będzie prawdopodobnie wywiadem z kilkoma najlepszymi kandydatami. Jest to najważniejszy krok w procesie, ponieważ kandydaci mogą mówić za siebie, wykazać się kompetencjami i osobowością oraz określić, czy firma i stanowisko będą dla nich odpowiednie. Po tym kroku najlepszy kandydat otrzyma ofertę. Jeśli się zgodzą, proces rekrutacji na to stanowisko dobiega końca. Jeśli kandydat odrzuci ofertę pracy, firma złoży ofertę do następnego wyboru.
-
Czy istnieją różnice w procesie rekrutacji dla małych, średnich i dużych firm? Jak rozwiążemy je w naszym modelu?
Będą pewne różnice w procesach rekrutacyjnych małych, średnich i dużych firm. Ponadto proces będzie się różnił w zależności od rekrutowanych stanowisk. Pomyśl, jak różne są wymagane umiejętności i doświadczenia dla menedżera treści, ornitologa i kapitana statku wycieczkowego. Niektóre stanowiska będą miały więcej testów i rozmów kwalifikacyjnych, inne mogą mieć tylko kilka. Ale ostatecznie wszystko sprowadza się do uzyskania właściwych odpowiedzi i rankingu kandydatów.
W tym modelu wszystkie testy i wywiady traktuję w ten sam sposób. Przechowamy odpowiedzi każdego kandydata, powiążemy je z odpowiednim pytaniem i zachowamy wynik kandydata na każdym etapie procesu.
-
Kto może korzystać z tego modelu danych?
Model ten jest bardzo specyficzny i powinien być stosowany wyłącznie w procesie rekrutacji. Ale to nie ogranicza się do działów HR; możesz również użyć tego modelu do prowadzenia profesjonalnej usługi rekrutacyjnej.
-
Model danych
Model danych składa się z pięciu głównych obszarów tematycznych:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Opiszę każdy obszar tematyczny osobno, w tej samej kolejności, w jakiej są wymienione.
Sekcja 1:Oferty pracy
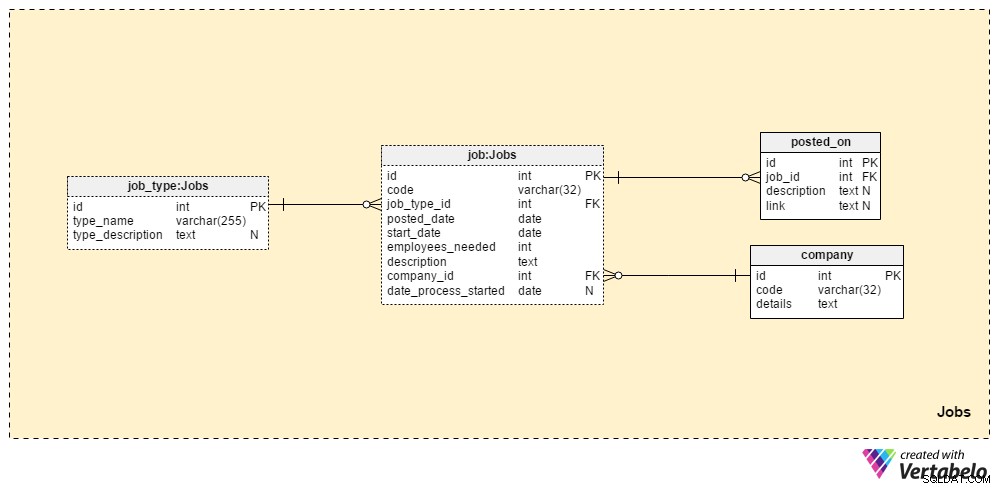
Jobs sekcja będzie przechowywać wszystkie szczegóły dla wszystkich pozycji, które kiedykolwiek opublikowaliśmy. Dwie tabele słownikowe, company tabela i job_type tabeli, są częścią początkowej konfiguracji. Pozostałe dwie tabele, job i posted_on , zawierają „prawdziwe” dane związane z ofertami pracy.
job_type słownik zawiera listę różnych i UNIKATOWYCH typów zadań. Możemy oczekiwać wartości takich jak „starszy administrator bazy danych” lub „dziennikarz IT” być przechowywane w type_name atrybut. type_description atrybut może przechowywać bardziej szczegółowy opis zadania.
company słownik zawiera listę wszystkich firm, z którymi współpracujemy. Jeśli zatrudniamy pracowników tylko dla naszej firmy, w tym słowniku będzie znajdować się tylko nazwa naszej firmy. Jeśli jesteśmy agencją rekrutacyjną, będzie ona przechowywać nazwy każdej firmy, która nas zatrudniła.
Lista wszystkich stanowisk, które kiedykolwiek opublikowaliśmy, jest przechowywana w tabeli „praca”. Atrybuty w tej tabeli to:
code– Nasz wewnętrzny UNIKALNY ID używany do oznaczania pracy.job_type_id– Odwołuje się do powiązanego typu pracy.posted_date– Data opublikowania tego stanowiska pracy.start_date– Przewidywana data rozpoczęcia (pierwszy dzień roboczy) dla tej pracy.employees_needed– Liczba pracowników, których chcemy zatrudnić podczas tej rekrutacji. Przeważnie będzie to miało wartość „1”, ale w niektórych przypadkach – np. przy zakładaniu nowej firmy lub zakładaniu nowego działu – możemy spodziewać się większych wartości.description– Szczegółowy opis tego stanowiska. To jest miejsce, w którym wymienimy wszystkie wymagane, preferowane i pożądane umiejętności zawodowe.company_id– Referencje ID firmy, która nas zatrudniła. Jeśli jesteśmy agencją rekrutacyjną, będzie to odnosić się do nazwy firmy przechowywanej wcompanystół. W przeciwnym razie będzie to identyfikator naszej firmy.date_process_started– Data rozpoczęcia procesu rekrutacji. Może to być NULL, jeśli musimy zdefiniować przyszłe kroki i działania dotyczące tej pracy.
Ostatnia tabela w tym obszarze tematycznym to posted_on stół. Dla każdego job_id , przechowamy link do stanowiska pracy i powiązanego description . Możemy wykorzystać te dane, aby dowiedzieć się, gdzie kandydaci znajdują nasze oferty pracy.
Sekcja 2:Kandydaci, Rekruterzy i Dokumenty
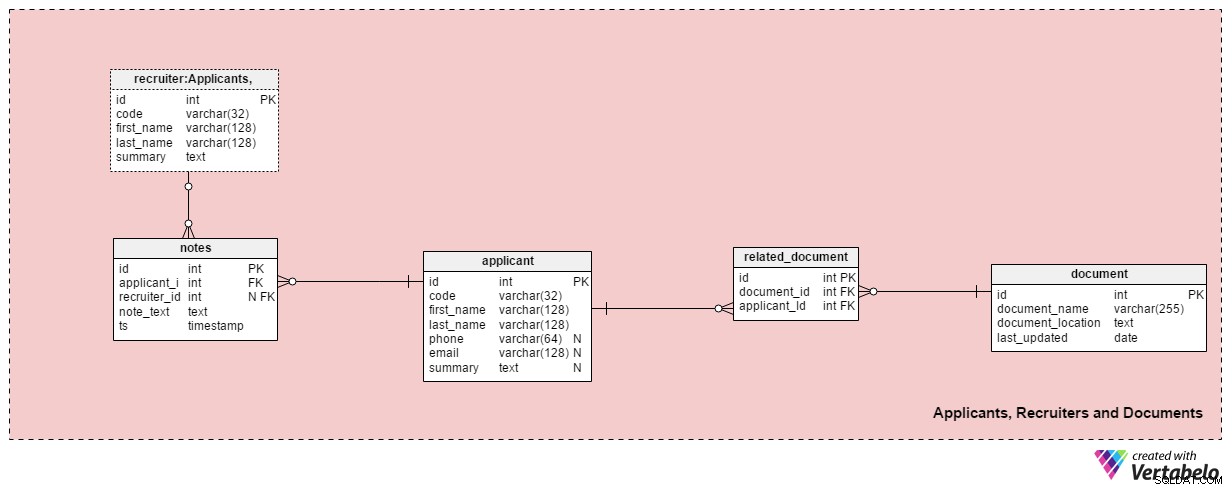
Ten obszar tematyczny zawiera wszystkie tabele potrzebne do przechowywania informacji o osobach rekrutujących, kandydatach i związanych z nimi dokumentach.
applicant tabela zawiera listę wszystkich kandydatów, z którymi kiedykolwiek mieliśmy kontakt. Każdy aplikant jest WYJĄTKOWO zdefiniowany w naszym systemie za pomocą „kodu”. Poza tym będziemy przechowywać imię i nazwisko każdego kandydata, phone numer, email adres i ich summary . Stół ten można dostosować do konkretnych potrzeb, m.in. dodawanie dodatkowych numerów telefonów, adresów e-mail lub adresów fizycznych.
Powiążemy wnioskodawców z dostępnymi dokumentami. Lista wszystkich dostępnych dokumentów (CV lub CV, stopnie naukowe lub dyplomy, transkrypcje, certyfikaty itp.) jest przechowywana w document stół. Dla każdego dokumentu zachowamy jego nazwę w systemie, jego lokalizację i czas ostatniej aktualizacji.
Powiążemy kandydatów z dokumentami za pomocą related_document stół. Zawiera tylko dwa klucze obce, które tworzą document_id – applicant_id UNIKALNA para.
recruiter tabela zawiera listę pracowników, których można przydzielić do podania o pracę lub którzy wprowadzają uwagi dotyczące kandydata. Każdy rekruter jest WYJĄTKOWO zdefiniowany przez swój code . Będziemy przechowywać tylko podstawowe dane, takie jak first_name , last_name i summary rekrutera .
Ostatnia tabela w tym obszarze tematycznym to notes stół. Tutaj będziemy przechowywać wszystkie notatki związane z kandydatem. Moglibyśmy przechowywać notatki, takie jak „Wnioskodawca nie wziął udziału w spotkaniu” lub „Kandydat świetnie poradził sobie podczas pierwszej rozmowy kwalifikacyjnej” . W przypadku każdej notatki będziemy przechowywać identyfikator rekrutera, który sporządził tę notatkę, identyfikator powiązanego kandydata, note_text oraz sygnaturę czasową utworzenia notatki.
Sekcja 3:Szczegóły testu
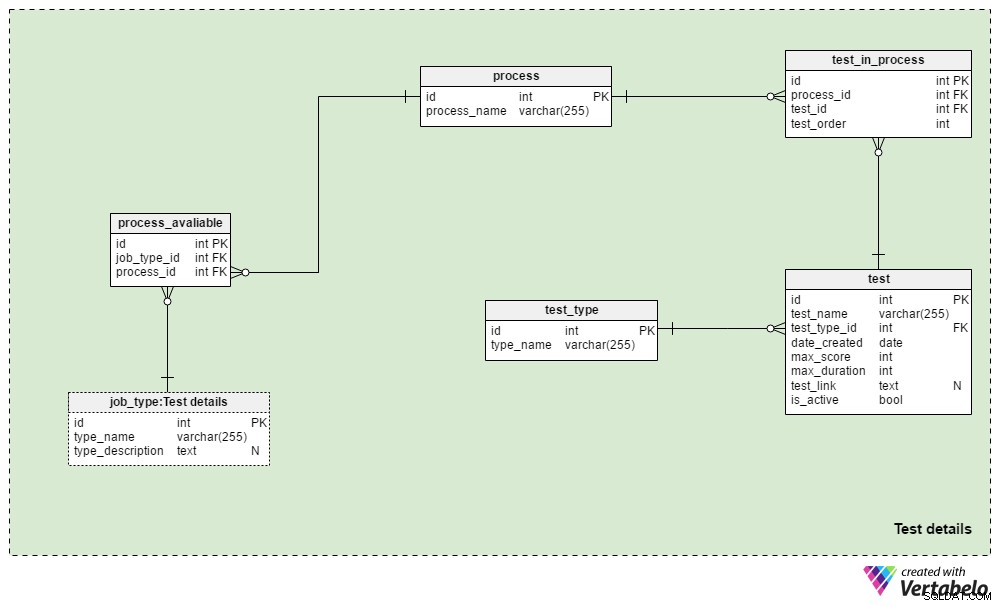
Test details obszar tematyczny zawiera tabele służące do definiowania procesów rekrutacyjnych oraz testy stosowane w tych procesach. Zasadniczo zawsze stosujemy ten sam proces selekcji dla tego samego rodzaju stanowiska:zmiany są wprowadzane tylko wtedy, gdy wymagają tego okoliczności biznesowe. Moglibyśmy użyć kilku różnych procesów dla każdego rodzaju pracy i prawie na pewno użyjemy tego samego procesu dla różnych typów zadań.
process table to prosty słownik zawierający tylko UNIKALNY process_name atrybut. Zawiera listę wszystkich procesów rekrutacyjnych, z których kiedykolwiek korzystaliśmy i których obecnie używamy.
Powiążemy procesy z różnymi rodzajami pracy. Będziemy przechowywać te relacje w process_available stół. Jego jedynymi atrybutami są UNIKALNA para job_type_id – process_id . Gdy dla danego rodzaju pracy dostępnych jest wiele procesów, pozwala to rekruterowi wybrać jeden.
test_in_process tabela służy do określenia kolejności testów podczas tego procesu. Atrybuty w tej tabeli to:
process_iditest_id– Odwołuje się do powiązanego procesu i testu.test_order– Numer porządkowy tego testu lub kroku w procesie. Razem zprocess_id, tworzy UNIKALNY klucz tabeli. W trakcie procesu możemy mieć tylko jeden krok na raz.
test tabela zawiera listę wszystkich testów aktualnie i wcześniej stosowanych w procesie rekrutacji. Jako testy będziemy też traktować recenzje CV i rozmowy kwalifikacyjne. Chociaż nie potrzebują zdefiniowanych pytań i odpowiedzi, są częścią ewaluacji. Dla każdego testu będziemy przechowywać:
test_name– UNIKALNE oznaczenie dla każdego testu.test_type_id– Odwołuje się dotest_typesłownik.date_created– Data utworzenia tego testu w naszym systemie.max_score– Maksymalny wynik osiągalny dla tego testu. Ta wartość to suma wszystkich poprawnych odpowiedzi w tym teście lub najwyższa ocena, jaką rekruterzy mogliby wystawić na CV lub rozmowę kwalifikacyjną.max_duration– Jak długo (w minutach) kandydat musi wypełnić test.test_link– Zawiera łącze do lokalizacji testowej. Ta wartość może wynosić NULL, gdy nie używamy testu w procesie.is_active– Oznacza, czy obecnie używamy tego testu.
Wspomnieliśmy już o test_type słownik. Zawiera wszystkie UNIKALNE nazwy testów według formatu, np. „Recenzja CV” , „test umiejętności online” , „test umiejętności papierowych” i „wywiad” .
Ten model nie zawiera struktury potrzebnej do przechowywania pytań testowych i odpowiedzi. Zamiast tego przechowuje link do lokalizacji, które zawierają te informacje. Ten sam projekt będzie używany w Applications Tematyka.
Sekcja 4:Aplikacje
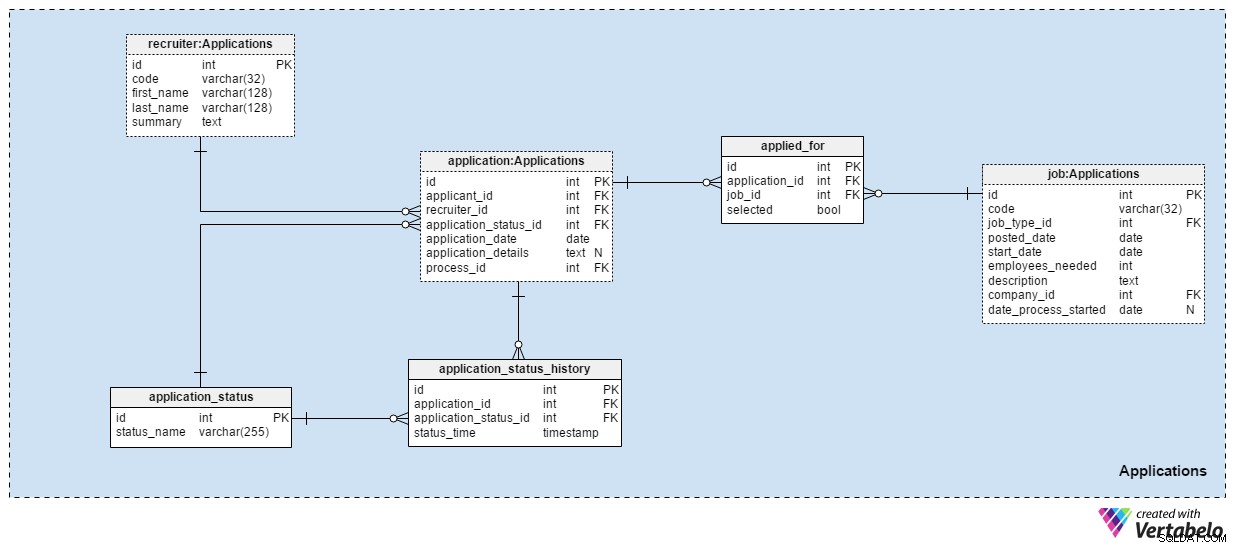
Applications obszar tematyczny jest prawdopodobnie najważniejszy w tym modelu danych. Wszystkie inne wymienione do tej pory obszary tematyczne opisywały zastosowania. Ten przechowuje prawdziwe rzeczy.
Każda aplikacja, którą kiedykolwiek otrzymaliśmy, jest rejestrowana w application stół. W przypadku każdej aplikacji będziemy przechowywać identyfikatory powiązanych kandydatów, identyfikatory rekruterów oraz odniesienie do aktualnego statusu tej aplikacji. Zaktualizujemy ten status jednocześnie z nowym wpisem w application_status_history stół. application_date atrybut służy do przechowywania odpowiedniej daty, podczas gdy wszystkie dodatkowe szczegóły są przechowywane w formacie tekstowym. process_id atrybut przechowuje odniesienie do procesu wybranego dla tej aplikacji.
Z biegiem czasu status aplikacji będzie się zmieniał. Lista wszystkich statusów aplikacji jest przechowywana w application_status słownik. Jedynym atrybutem jest status_name i może posiadać tylko UNIKALNE wartości. Oczekiwane wartości to:„zastosowano” , „Przejrzane CV” , „wybrany do testu” , „odrzucony po sprawdzeniu CV” , „zdał test” , „zaproszeni na rozmowę kwalifikacyjną” i „zakończony przez kandydata” .
Będziemy przechowywać wszystkie stany aplikacji w application_status_history stół. Ta tabela zawiera odniesienia do application tabela i application_status słownik. Przechowamy również dokładny status_time kiedy ten status został nadany aplikacji. application_id – status_time para tworzy UNIKALNY klucz tej tabeli.
W większości przypadków kandydat będzie ubiegał się tylko o jedno stanowisko z jednym wnioskiem. Możliwe, że kandydat będzie aplikował na więcej niż jedno stanowisko i podczas procesu selekcji wybierzemy dla niego najbardziej odpowiednią rolę. W applied_for tabeli, przechowamy UNIKALNĄ parę application_id – job_id . Odnotujemy również, czy kandydat powiązany z tą aplikacją został selected na to stanowisko. Możemy się spodziewać, że wszystkie selected wartości zostaną ustawione na „Fałsz” na początku procesu selekcji i że zaktualizujemy tylko jedną na każde stanowisko do „Prawda” .
Sekcja 5:Testy aplikacji
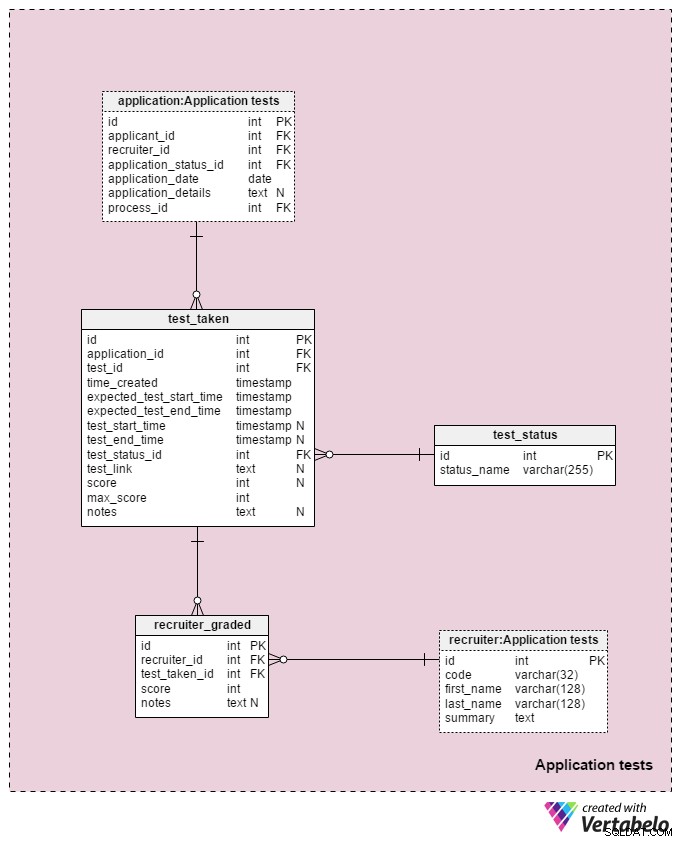
Ostatni obszar tematyczny w naszym modelu będzie używany do przechowywania wyników każdego testu wykonanego podczas procesu selekcji. Dwie tabele używane w tym obszarze tematycznym są kopiami z innych obszarów tematycznych:application i recruiter . Służą one tutaj w celu uproszczenia modelu.
Wszystkie szczegóły związane z każdym testem są przechowywane w test_taken stół. Ta tabela zawiera również wszystkie inne etapy procesu, które można ocenić, takie jak przegląd CV. Atrybuty w tej tabeli to:
application_id– Odwołuje się doapplicationstół. Dotyczy to testu z kandydatem, który poddał się temu testowi.test_id– Odwołuje się dotestkatalog. Możemy również odwołać się dotest_in_processtabelę tutaj, która dostarczyłaby nam więcej informacji o wykonanym teście. Postanowiłem tego nie robić, ponieważ ta struktura zapewnia nam większą elastyczność. (np. jeśli chcemy zezwolić kandydatom na dwukrotne przystąpienie do testu lub poza zwykłymi godzinami).time_created– Rzeczywisty czas, w którym wstawiliśmy ten test do naszego systemu.expected_test_start_timeiexpected_test_end_time– Godzina rozpoczęcia i zakończenia, zgodnie z ustaleniami ze wnioskodawcą. Możemy zmienić te wartości na wypadek, gdyby kandydat lub rekruter musiał przełożyć test.test_start_timeitest_end_time– Rzeczywiste godziny rozpoczęcia i zakończenia testu. Będą one zawierać wartości NULL podczas tworzenia testu; wartości zostaną zaktualizowane, gdy kandydat rozpocznie i zakończy ten test.test_status_id– Odwołuje się dotest_statussłownik.test_link– Linki do testu z odpowiedziami kandydata. Zostanie on zaktualizowany, gdy kandydat prześle test.score– Wynik wnioskodawcy na tym teście. Jest to ustalane ręcznie przez osobę rekrutującą (np. w celu przeglądu CV) lub automatycznie (suma wszystkich punktów testowych). Może również posiadać wartość NULL dla testów, które nie są punktowane lub oceniane na jakiejś predefiniowanej skali. Ponadto test, który jest zaplanowany, ale jeszcze nie został ukończony, może mieć wartość NULL.max_score– Maksymalny możliwy do uzyskania wynik testu. To to samo, co wartość przechowywana wtest”.max_scoreatrybut. Chcę zachować tę wartość, ponieważ rekruter może zmodyfikować test podczas jego wykonywania, a tym samym zmienić maksymalny wynik, który można osiągnąć.notes– Wszelkie dodatkowe uwagi lub uwagi wprowadzone przez rekruterów dotyczące tego konkretnego testu.
Kombinacja test_id – application_id – expected_test_start_time atrybuty tworzą klucz UNIKATOWY tej tabeli. Przed dodaniem nowej sesji testowej nadal powinniśmy sprawdzić, czy dla powiązanego kandydata i wszystkich powiązanych rekruterów nie nakładają się na siebie interwały testowe.
test_status słownik zawiera listę wszystkich UNIKALNYCH status_name które można przypisać do testu. Niektóre oczekiwane wartości to:„nie rozpoczęto” , „w toku” , „ukończono pomyślnie” , „ukończono bez powodzenia” , „przełożone” , „anulowane” i „kandydat anulowany” .
Ostatnia tabela w naszym modelu to recruiter_graded tabela, w której przechowywane są wszystkie oceny, które wystawiali rekrutujący podczas oceniania każdego testu. Dlatego będziemy przechowywać odniesienia do recruiter i test_taken tabele. Przechowamy również score osiągnięte, jak również wszelkie notes . Ta informacja jest bardzo ważna, zwłaszcza gdy oceniamy testy ręcznie (np. w przypadku recenzji CV i rozmów kwalifikacyjnych).
Dziś omówiliśmy model danych, który może objąć prawie każdą sytuację w procesie selekcji i rekrutacji – w tym rzadkie wyjątki.
Większość z nas ma pewne doświadczenie w tym temacie. Podziel się swoim doświadczeniem, gdy byłeś w roli rekrutera lub po drugiej stronie biurka. Czy ten model obejmuje sytuacje, z którymi się spotkałeś? Jeśli nie, jakie zmiany byś zaproponował?