Ludzie zastanawiają się, czy powinni robić wszystko, co w ich mocy, aby zapobiegać wyjątkom, czy po prostu pozwolić systemowi się nimi zająć. Widziałem kilka dyskusji, w których ludzie debatowali, czy powinni zrobić wszystko, co w ich mocy, aby zapobiec wyjątkowi, ponieważ obsługa błędów jest „droga”. Nie ma wątpliwości, że obsługa błędów nie jest bezpłatna, ale przewidziałbym, że naruszenie ograniczenia jest co najmniej tak samo skuteczne, jak najpierw sprawdzenie potencjalnego naruszenia. Na przykład może to być inne w przypadku naruszenia klucza niż naruszenia ograniczenia statycznego, ale w tym poście skupię się na tym pierwszym.
Podstawowe podejścia, których ludzie używają do radzenia sobie z wyjątkami, to:
- Po prostu pozwól silnikowi się tym zająć i prześlij każdy wyjątek z powrotem do dzwoniącego.
- Użyj
BEGIN TRANSACTIONiROLLBACKjeśli@@ERROR <> 0. - Użyj
TRY/CATCHzROLLBACKwCATCHblok (SQL Server 2005+).
I wielu przyjmuje podejście, że powinni najpierw sprawdzić, czy nie doznają naruszenia, ponieważ wydaje się, że czystsze jest samodzielne radzenie sobie z duplikatem, niż zmuszanie do tego silnika. Moja teoria mówi, że powinieneś ufać, ale weryfikować; na przykład rozważ takie podejście (głównie pseudokod):
JEŚLI NIE ISTNIEJE ([wiersz, który może spowodować naruszenie])BEGIN BEGIN TRY BEGIN TRANSACTION; WSTAW ()... POTWIERDZENIE TRANSAKCJI; END TRY BEGIN CATCH -- cóż, i tak popełniliśmy naruszenie; -- Domyślam się, że wstawiono nowy wiersz lub -- zaktualizowano, ponieważ wykonaliśmy sprawdzenie TRANSAKCJI WYCOFANIA; KOŃCOWE ZGŁOSZENIE
Wiemy, że IF NOT EXISTS sprawdzenie nie gwarantuje, że ktoś inny nie wstawi wiersza do czasu, gdy dotrzemy do INSERT (chyba że umieścimy na stole agresywne blokady i/lub użyjemy SERIALIZABLE ), ale zewnętrzna kontrola uniemożliwia nam próbę popełnienia niepowodzenia, a następnie wycofania. Pozostajemy z dala od całego TRY/CATCH struktury, jeśli już wiemy, że INSERT nie powiedzie się i logiczne byłoby założenie, że – przynajmniej w niektórych przypadkach – będzie to bardziej wydajne niż wprowadzenie TRY/CATCH struktura bezwarunkowo. Nie ma to większego sensu w pojedynczym INSERT scenariusz, ale wyobraź sobie przypadek, w którym dzieje się więcej w tym TRY blokowania (i więcej potencjalnych naruszeń, które możesz sprawdzić z wyprzedzeniem, co oznacza jeszcze więcej pracy, którą w innym przypadku będziesz musiał wykonać, a następnie wycofać, jeśli nastąpi późniejsze naruszenie).
Teraz byłoby interesujące zobaczyć, co by się stało, gdybyś użył innego niż domyślnego poziomu izolacji (co omówię w przyszłym poście), szczególnie ze współbieżnością. Jednak w tym poście chciałem zacząć powoli i przetestować te aspekty z jednym użytkownikiem. Utworzyłem tabelę o nazwie dbo.[Objects] , bardzo uproszczona tabela:
CREATE TABLE dbo.[Obiekty]( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY);GO
Chciałem wypełnić tę tabelę 100 000 wierszy przykładowych danych. Aby wartości w kolumnie nazwy były unikatowe (ponieważ PK jest ograniczeniem, które chciałem naruszyć), stworzyłem funkcję pomocniczą, która pobiera liczbę wierszy i minimalny ciąg znaków. Minimalny ciąg znaków będzie używany do upewnienia się, że albo (a) zestaw rozpoczął się poza maksymalną wartością w tabeli Obiekty, albo (b) zestaw zaczął się od minimalnej wartości w tabeli Obiekty. (Wskażę je ręcznie podczas testów, zweryfikowane po prostu przez sprawdzenie danych, chociaż prawdopodobnie mogłem wbudować to sprawdzenie w funkcję.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32))RETURNS TABLEAS RETURN ( SELECT TOP (@n) name =name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn =ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b GDZIE a.name>=@minString AND b.name>=@minString ) AS x );Idź
To stosuje CROSS JOIN z sys.all_objects na siebie, dodając unikalny numer wiersza do każdej nazwy, tak aby pierwsze 10 wyników wyglądało tak:
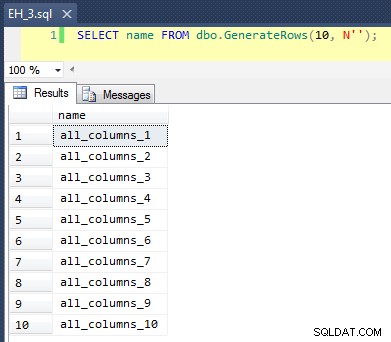
Wypełnienie tabeli 100 000 wierszy było proste:
WSTAW dbo.[Obiekty](nazwa) WYBIERZ nazwę FROM dbo.GenerateRows(100000, N'') ORDER BY name;GO
Teraz, ponieważ zamierzamy wstawić nowe unikalne wartości do tabeli, stworzyłem procedurę czyszczenia na początku i na końcu każdego testu – oprócz usuwania wszystkich dodanych przez nas wierszy, zostanie ona również wyczyszczona pamięć podręczna i bufory. Oczywiście nie jest to coś, co chcesz zakodować w procedurze w swoim systemie produkcyjnym, ale całkiem dobrze do lokalnego testowania wydajności.
UTWÓRZ PROCEDURĘ dbo.EH_Cleanup-- P.S. „EH” oznacza obsługę błędów, a nie „Eh?” ASBEGIN SET NOCOUNT ON; DELETE dbo.[Obiekty] WHERE ObjectID> 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS;ENDGO
Stworzyłem również tabelę dziennika, aby śledzić czas rozpoczęcia i zakończenia każdego testu:
CREATE TABLE dbo.RunTimeLog( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) );Idź
Wreszcie testowa procedura składowana obsługuje różne rzeczy. Mamy trzy różne metody obsługi błędów, jak opisano w powyższych punktach:„JustInsert”, „Rollback” i „TryCatch”; mamy również trzy różne typy wstawiania:(1) wszystkie wstawienia się powiodły (wszystkie wiersze są unikalne), (2) wszystkie wstawienia kończą się niepowodzeniem (wszystkie wiersze są duplikatami) i (3) połówki wstawiają się pomyślnie (połowa wierszy jest unikalna, a połowa wiersze są duplikatami). W połączeniu z tym są dwa różne podejścia:sprawdź naruszenie przed próbą wstawienia lub po prostu idź dalej i pozwól silnikowi określić, czy jest to prawidłowe. Pomyślałem, że to da dobre porównanie różnych technik obsługi błędów w połączeniu z różnymi prawdopodobieństwami kolizji, aby zobaczyć, czy wysoki lub niski procent kolizji miałby znaczący wpływ na wyniki.
Do tych testów wybrałem 40 000 wierszy jako moją całkowitą liczbę prób wstawienia, a w procedurze wykonałem połączenie 20 000 unikalnych lub nieunikatowych rzędów z 20 000 innych unikalnych lub nieunikatowych rzędów. Widać, że na stałe zakodowałem ciągi odcięcia w procedurze; pamiętaj, że w twoim systemie te odcięcia prawie na pewno wystąpią w innym miejscu.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT =20000ASBEGIN SET NOCOUNT ON; -- wyczyść wszystkie nowe wiersze i usuń bufory/wyczyść pamięć podręczną proc EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT =1, @LogID INT; -- wygeneruj nowy wpis w dzienniku INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; USTAW @LogID =SCOPE_IDENTITY(); -- jeśli chcemy, aby wszystko się powiodło, potrzebujemy zestawu danych -- który zawiera 40 000 wierszy, z których wszystkie są niepowtarzalne. Tak więc suma numer dwa — zestawy, z których każdy jest oddalony od siebie o>=20 000 wierszy i nie — już istnieją w tabeli podstawowej:IF @InsertType ='AllSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @CutoffString2 =N'dm_clr_properties_1398 '; -- jeśli chcemy, aby wszystkie zawiodły, to jest to łatwe, możemy po prostu -- połączyć dwa zestawy, które zaczynają się w tym samym miejscu co początkowe -- populacja:IF @InsertType ='AllFail' SELECT @CutoffString1 =N'', @CutoffString2 =N''; -- a jeśli chcemy, aby połowa się powiodła, potrzebujemy 20 000 unikalnych -- wartości i 20 000 duplikatów:IF @InsertType ='HalfSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @CutoffString2 =N''; DECLARE c KURSOR LOKALNY STATYCZNY FORWARD_ONLY READ_ONLY FOR SELECT nazwa FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT nazwa FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OTWARTE c; FETCH NEXT FROM c DO @Name; WHILE @@FETCH_STATUS =0 BEGIN SET @Continue =1; -- wpiszmy podstawowy blok kodu tylko wtedy, gdy -- musimy sprawdzić, a czek zwróci pusty -- (innymi słowy, nie próbuj w ogóle, jeśli mamy -- duplikat, ale sprawdź tylko, czy nie ma duplikatu - - w niektórych przypadkach:IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name =@Name) SET @Continue =0; END IF @Continue =1 BEGIN -- po prostu pozwól silnikowi catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Obiekty](nazwa) SELECT @name;END -- rozpocznij transakcję, ale pozwól silnikowi wyłapać IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo. [Obiekty](nazwa) SELECT @nazwa IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION END ELSE BEGIN COMMIT TRANSACTION END END -- użyj try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Obiekty](nazwa) SELECT @Nazwa; POTWIERDZENIE TRANSAKCJI; KONIEC SPRÓBUJ ROZPOCZNIJ CATCH TRANSAKCJA WYCOFANIA; END CATCH END END FETCH NEXT FROM c INTO @Name; KONIEC ZAMKNIJ c; ZWOLNIJ PRZYDZIELENIE c; -- zaktualizuj wpis w dzienniku UPDATE dbo.RunTimeLog SET EndDate =SYSUTCDATETIME() WHERE LogID =@LogID; -- wyczyść wszystkie nowe wiersze i usuń bufory/wyczyść pamięć podręczną proc EXEC dbo.EH_Cleanup;ENDGO
Teraz możemy wywołać tę procedurę z różnymi argumentami, aby uzyskać różne zachowanie, którego szukamy, próbując wstawić 40 000 wartości (i oczywiście wiedząc, ile powinno się udać lub nie w każdym przypadku). Dla każdej „metody obsługi błędów” (wystarczy spróbować wstawić, użyć begin tran/rollback lub try/catch) i każdego typu wstawiania (wszystko się powiodło, połowa się powiodła i żaden się nie powiódł) w połączeniu z tym, czy należy sprawdzić, czy nie doszło do naruszenia po pierwsze, daje nam to 18 kombinacji:
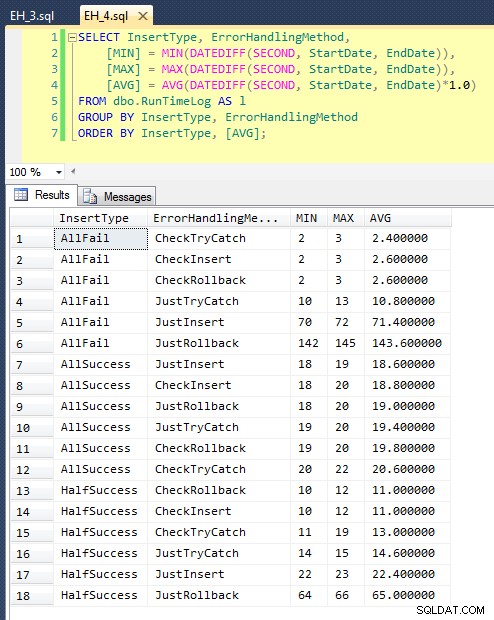
EXEC dbo.EH_Wstaw „JustInsert”, „AllSuccess”, 20000;EXEC dbo.EH_Insert „JustInsert”, „HalfSuccess”, 20000;EXEC dbo.EH_Insert „JustInsert”, 20000; EXEC dbo.EH_Insert „JustTryCatch”, „AllSuccess”, 20000;EXEC dbo.EH_Insert „JustTryCatch”, „HalfSuccess”, 20000;EXEC dbo.EH_Insert „JustTryCatch”, 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'JustRollback', 'AllFail' EXEC dbo.EH_Insert „CheckInsert”, „AllSuccess”, 20000;EXEC dbo.EH_Insert „CheckInsert”, „HalfSuccess”, 20000;EXEC dbo.EH_Insert „CheckInsert”, „AllFail”, 20000; EXEC dbo.EH_Insert „CheckTryCatch”, „AllSuccess”, 20000;EXEC dbo.EH_Insert „CheckTryCatch”, „HalfSuccess”, 20000;EXEC dbo.EH_Insert „CheckTryCatch”, 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'CheckRollback', 'AllFail>, 20000;Po uruchomieniu tego (zajmuje to około 8 minut w moim systemie) mamy wyniki w naszym logu. Przeprowadziłem całą partię pięć razy, aby upewnić się, że otrzymaliśmy przyzwoite średnie i wygładzić wszelkie anomalie. Oto wyniki:
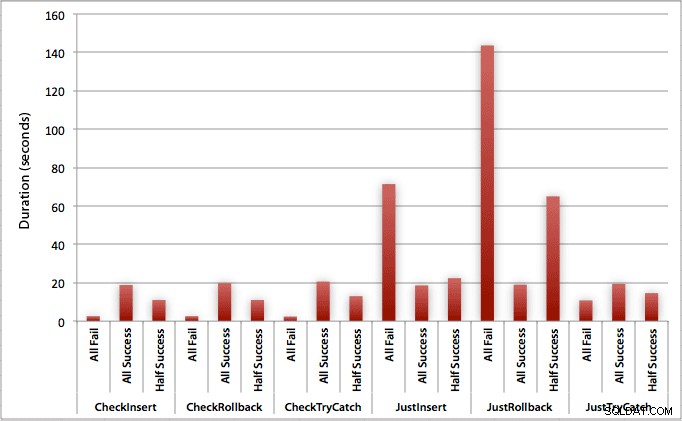
Wykres przedstawiający wszystkie czasy trwania jednocześnie pokazuje kilka poważnych wartości odstających:
Widać, że w przypadkach, w których spodziewamy się wysokiego wskaźnika niepowodzeń (w tym teście 100%), rozpoczęcie transakcji i wycofanie jest zdecydowanie najmniej atrakcyjnym podejściem (3,59 milisekundy na próbę), przy jednoczesnym umożliwieniu podniesienia silnika błąd jest o połowę gorszy (1,785 milisekundy na próbę). Kolejnym najgorszym rozwiązaniem był przypadek, w którym rozpoczynamy transakcję, a następnie ją wycofujemy, w scenariuszu, w którym spodziewamy się, że około połowa prób zakończy się niepowodzeniem (średnio 1,625 milisekundy na próbę). 9 przypadków po lewej stronie wykresu, w których najpierw sprawdzamy naruszenie, nie przekroczyło 0,515 milisekund na próbę.
To powiedziawszy, indywidualne wykresy dla każdego scenariusza (wysoki procent sukcesu, wysoki procent niepowodzenia i 50-50) naprawdę pokazują wpływ każdej metody.
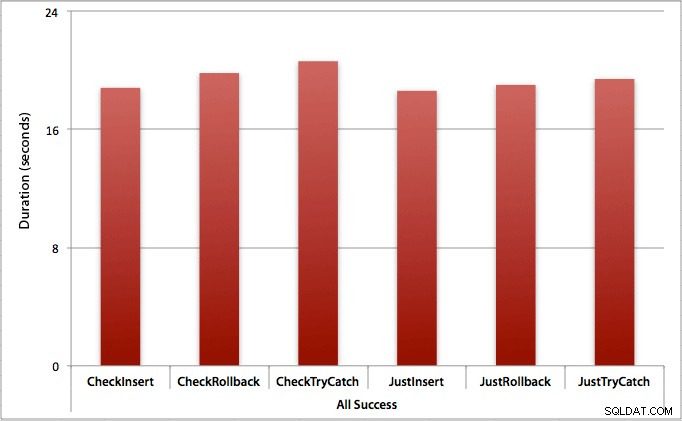
Gdzie wszystkie wstawki kończą się sukcesem
W tym przypadku widzimy, że narzut związany z pierwszym sprawdzeniem naruszenia jest znikomy, ze średnią różnicą 0,7 sekundy w całej partii (lub 125 mikrosekund na próbę wstawienia):
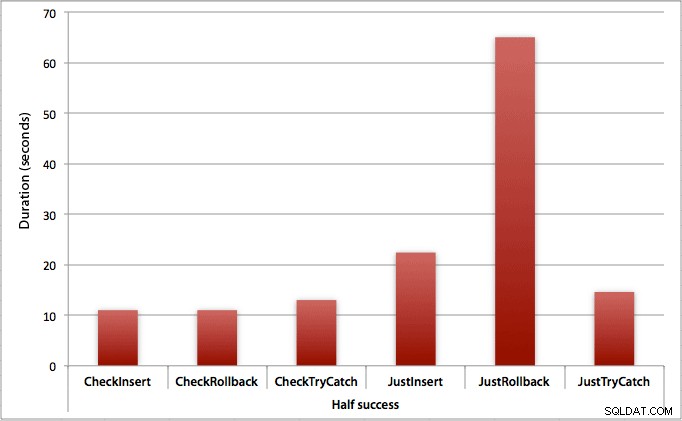
Gdzie udaje się tylko połowa wstawek
Gdy połowa wstawek zawiedzie, widzimy duży skok w czasie trwania metod wstawiania/wycofywania. Scenariusz, w którym rozpoczynamy transakcję i cofamy ją, jest około 6 razy wolniejszy w całej partii w porównaniu do pierwszego sprawdzania (1,625 milisekundy na próbę w porównaniu z 0,275 milisekundy na próbę). Nawet metoda TRY/CATCH jest o 11% szybsza, gdy najpierw sprawdzamy:
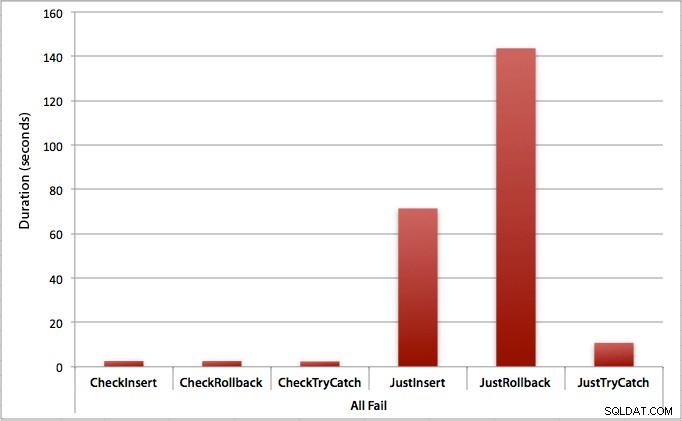
Gdzie wszystkie wstawki zawodzą
Jak można się spodziewać, pokazuje to najbardziej wyraźny wpływ obsługi błędów i najbardziej oczywiste korzyści z pierwszego sprawdzenia. Metoda wycofywania jest prawie 70 razy wolniejsza w tym przypadku, gdy nie sprawdzamy, w porównaniu do tego, kiedy to robimy (3,59 milisekundy na próbę vs. 0,065 milisekundy na próbę):
Co nam to mówi? Jeśli uważamy, że będziemy mieć wysoki wskaźnik awaryjności lub nie mamy pojęcia, jaki będzie nasz potencjalny wskaźnik awaryjności, to sprawdzenie najpierw, aby uniknąć naruszeń w silniku, będzie ogromnie warte naszego czasu. Nawet w przypadku, gdy za każdym razem mamy udaną wkładkę, koszt pierwszego sprawdzenia jest marginalny i łatwo uzasadniony potencjalnym kosztem późniejszej obsługi błędów (chyba że przewidywany wskaźnik awarii wynosi dokładnie 0%).
Myślę więc, że na razie będę się trzymać mojej teorii, że w prostych przypadkach sensowne jest sprawdzenie pod kątem potencjalnego naruszenia, zanim powiesz SQL Serverowi, aby mimo to kontynuował i wstawiał. W przyszłym poście przyjrzę się wpływowi na wydajność różnych poziomów izolacji, współbieżności, a może nawet kilku innych technik obsługi błędów.
[Na marginesie napisałem skróconą wersję tego posta jako wskazówkę dla mssqltips.com w lutym.]