Wspólnym elementem używanym w projektowaniu bazy danych jest ograniczenie. Ograniczenia mają różne smaki (np. domyślne, unikalne) i wymuszają integralność kolumn, w których istnieją. Dobrze zaimplementowane ograniczenia są potężnym elementem w projektowaniu bazy danych, ponieważ zapobiegają przedostawaniu się danych, które nie spełniają określonych kryteriów, do bazy danych. Jednak ograniczenia można naruszyć za pomocą poleceń takich jak WITH NOCHECK i IGNORE_CONSTRAINTS . Ponadto przy użyciu REPAIR_ALLOW_DATA_LOSS opcja z dowolnym DBCC CHECK polecenie naprawy uszkodzenia bazy danych, ograniczenia nie są brane pod uwagę.
W związku z tym w bazie danych mogą znajdować się nieprawidłowe dane — albo dane, które nie są zgodne z ograniczeniem, albo dane, które nie zachowują już oczekiwanej relacji klucza podstawowego i obcego. SQL Server zawiera DBCC CHECKCONSTRAINTS oświadczenie, aby znaleźć dane, które naruszają ograniczenia. Po wykonaniu dowolnej opcji naprawy uruchom DBCC CHECKCONSTRAINTS dla całej bazy danych, aby upewnić się, że nie ma problemów, i może się zdarzyć, że konieczne będzie uruchomienie CHECKCONSTRAINTS dla wybranego wiązania lub tabeli. Utrzymanie integralności danych ma kluczowe znaczenie i chociaż uruchamianie DBCC CHECKCONSTRAINTS nie jest typowe w celu znalezienia nieprawidłowych danych zgodnie z harmonogramem, kiedy trzeba je uruchomić, dobrze jest zrozumieć wpływ, jaki może to mieć na wydajność.
DBCC CHECKCONSTRAINTS można wykonać dla pojedynczego ograniczenia, tabeli lub całej bazy danych. Podobnie jak w przypadku innych poleceń sprawdzających, może to zająć dużo czasu i zużywać zasoby systemowe, szczególnie w przypadku większych baz danych. W przeciwieństwie do innych poleceń sprawdzających, CHECKCONSTRAINTS nie używa migawki bazy danych.
Dzięki rozszerzonym zdarzeniom możemy zbadać wykorzystanie zasobów podczas wykonywania DBCC CHECKCONSTRAINTS do stołu. Aby lepiej pokazać wpływ, uruchomiłem skrypt Create Enlarged AdventureWorks Tables.sql od Jonathana Kehayiasa (blog | @SQLPoolBoy), aby utworzyć większe tabele. Skrypt Jonathana tworzy tylko indeksy dla tabel, więc poniższe stwierdzenia są niezbędne, aby dodać kilka wybranych ograniczeń:
USE [AdventureWorks2012]; GO ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID] FOREIGN KEY([SalesOrderID]) REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID]) ON DELETE CASCADE; GO ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK ADD CONSTRAINT [CK_SalesOrderDetailEnlarged_OrderQty] CHECK (([OrderQty]>(0))) GO ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK ADD CONSTRAINT [CK_SalesOrderDetailEnlarged_UnitPrice] CHECK (([UnitPrice]>=(0.00))); GO ALTER TABLE [Sales].[SalesOrderHeaderEnlarged] WITH CHECK ADD CONSTRAINT [CK_SalesOrderHeaderEnlarged_DueDate] CHECK (([DueDate]>=[OrderDate])) GO ALTER TABLE [Sales].[SalesOrderHeaderEnlarged] WITH CHECK ADD CONSTRAINT [CK_SalesOrderHeaderEnlarged_Freight] CHECK (([Freight]>=(0.00))) GO
Możemy zweryfikować, jakie ograniczenia istnieją za pomocą sp_helpconstraint :
EXEC sp_helpconstraint '[Sales].[SalesOrderDetailEnlarged]'; GO

sp_helpconstraint dane wyjściowe
Gdy ograniczenia istnieją, możemy porównać wykorzystanie zasobów dla DBCC CHECKCONSTRAINTS dla pojedynczego ograniczenia, tabeli i całej bazy danych przy użyciu zdarzeń rozszerzonych. Najpierw utworzymy sesję, która po prostu przechwytuje sp_statement_completed zdarzenia, zawiera sql_text akcja i wysyła dane wyjściowe do ring_buffer :
CREATE EVENT SESSION [Constraint_Performance] ON SERVER
ADD EVENT sqlserver.sp_statement_completed
(
ACTION(sqlserver.database_id,sqlserver.sql_text)
)
ADD TARGET package0.ring_buffer
(
SET max_events_limit=(5000)
)
WITH
(
MAX_MEMORY=32768 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS, MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE, TRACK_CAUSALITY=OFF, STARTUP_STATE=OFF
);
GO
Następnie rozpoczniemy sesję i uruchomimy każdy z DBCC CHECKCONSTRAINT polecenia, a następnie wyprowadź bufor pierścieniowy do tabeli tymczasowej w celu manipulowania. Zauważ, że DBCC DROPCLEANBUFFERS wykonuje się przed każdym sprawdzeniem, tak aby każdy zaczynał się od zimnej pamięci podręcznej, zachowując pole testowania poziomu.
ALTER EVENT SESSION [Constraint_Performance]
ON SERVER
STATE=START;
GO
USE [AdventureWorks2012];
GO
DBCC DROPCLEANBUFFERS;
GO
DBCC CHECKCONSTRAINTS ('[Sales].[CK_SalesOrderDetailEnlarged_OrderQty]') WITH NO_INFOMSGS;
GO
DBCC DROPCLEANBUFFERS;
GO
DBCC CHECKCONSTRAINTS ('[Sales].[FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]') WITH NO_INFOMSGS;
GO
DBCC DROPCLEANBUFFERS;
GO
DBCC CHECKCONSTRAINTS ('[Sales].[SalesOrderDetailEnlarged]') WITH NO_INFOMSGS;
GO
DBCC DROPCLEANBUFFERS;
GO
DBCC CHECKCONSTRAINTS WITH ALL_CONSTRAINTS, NO_INFOMSGS;
GO
DECLARE @target_data XML;
SELECT @target_data = CAST(target_data AS XML)
FROM sys.dm_xe_sessions AS s
INNER JOIN sys.dm_xe_session_targets AS t
ON t.event_session_address = s.[address]
WHERE s.name = N'Constraint_Performance'
AND t.target_name = N'ring_buffer';
SELECT
n.value('(@name)[1]', 'varchar(50)') AS event_name,
DATEADD(HOUR ,DATEDIFF(HOUR, SYSUTCDATETIME(), SYSDATETIME()),n.value('(@timestamp)[1]', 'datetime2')) AS [timestamp],
n.value('(data[@name="duration"]/value)[1]', 'bigint') AS duration,
n.value('(data[@name="physical_reads"]/value)[1]', 'bigint') AS physical_reads,
n.value('(data[@name="logical_reads"]/value)[1]', 'bigint') AS logical_reads,
n.value('(action[@name="sql_text"]/value)[1]', 'varchar(max)') AS sql_text,
n.value('(data[@name="statement"]/value)[1]', 'varchar(max)') AS [statement]
INTO #EventData
FROM @target_data.nodes('RingBufferTarget/event[@name=''sp_statement_completed'']') AS q(n);
GO
ALTER EVENT SESSION [Constraint_Performance]
ON SERVER
STATE=STOP;
GO
Parsowanie ring_buffer do tabeli tymczasowej może zająć trochę więcej czasu (około 20 sekund na moim komputerze), ale wielokrotne odpytywanie danych jest szybsze z tabeli tymczasowej niż za pomocą ring_buffer . Jeśli spojrzymy na dane wyjściowe, zobaczymy, że dla każdego DBCC CHECKCONSTRAINTS wykonywanych jest kilka instrukcji :
SELECT * FROM #EventData WHERE [sql_text] LIKE 'DBCC%';
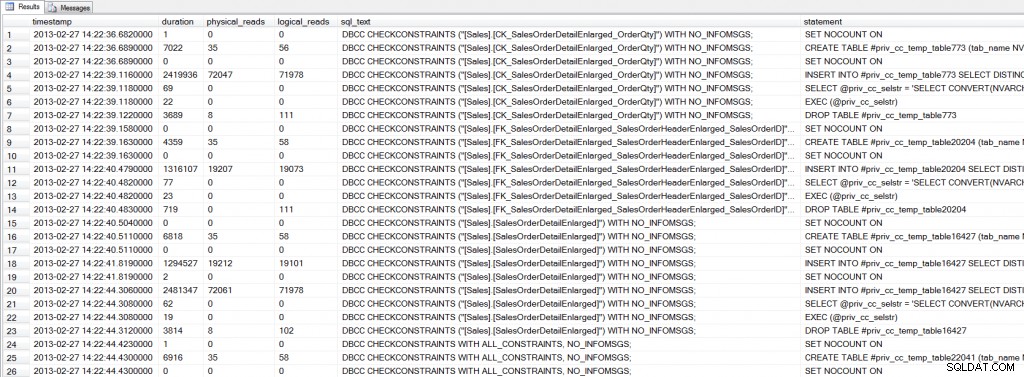
Rozszerzone dane wyjściowe
Używanie zdarzeń rozszerzonych do zagłębienia się w wewnętrzne działanie CHECKCONSTRAINTS to ciekawe zadanie, ale tak naprawdę interesuje nas tutaj zużycie zasobów – w szczególności I/O. Możemy agregować physical_reads dla każdego polecenia sprawdzania, aby porównać I/O:
SELECT [sql_text], SUM([physical_reads]) AS [Total Reads] FROM #EventData WHERE [sql_text] LIKE 'DBCC%' GROUP BY [sql_text];

Zbiorcze operacje we/wy dla czeków
Aby sprawdzić ograniczenie, SQL Server musi odczytać dane, aby znaleźć wiersze, które mogą naruszać ograniczenie. Definicja CK_SalesOrderDetailEnlarged_OrderQty ograniczenie to [OrderQty] > 0 . Ograniczenie klucza obcego, FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID , nawiązuje relację z SalesOrderID między [Sales].[SalesOrderHeaderEnlarged] i [Sales].[SalesOrderDetailEnlarged] tabele. Intuicyjnie mogłoby się wydawać, że sprawdzenie ograniczenia klucza obcego wymagałoby większej liczby operacji we/wy, ponieważ SQL Server musi odczytywać dane z dwóch tabel. Jednak [SalesOrderID] istnieje na poziomie liścia IX_SalesOrderHeaderEnlarged_SalesPersonID indeks nieklastrowy w [Sales].[SalesOrderHeaderEnlarged] tabeli oraz w IX_SalesOrderDetailEnlarged_ProductID indeks [Sales].[SalesOrderDetailEnlarged] stół. W związku z tym SQL Server skanuje te dwa indeksy, aby porównać [SalesOrderID] wartości między dwiema tabelami. Wymaga to nieco ponad 19 000 odczytów. W przypadku CK_SalesOrderDetailEnlarged_OrderQty ograniczenie, [OrderQty] kolumna nie jest zawarta w żadnym indeksie, więc następuje pełne skanowanie indeksu klastrowego, co wymaga ponad 72 000 odczytów.
Gdy wszystkie ograniczenia dla tabeli są sprawdzone, wymagania we/wy są wyższe niż w przypadku sprawdzania pojedynczego ograniczenia i ponownie wzrastają, gdy sprawdzana jest cała baza danych. W powyższym przykładzie [Sales].[SalesOrderHeaderEnlarged] i [Sales].[SalesOrderDetailEnlarged] tabele są nieproporcjonalnie większe niż inne tabele w bazie danych. Nie jest to rzadkie w rzeczywistych scenariuszach; bardzo często bazy danych mają kilka dużych tabel, które stanowią dużą część bazy danych. Podczas uruchamiania CHECKCONSTRAINTS w przypadku tych tabel należy mieć świadomość potencjalnego zużycia zasobów wymaganych do sprawdzenia. Jeśli to możliwe, przeprowadzaj kontrole poza godzinami pracy, aby zminimalizować wpływ na użytkownika. W przypadku, gdy kontrole muszą być przeprowadzane w normalnych godzinach pracy, zrozumienie istniejących ograniczeń i istniejących indeksów wspierających walidację może pomóc w ocenie efektu kontroli. Możesz najpierw przeprowadzić testy w środowisku testowym lub programistycznym, aby zrozumieć wpływ na wydajność, ale mogą wtedy istnieć różnice w zależności od sprzętu, porównywalnych danych itp. Na koniec pamiętaj, że za każdym razem, gdy uruchamiasz polecenie sprawdzające, które zawiera REPAIR_ALLOW_DATA_LOSS opcji, wykonaj naprawę za pomocą DBCC CHECKCONSTRAINTS . Naprawa bazy danych nie uwzględnia żadnych ograniczeń, ponieważ uszkodzenie jest naprawione, więc oprócz potencjalnej utraty danych, możesz otrzymać dane, które naruszają jedno lub więcej ograniczeń w Twojej bazie danych.



