T-SQL Tuesday #78 jest prowadzony przez Wendy Pastrick, a wyzwaniem w tym miesiącu jest po prostu „nauczenie się czegoś nowego i blogowanie o tym”. Jej notka skłania się ku nowym funkcjom SQL Server 2016, ale ponieważ blogowałem i prezentowałem wiele z nich, pomyślałem, że zbadam coś innego z pierwszej ręki, co zawsze mnie naprawdę interesowało.
Widziałem, jak wiele osób twierdzi, że stos może być lepszy niż indeks klastrowy w niektórych sytuacjach. Nie mogę się z tym nie zgodzić. Jednym z interesujących powodów, które zauważyłem, jest to, że wyszukiwanie RID jest szybsze niż wyszukiwanie klucza. Jestem wielkim fanem indeksów klastrowych, a nie stosów, więc czułem, że wymaga to trochę testów.
Więc przetestujmy to!
Pomyślałem, że dobrze byłoby utworzyć bazę danych z dwiema tabelami, identycznymi, z wyjątkiem tego, że jedna ma klastrowany klucz podstawowy, a druga nieklastrowany klucz podstawowy. Czas załadować kilka wierszy do tabeli, zaktualizować kilka wierszy w pętli i wybrać z indeksu (wymuszanie wyszukiwania klucza lub RID).
Specyfikacje systemu
To pytanie często się pojawia, więc aby wyjaśnić ważne szczegóły dotyczące tego systemu, korzystam z 8-rdzeniowej maszyny wirtualnej z 32 GB pamięci RAM, wspieranej przez pamięć masową PCIe. Wersja SQL Server to 2014 SP1 CU6, bez specjalnych zmian konfiguracji lub uruchomionych flag śledzenia:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) — 12.0.4449.0 (X64)13 kwietnia 2016 12:41:07
Prawa autorskie (c) Microsoft Corporation
Developer Edition (64- bit) w systemie Windows NT 6.3
Baza danych
Stworzyłem bazę danych z dużą ilością wolnego miejsca zarówno w pliku danych, jak i pliku dziennika, aby zapobiec zakłócaniu testów przez zdarzenia autogrowu. Ustawiłem również bazę danych na proste odzyskiwanie, aby zminimalizować wpływ na dziennik transakcji.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Stoły
Jak powiedziałem, dwie tabele, z tą różnicą, że klucz podstawowy jest zgrupowany.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Tabela do przechwytywania czasu pracy
Mógłbym monitorować procesor i to wszystko, ale tak naprawdę ciekawostką jest prawie zawsze środowisko uruchomieniowe. Stworzyłem więc tabelę rejestrowania, aby uchwycić czas wykonywania każdego testu:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Test wstawiania
Więc ile czasu zajmuje wstawienie 2000 wierszy, 100 razy? Pobieram dość podstawowe dane z sys.all_objects i ciągnąc definicję dla wszelkich procedur, funkcji itp.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Test aktualizacji
W przypadku testu aktualizacji chciałem po prostu przetestować szybkość zapisywania w indeksie klastrowym w porównaniu ze stertą w sposób bardzo wiersz po wierszu. Wrzuciłem więc 200 losowych wierszy do tabeli #temp, a następnie zbudowałem wokół niej kursor (tabela #temp zapewnia jedynie, że te same 200 wierszy zostanie zaktualizowanych w obu wersjach tabeli, co prawdopodobnie jest przesadą).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Test wyboru
Tak więc powyżej widziałeś, że utworzyłem indeks z Name jako kluczowa kolumna w każdej tabeli; w celu oszacowania kosztu wykonania wyszukiwań dla znacznej ilości wierszy napisałem zapytanie, które przypisuje dane wyjściowe do zmiennej (eliminując sieci I/O i czas renderowania klienta), ale wymusza użycie indeksu:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; W tym przypadku chciałem pokazać kilka interesujących aspektów planów przed zestawieniem wyników testów. Przeprowadzanie ich pojedynczo i łeb w łeb zapewnia następujące wskaźniki porównawcze:

Czas trwania nie ma znaczenia dla pojedynczej instrukcji, ale spójrz na te odczyty. Jeśli korzystasz z wolnego miejsca na dysku, jest to duża różnica, której nie zobaczysz na mniejszą skalę i/lub na dysku SSD do programowania lokalnego.
A potem plany pokazujące dwa różne wyszukiwania za pomocą SQL Sentry Plan Explorer:

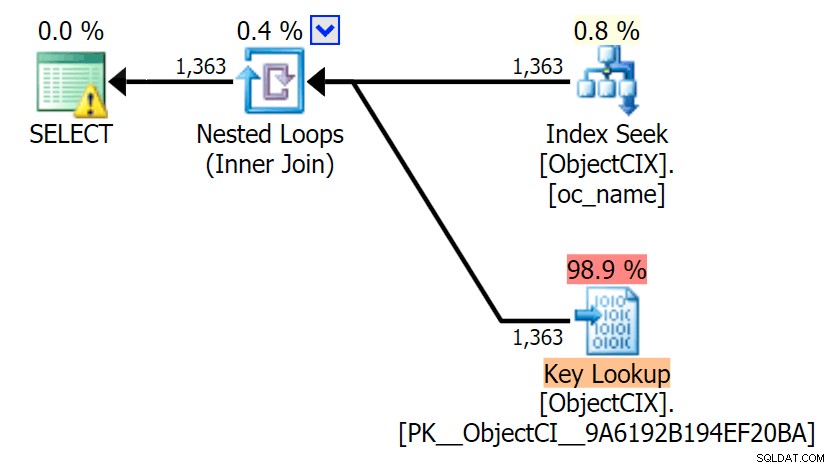
Plany wyglądają prawie identycznie i możesz nie zauważyć różnicy w odczytach w SSMS, chyba że przechwytujesz dane statystyczne we/wy. Nawet szacowane koszty we/wy dla dwóch wyszukiwań były podobne — 1,69 dla wyszukiwania klucza i 1,59 dla wyszukiwania RID. (Ikona ostrzeżenia w obu planach dotyczy brakującego indeksu pokrycia).
Warto zauważyć, że jeśli nie wymusimy wyszukiwania i nie pozwolimy SQL Serverowi zdecydować, co zrobić, w obu przypadkach wybierze standardowe skanowanie – bez ostrzeżenia o braku indeksu i przyjrzymy się, jak bardzo są bliższe odczyty:

Optymalizator wie, że w tym przypadku skanowanie będzie znacznie tańsze niż wyszukiwanie + wyszukiwania. Wybrałem kolumnę LOB do przypisania zmiennych tylko dla efektu, ale wyniki były podobne również przy użyciu kolumny innej niż LOB.
Wyniki testu
Mając tabelę Timings, mogłem łatwo uruchomić testy wiele razy (przeprowadziłem kilkanaście testów), a następnie uzyskać średnie dla testów z następującym zapytaniem:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
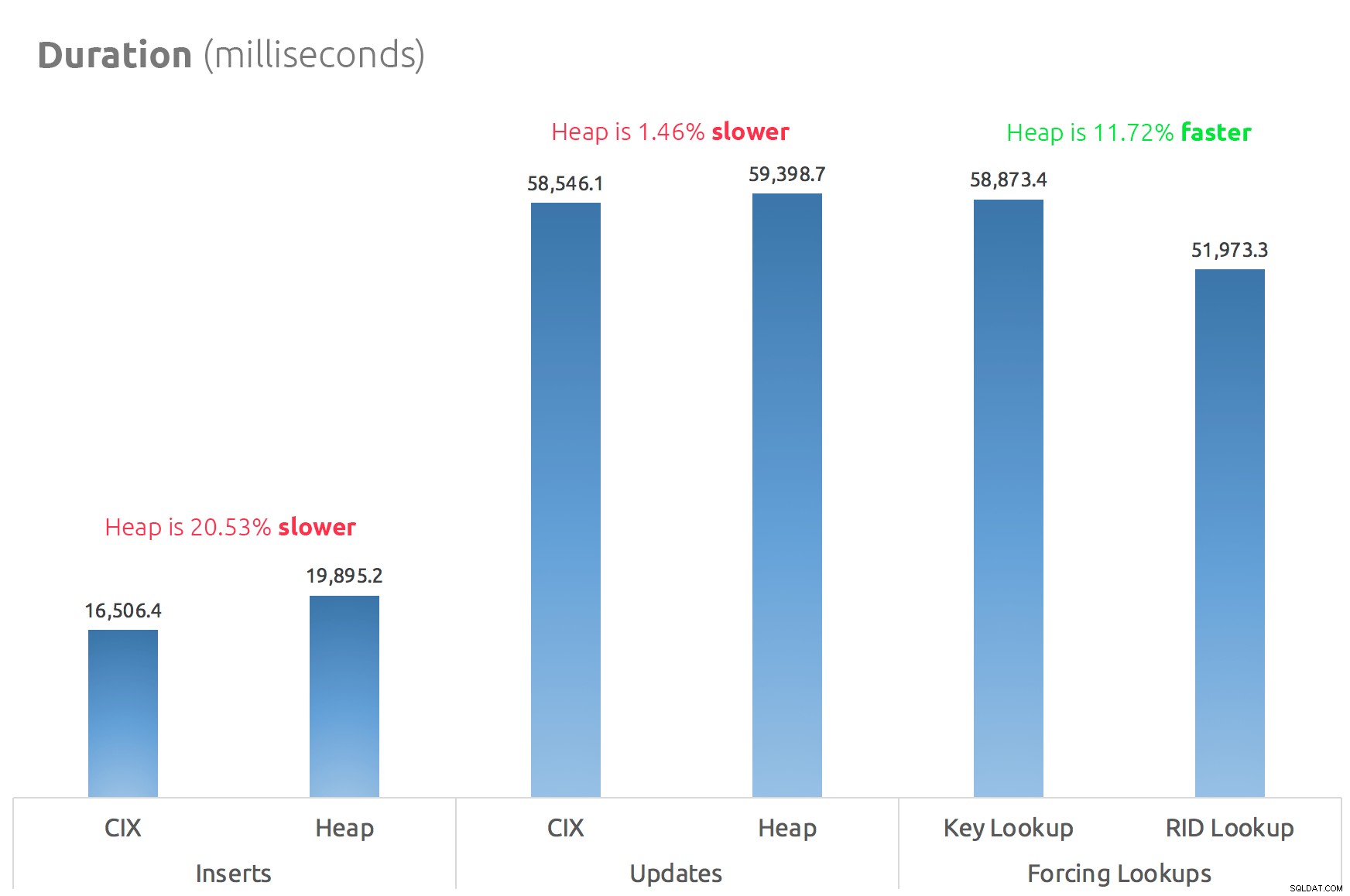
Prosty wykres słupkowy pokazuje ich porównanie:
Wniosek
Tak więc plotki są prawdziwe:przynajmniej w tym przypadku wyszukiwanie RID jest znacznie szybsze niż wyszukiwanie klucza. Przejście bezpośrednio do file:page:slot jest oczywiście bardziej wydajne pod względem I/O niż podążanie za b-drzewo (a jeśli nie korzystasz z nowoczesnej pamięci masowej, delta może być znacznie bardziej zauważalna).
To, czy chcesz z tego skorzystać i wprowadzić wszystkie inne aspekty sterty, będzie zależeć od obciążenia — sterta jest nieco droższa w przypadku operacji zapisu. Ale to nie ostateczne – może się to znacznie różnić w zależności od struktury tabeli, indeksów i wzorców dostępu.
Przetestowałem tutaj bardzo proste rzeczy, a jeśli masz wątpliwości, gorąco polecam przetestowanie rzeczywistego obciążenia na własnym sprzęcie i porównanie dla siebie (i nie zapomnij przetestować tego samego obciążenia, w którym obecne są indeksy pokrywające; prawdopodobnie uzyskasz znacznie lepszą ogólną wydajność, jeśli możesz po prostu całkowicie wyeliminować wyszukiwania). Pamiętaj, aby zmierzyć wszystkie ważne dla Ciebie wskaźniki; tylko dlatego, że skupiam się na czasie trwania, nie oznacza, że jest to ten, na którym najbardziej Ci zależy. :-)