Ten post jest częścią serii artykułów o celach rzędów. Pierwszą część znajdziesz tutaj:
- Część 1:ustalanie i identyfikacja celów wierszy
Stosunkowo dobrze wiadomo, że użycie TOP lub FAST n wskazówka dotycząca zapytania może ustawić cel w wierszu w planie wykonania (zobacz Ustawianie i identyfikacja celów wierszy w planach wykonania, jeśli potrzebujesz odświeżenia na temat celów wierszy i ich przyczyn). Rzadziej zauważa się, że sprzężenia typu semi (i sprzężenia anty) mogą również wprowadzać cel wiersza, chociaż jest to nieco mniej prawdopodobne niż w przypadku TOP , FAST i SET ROWCOUNT .
Ten artykuł pomoże Ci zrozumieć, kiedy i dlaczego sprzężenie semi wywołuje logikę celu wiersza optymalizatora.
Częściowo dołącza
Semi join zwraca wiersz z jednego wejścia złączenia (A), jeśli istnieje co najmniej jedno pasujący wiersz na drugim wejściu złączenia (B).
Podstawowe różnice między sprzężeniem semi a sprzężeniem zwykłym to:
- Złączenie częściowe albo zwraca każdy wiersz z wejścia A, albo nie. Nie może wystąpić duplikacja wierszy.
- Zwykłe sprzężenie duplikuje wiersze, jeśli istnieje wiele dopasowań w predykacie sprzężenia.
- Złączenie częściowe jest zdefiniowane tak, aby zwracać tylko kolumny z wejścia A.
- Zwykłe łączenie może zwracać kolumny z jednego (lub obu) wejść łączenia.
Obecnie T-SQL nie obsługuje bezpośredniej składni, takiej jak FROM A SEMI JOIN B ON A.x = B.y , więc musimy użyć form pośrednich, takich jak EXISTS , SOME/ANY (w tym równoważny skrót IN dla porównań równości) i ustaw INTERSECT .
Powyższy opis sprzężenia częściowego naturalnie wskazuje na zastosowanie celu wiersza, ponieważ interesuje nas znalezienie dowolnego pasującego wiersza w B, a nie wszystkie takie wiersze . Niemniej jednak logiczne semi join wyrażone w T-SQL może nie prowadzić do planu wykonania z wykorzystaniem celu wiersza z kilku powodów, które rozpakujemy dalej.
Transformacja i uproszczenie
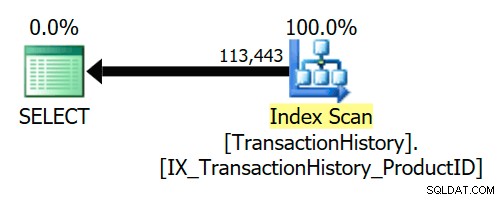
Logiczne sprzężenie pół może zostać uproszczone lub zastąpione czymś innym podczas kompilacji i optymalizacji zapytania. Poniższy przykład AdventureWorks pokazuje, że sprzężenie częściowe zostało całkowicie usunięte z powodu relacji zaufanego klucza obcego:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
Klucz obcy zapewnia, że Product wiersze będą zawsze istniały dla każdego wiersza historii. W rezultacie plan wykonania ma dostęp tylko do TransactionHistory tabela:
Bardziej powszechnym przykładem jest sytuacja, w której sprzężenie pół można przekształcić w sprzężenie wewnętrzne. Na przykład:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
Z planu wykonania wynika, że optymalizator wprowadził agregat (grupowanie na INV.ProductID ), aby upewnić się, że połączenie wewnętrzne może zwrócić tylko Product wiersze raz lub wcale (zgodnie z wymogami semantyki sprzężenia częściowego):
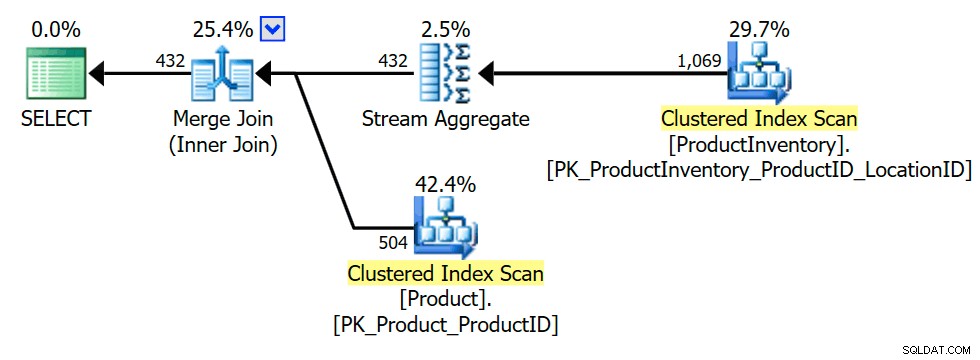
Transformacja do sprzężenia wewnętrznego jest badana wcześnie, ponieważ optymalizator zna więcej sztuczek dotyczących wewnętrznych sprzężeń równorzędnych niż w przypadku sprzężeń semi, co potencjalnie prowadzi do większej liczby możliwości optymalizacji. Oczywiście ostateczny wybór planu jest nadal decyzją opartą na kosztach spośród zbadanych alternatyw.
Wczesne optymalizacje
Chociaż w T-SQL brakuje bezpośredniego SEMI JOIN składni, optymalizator wie wszystko o sprzężeniach typu semi natywnie i może nimi bezpośrednio manipulować. Typowe obejścia składnie semi-join są przekształcane w „prawdziwe” wewnętrzne sprzężenia semi-join na wczesnym etapie procesu kompilacji zapytania (na długo przed rozważeniem nawet trywialnego planu).
Dwie główne grupy składni obejść to EXISTS/INTERSECT i ANY/SOME/IN . EXISTS i INTERSECT przypadki różnią się tylko tym, że ten ostatni ma niejawny DISTINCT (grupowanie na wszystkich rzutowanych słupach). Oba EXISTS i INTERSECT są analizowane jako EXISTS ze skorelowanym podzapytaniem. ANY/SOME/IN wszystkie reprezentacje są interpretowane jako NIEKTÓRE operacje. Możemy zbadać wcześnie tę aktywność optymalizacyjną za pomocą kilku nieudokumentowanych flag śledzenia, które wysyłają informacje o aktywności optymalizatora do zakładki wiadomości SSMS.
Na przykład, semi-join, którego używaliśmy do tej pory, można również zapisać za pomocą IN :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); Drzewo danych wejściowych optymalizatora wygląda następująco:

Operator skalarny ScaOp_SomeComp to SOME porównanie wspomniane powyżej. 2 to kod testu równości, ponieważ IN jest odpowiednikiem = SOME . Jeśli jesteś zainteresowany, istnieją kody od 1 do 6 reprezentujące odpowiednio (<, =, <=,>, !=,>=) operatory porównania.
Wracając do EXISTS składnia, której wolę używać najczęściej do wyrażenia pośredniego sprzężenia semi:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); Drzewo danych wejściowych optymalizatora to:

To drzewo jest dość bezpośrednim tłumaczeniem tekstu zapytania; pamiętaj jednak, że SELECT * został już zastąpiony przez rzut o stałej wartości całkowitej 1 (patrz przedostatni wiersz tekstu).
Następną rzeczą, jaką robi optymalizator, jest rozpakowanie podzapytania w selekcji relacyjnej (=filtr) przy użyciu reguły RemoveSubqInSel . Optymalizator zawsze to robi, ponieważ nie może bezpośrednio operować na podzapytaniach. Rezultatem jest zastosuj (inaczej sprzężenie skorelowane lub boczne):

(Ta sama reguła usuwania podzapytań daje takie same dane wyjściowe dla SOME również drzewo wejściowe).
Następnym krokiem jest przepisanie zgłoszenia jako zwykłego dołączenia za pomocą ApplyHandler rządzić rodziną. Jest to coś, co optymalizator zawsze próbuje zrobić, ponieważ ma więcej reguł eksploracji dla złączeń niż dla zastosowania. Nie każdy wniosek można przepisać jako sprzężenie, ale obecny przykład jest prosty i odnosi sukces:

Zwróć uwagę, że typ sprzężenia jest pozostawiony semi. Rzeczywiście, jest to dokładnie to samo drzewo, które otrzymalibyśmy natychmiast, gdyby obsługiwała składnię T-SQL, taką jak:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; Byłoby miło móc wyrażać zapytania bardziej bezpośrednio w ten sposób. W każdym razie zachęcamy zainteresowanego czytelnika do zbadania powyższych działań upraszczających z innymi logicznie równoważnymi sposobami napisania tego semi-join w T-SQL.
Ważnym wnioskiem na tym etapie jest to, że optymalizator zawsze usuwa podzapytania , zastępując je zastosowaniem. Następnie próbuje przepisać zgłoszenie jako zwykłe sprzężenie, aby zmaksymalizować szanse na znalezienie dobrego planu. Pamiętaj, że wszystko, co poprzednio, ma miejsce, zanim nawet błahy plan zostanie rozważony. Podczas optymalizacji opartej na kosztach optymalizator może również rozważyć łączenie transformacji z powrotem do zastosowania.
Hash i łączenie częściowe
SQL Server ma trzy główne opcje fizycznych implementacji dostępnych dla logicznego sprzężenia częściowego. Dopóki predykat equijoin jest obecny, dostępne są opcje mieszania i łączenia; oba mogą działać w trybach lewego i prawego sprzężenia pół. Złączanie zagnieżdżonych pętli obsługuje tylko lewe (nie prawe) sprzężenie semi, ale nie wymaga predykatu equijoin. Przyjrzyjmy się haszowi i połączmy fizyczne opcje dla naszego przykładowego zapytania (zapisane tym razem jako zbiór przecinający się):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
Optymalizator może znaleźć plan dla wszystkich czterech kombinacji (lewego/prawego) i (mieszającego/scalającego) semi-join dla tego zapytania:
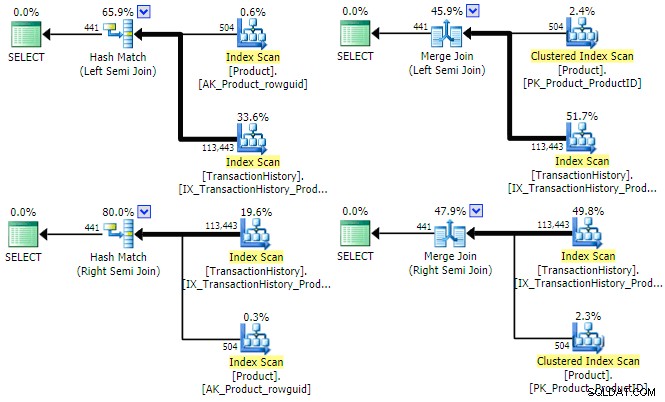
Warto krótko wspomnieć, dlaczego optymalizator może rozważyć zarówno lewe, jak i prawe sprzężenia semi dla każdego typu złączenia. W przypadku łączenia mieszającego, głównym kosztem jest szacowany rozmiar tablicy mieszającej, która zawsze jest początkowo lewą (górną) wartością wejściową. W przypadku scalania semi-join, właściwości każdego wejścia określają, czy zostanie użyte scalanie jeden-do-wielu, czy też mniej wydajne scalanie wiele-do-wielu z tabelą roboczą.
Z powyższych planów wykonania może wynikać, że ani hash, ani scalanie semi-join nie skorzystają na ustaleniu celu wiersza . Oba typy łączenia zawsze testują predykat łączenia w samym łączeniu i dążą do wykorzystania wszystkich wierszy z obu danych wejściowych w celu zwrócenia pełnego zestawu wyników. Nie oznacza to, że ogólnie nie istnieją optymalizacje wydajności dla łączenia mieszającego i scalającego — na przykład oba mogą wykorzystywać mapy bitowe w celu zmniejszenia liczby wierszy docierających do złączenia. Chodzi raczej o to, że cel w wierszu na którymkolwiek z danych wejściowych nie sprawi, że hash lub scalanie semi-join będzie bardziej wydajne.
Zagnieżdżone pętle i zastosuj półzłącze
Pozostały typ łączenia fizycznego to pętle zagnieżdżone, które występują w dwóch odmianach:zwykłe (nieskorelowane) pętle zagnieżdżone i zastosuj zagnieżdżone pętle (czasami określane również jako skorelowane lub boczny dołącz).
Łączenie zwykłych pętli zagnieżdżonych jest podobne do łączenia mieszającego i scalającego, ponieważ predykat łączenia jest oceniany podczas łączenia. Tak jak poprzednio, oznacza to, że nie ma wartości w ustalaniu celu wiersza na żadnym z danych wejściowych. Lewe (górne) dane wejściowe zawsze będą ostatecznie w pełni wykorzystane, a wewnętrzne dane wejściowe nie mają możliwości określenia, które wiersze powinny mieć priorytet, ponieważ nie możemy wiedzieć, czy wiersz się połączy, czy nie, dopóki predykat nie zostanie przetestowany przy łączeniu .
W przeciwieństwie do tego, zastosowanie sprzężenia zagnieżdżonych pętli ma jedno lub więcej odniesień zewnętrznych (parametry skorelowane) na złączeniu, z predykatem złączenia przesuniętym w dół wewnętrzna (dolna) strona połączenia. Stwarza to możliwość użytecznego zastosowania celu wiersza. Przypomnijmy, że semi join wymaga tylko sprawdzenia, czy na wejściu złączenia B istnieje wiersz, który pasuje do bieżącego wiersza na wejściu złączenia A (myślę teraz tylko o strategiach złączenia zagnieżdżonych pętli).
Innymi słowy, w każdej iteracji zastosowania możemy przestać patrzeć na dane wejściowe B, gdy tylko zostanie znalezione pierwsze dopasowanie, używając predykatu złączenia push-down. To jest dokładnie to, do czego cel wiersza jest dobry:generowanie części planu zoptymalizowanego w celu szybkiego zwrócenia pierwszych n pasujących wierszy (gdzie n = 1 tutaj).
Oczywiście bramka w rzędzie może być dobra lub nie, w zależności od okoliczności. Pod tym względem nie ma nic szczególnego w celu semi-join row. Rozważ sytuację, w której wewnętrzna strona sprzężenia częściowego jest bardziej złożona niż pojedynczy prosty dostęp do tabeli, na przykład sprzężenie wielu tabel. Wyznaczenie celu w wierszu może pomóc optymalizatorowi wybrać skuteczną strategię nawigacyjną tylko dla tego konkretnego poddrzewa , znalezienie pierwszego pasującego wiersza, aby spełnić półsprzężenie za pomocą zagnieżdżonych pętli sprzężenia i wyszukiwania indeksu. Bez celu dotyczącego wiersza optymalizator może naturalnie wybrać sprzężenia mieszające lub scalające z sortowaniem, aby zminimalizować oczekiwany koszt zwrócenia wszystkich możliwych wierszy. Zauważ, że istnieje tu założenie, a mianowicie, że ludzie zazwyczaj piszą sprzężenia semi z oczekiwaniem, że wiersz pasujący do warunku wyszukiwania rzeczywiście istnieje. Wydaje mi się to wystarczająco słuszne założenie.
Niezależnie od tego ważnym punktem na tym etapie jest:Tylko zastosuj łączenie zagnieżdżonych pętli ma cel w postaci wiersza zastosowane przez optymalizator (pamiętaj jednak, że cel dotyczący wiersza dla zastosowania łączenia zagnieżdżonych pętli jest dodawany tylko wtedy, gdy cel wiersza jest mniejszy niż oszacowanie bez niego). Przyjrzymy się kilku praktycznym przykładom, aby miejmy nadzieję, że wszystko będzie jasne w następnej kolejności.
Przykłady półzłączy zagnieżdżonych pętli
Poniższy skrypt tworzy dwie tymczasowe tabele sterty. Pierwsza ma numery od 1 do 20 włącznie; druga ma 10 kopii każdego numeru z pierwszej tabeli:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; Bez indeksów i ze stosunkowo małą liczbą wierszy, optymalizator wybiera implementację zagnieżdżonych pętli (zamiast mieszania lub scalania) dla następującego zapytania semi-join). Nieudokumentowane flagi śledzenia pozwalają nam zobaczyć drzewo wyjściowe optymalizatora i informacje o celu wiersza:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
Szacowany plan wykonania obejmuje sprzężenie zagnieżdżonych pętli semi-join, z 200 wierszami na pełne skanowanie tabeli #E2 . 20 iteracji pętli daje w sumie szacunkową liczbę 4000 wierszy:
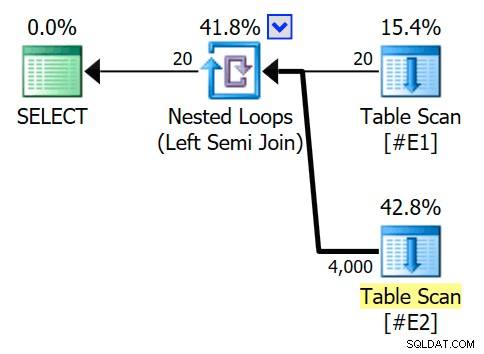
Właściwości operatora zagnieżdżonych pętli pokazują, że predykat jest stosowany przy łączeniu co oznacza, że jest to nieskorelowane połączenie zagnieżdżonych pętli :
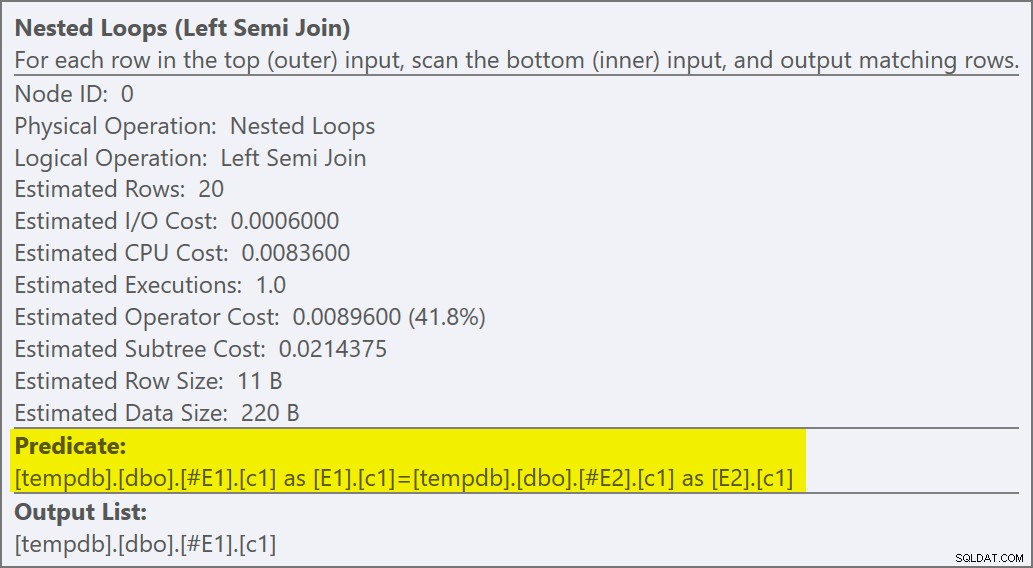
Dane wyjściowe flagi śledzenia (na karcie wiadomości SSMS) pokazują półsprzężenie zagnieżdżonych pętli i brak celu wiersza (RowGoal 0):

Należy zauważyć, że plan powykonawczy dla tego zapytania dotyczącego zabawek nie pokaże łącznie 4000 wierszy odczytanych z tabeli nr E2. Częściowe sprzężenie zagnieżdżonych pętli (skorelowane lub nie) przestanie szukać większej liczby wierszy po wewnętrznej stronie (na iterację), gdy tylko zostanie napotkane pierwsze dopasowanie dla bieżącego wiersza zewnętrznego. Teraz kolejność wierszy napotkanych podczas skanowania stosu #E2 w każdej iteracji jest niedeterministyczna (i może być inna w każdej iteracji), więc zasadniczo prawie wszystkie wiersze można przetestować w każdej iteracji, w przypadku, gdy pasujący wiersz zostanie napotkany tak późno, jak to możliwe (lub rzeczywiście, w przypadku braku pasującego wiersza, wcale).
Na przykład, jeśli założymy implementację środowiska wykonawczego, w której wiersze są skanowane za każdym razem w tej samej kolejności (np. „kolejność wstawiania”), całkowita liczba wierszy przeskanowanych w tym przykładzie zabawki wyniesie 20 wierszy w pierwszej iteracji, 1 wiersz w drugiej iteracji 2 rzędy w trzeciej iteracji i tak dalej, łącznie 20 + 1 + 2 + (…) + 19 =210 rzędów. Rzeczywiście, prawdopodobnie zaobserwujesz tę sumę, która mówi więcej o ograniczeniach prostego kodu demonstracyjnego niż o czymkolwiek innym. Nie można polegać na kolejności wierszy zwracanych przez nieuporządkowaną metodę dostępu, tak samo jak nie można polegać na pozornie uporządkowanych wynikach zapytania bez najwyższego poziomu ORDER BY klauzula.
Zastosuj półłączenie
Teraz tworzymy indeks nieklastrowy na większej tabeli (aby zachęcić optymalizatora do wybrania zastosowania sprzężenia częściowego) i ponownie uruchamiamy zapytanie:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); Plan wykonania zawiera teraz zastosowanie semi-join, z 1 wierszem na szukanie indeksu (i 20 iteracjami, jak poprzednio):
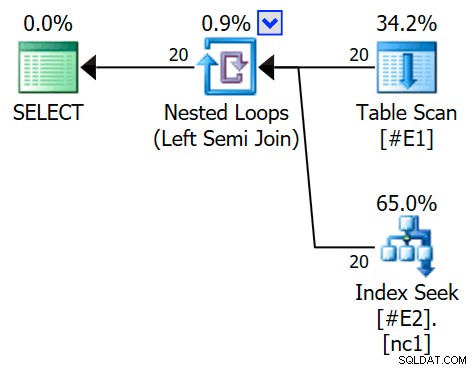
Możemy powiedzieć, że jest to zastosuj sprzężenie częściowe ponieważ właściwości łączenia pokazują odniesienie zewnętrzne zamiast predykatu sprzężenia:
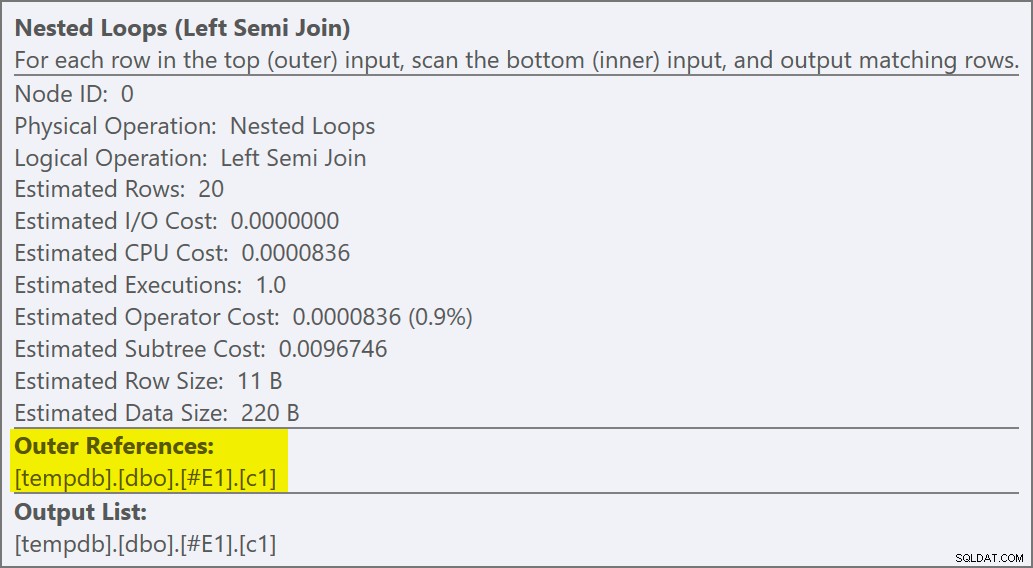
Predykat przyłączenia został przesunięty w dół wewnętrzna strona aplikacji i dopasowana do nowego indeksu:
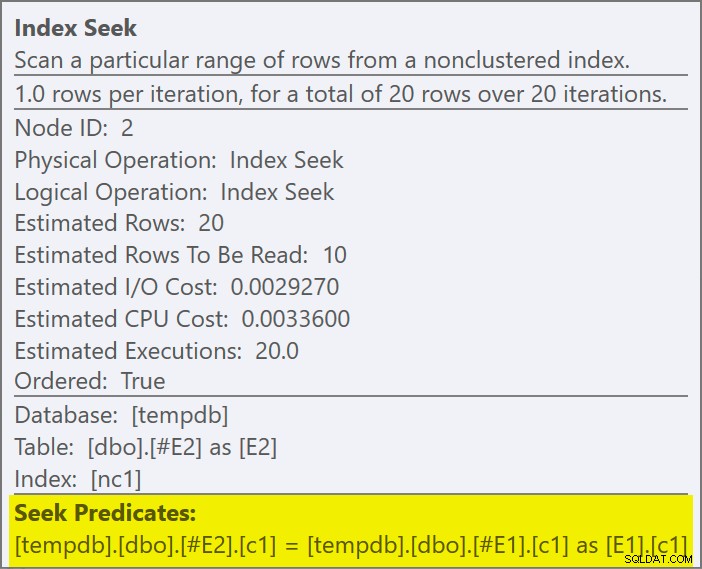
Oczekuje się, że każde wyszukiwanie zwróci 1 wiersz, mimo że każda wartość jest zduplikowana 10 razy w tej tabeli; jest to efekt celu wiersza . Cel wiersza będzie łatwiejszy do zidentyfikowania w kompilacjach SQL Server, które uwidaczniają EstimateRowsWithoutRowGoal atrybut planu (SQL Server 2017 CU3 w momencie pisania tego tekstu). W nadchodzącej wersji Eksploratora planów zostanie to również ujawnione w podpowiedziach dla odpowiednich operatorów:

Dane wyjściowe flagi śledzenia to:
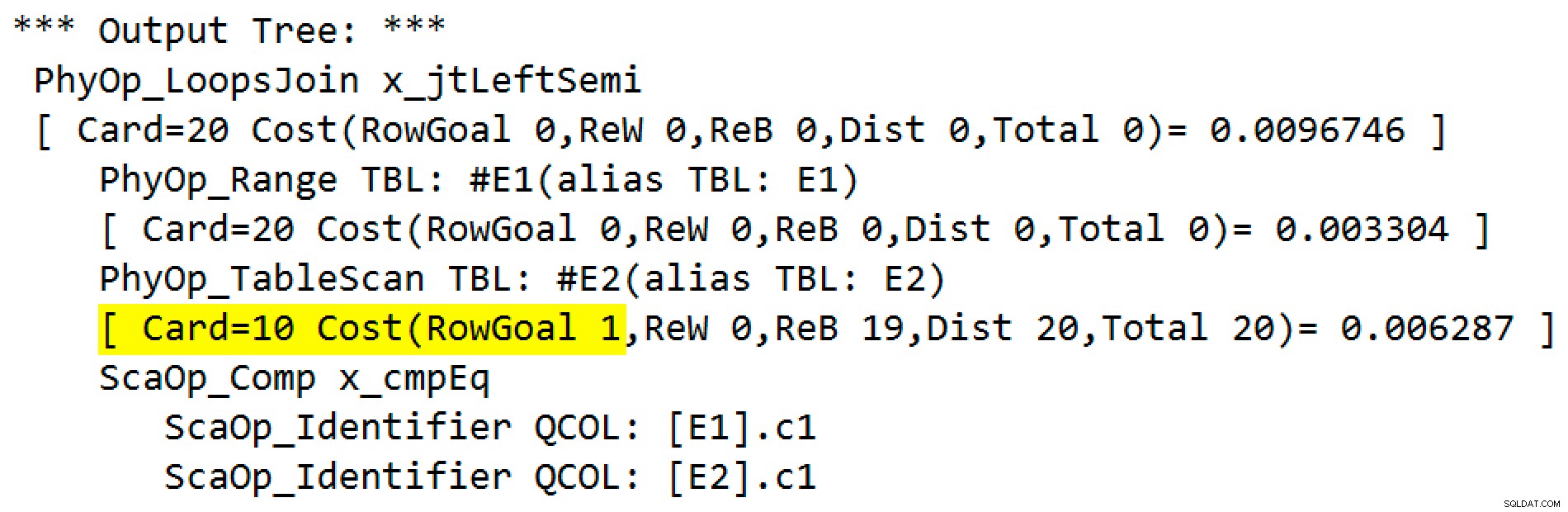
Operator fizyczny zmienił się z sprzężenia w pętli na aplikację działającą w trybie lewego sprzężenia częściowego. Dostęp do tabeli #E2 uzyskał cel rzędu 1 (liczność bez celu rzędu jest pokazana jako 10). Cel wiersza nie jest w tym przypadku wielkim problemem, ponieważ koszt pobrania szacunkowych dziesięciu wierszy na wyszukiwanie nie jest dużo większy niż za jeden wiersz. Wyłączanie celów wierszy dla tego zapytania (przy użyciu flagi śledzenia 4138 lub DISABLE_OPTIMIZER_ROWGOAL wskazówka dotycząca zapytania) nie zmieni kształtu planu.
Niemniej jednak w bardziej realistycznych zapytaniach redukcja kosztów wynikająca z celu związanego z wierszem po stronie wewnętrznej może stanowić różnicę między konkurencyjnymi opcjami implementacji. Na przykład wyłączenie celu wiersza może spowodować, że optymalizator zamiast tego wybierze mieszanie lub scalanie sprzężenia częściowego lub dowolną z wielu innych opcji rozważanych w zapytaniu. Jeśli nic więcej, tutaj cel rzędu dokładnie odzwierciedla fakt, że zastosowanie sprzężenia częściowego przestanie przeszukiwać wewnętrzną stronę, gdy tylko zostanie znaleziony pierwszy mecz i przejdzie do następnego rzędu strony zewnętrznej.
Zauważ, że duplikaty zostały utworzone w tabeli #E2 tak, aby cel zastosowania wiersza semi join był niższy niż normalne oszacowanie (10, z informacji o gęstości statystyk). Jeśli nie było duplikatów, oszacowanie wiersza dla każdego wyszukiwania w #E2 byłby również 1 wierszem, więc cel rzędu 1 nie zostałby zastosowany (pamiętaj o ogólnej zasadzie!)
Gole z rzędu kontra najwyższe
Biorąc pod uwagę, że plany wykonania w ogóle nie wskazują na obecność celu wiersza przed SQL Server 2017 CU3, można by pomyśleć, że jaśniejsze byłoby zaimplementowanie tej optymalizacji przy użyciu jawnego operatora Top, a nie ukrytej właściwości, takiej jak cel wiersza. Pomysł polegałby na tym, aby po prostu umieścić operator Top (1) po wewnętrznej stronie Zastosuj sprzężenie semi/anty, zamiast ustawiać cel wiersza w samym sprzężeniu.
Użycie operatora Top w ten sposób nie byłoby całkowicie bezprecedensowe. Na przykład istnieje już specjalna wersja Top, znana jako górna liczba wierszy, widoczna w planach wykonania modyfikacji danych, gdy niezerowy SET ROWCOUNT obowiązuje (należy zauważyć, że to konkretne użycie jest przestarzałe od 2005 roku, chociaż nadal jest dozwolone w programie SQL Server 2017). Implementacja górnej liczby wierszy jest trochę niezgrabna, ponieważ najwyższy operator jest zawsze wyświetlany jako Top (0) w planie wykonania, niezależnie od obowiązującego rzeczywistego limitu liczby wierszy.
Nie ma przekonującego powodu, dla którego cel zastosowania wiersza sprzężenia częściowego nie mógłby zostać zastąpiony jawnym operatorem Top (1). To powiedziawszy, jest kilka powodów, aby preferować nie robić tego:
- Dodanie wyraźnego Top (1) wymaga więcej wysiłku związanego z kodowaniem optymalizatora i testowania niż dodanie celu wiersza (który jest już używany do innych rzeczy).
- Top nie jest operatorem relacyjnym; optymalizator ma niewielkie wsparcie dla wnioskowania na ten temat. Może to negatywnie wpłynąć na jakość planu, ograniczając zdolność optymalizatora do przekształcania części planu zapytania, np. przenosząc agregaty, związki, filtry i sprzężenia.
- Wprowadzi to ścisłe sprzężenie między zastosowaniem implementacji częściowego sprzężenia a szczytem. Specjalne przypadki i ścisłe sprzężenie to świetne sposoby na wprowadzanie błędów i utrudnienie przyszłych zmian i zwiększenie ich podatności na błędy.
- Góra (1) byłaby logicznie zbędna i byłaby obecna tylko ze względu na efekt uboczny celu w rzędzie.
Ten ostatni punkt warto rozwinąć na przykładzie:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
TOP (1) w istniejącym podzapytaniu jest uproszczone przez optymalizator, dając prosty plan wykonania semi-join:
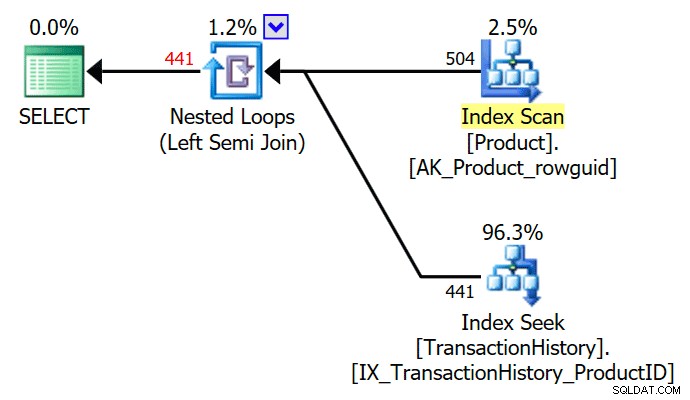
Optymalizator może również usunąć nadmiarowy DISTINCT lub GROUP BY w podzapytaniu. Poniższe wszystkie tworzą ten sam plan, co powyżej:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Podsumowanie i przemyślenia końcowe
Tylko zastosuj Zagnieżdżone pętle semi join mogą mieć cel wiersza ustawiony przez optymalizator. Jest to jedyny typ złączenia, który wypycha predykat(y) złączenia w dół ze złączenia, umożliwiając testowanie pod kątem istnienia dopasowania, które można wykonać wcześnie . Nieskorelowane pętle zagnieżdżone półzłączone prawie nigdy* ustawia cel w wierszu, a nie mieszanie lub scalanie półzłącza. Zastosuj pętle zagnieżdżone można odróżnić od nieskorelowanych pętli zagnieżdżonych łączyć przez obecność odniesień zewnętrznych (zamiast predykatu) na operatorze łączenia zagnieżdżonych pętli dla zastosowania.
Szanse na zobaczenie zastosowania semi-join w ostatecznym planie wykonania zależą w pewnym stopniu od wczesnych działań optymalizacyjnych. Ze względu na brak bezpośredniej składni T-SQL, musimy wyrazić sprzężenia semi w terminach pośrednich. Są one analizowane w drzewo logiczne zawierające podzapytanie, które wczesna aktywność optymalizatora przekształca w zastosowanie, a następnie w nieskorelowane sprzężenie częściowe, jeśli to możliwe.
To działanie upraszczające określa, czy logiczne sprzężenie częściowe jest prezentowane optymalizatorowi opartemu na kosztach jako zastosowanie czy zwykłe sprzężenie częściowe. Gdy przedstawiane jako logiczne zastosuj semi join, CBO jest prawie pewne, że stworzy ostateczny plan wykonania zawierający fizyczne zastosowanie zagnieżdżonych pętli (a więc ustalenie celu wiersza). Po przedstawieniu nieskorelowanego sprzężenia częściowego CBO może rozważ przekształcenie w zastosowanie (lub nie). Ostateczny wybór planu to jak zwykle seria decyzji opartych na kosztach.
Podobnie jak wszystkie cele rzędu, cel rzędu półzłącza może być dobrą lub złą rzeczą dla wydajności. Wiedza, że zastosowanie semi-join wyznacza cel wiersza, pomoże przynajmniej ludziom rozpoznać i rozwiązać przyczynę, jeśli wystąpi problem. Rozwiązaniem nie zawsze (a nawet zwykle) będzie wyłączenie celów wierszy dla zapytania. Często można wprowadzić ulepszenia w indeksowaniu (i/lub zapytaniu), aby zapewnić skuteczny sposób znajdowania pierwszego pasującego wiersza.
Omówię anty-semi-join w osobnym artykule, kontynuując serię bramek rzędowych.
* Wyjątkiem jest półsprzężenie nieskorelowanych zagnieżdżonych pętli bez predykatu złączenia (rzadki widok). To wyznacza cel wiersza.