Ten artykuł jest dwunastą częścią serii poświęconej nazwanym wyrażeniom tabelowym. Do tej pory omówiłem tabele pochodne i CTE, które są nazwanymi wyrażeniami tabelowymi o zasięgu instrukcji, oraz widoki, które są nazwanymi wyrażeniami tabelowymi wielokrotnego użytku. W tym miesiącu przedstawię wbudowane funkcje z wartościami tabelarycznymi (iTVF) i opiszę ich zalety w porównaniu z innymi nazwanymi wyrażeniami tabelowymi. Porównuję je również z procedurami składowanymi, skupiając się głównie na różnicach w zakresie domyślnej strategii optymalizacji oraz planuję buforowanie i zachowanie ponownego użycia. Jeśli chodzi o optymalizację, jest wiele do omówienia, więc rozpocznę dyskusję w tym miesiącu i kontynuuję ją w przyszłym.
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który tworzy i wypełnia go tutaj, oraz jego diagram ER można znaleźć tutaj.
Co to jest wbudowana funkcja z wartościami tabelarycznymi?
W porównaniu z poprzednio omówionymi nazwanymi wyrażeniami tabelowymi, iTVF przypominają głównie widoki. Podobnie jak widoki, iTVF są tworzone jako stały obiekt w bazie danych, a zatem mogą być ponownie wykorzystywane przez użytkowników, którzy mają uprawnienia do interakcji z nimi. Główną zaletą iTVF w porównaniu z widokami jest fakt, że obsługują one parametry wejściowe. Najłatwiej więc opisać iTVF jako widok sparametryzowany, chociaż technicznie tworzy się go za pomocą instrukcji CREATE FUNCTION, a nie za pomocą instrukcji CREATE VIEW.
Ważne jest, aby nie mylić iTVF z wielowyrazowymi funkcjami z wartościami tabelarycznymi (MSTVF). To pierwsze jest nieliniowym nazwanym wyrażeniem tabelowym opartym na pojedynczym zapytaniu podobnym do widoku i jest przedmiotem tego artykułu. Ten ostatni jest modułem programistycznym, który zwraca zmienną tabeli jako wyjście, z przepływem wieloinstrukcyjnym w swoim ciele, którego celem jest wypełnienie zwróconej zmiennej tabeli danymi.
Składnia
Oto składnia T-SQL do tworzenia iTVF:
CREATE [OR ALTER] FUNCTION [
[ (
TABELA ZWROTÓW
[ Z
JAK
POWRÓT
Obserwuj w składni możliwość definiowania parametrów wejściowych.
Cel atrybutu SCHEMABIDNING jest taki sam jak w przypadku widoków i powinien być oceniany na podstawie podobnych rozważań. Aby uzyskać szczegółowe informacje, zobacz część 10 serii.
Przykład
Jako przykład dla iTVF, załóżmy, że musisz utworzyć nazwane wyrażenie tabeli wielokrotnego użytku, które akceptuje jako dane wejściowe identyfikator klienta (@custid) i liczbę (@n) i zwraca żądaną liczbę najnowszych zamówień z tabeli Sales.Orders dla klienta wejściowego.
Nie możesz zaimplementować tego zadania z widokiem, ponieważ widoki nie obsługują parametrów wejściowych. Jak wspomniano, możesz myśleć o iTVF jako o sparametryzowanym widoku i jako taki jest to właściwe narzędzie do tego zadania.
Przed wdrożeniem samej funkcji, oto kod do utworzenia indeksu pomocniczego w tabeli Sales.Orders:
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
A oto kod do utworzenia funkcji o nazwie Sales.GetTopCustOrders:
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Podobnie jak w przypadku tabel i widoków bazowych, gdy jesteś po pobraniu danych, określasz iTVF w klauzuli FROM instrukcji SELECT. Oto przykład żądania trzech ostatnich zamówień dla klienta 1:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
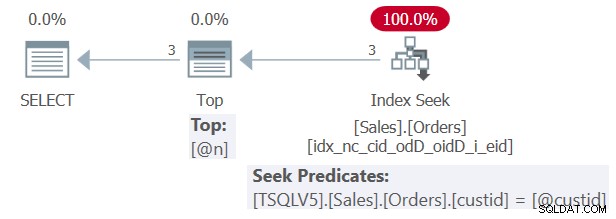
Nazywam ten przykład Zapytanie 1. Plan dla Zapytania 1 pokazano na rysunku 1.
 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Co jest wbudowanego w iTVF?
Jeśli zastanawiasz się nad źródłem terminu inline w wbudowanych funkcjach z wartościami przechowywanymi w tabeli ma to związek z ich optymalizacją. Koncepcja inline ma zastosowanie do wszystkich czterech rodzajów nazwanych wyrażeń tabelowych obsługiwanych przez T-SQL i częściowo obejmuje to, co opisałem w części 4 serii jako rozmieszczanie/podstawianie. Pamiętaj, aby ponownie odwiedzić odpowiednią sekcję w części 4, jeśli potrzebujesz odświeżenia.
Jak widać na rysunku 1, dzięki temu, że funkcja została wbudowana, SQL Server był w stanie stworzyć optymalny plan, który współdziała bezpośrednio z indeksami podstawowej tabeli bazowej. W naszym przypadku plan wykonuje wyszukiwanie w indeksie pomocniczym, który utworzyłeś wcześniej.
iTVF idą o krok dalej w koncepcji inliningu, domyślnie stosując optymalizację osadzania parametrów. Paul White opisuje optymalizację osadzania parametrów w swoim doskonałym artykule Parameter Sniffing, Embedding, and the RECOMPILE Options. W przypadku optymalizacji osadzania parametrów odwołania do parametrów zapytania są zastępowane wartościami stałymi literału z bieżącego wykonania, a następnie kod ze stałymi zostaje zoptymalizowany.
Zauważ w planie na rysunku 1, że zarówno predykat seek operatora Index Seek, jak i górne wyrażenie operatora Top pokazują osadzone wartości stałych literału 1 i 3 z bieżącego wykonania zapytania. Nie pokazują odpowiednio parametrów @custid i @n.
W przypadku iTVF domyślnie używana jest optymalizacja osadzania parametrów. W przypadku procedur składowanych zapytania parametryczne są domyślnie optymalizowane. Aby zażądać optymalizacji osadzania parametrów, należy dodać OPTION(RECOMPILE) do zapytania procedury składowanej. Więcej szczegółów na temat optymalizacji iTVF w porównaniu z procedurami składowanymi, w tym implikacje, wkrótce.
Modyfikowanie danych przez iTVF
Przypomnij sobie z części 11 serii, że o ile spełnione są określone wymagania, nazwane wyrażenia tabelowe mogą być celem instrukcji modyfikacji. Ta zdolność ma zastosowanie do iTVF podobnie do sposobu, w jaki ma zastosowanie do widoków. Na przykład, oto kod, którego możesz użyć do usunięcia trzech ostatnich zamówień klienta 1 (w rzeczywistości tego nie uruchamiaj):
DELETE FROM Sales.GetTopCustOrders(1, 3);
W szczególności w naszej bazie danych próba uruchomienia tego kodu zakończy się niepowodzeniem z powodu wymuszenia integralności referencyjnej (zamówienia, których dotyczy problem, mają powiązane wiersze zamówienia w tabeli Sales.OrderDetails), ale jest to prawidłowy i obsługiwany kod.
iTVF a procedury przechowywane
Jak wspomniano wcześniej, domyślna strategia optymalizacji zapytań dla iTVF jest inna niż dla procedur składowanych. W przypadku iTVF domyślnie używana jest optymalizacja osadzania parametrów. W przypadku procedur składowanych ustawieniem domyślnym jest optymalizacja zapytań parametrycznych podczas stosowania wykrywania parametrów. Aby uzyskać osadzanie parametrów dla zapytania procedury składowanej, musisz dodać OPTION(RECOMPILE).
Jak w przypadku wielu strategii i technik optymalizacji, osadzanie parametrów ma swoje plusy i minusy.
Głównym plusem jest to, że umożliwia uproszczenie zapytań, które czasami mogą skutkować bardziej wydajnymi planami. Niektóre z tych uproszczeń są naprawdę fascynujące. Paul demonstruje to za pomocą przechowywanych procedur w swoim artykule, a ja zademonstruję to za pomocą iTVF w przyszłym miesiącu.
Głównym minusem optymalizacji osadzania parametrów jest brak wydajnego buforowania planów i zachowania ponownego wykorzystania, tak jak w przypadku planów parametrycznych. Z każdą odrębną kombinacją wartości parametrów otrzymujesz odrębny ciąg zapytania, a tym samym oddzielną kompilację, która skutkuje oddzielnym planem w pamięci podręcznej. Dzięki iTVF ze stałymi danymi wejściowymi można uzyskać zachowanie ponownego wykorzystania planu, ale tylko wtedy, gdy powtarzają się te same wartości parametrów. Oczywiście zapytanie procedury składowanej z opcją OPTION(RECOMPILE) nie spowoduje ponownego użycia planu nawet w przypadku powtórzenia tych samych wartości parametrów na żądanie.
Pokażę trzy przypadki:
- Plany wielokrotnego użytku ze stałymi wynikającymi z domyślnej optymalizacji osadzania parametrów dla zapytań iTVF ze stałymi
- Sparametryzowane plany wielokrotnego użytku wynikające z domyślnej optymalizacji sparametryzowanych zapytań procedur składowanych
- Plany jednorazowego użytku ze stałymi wynikającymi z optymalizacji osadzania parametrów dla zapytań procedur składowanych za pomocą OPTION(RECOMPILE)
Zacznijmy od przypadku nr 1.
Użyj następującego kodu, aby wysłać zapytanie do naszego iTVF za pomocą @custid =1 i @n =3:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Przypominamy, że byłoby to drugie wykonanie tego samego kodu, ponieważ wykonałeś go już raz z tymi samymi wartościami parametrów wcześniej, co skutkuje planem pokazanym na rysunku 1.
Użyj następującego kodu, aby wysłać zapytanie do iTVF za pomocą @custid =2 i @n =3 raz:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
Będę odnosić się do tego kodu jako do Zapytania 2. Plan dla Zapytania 2 jest pokazany na rysunku 2.
 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Przypomnijmy, że plan na rysunku 1 dla zapytania 1 odnosił się do stałego identyfikatora klienta 1 w predykacie wyszukiwania, podczas gdy ten plan odnosi się do stałego identyfikatora klienta 2.
Użyj następującego kodu, aby sprawdzić statystyki wykonania zapytania:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
Ten kod generuje następujące dane wyjściowe:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
Utworzono tutaj dwa oddzielne plany:jeden dla zapytania z identyfikatorem klienta 1, który został użyty dwukrotnie, a drugi dla zapytania z identyfikatorem klienta 2, który został użyty raz. Dzięki bardzo dużej liczbie różnych kombinacji wartości parametrów otrzymasz dużą liczbę kompilacji i planów w pamięci podręcznej.
Przejdźmy do przypadku nr 2:domyślna strategia optymalizacji zapytań sparametryzowanych procedur składowanych. Użyj następującego kodu, aby umieścić nasze zapytanie w procedurze składowanej o nazwie Sales.GetTopCustOrders2:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Użyj następującego kodu, aby wykonać procedurę składowaną z @custid =1 i @n =3 dwukrotnie:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Pierwsze wykonanie uruchamia optymalizację zapytania, czego wynikiem jest sparametryzowany plan pokazany na rysunku 3:
 Rysunek 3:Plan sprzedaży.GetTopCustOrders2 proc
Rysunek 3:Plan sprzedaży.GetTopCustOrders2 proc
Zwróć uwagę na odniesienie do parametru @custid w predykacie wyszukiwania i do parametru @n w górnym wyrażeniu.
Użyj następującego kodu, aby wykonać procedurę składowaną z @custid =2 i @n =3 raz:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Zbuforowany sparametryzowany plan pokazany na rysunku 3 jest ponownie używany.
Użyj następującego kodu, aby sprawdzić statystyki wykonania zapytania:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Ten kod generuje następujące dane wyjściowe:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Tylko jeden sparametryzowany plan został utworzony i zapisany w pamięci podręcznej i użyty trzy razy, pomimo zmieniających się wartości identyfikatora klienta.
Przejdźmy do przypadku nr 3. Jak wspomniano, w przypadku zapytań procedury składowanej można uzyskać optymalizację osadzania parametrów podczas korzystania z opcji OPTION(RECOMPILE). Użyj następującego kodu, aby zmienić zapytanie procedury, aby uwzględnić tę opcję:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
Wykonaj proc z @custid =1 i @n =3 dwa razy:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Otrzymasz taki sam plan, jak pokazano wcześniej na rysunku 1, z osadzonymi stałymi.
Wykonaj proc z @custid =2 i @n =3 raz:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Otrzymujesz taki sam plan, jak pokazano wcześniej na Rysunku 2, z osadzonymi stałymi.
Sprawdź statystyki wykonania zapytania:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Ten kod generuje następujące dane wyjściowe:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Licznik egzekucji pokazuje 1, odzwierciedlając tylko ostatnią egzekucję. SQL Server buforuje ostatnio wykonany plan, dzięki czemu może wyświetlać statystyki tego wykonania, ale na żądanie nie wykorzystuje ponownie planu. Jeśli sprawdzisz plan pokazany pod atrybutem query_plan, okaże się, że jest to ten utworzony dla stałych w ostatnim wykonaniu, pokazanym wcześniej na rysunku 2.
Jeśli zależy Ci na mniejszej liczbie kompilacji i wydajnym buforowaniu planów oraz zachowaniu ponownego wykorzystania, najlepszym rozwiązaniem jest domyślne podejście do optymalizacji procedur składowanych sparametryzowanych zapytań.
Implementacja oparta na iTVF ma dużą przewagę nad implementacją opartą na procedurach składowanych — gdy trzeba zastosować funkcję do każdego wiersza w tabeli i przekazać kolumny z tabeli jako dane wejściowe. Załóżmy na przykład, że musisz zwrócić trzy najnowsze zamówienia dla każdego klienta w tabeli Sales.Customers. Żadna konstrukcja zapytania nie umożliwia zastosowania procedury składowanej na wiersz w tabeli. Możesz zaimplementować rozwiązanie iteracyjne z kursorem, ale zawsze jest dobry dzień, kiedy możesz uniknąć kursorów. Łącząc operatora APPLY z wywołaniem iTVF, możesz wykonać zadanie ładnie i czysto, tak jak:
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
Ten kod generuje następujące dane wyjściowe (w skrócie):
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
Wywołanie funkcji zostaje wbudowane, a odwołanie do parametru @custid jest zastępowane korelacją C.custid. Daje to plan pokazany na rysunku 4.
 Rysunek 4:Plan zapytania z APPLY i Sales.GetTopCustOrders iTVF
Rysunek 4:Plan zapytania z APPLY i Sales.GetTopCustOrders iTVF
Plan skanuje indeks w tabeli Sales.Customers w celu uzyskania zestawu identyfikatorów klientów i stosuje wyszukiwanie w indeksie pomocniczym utworzonym wcześniej w Sales.Orders per customer. Jest tylko jeden plan, ponieważ funkcja została umieszczona w zapytaniu zewnętrznym, zamieniając się w sprzężenie skorelowane lub boczne. Ten plan jest bardzo wydajny, zwłaszcza gdy kolumna custid w Sales.Orders jest bardzo gęsta, co oznacza, że istnieje niewielka liczba odrębnych identyfikatorów klientów.
Oczywiście istnieją inne sposoby realizacji tego zadania, takie jak użycie CTE z funkcją ROW_NUMBER. Takie rozwiązanie sprawdza się lepiej niż to oparte na ZASTOSUJ, gdy kolumna custid w tabeli Sales.Orders ma niską gęstość. Tak czy inaczej, konkretne zadanie, którego użyłem w moich przykładach, nie jest tak ważne dla celów naszej dyskusji. Chodziło mi o wyjaśnienie różnych strategii optymalizacji stosowanych przez SQL Server za pomocą różnych narzędzi.
Kiedy skończysz, użyj następującego kodu do czyszczenia:
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
Podsumowanie i co dalej
Więc czego się z tego nauczyliśmy?
iTVF to sparametryzowane nazwane wyrażenie tabelowe wielokrotnego użytku.
SQL Server używa domyślnie strategii optymalizacji osadzania parametrów z iTVF oraz strategii optymalizacji zapytań parametrycznych z zapytaniami procedur składowanych. Dodanie opcji OPTION(RECOMPILE) do zapytania procedury składowanej może spowodować optymalizację osadzania parametrów.
Jeśli chcesz uzyskać mniej kompilacji i wydajne buforowanie planów oraz zachowanie ponownego wykorzystania, dobrym rozwiązaniem są plany sparametryzowanych zapytań procedur.
Plany zapytań iTVF są buforowane i mogą być ponownie użyte, o ile powtarzają się te same wartości parametrów.
Możesz wygodnie połączyć użycie operatora ZASTOSUJ i iTVF, aby zastosować iTVF do każdego wiersza z lewej tabeli, przekazując kolumny z lewej tabeli jako dane wejściowe do iTVF.
Jak wspomniano, jest wiele do omówienia na temat optymalizacji iTVF. W tym miesiącu porównałem iTVF i procedury składowane pod kątem domyślnej strategii optymalizacji oraz zaplanowałem zachowanie pamięci podręcznej i ponowne użycie. W przyszłym miesiącu zagłębię się w uproszczenia wynikające z optymalizacji osadzania parametrów.