Czasami zdarza się, że masz bardzo duży plik tekstowy lub CSV do przetworzenia, ale najpierw chcesz zrobić mniejsze pliki z tego dużego pliku. Ponieważ przetworzenie lub otwarcie tego dużego pliku może zająć zbyt dużo czasu. Więc podaję poniżej przykład, jak podzielić duży plik tekstowy/CSV na wiele plików w PL SQL przy użyciu procedury składowanej.
Musisz tylko przekazać dwa parametry do tej procedury PL SQL, pierwszy to nazwa obiektu katalogu bazy danych, w którym znajdują się pliki tekstowe, a drugi to nazwa pliku źródłowego (plik, który chcesz podzielić).
Jeśli obiekt katalogu Oracle nie istnieje dla lokalizacji plików tekstowych, możesz go utworzyć, jak pokazano poniżej:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Zmień powyższą ścieżkę zgodnie z lokalizacją plików. Następnie utwórz poniższą procedurę, wykonując jej skrypt:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Ta procedura dzieli 100 wierszy na każdy plik, który możesz modyfikować zgodnie z potrzebami. Teraz wykonaj tę procedurę, jak pokazano poniżej, przekazując nazwę obiektu katalogu bazy danych i nazwę pliku:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
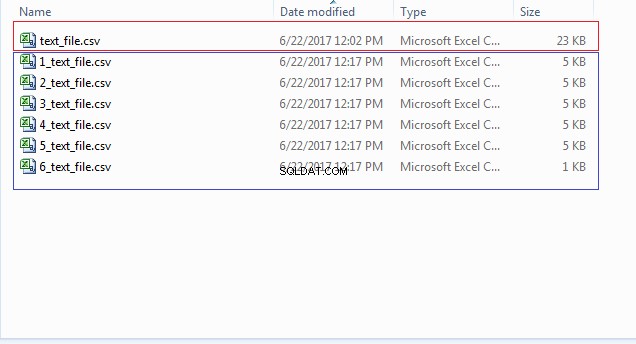
END; Możesz sprawdzić lokalizację pliku (CSV_FILE_DIR) pod kątem wielu plików zaczynających się od numerów, takich jak 1_text_file.csv, 2_text_file.csv i tak dalej, jak pokazano na poniższym obrazku: