Badamy migrację bazy danych Oracle z instancji EC2 do zarządzanej usługi RDS. W pierwszym z czterech artykułów, „Migracja bazy danych Oracle z AWS EC2 do AWS RDS, część 1”, stworzyliśmy instancje baz danych na EC2 i RDS. W drugim artykule, „Migracja bazy danych Oracle z AWS EC2 do AWS RDS, część 2”, utworzyliśmy użytkownika uprawnień do migracji bazy danych, a także stworzyliśmy tabelę bazy danych do migracji. Tylko w drugim artykule stworzyliśmy instancję replikacji i punkty końcowe replikacji. W trzecim artykule, „Migracja bazy danych Oracle z AWS EC2 do AWS RDS, część 3”, stworzyliśmy zadanie migracji w celu migracji istniejących zmian. W dalszej części artykułu będziemy migrować bieżące zmiany w danych. Ten artykuł ma następujące sekcje:
- Tworzenie i uruchamianie zadania replikacji w celu migracji bieżących zmian
- Dodawanie dodatkowego rejestrowania
- Dodawanie tabeli do instancji bazy danych Oracle w EC2
- Dodawanie danych tabeli
- Eksplorowanie zreplikowanej tabeli bazy danych
- Upuszczanie i ponowne ładowanie danych
- Zatrzymywanie i rozpoczynanie zadania
- Usuwanie baz danych
- Wniosek
Tworzenie i uruchamianie zadania replikacji w celu migracji bieżących zmian
W kolejnych podrozdziałach stworzymy zadanie replikacji zachodzących zmian. Aby zademonstrować trwającą replikację, najpierw rozpoczniemy zadanie, a następnie utworzymy tabelę i dodamy dane. Upuść tabelę DVOHRA.WLSLOG , jak pokazano na rysunku 1; będziemy tworzyć tę samą tabelę, aby zademonstrować trwającą replikację.

Rysunek 1: Stolik zrzutowy DVOHRA.WLSLOG
Dodawanie dodatkowego rejestrowania
Usługa migracji bazy danych wymaga włączenia dodatkowego rejestrowania, aby umożliwić przechwytywanie danych zmian (CDC), które jest używane do replikowania bieżących zmian. Rejestrowanie uzupełniające to proces przechowywania informacji o tym, które wiersze danych w tabeli uległy zmianie. Rejestrowanie uzupełniające dodaje dodatkowe lub dodatkowe dane w kolumnie w plikach dziennika ponawiania za każdym razem, gdy wykonywana jest aktualizacja tabeli. Zmienione kolumny są rejestrowane jako dane uzupełniające w plikach dziennika ponownego przetwarzania wraz z kluczem identyfikującym, który może być kluczem podstawowym lub unikalnym indeksem. Jeśli tabela nie ma klucza podstawowego ani unikalnego indeksu, wszystkie kolumny skalarne są rejestrowane w plikach dziennika ponawiania, aby jednoznacznie identyfikować wiersz danych, co może spowodować duży rozmiar plików dziennika ponawiania. Oracle Database obsługuje następujące rodzaje dodatkowego rejestrowania:
- Minimalne rejestrowanie uzupełniające: Tylko minimalna ilość danych wymagana przez LogMiner do zmian DML jest zapisywana w plikach dziennika ponawiania.
- Logowanie kluczy identyfikacyjnych na poziomie bazy danych: Obsługiwane są różne rodzaje rejestrowania kluczy identyfikacyjnych na poziomie bazy danych — ALL, PRIMARY KEY, UNIQUE i FOREIGN KEY. Na poziomie ALL wszystkie kolumny (z wyjątkiem LOB, Long i ADT) są rejestrowane w plikach dziennika przeróbek. W przypadku klucza podstawowego tylko kolumny klucza podstawowego są przechowywane w plikach dziennika ponownego wykonywania, gdy wiersz zawierający klucz podstawowy jest aktualizowany; nie jest wymagane aktualizowanie kolumny klucza podstawowego. Rodzaj FOREIGN KEY przechowuje tylko klucze obce wiersza w plikach dziennika ponawiania, gdy którykolwiek z czerwonych plików dziennika jest aktualizowany. Rodzaj UNIQUE przechowuje tylko kolumny w unikalnym kluczu złożonym lub indeksie bitmapy, gdy jakakolwiek kolumna w unikalnym kluczu złożonym lub indeksie bitmapy uległa zmianie.
- Dodatkowe rejestrowanie na poziomie tabeli: Określa na poziomie tabeli, które kolumny są przechowywane w plikach dziennika przeróbek. Rejestrowanie kluczy identyfikacyjnych na poziomie tabeli obsługuje te same poziomy, co rejestrowanie kluczy identyfikacyjnych na poziomie bazy danych; WSZYSTKO, KLUCZ PODSTAWOWY, KLUCZ UNIKATOWY i KLUCZ OBCNY. Na poziomie tabeli obsługiwane są również dodatkowe grupy dzienników zdefiniowane przez użytkownika, które pozwalają użytkownikowi określić, które kolumny mają być dodatkowo rejestrowane. Dodatkowe grupy dzienników zdefiniowane przez użytkownika mogą być warunkowe lub bezwarunkowe.
W przypadku ciągłej replikacji musimy ustawić minimalne dodatkowe rejestrowanie i dodatkowe rejestrowanie na poziomie tabeli dla WSZYSTKICH kolumn.
W SQL*Plus uruchom następującą instrukcję, aby ustawić minimalne dodatkowe rejestrowanie:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Dane wyjściowe są następujące:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
Aby znaleźć stan minimalnego rejestrowania dodatkowego, uruchom następującą instrukcję. A jeśli dane wyjściowe mają wartość kolumny SUPPLEME jako TAK, włączone jest minimalne dodatkowe rejestrowanie.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
Ustawienie minimalnego dodatkowego rejestrowania i sprawdzania stanu wyjściowego pokazano na rysunku 2.
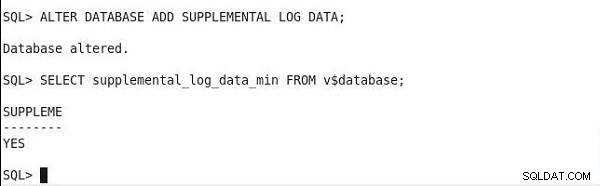
Rysunek 2: Ustawianie i weryfikacja minimalnego rejestrowania dodatkowego
Ustawimy również rejestrowanie kluczy identyfikacyjnych na poziomie tabeli, gdy dodamy dane tabeli i tabeli, aby zademonstrować trwającą replikację po rozpoczęciu zadania. Jeśli dodamy tabelę i dane tabeli przed utworzeniem i rozpoczęciem zadania, nie będziemy w stanie zademonstrować trwającej replikacji.
Aby utworzyć zadanie dla trwającej replikacji, kliknij Utwórz zadanie , jak pokazano na rysunku 3.

Rysunek 3: Zadania>Utwórz zadanie
W Utwórz zadanie kreatora, określ nazwę i opis zadania, a następnie wybierz instancję replikacji, źródłowy punkt końcowy i docelowy punkt końcowy, jak pokazano na rysunku 4. Wybierz Typ migracji jako Przeprowadź migrację istniejących danych i replikuj bieżące zmiany .
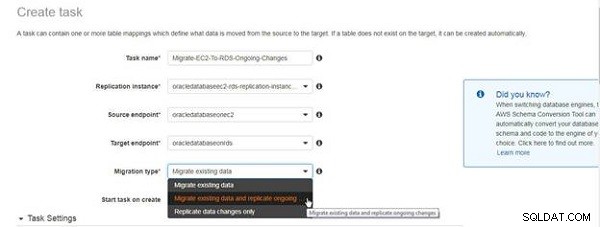
Rysunek 4: Wybór typu migracji dla trwającej replikacji
Komunikat przedstawiony na rysunku 5 wskazuje, że dla trwającej replikacji wymagane jest włączenie dodatkowego rejestrowania. Komunikat nie ma wskazywać, że dodatkowe logowanie nie zostało włączone, a jedynie jako przypomnienie. Włączyliśmy już dodatkowe logowanie. Zaznacz pole wyboru Rozpocznij zadanie przy tworzeniu .
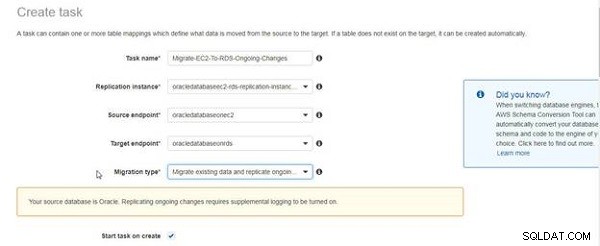
Rysunek 5: Wiadomość o dodatkowym wymogu rejestrowania w celu replikowania trwających zmian
Ustawienia zadań są takie same jak w przypadku migracji tylko istniejących danych (patrz Rysunek 6).
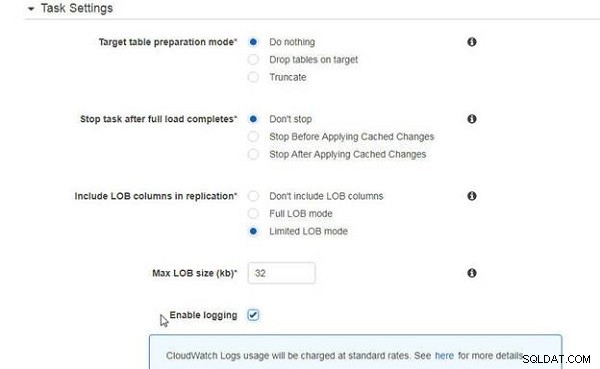
Rysunek 6: Ustawienia zadań
W przypadku mapowań tabel wymagana jest co najmniej jedna reguła wyboru. Dodaj regułę wyboru, aby uwzględnić wszystkie tabele w DVOHRA tabeli, jak pokazano na rysunku 7.
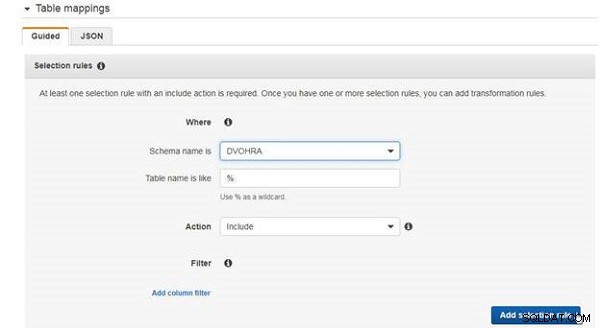
Rysunek 7: Dodawanie reguły wyboru
Dodaną regułę wyboru pokazano na rysunku 8.
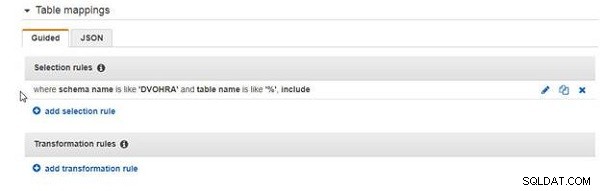
Rysunek 8: Reguła wyboru
Kliknij Utwórz zadanie aby utworzyć zadanie, jak pokazano na rysunku 9.
Rysunek 9: Utwórz zadanie
Nowe zadanie zostanie dodane ze statusem Tworzenie , jak pokazano na rysunku 10.

Rysunek 10: Dodano zadanie ze stanem Tworzę
Po zastosowaniu reguł wyboru i transformacji dla wszystkich istniejących danych i migracji danych, status zadania staje się Wczytywanie zakończone, replikacja trwa (patrz Rysunek 11).

Rysunek 11: Ładowanie zakończone, replikacja w toku
Statystyki tabeli zakładka nie wyświetla żadnych tabel jako przeniesionych lub zreplikowanych, jak pokazano na rysunku 12.
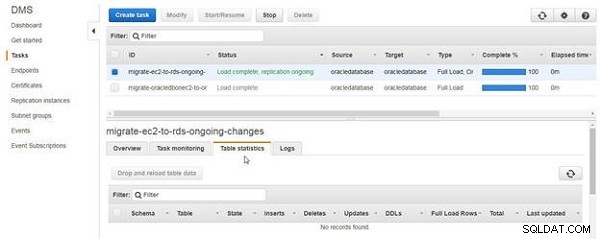
Rysunek 12: Statystyki tabeli
Aby przeglądać dzienniki CloudWatch, kliknij Dzienniki i kliknij łącze, jak pokazano na rysunku 13.
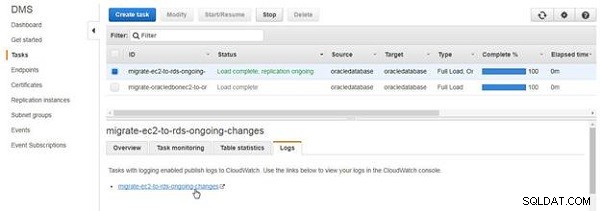
Rysunek 13: Dzienniki
Zostaną wyświetlone logi CloudWatch, jak pokazano na rysunku 14. Ostatni wpis w logach dotyczy uruchomienia replikacji. Trwające zadanie replikacji nie kończy się po załadowaniu istniejących danych, jeśli takie istnieją, ale jest kontynuowane.
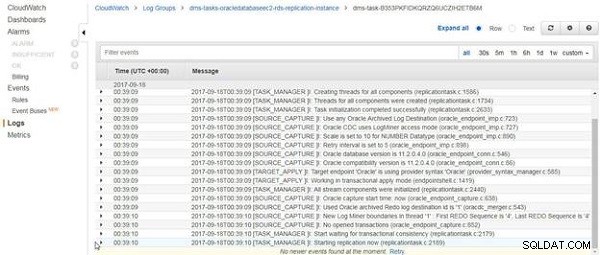
Rysunek 14: Dzienniki CloudWatch
Dodawanie tabeli do instancji bazy danych Oracle w EC2
Następnie utwórz tabelę i dodaj dane tabeli, aby zademonstrować trwającą replikację. Uruchom następujące dwie instrukcje razem, aby dodatkowe rejestrowanie na poziomie tabeli zostało ustawione podczas tworzenia tabeli. Zmodyfikuj skrypt, aby zmienić schemat.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
Dodatkowe rejestrowanie na poziomie tabeli jest ustawiane podczas tworzenia tabeli.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
Wynik jest pokazany w SQL*Plus na rysunku 15.
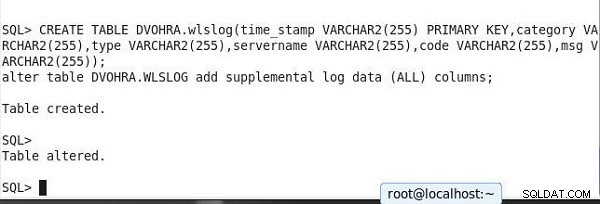
Rysunek 15: Tworzenie tabeli i ustawianie dodatkowego rejestrowania
Jak dotąd utworzyliśmy tylko tabelę, a nie dodaliśmy żadnych danych tabeli. DDL dla tabeli jest migrowane, jak pokazano w statystykach tabeli na rysunku 16.
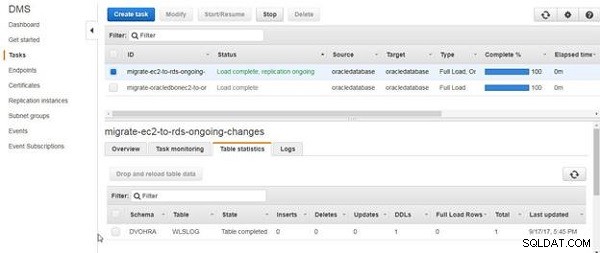
Rysunek 16: DDL dla przeniesionych tabel
Dodawanie danych tabeli
Następnie uruchom następujący skrypt SQL, aby dodać dane do utworzonej tabeli. Zmodyfikuj skrypt, aby zmienić schemat.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Następnie uruchom instrukcję Commit.
SQL> COMMIT; Commit complete.
Eksploracja zreplikowanej tabeli bazy danych
Statystyki tabeli wyświetlają wstawki jako liczbę dodanych wierszy danych, jak pokazano na rysunku 17.
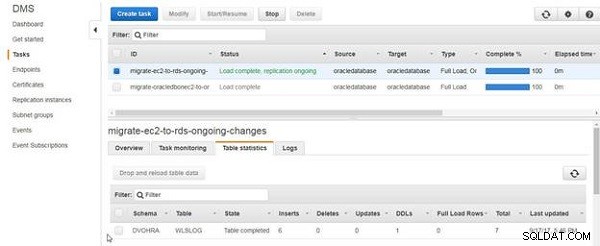
Rysunek 17: Lista statystyk tabeli 6 wstawek
Zadanie jest kontynuowane po zreplikowaniu trwających zmian. Dodaj kolejny wiersz danych.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Kliknij Odśwież dane z serwera, jak pokazano na rysunku 18.
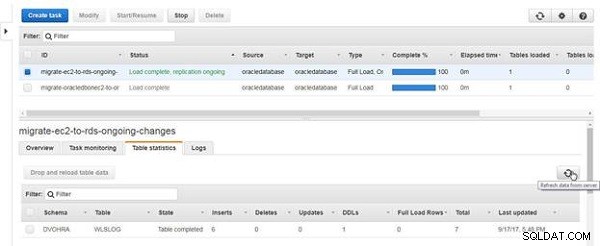
Rysunek 18: Odśwież dane z serwera
Całkowita liczba wstawek w statystykach tabeli wynosi 7, jak pokazano na rysunku 19.
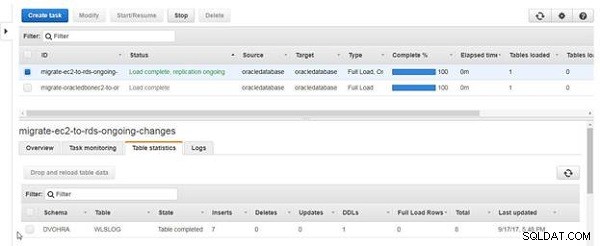
Rysunek 19: Statystyki tabeli z wstawkami jako 7
Upuszczanie i ponowne ładowanie danych
Aby upuścić i ponownie załadować dane tabeli, kliknij Upuść i ponownie załaduj dane tabeli , jak pokazano na rysunku 20.
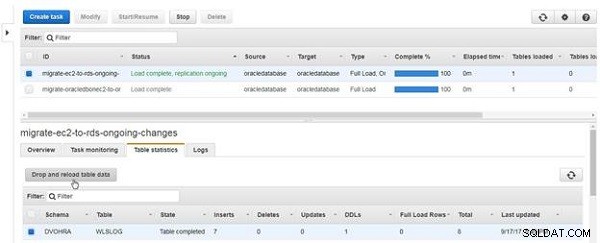
Rysunek 20: Upuść i ponownie załaduj dane tabeli
Kliknij Odśwież dane z serwera (patrz Rysunek 21).
Rysunek 21: Odśwież dane z serwera
Ikona i Stan kolumna tabeli wskazuje, że tabela jest ładowana ponownie, jak pokazano na rysunku 22.
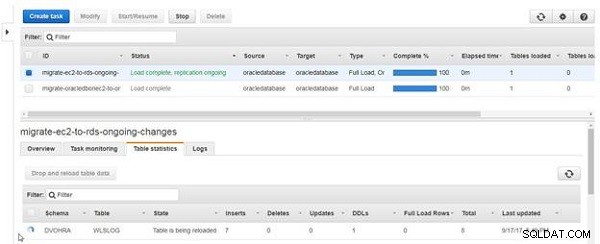
Rysunek 22: Tabela jest ładowana ponownie
Po zakończeniu przeładowywania tabeli kolumna Stan tabeli staje się Tabela ukończona , jak pokazano na rysunku 23. Po ponownym załadowaniu danych tabeli Pełne ładowanie wierszy wyświetla wartość 7, a Inserts 0, ponieważ ponowne ładowanie nie jest trwającą replikacją, ale pełnym ładowaniem.
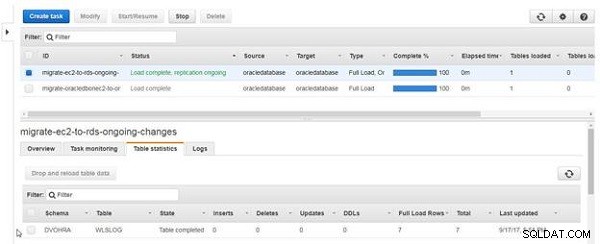
Rysunek 23: Ponowne ładowanie tabeli zakończone
Ponieważ dane tabeli są usuwane i ponownie ładowane, a dane tabeli źródłowej nie uległy zmianie, dzienniki CloudWatch zawierają komunikat „Niektóre zmiany ze źródłowej bazy danych nie miały wpływu po zastosowaniu do docelowej bazy danych”, jak pokazano na rysunku 24.
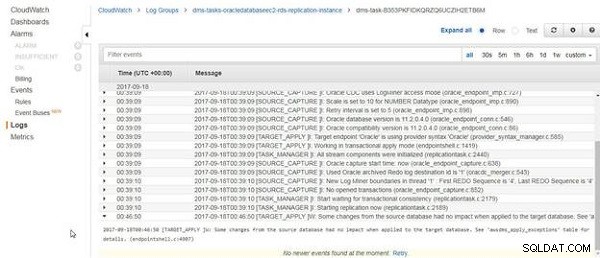
Rysunek 24: Niektóre zmiany ze źródłowej bazy danych nie miały wpływu po zastosowaniu w docelowej bazie danych
Po ponownym załadowaniu DVOHRA.wlslog tabela została zakończona, komunikat „Zakończono ładowanie dla tabeli DVOHRA.wlslog. Otrzymano 7 wierszy”, jak pokazano na rysunku 25.
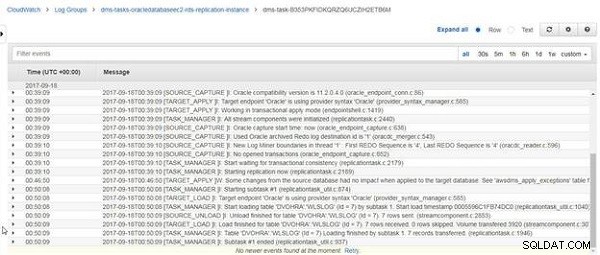
Rysunek 25: Dziennik CloudWatch Komunikat o zakończeniu ładowania
Zatrzymywanie i rozpoczynanie zadania
Zadanie typu, które obejmuje trwającą replikację, nie zatrzymuje się samo, chyba że wystąpi błąd. Aby zatrzymać zadanie, kliknij Zatrzymaj (patrz Rysunek 26).
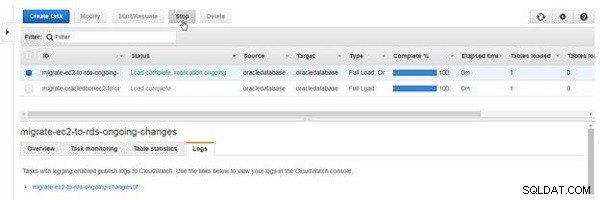
Rysunek 26: Zatrzymywanie zadania
W Zatrzymaj zadanie kliknij Zatrzymaj , jak pokazano na rysunku 27.
Rysunek 27: Okno dialogowe potwierdzenia, aby zatrzymać zadanie
Status zadania to Zatrzymywanie , jak pokazano na rysunku 28.
Rysunek 28: Zatrzymywanie zadania
Gdy zadanie zostanie zatrzymane, stan zmieni się na Zatrzymane , jak pokazano na rysunku 29.
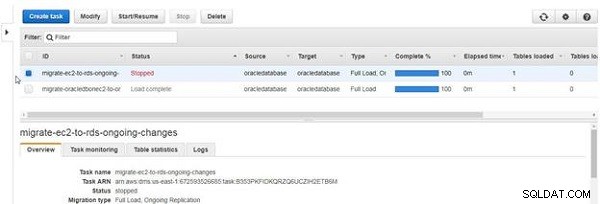
Rysunek 29: Zadanie zatrzymane
Aby rozpocząć zatrzymane zadanie, kliknij Rozpocznij/Wznów , jak pokazano na rysunku 30.
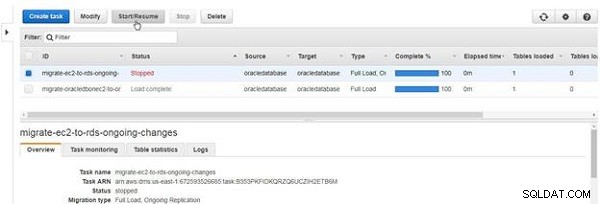
Rysunek 30: Rozpoczynanie lub wznawianie zadania
W Rozpocznij zadanie kliknij Rozpocznij aby rozpocząć zadanie od punktu zatrzymania (patrz Rysunek 31). Inną opcją jest ponowne uruchomienie zadania.
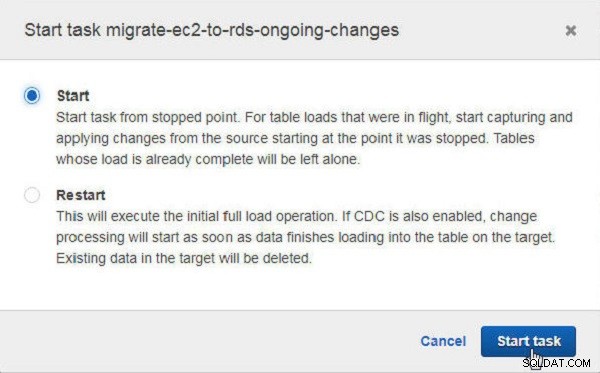
Rysunek 31: Uruchamianie zadania po zatrzymaniu
Status zadania to Rozpoczęcie , jak pokazano na rysunku 32.

Rysunek 32: Rozpoczęcie zadania
Po zakończeniu migracji istniejących danych zadanie będzie nadal działać ze statusem Wczytywanie zakończone, replikacja w toku , jak pokazano na rysunku 33.

Rysunek 33: Ładowanie zakończone, replikacja w toku
Usuwanie baz danych
Instancję RDS DB można usunąć za pomocą Instance Actions>Delete Komenda. Baza danych Oracle w instancji EC2 może zostać zatrzymana za pomocą Actions>Instance State>Stop , jak pokazano na rysunku 34.

Rysunek 34: Zatrzymywanie instancji EC2
Wniosek
W czterech artykułach omówiliśmy migrację bazy danych Oracle z AWS EC2 do AWS RDS.



