Problem jest dobrze znany wszystkim, którzy pracowali z implementacjami bibliotek wyrażeń regularnych Henry'ego Spencera:leniwe kwantyfikatory nie powinny być mylone z zachłannymi kwantyfikatorami w jednej i tej samej gałęzi ponieważ prowadzi to do nieokreślonego zachowania. Silnik TRE regex używany w R wykazuje to samo zachowanie. Chociaż możesz do pewnego stopnia mieszać leniwe i zachłanne kwantyfikatory, zawsze musisz upewnić się, że uzyskasz spójny wynik.
Rozwiązaniem jest używanie tylko leniwych kwantyfikatorów wewnątrz grupy przechwytywania:
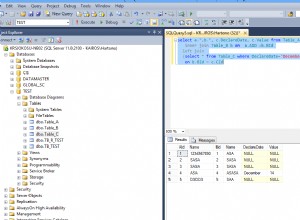
select REGEXP_REPLACE('+000099,8420000', '^\+?(-?)0*([0-9]+?,[0-9]+?)0*$','\1\2') as Result from dual
Zobacz demo online
[0-9]+?,[0-9]+? część pasuje do 1 lub więcej cyfr, ale jak najmniej razy, po czym następuje przecinek, a następnie 1 lub więcej cyfr, jak najmniej.
Jeszcze kilka testów (wybierz REGEXP_REPLACE('+00009,010020','[0-9]+,[0-9]+?([1-9])','\1') z podwójnego daje +20 ) udowodnić, że pierwszy kwantyfikator w grupie ustawia typ zachłanności kwantyfikatora . W powyższym przypadku zachłanność kwantyfikatora grupy 0 jest ustawiona na zachłanna przez pierwszy ? kwantyfikator i Grupa 1 (tj. ([0-9]+?,[0-9]+?) ) typ zachłanności jest ustawiany za pomocą pierwszego +? (co jest leniwe).