TeamCity to serwer ciągłej integracji i ciągłego dostarczania zbudowany w Javie. Jest dostępny jako usługa w chmurze i lokalnie. Jak możesz sobie wyobrazić, narzędzia ciągłej integracji i dostarczania są kluczowe dla rozwoju oprogramowania, a ich dostępność musi pozostać nienaruszona. Na szczęście TeamCity można wdrożyć w trybie wysokiej dostępności.
Ten wpis na blogu obejmie przygotowanie i wdrożenie wysoce dostępnego środowiska dla TeamCity.
Środowisko
TeamCity składa się z kilku elementów. Istnieje aplikacja Java i baza danych, która tworzy kopię zapasową. Wykorzystuje również agentów, którzy komunikują się z podstawową instancją TeamCity. Wdrożenie o wysokiej dostępności składa się z kilku instancji TeamCity, z których jedna działa jako główna, a druga drugorzędna. Te instancje mają dostęp do tej samej bazy danych i katalogu danych. Pomocny schemat jest dostępny na stronie dokumentacji TeamCity, jak pokazano poniżej:

Jak widać, istnieją dwa wspólne elementy — katalog danych i baza danych. Musimy zapewnić, aby były one również wysoce dostępne. Istnieją różne opcje, których możesz użyć do zbudowania współdzielonego uchwytu; jednak użyjemy GlusterFS. Jeśli chodzi o bazę danych, użyjemy jednego z obsługiwanych systemów zarządzania relacyjnymi bazami danych — PostgreSQL, i użyjemy ClusterControl do zbudowania na jego podstawie stosu wysokiej dostępności.
Jak skonfigurować GlusterFS
Zacznijmy od podstaw. Chcemy skonfigurować nazwy hostów i /etc/hosts na naszych węzłach TeamCity, gdzie będziemy również wdrażać GlusterFS. Aby to zrobić, musimy skonfigurować repozytorium dla najnowszych pakietów GlusterFS na wszystkich z nich:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateNastępnie możemy zainstalować GlusterFS na wszystkich naszych węzłach TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS używa portu 24007 do łączności między węzłami; musimy upewnić się, że jest otwarty i dostępny dla wszystkich węzłów.
Gdy połączenie jest na miejscu, możemy utworzyć klaster GlusterFS, uruchamiając go z jednego węzła:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Teraz możemy przetestować, jak wygląda stan:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Wygląda na to, że wszystko jest w porządku, a łączność jest na miejscu.
Następnie powinniśmy przygotować urządzenie blokowe do użycia przez GlusterFS. Musi to zostać wykonane na wszystkich węzłach. Najpierw utwórz partycję:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Następnie sformatuj tę partycję:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Na koniec, we wszystkich węzłach, musimy utworzyć katalog, który będzie używany do zamontowania partycji i edycji fstab, aby upewnić się, że zostanie zamontowany podczas uruchamiania:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabSprawdźmy teraz, czy to działa:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Teraz możemy użyć jednego z węzłów do utworzenia i uruchomienia woluminu GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successProszę zauważyć, że używamy wartości „3” dla liczby replik. Oznacza to, że każdy tom będzie istniał w trzech egzemplarzach. W naszym przypadku każda cegła, każdy wolumin /dev/sdb1 we wszystkich węzłach będzie zawierał wszystkie dane.
Po uruchomieniu woluminów możemy zweryfikować ich status:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksJak widać, wszystko wygląda dobrze. Ważne jest to, że GlusterFS wybrał port 49152 do uzyskania dostępu do tego woluminu i musimy upewnić się, że jest on dostępny we wszystkich węzłach, w których będziemy go montować.
Następnym krokiem będzie zainstalowanie pakietu klienta GlusterFS. W tym przykładzie musimy go zainstalować na tych samych węzłach, co serwer GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Następnie musimy utworzyć katalog we wszystkich węzłach, który będzie używany jako udostępniony katalog danych dla TeamCity. To musi się zdarzyć na wszystkich węzłach:
example@sqldat.com:~# sudo mkdir /teamcity-storageNa koniec zamontuj wolumin GlusterFS na wszystkich węzłach:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageTo kończy przygotowania do współdzielonej pamięci masowej.
Tworzenie wysoce dostępnego klastra PostgreSQL
Po zakończeniu konfiguracji współdzielonej pamięci masowej dla TeamCity możemy teraz zbudować naszą wysoce dostępną infrastrukturę bazy danych. TeamCity może korzystać z różnych baz danych; jednak na tym blogu będziemy używać PostgreSQL. Wykorzystamy ClusterControl do wdrożenia, a następnie zarządzania środowiskiem bazy danych.
Przewodnik TeamCity dotyczący tworzenia wdrożenia wielowęzłowego jest pomocny, ale wydaje się, że pomija wysoką dostępność wszystkiego poza TeamCity. Przewodnik TeamCity sugeruje serwer NFS lub SMB do przechowywania danych, który sam w sobie nie ma nadmiarowości i stanie się pojedynczym punktem awarii. Rozwiązaliśmy to za pomocą GlusterFS. Wspominają o udostępnionej bazie danych, ponieważ pojedynczy węzeł bazy danych oczywiście nie zapewnia wysokiej dostępności. Musimy zbudować odpowiedni stos:

W naszym przypadku. będzie się składać z trzech węzłów PostgreSQL, jednego podstawowego i dwóch replik. Użyjemy HAProxy jako modułu równoważenia obciążenia i użyjemy Keepalived do zarządzania wirtualnym adresem IP, aby zapewnić pojedynczy punkt końcowy, z którym aplikacja ma się połączyć. ClusterControl obsłuży awarie, monitorując topologię replikacji i w razie potrzeby przeprowadzając wymagane odzyskiwanie, takie jak ponowne uruchomienie nieudanych procesów lub przełączenie awaryjne na jedną z replik w przypadku awarii węzła podstawowego.
Na początek wdrożymy węzły bazy danych. Należy pamiętać, że ClusterControl wymaga połączenia SSH z węzła ClusterControl do wszystkich węzłów, którymi zarządza.

Następnie wybieramy użytkownika, którego będziemy używać do łączenia się z bazę danych, jej hasło i wersję PostgreSQL do wdrożenia:

Następnie określimy, których węzłów użyć do wdrożenia PostgreSQL :
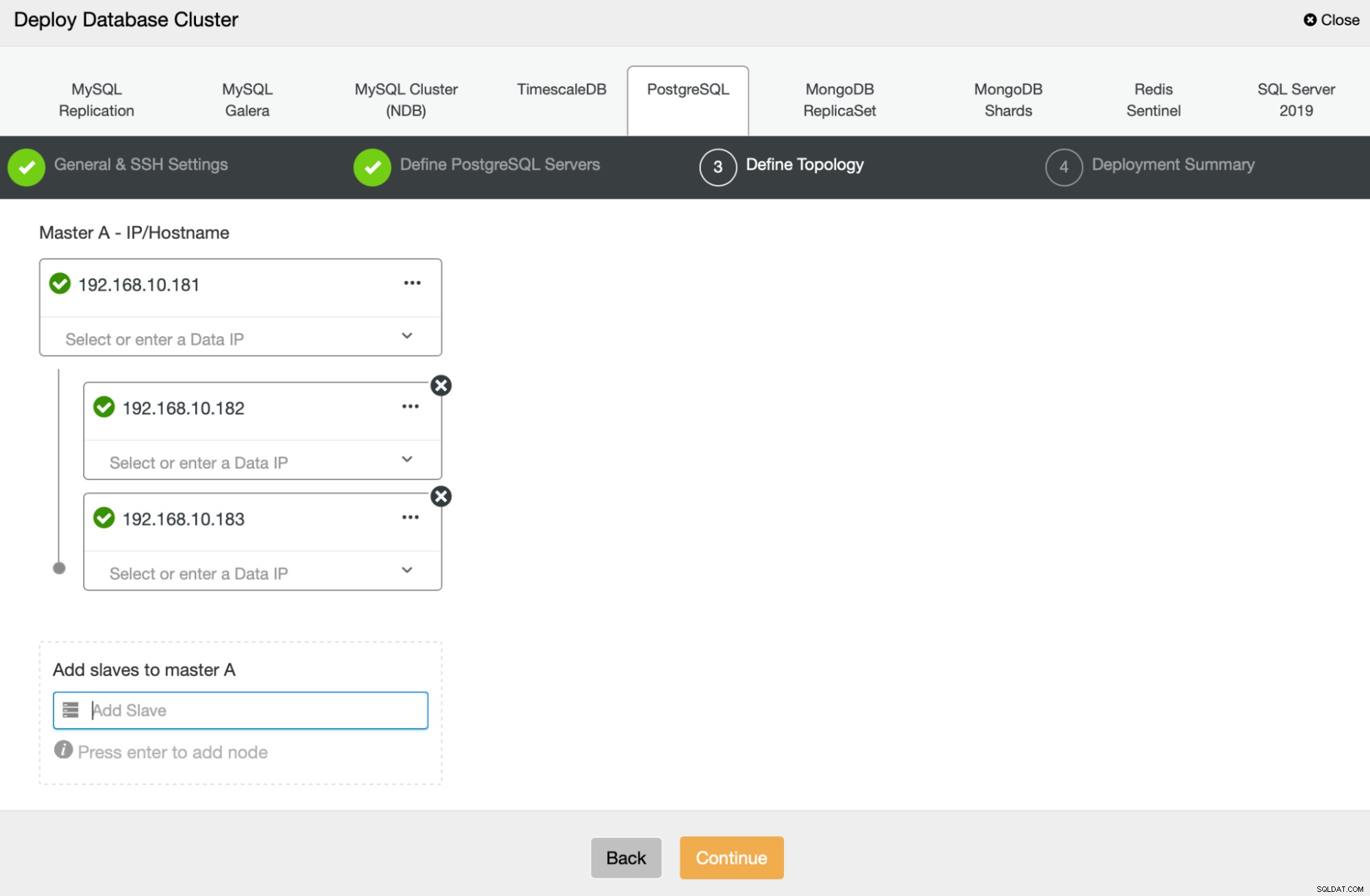
Na koniec możemy określić, czy węzły mają używać replikacji asynchronicznej, czy synchronicznej. Główna różnica między nimi polega na tym, że replikacja synchroniczna zapewnia, że każda transakcja wykonywana w węźle podstawowym będzie zawsze replikowana w replikach. Jednak replikacja synchroniczna spowalnia również zatwierdzanie. Zalecamy włączenie replikacji synchronicznej w celu uzyskania najlepszej trwałości, ale należy później sprawdzić, czy wydajność jest akceptowalna.

Po kliknięciu „Wdróż” rozpocznie się zadanie wdrażania. Jego postęp możemy monitorować w zakładce Aktywność w interfejsie ClusterControl. W końcu powinniśmy zobaczyć, że zadanie zostało ukończone, a klaster został pomyślnie wdrożony.

Wdróż instancje HAProxy, przechodząc do Zarządzanie -> Systemy równoważenia obciążenia. Wybierz HAProxy jako system równoważenia obciążenia i wypełnij formularz. Najważniejszym wyborem jest to, gdzie chcesz wdrożyć HAProxy. W tym przypadku użyliśmy węzła bazy danych, ale w środowisku produkcyjnym najprawdopodobniej chcesz oddzielić load balancery od instancji bazy danych. Następnie wybierz węzły PostgreSQL, które chcesz uwzględnić w HAProxy. Chcemy je wszystkie.

Teraz rozpocznie się wdrażanie HAProxy. Chcemy powtórzyć to co najmniej jeszcze raz, aby utworzyć dwie instancje HAProxy na potrzeby nadmiarowości. W tym wdrożeniu zdecydowaliśmy się na trzy systemy równoważenia obciążenia HAProxy. Poniżej znajduje się zrzut ekranu ekranu ustawień podczas konfigurowania wdrożenia drugiego HAProxy:
Gdy wszystkie nasze instancje HAProxy będą działać, możemy wdrożyć Keepalived . Pomysł polega na tym, że Keepalived będzie kolokował z HAProxy i będzie monitorował proces HAProxy. Jedna z instancji z działającym HAProxy będzie miała przypisany wirtualny adres IP. Ten adres VIP powinien być używany przez aplikację do łączenia się z bazą danych. Keepalived wykryje, czy ta HAProxy stanie się niedostępna i przeniesie się do innej dostępnej instancji HAProxy.
Kreator wdrażania wymaga od nas przekazania instancji HAProxy, które mają być monitorowane przez Keepalived. Musimy również przekazać adres IP i interfejs sieciowy dla VIP.

Ostatnim i ostatnim krokiem będzie utworzenie bazy danych dla TeamCity:

Na tym zakończyliśmy wdrażanie wysoce dostępnego klastra PostgreSQL.
Wdrażanie TeamCity jako wielowęzłowego
Następnym krokiem jest wdrożenie TeamCity w środowisku wielowęzłowym. Wykorzystamy trzy węzły TeamCity. Najpierw musimy zainstalować Java JRE i JDK, które spełniają wymagania TeamCity.
apt install default-jre default-jdkTeraz na wszystkich węzłach musimy pobrać TeamCity. Zainstalujemy w lokalnym, a nie udostępnionym katalogu.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzWtedy możemy uruchomić TeamCity na jednym z węzłów:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logPo uruchomieniu TeamCity możemy uzyskać dostęp do interfejsu użytkownika i rozpocząć wdrażanie. Początkowo musimy przekazać lokalizację katalogu danych. To jest udostępniony wolumen, który utworzyliśmy w GlusterFS.

Następnie wybierz bazę danych. Będziemy korzystać z klastra PostgreSQL, który już stworzyliśmy.

Pobierz i zainstaluj sterownik JDBC:

Następnie wypełnij dane dostępu. Użyjemy wirtualnego adresu IP dostarczonego przez Keepalived. Należy pamiętać, że używamy portu 5433. Jest to port używany do odczytu/zapisu zaplecza HAProxy; zawsze będzie wskazywał na aktywny węzeł główny. Następnie wybierz użytkownika i bazę danych do użycia z TeamCity.

Po wykonaniu tej czynności TeamCity rozpocznie inicjowanie struktury bazy danych.

Zgadzam się z Umową licencyjną:

Na koniec utwórz użytkownika TeamCity:

To wszystko! Powinniśmy być teraz w stanie zobaczyć GUI TeamCity:

Teraz musimy ustawić TeamCity w trybie wielowęzłowym. Najpierw musimy edytować skrypty startowe we wszystkich węzłach:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shMusimy upewnić się, że wyeksportowane zostaną następujące dwie zmienne. Sprawdź, czy używasz prawidłowej nazwy hosta, adresu IP i poprawnych katalogów dla pamięci lokalnej i współdzielonej:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Gdy to zrobisz, możesz uruchomić pozostałe węzły:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startPowinieneś zobaczyć następujące dane wyjściowe w Administracja -> Konfiguracja węzłów:Jeden węzeł główny i dwa węzły rezerwowe.

Pamiętaj, że przełączanie awaryjne w TeamCity nie jest automatyczne. Jeśli główny węzeł przestanie działać, powinieneś połączyć się z jednym z węzłów drugorzędnych. Aby to zrobić, przejdź do „Konfiguracji węzłów” i awansuj do węzła „Główny”. Na ekranie logowania zobaczysz wyraźne wskazanie, że jest to węzeł drugorzędny:

W „Konfiguracji węzłów” zobaczysz, że jeden węzeł ma spadł z klastra:

Otrzymasz komunikat informujący, że nie możesz pisać do tego węzła. Nie martw się; zapis wymagany do promocji tego węzła do statusu „główny” będzie działał dobrze:

Kliknij „Włącz”, a pomyślnie promujemy dodatkowy węzeł TimeCity:

Gdy węzeł 1 stanie się dostępny i TeamCity zostanie ponownie uruchomiony na tym węźle, zobacz, jak ponownie dołącza do klastra:

Jeśli chcesz jeszcze bardziej poprawić wydajność, możesz wdrożyć HAProxy + Keepalived przed interfejsem TeamCity, aby zapewnić pojedynczy punkt wejścia do interfejsu GUI. Szczegółowe informacje na temat konfiguracji HAProxy dla TeamCity można znaleźć w dokumentacji.
Zawijanie
Jak widać, wdrożenie TeamCity w celu zapewnienia wysokiej dostępności nie jest takie trudne — większość z nich została dokładnie opisana w dokumentacji. Jeśli szukasz sposobów na zautomatyzowanie niektórych z tych elementów i dodanie wysoko dostępnego zaplecza bazy danych, rozważ wypróbowanie ClusterControl bezpłatnie przez 30 dni. ClusterControl może szybko wdrożyć i monitorować zaplecze, zapewniając automatyczne przełączanie awaryjne, odzyskiwanie, monitorowanie, zarządzanie kopiami zapasowymi i nie tylko.
Aby uzyskać więcej wskazówek na temat narzędzi do tworzenia oprogramowania i najlepszych praktyk, sprawdź, jak wesprzeć swój zespół DevOps w zakresie jego potrzeb w zakresie baz danych.
Aby otrzymywać najnowsze wiadomości i najlepsze praktyki zarządzania infrastrukturą baz danych opartą na otwartym kodzie źródłowym, nie zapomnij śledzić nas na Twitterze lub LinkedIn i subskrybować nasz biuletyn. Do zobaczenia wkrótce!