PostgreSQL, znany również jako najbardziej zaawansowana na świecie baza danych open source, ma nową wersję od 24 września 2020 r., a teraz jest dojrzały, możemy sprawdzić, co nowego tam jest, aby zacząć myśleć o plan migracji. PostgreSQL 13 jest dostępny z wieloma nowymi funkcjami i ulepszeniami. W tym blogu wspomnimy o niektórych z tych nowych funkcji i zobaczymy, jak wdrożyć lub zaktualizować swoją aktualną wersję PostgreSQL.
Nowe funkcje i ulepszenia PostgreSQL 13
Zacznijmy wspominać o niektórych nowych funkcjach i ulepszeniach tej wersji PostgreSQL 13, które można zobaczyć w oficjalnej dokumentacji.
Partycjonowanie
-
Zezwalaj na wycinanie partycji i łączeń na partycje w większej liczbie przypadków
-
Obsługa wyzwalaczy na poziomie wiersza PRZED wyzwalaczami w tabelach podzielonych na partycje
-
Zezwalaj na logiczną replikację partycjonowanych tabel za pośrednictwem publikacji
-
Zezwalaj na logiczną replikację do podzielonych na partycje tabel dla subskrybentów
-
Zezwalaj na używanie zmiennych obejmujących cały wiersz w wyrażeniach partycjonujących
Indeksy
-
Bardziej wydajne przechowywanie duplikatów w indeksach B-drzewa
-
Zezwalaj indeksom GiST i SP-GiST w kolumnach na obsługę pól ORDER BY <-> zapytania punktowe
-
Zezwalaj na wydajniejszą obsługę indeksów GIN! (NIE) klauzule w wyszukiwaniu tsquery
-
Zezwalaj klasom operatorów indeksu na przyjmowanie parametrów
Optymalizator
-
Popraw szacowanie selektywności optymalizatora dla operatorów zawierania/dopasowania
-
Zezwalaj na ustawienie celu statystyk dla statystyk rozszerzonych
-
Zezwalaj na użycie wielu obiektów statystyk rozszerzonych w jednym zapytaniu
-
Zezwalaj na używanie rozszerzonych obiektów statystycznych dla klauzul OR i list stałych IN/ANY
-
Zezwalaj na wywoływanie funkcji w klauzulach FROM (w linii), jeśli mają one wartości stałe
Wydajność
-
Zaimplementuj sortowanie przyrostowe i popraw wydajność sortowania wartości inet
-
Zezwalaj agregacji skrótu na używanie pamięci dyskowej dla dużych zestawów wyników agregacji
-
Zezwalaj na wstawianie, a nie tylko aktualizacje i usuwanie, wyzwalanie czynności odkurzania w autoodkurzaniu
-
Dodaj parametr maintenance_io_concurrency, aby kontrolować współbieżność we/wy dla operacji konserwacyjnych
-
Zezwalaj na pomijanie zapisów WAL podczas transakcji, która tworzy lub przepisuje relację, jeśli wal_level jest minimalny
-
Zwiększ wydajność podczas odtwarzania poleceń DROP DATABASE, gdy używanych jest wiele obszarów tabel
-
Przyspiesz konwersję liczb całkowitych na tekst
-
Zmniejsz użycie pamięci przez ciągi zapytań i skrypty rozszerzeń, które zawierają wiele instrukcji SQL
Monitorowanie
-
Zezwalaj EXPLAIN, auto_explain, autovacuum i pg_stat_statements na śledzenie statystyk użytkowania WAL
-
Zezwalaj na rejestrowanie próbki instrukcji SQL, a nie wszystkich instrukcji
-
Dodaj typ zaplecza do csvlog i opcjonalnie log_line_prefix wyjścia logu
-
Poprawa kontroli nad logowaniem parametrów przygotowywanych instrukcji
-
Dodaj Leader_pid do pg_stat_activity, aby zgłosić proces przywódcy pracownika równoległego
-
Dodaj widok systemowy pg_stat_progress_basebackup, aby raportować postęp przesyłania strumieniowego podstawowych kopii zapasowych
-
Dodaj widok systemowy pg_stat_progress_analyze, aby raportować postęp ANALIZY
-
Dodaj widok systemowy pg_shmem_allocations, aby wyświetlić wykorzystanie pamięci współdzielonej
Replikacja i odzyskiwanie
-
Zezwalaj na zmianę ustawień konfiguracji replikacji strumieniowej przez ponowne wczytanie
-
Zezwalaj odbiornikom WAL na używanie tymczasowego gniazda replikacji, gdy nie określono stałego gniazda
-
Zezwalaj na ograniczenie pamięci WAL dla gniazd replikacji przez max_slot_wal_keep_size
-
Zezwalaj promocji trybu gotowości na anulowanie żądanej pauzy
-
Wygeneruj błąd, jeśli odzyskiwanie nie osiąga określonego celu odzyskiwania
-
Zezwalaj na kontrolowanie ilości pamięci używanej przez logiczne dekodowanie przed rozlaniem jej na dysk
-
Zezwalaj na kontynuowanie odzyskiwania, nawet jeśli WAL odwołuje się do nieprawidłowych stron
Polecenia narzędziowe
-
Zezwalaj VACUUM na równoległe przetwarzanie indeksów tabeli
-
Raportuj wykorzystanie buforu czasu planowania w danych wyjściowych EXPLAIN BUFFER
-
Zrób CREATE TABLE LIKE propaguj właściwość NO INHERIT ograniczenia CHECK do utworzonej tabeli
-
Dodaj ALTER TABLE ... DROP EXPRESSION, aby umożliwić usunięcie właściwości GENERATED z kolumny
-
Dodaj składnię ALTER VIEW, aby zmienić nazwy kolumn widoku
-
Dodaj opcje ALTER TYPE, aby zmodyfikować właściwości TOAST typu podstawowego i funkcje pomocnicze
-
Dodaj opcję CREATE DATABASE LOCALE
-
Zezwól DROP DATABASE na rozłączanie sesji przy użyciu docelowej bazy danych, dzięki czemu upuszczenie się powiedzie
I wiele innych zmian. Wspomnieliśmy tylko o niektórych z nich, aby uniknąć większego posta na blogu. Zobaczmy teraz, jak wdrożyć tę nową wersję.
Jak wdrożyć PostgreSQL 13
W tym celu założymy, że masz zainstalowany ClusterControl, w przeciwnym razie możesz postępować zgodnie z odpowiednią dokumentacją, aby go zainstalować.
Aby przeprowadzić wdrożenie z ClusterControl, po prostu wybierz opcję Wdróż i postępuj zgodnie z wyświetlanymi instrukcjami.
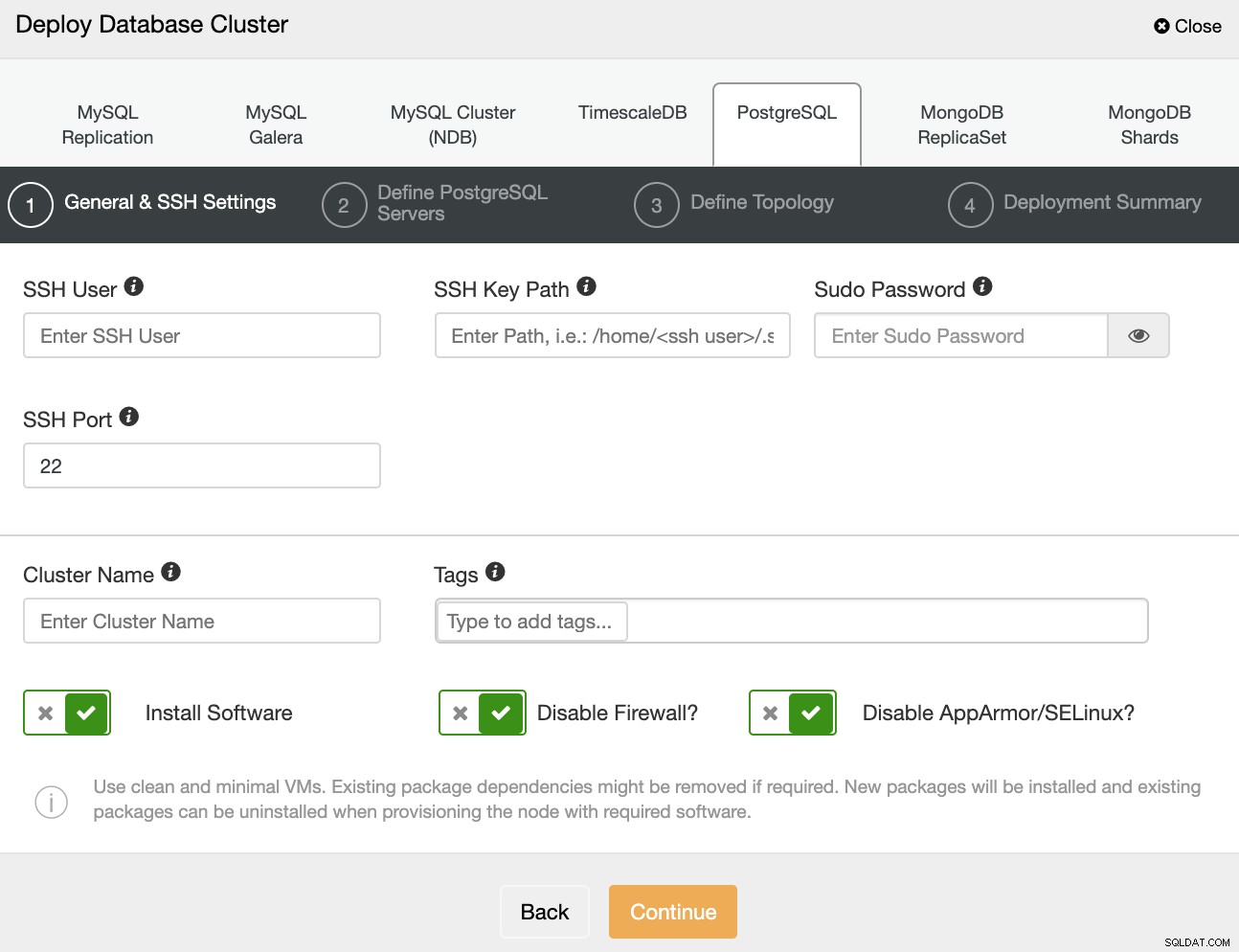
Wybierając PostgreSQL, musisz określić Użytkownika, Klucz lub Hasło oraz Port aby połączyć się przez SSH z Twoimi serwerami. Możesz również dodać nazwę dla swojego nowego klastra i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
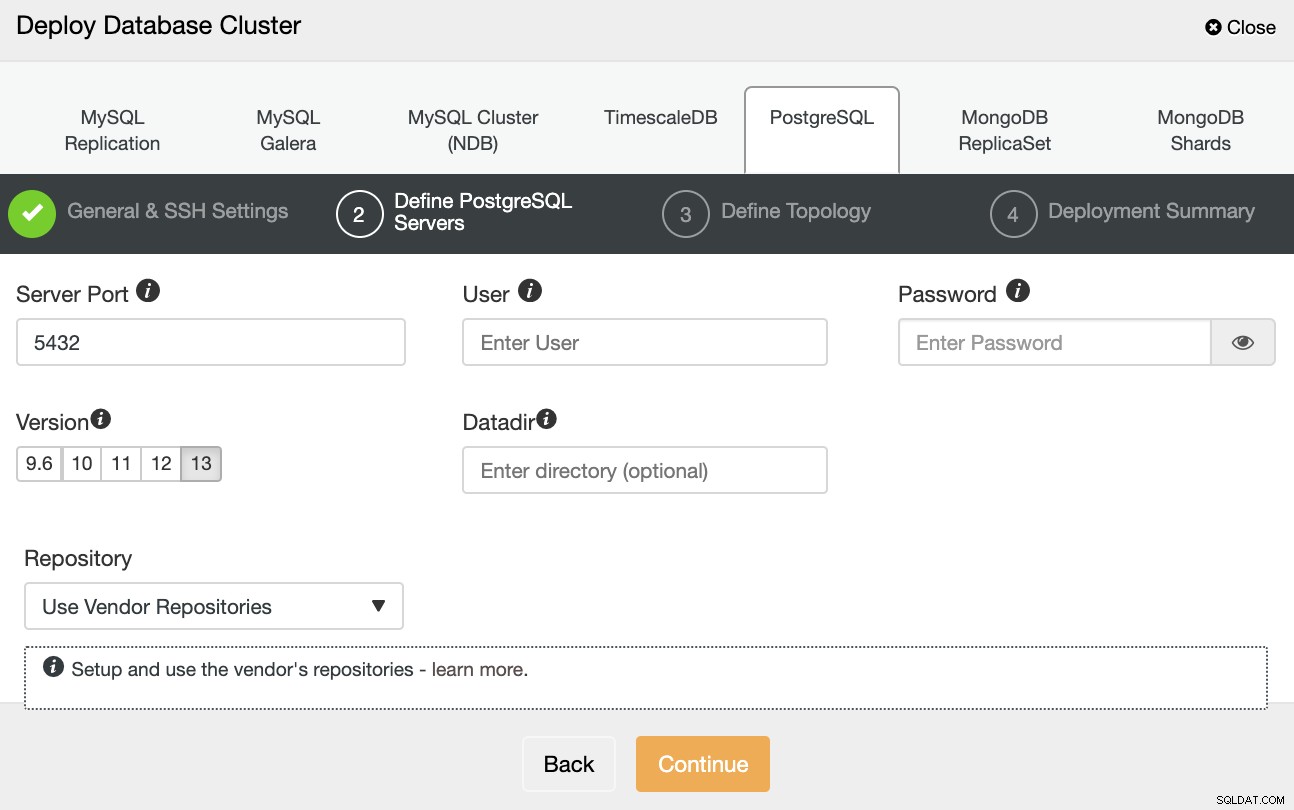
Po skonfigurowaniu informacji dostępu SSH należy zdefiniować poświadczenia bazy danych , wersja i katalog danych (opcjonalnie). Możesz także określić, którego repozytorium chcesz użyć.
W następnym kroku musisz dodać swoje serwery do klastra, który zamierzasz utworzyć przy użyciu adresu IP lub nazwy hosta.
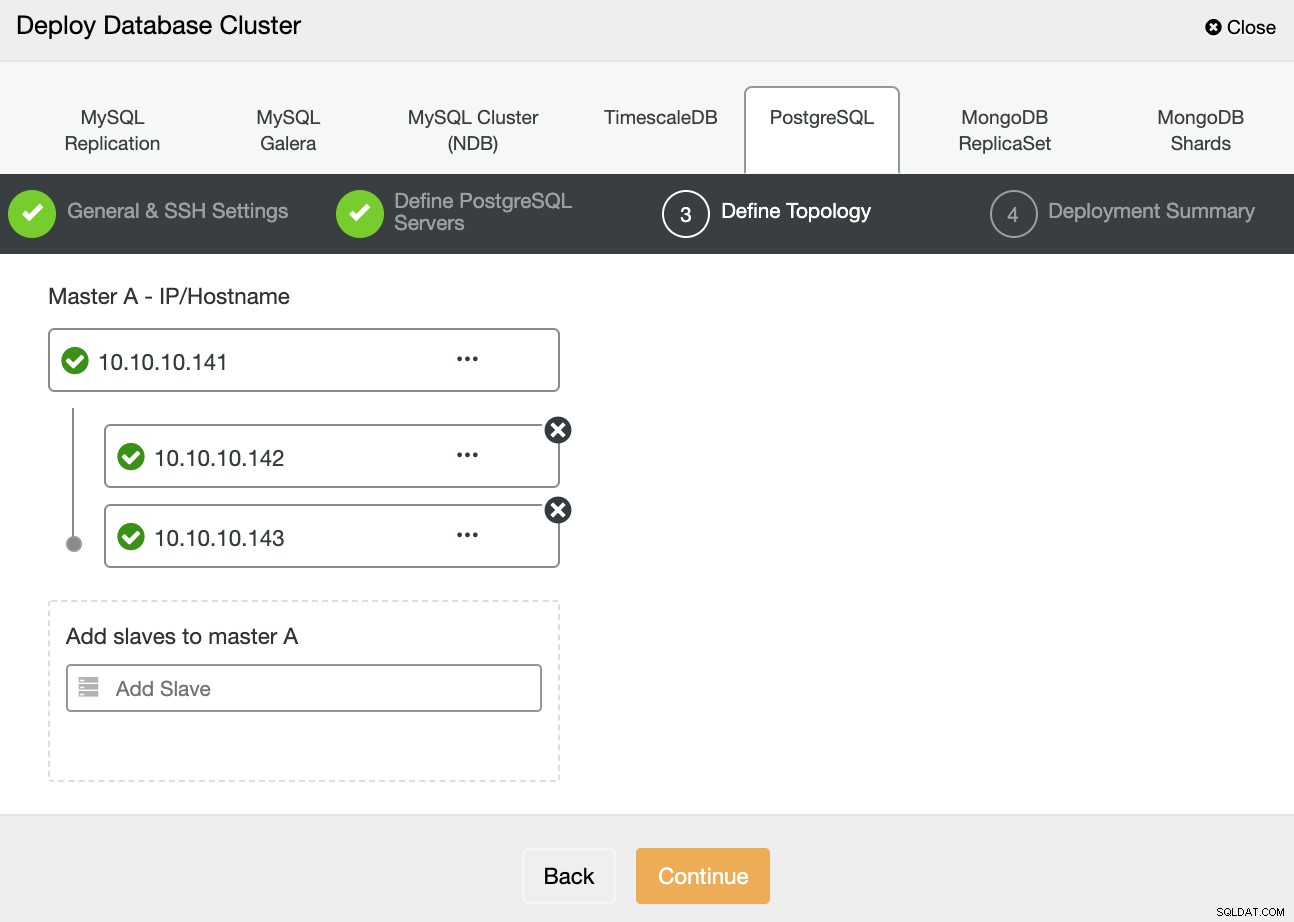
W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna, czy Asynchronicznie, a następnie po prostu naciśnij Wdróż.
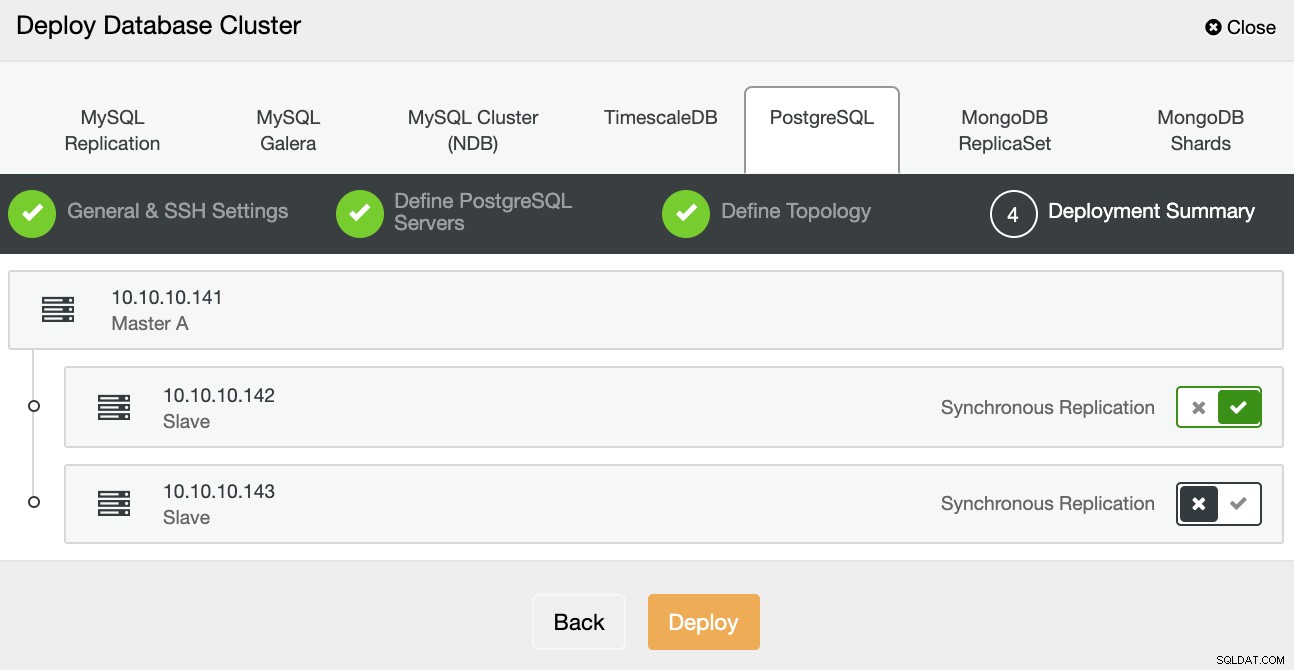
Po zakończeniu zadania możesz zobaczyć swój nowy klaster PostgreSQL w główny ekran ClusterControl.

Teraz masz już utworzony klaster, możesz wykonać na nim kilka zadań, jak dodawanie systemów równoważenia obciążenia (HAProxy), puli połączeń (PgBouncer) lub nowych urządzeń podrzędnych replikacji z tego samego interfejsu użytkownika ClusterControl.
Aktualizacja do PostgreSQL 13
Jeśli chcesz zaktualizować swoją aktualną wersję PostgreSQL do nowej, masz trzy główne opcje, które wykonają to zadanie.
-
Pg_dump:Jest to logiczne narzędzie do tworzenia kopii zapasowych, które pozwala zrzucić dane i przywrócić je w nowym PostgreSQL wersja. Tutaj będziesz mieć czas przestoju, który będzie się różnić w zależności od rozmiaru danych. Musisz zatrzymać system lub uniknąć nowych danych w węźle podstawowym, uruchomić pg_dump, przenieść wygenerowany zrzut do nowego węzła bazy danych i przywrócić go. W tym czasie nie możesz pisać do swojej podstawowej bazy danych PostgreSQL, aby uniknąć niespójności danych.
-
Pg_upgrade:Jest to narzędzie PostgreSQL do aktualizacji Twojej wersji PostgreSQL na miejscu. Może to być niebezpieczne w środowisku produkcyjnym i w takim przypadku nie zalecamy tej metody. Korzystając z tej metody, również będziesz mieć przestój, ale prawdopodobnie będzie on znacznie krótszy niż przy użyciu poprzedniej metody pg_dump.
-
Replikacja logiczna:Od wersji PostgreSQL 10 możesz używać tej metody replikacji, która umożliwia przeprowadzanie uaktualnień głównych wersji za pomocą zerowy (lub prawie zerowy) czas przestoju. W ten sposób można dodać węzeł zapasowy w ostatniej wersji PostgreSQL, a gdy replikacja jest aktualna, można przeprowadzić proces przełączania awaryjnego, aby promować nowy węzeł PostgreSQL.
Więcej szczegółowych informacji na temat nowych funkcji PostgreSQL 13 można znaleźć w oficjalnej dokumentacji.