Usługi AWS PostgreSQL są objęte parasolem RDS, czyli ofertą DaaS firmy Amazon dla wszystkich znanych silników baz danych.
Usługi zarządzanej bazy danych oferują pewne korzyści, które są atrakcyjne dla klientów poszukujących niezależności od utrzymania infrastruktury i wysoce dostępnych konfiguracji. Jak zawsze, nie ma jednego uniwersalnego rozwiązania. Aktualnie dostępne opcje są podświetlone poniżej:
Aurora PostgreSQL
Strona często zadawanych pytań dotyczących Amazon Aurora zawiera ważne szczegóły, które należy wziąć pod uwagę przed zanurzeniem się w produkcie. Na przykład dowiadujemy się, że warstwa pamięci masowej jest zwirtualizowana i znajduje się na zastrzeżonym zwirtualizowanym systemie pamięci masowej z kopią zapasową na dysku SSD.
Ceny
Jeśli chodzi o ceny, należy zauważyć, że Aurora PostgreSQL nie jest dostępna w bezpłatnej warstwie AWS.
Kompatybilność
Ta sama strona FAQ wyjaśnia, że Amazon nie twierdzi, że jest w 100% kompatybilny z PostgreSQL. Większość (moje podkreślenie) wniosków będzie w porządku, m.in. smak AWS PostgreSQL jest kompatybilny z wirem z PostgreSQL 9.6. W rezultacie Dissector PostgreSQL Wireshark będzie działał dobrze.
Wydajność
Wydajność jest również powiązana z typem instancji, na przykład maksymalna liczba połączeń jest domyślnie konfigurowana na podstawie rozmiaru instancji.
Jeśli chodzi o kompatybilność, ważny jest również rozmiar strony, który jest utrzymywany na poziomie 8KiB, który jest domyślnym rozmiarem strony PostgreSQL. Mówiąc o stronach, warto zacytować FAQ:„W przeciwieństwie do tradycyjnych silników baz danych Amazon Aurora nigdy nie przesyła zmodyfikowanych stron bazy danych do warstwy pamięci masowej, co skutkuje dalszymi oszczędnościami w zużyciu we/wy. Jest to możliwe, ponieważ Amazon zmienił sposób zarządzania pamięcią podręczną stron, umożliwiając jej pozostanie w pamięci w przypadku awarii bazy danych. Ta funkcja jest również korzystna dla ponownego uruchomienia bazy danych po awarii, dzięki czemu odzyskiwanie przebiega znacznie szybciej niż w przypadku tradycyjnej metody odtwarzania dzienników.
Zgodnie z FAQ, o którym mowa powyżej, Aurora PostgreSQL zapewnia trzykrotnie większą wydajność niż PostgreSQL w operacjach WYBIERZ i AKTUALIZUJ. Zgodnie z białą księgą PostgreSQL Benchmark White Paper firmy Amazon narzędziami używanymi do pomiaru wydajności były pgbench i sysbench. Godna uwagi jest zależność wydajności od typu wystąpienia, wyboru regionu i wydajności sieci. Zastanawiasz się, dlaczego nie wspomniano o INSERT? Dzieje się tak, ponieważ zgodność z PostgreSQL ACID („C”) wymaga, aby zaktualizowany rekord został utworzony za pomocą usunięcia, a następnie wstawienia.
Aby w pełni wykorzystać ulepszenia wydajności, Amazon zaleca, aby aplikacje były zaprojektowane do interakcji z bazą danych przy użyciu dużej liczby jednoczesnych zapytań i transakcji . Ten ważny czynnik jest często pomijany, co prowadzi do słabej wydajności, której winą jest implementacja.
Limity
Podczas planowania migracji należy wziąć pod uwagę pewne ograniczenia:
-
huge_pages nie można modyfikować, jednak jest domyślnie włączone:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row)
Nie można użyć - pg_hba, ponieważ wymaga ponownego uruchomienia serwera. Na marginesie, to musi być literówka w dokumentacji Amazona, ponieważ PostgreSQL wymaga tylko ponownego załadowania. Zamiast polegać na pg_hba, administratorzy będą musieli użyć AWS Security Groups i PostgreSQL GRANT.
- Rozdrobnienie PITR wynosi 5 minut.
- Replikacja między regionami nie jest obecnie dostępna dla PostgreSQL.
- Maksymalny rozmiar tabel to 64TiB
- Do 15 replik do odczytu
Skalowalność
Skalowanie w górę iw dół instancji bazy danych jest obecnie procesem ręcznym, który można wykonać za pomocą konsoli AWS lub CLI, chociaż automatyczne skalowanie działa, jednak zgodnie z FAQ Amazon Aurora będzie dostępne tylko dla MySQL.
 Zasoby obliczeniowe do skalowania dziennika zdarzeń
Zasoby obliczeniowe do skalowania dziennika zdarzeń W celu skalowania w poziomie aplikacje muszą korzystać z interfejsów API AWS SDK, na przykład w celu uzyskania szybkiego przełączania awaryjnego.
Wysoka dostępność
Przechodząc do wysokiej dostępności, w przypadku awarii węzła podstawowego, Aurora PostgreSQL zapewnia punkt końcowy klastra jako rekord A DNS, który jest automatycznie aktualizowany wewnętrznie w celu wskazania repliki wybranej jako nadrzędna.
Kopie zapasowe
Warto wspomnieć, że jeśli baza danych zostanie usunięta, wszelkie ręczne migawki kopii zapasowych zostaną zachowane, podczas gdy automatyczne migawki zostaną usunięte.
Replikacja
Ponieważ repliki współdzielą tę samą pamięć, co instancja podstawowa, opóźnienie replikacji teoretycznie mieści się w zakresie milisekund.
Amazon zaleca repliki do odczytu w celu skrócenia czasu przełączania awaryjnego. Z repliką do odczytu w trybie gotowości proces przełączania awaryjnego trwa około 30 sekund, podczas gdy bez repliki oczekuje się nawet 15 minut.
Inną dobrą wiadomością jest to, że obsługiwana jest również replikacja logiczna, jak pokazano na stronie 22.
Chociaż często zadawane pytania dotyczące Amazon Aurora nie zawierają szczegółowych informacji na temat replikacji, tak jak w przypadku MySQL, najlepsze praktyki Aurora PostgreSQL zawierają przydatne zapytanie do weryfikacji stanu replikacji:
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();Powyższe zapytanie daje:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07Ponieważ replikacja jest tak ważnym tematem, warto było skonfigurować test pgbench, jak opisano w białej księdze porównawczej, o której mowa powyżej:
[example@sqldat.com ~]$ whoami
ec2-user
[example@sqldat.com ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[example@sqldat.com ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[example@sqldat.com ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8Wskazówka: Unikaj niepotrzebnego wpisywania, tworząc plik pgpass i eksportując zmienne środowiskowe hosta, bazy danych i użytkownika, np.:
[example@sqldat.com ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[example@sqldat.com ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordUruchom polecenie inicjalizacji danych:
[example@sqldat.com ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresPodczas inicjowania danych przechwyć opóźnienie replikacji za pomocą powyższego kodu SQL wywołanego z następującego skryptu:
while : ; do
psql -t -q \
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
doneFiltrowanie danych wyjściowych screenloga za pomocą następującego polecenia:
[example@sqldat.com ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00Okazuje się, że replikacja była opóźniona nawet o 8 sekund!
W związku z tym metryka AWS CloudWatch AuroraReplicaLagMaximum nie zgadza się z wynikami powyższego polecenia SQL. Chciałbym wiedzieć dlaczego, więc opinie są bardzo mile widziane.
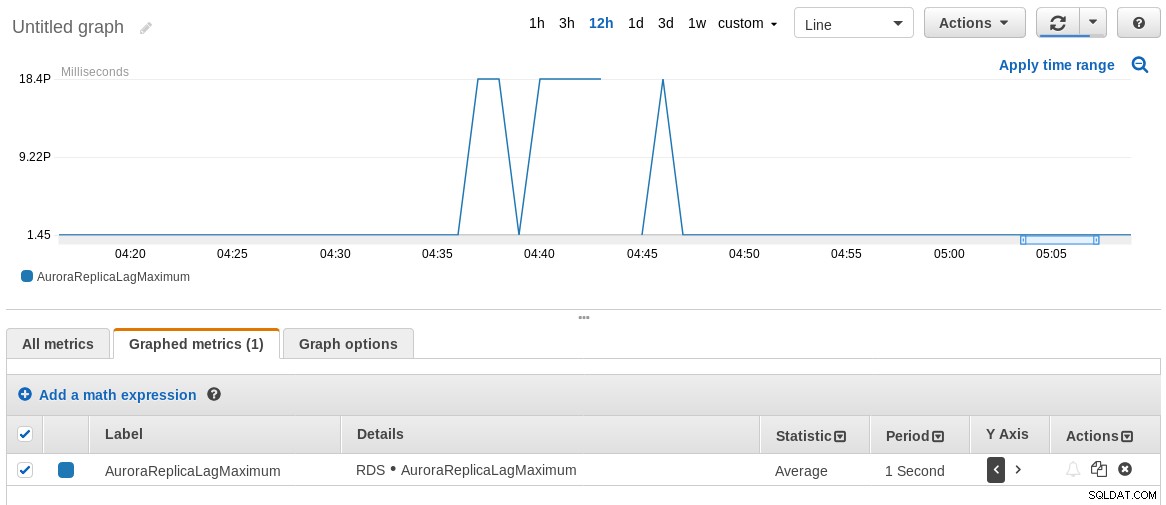 Wykres maksymalnego opóźnienia repliki RDS CloudWatch
Wykres maksymalnego opóźnienia repliki RDS CloudWatch Bezpieczeństwo
-
Szyfrowanie jest dostępne i musi być włączone podczas tworzenia bazy danych, ponieważ nie można go później zmienić.
Rozwiązywanie problemów
Ta krótka sekcja jest ważna. Upewnij się, że pamięć work_mem PostgreSQL jest odpowiednio dostrojona, aby operacje sortowania nie zapisywały danych na dysku.
Konfiguracja
Wystarczy postępować zgodnie z kreatorem konfiguracji w konsoli AWS:
-
Otwórz Amazon RDS konsola zarządzania.
 Konsola zarządzania RDS
Konsola zarządzania RDS -
Wybierz Amazon Aurora i PostgreSQL wydanie.
 Kreator Aurora PostgreSQL
Kreator Aurora PostgreSQL -
Podaj szczegóły bazy danych i zwróć uwagę na ograniczenia hasła Aurora PostgreSQL:
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@".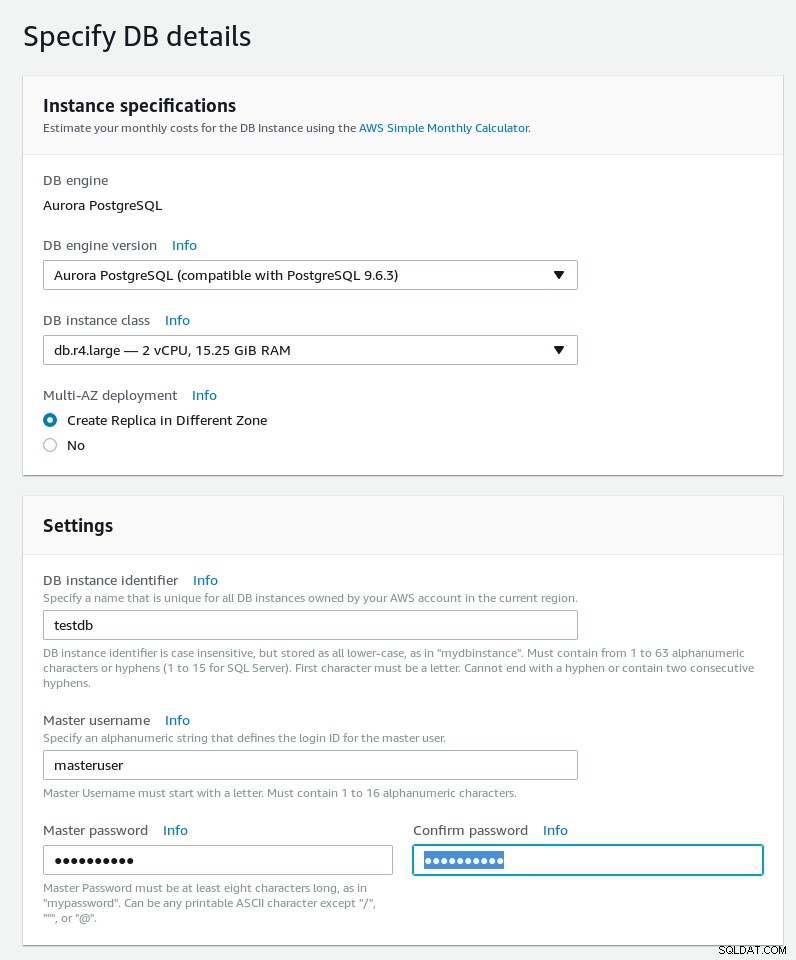 Szczegóły bazy danych kreatora Aurora PostgreSQL
Szczegóły bazy danych kreatora Aurora PostgreSQL -
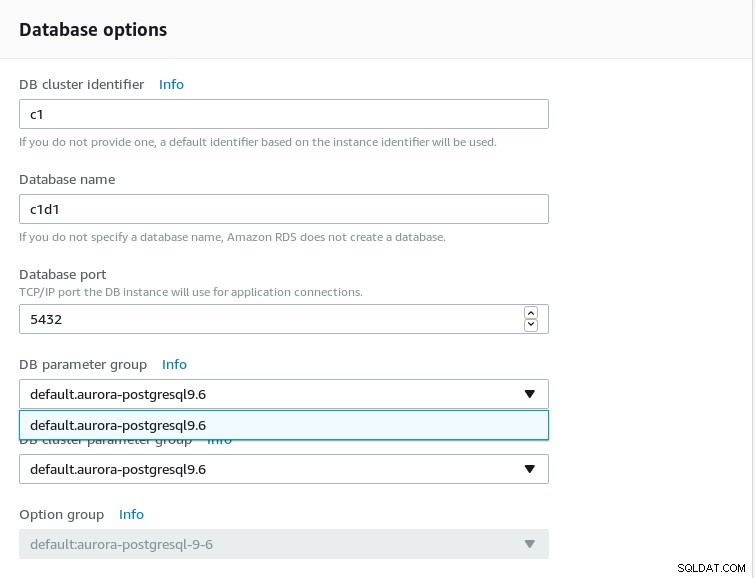
Skonfiguruj opcje bazy danych:
- W chwili pisania tego tekstu dostępny jest tylko PostgreSQL 9.6. Użyj PostgreSQL na Amazon RDS, jeśli potrzebujesz wsparcia dla nowszych wersji, w tym wersji beta.
-
Skonfiguruj priorytet przełączania awaryjnego i wybierz liczbę replik.
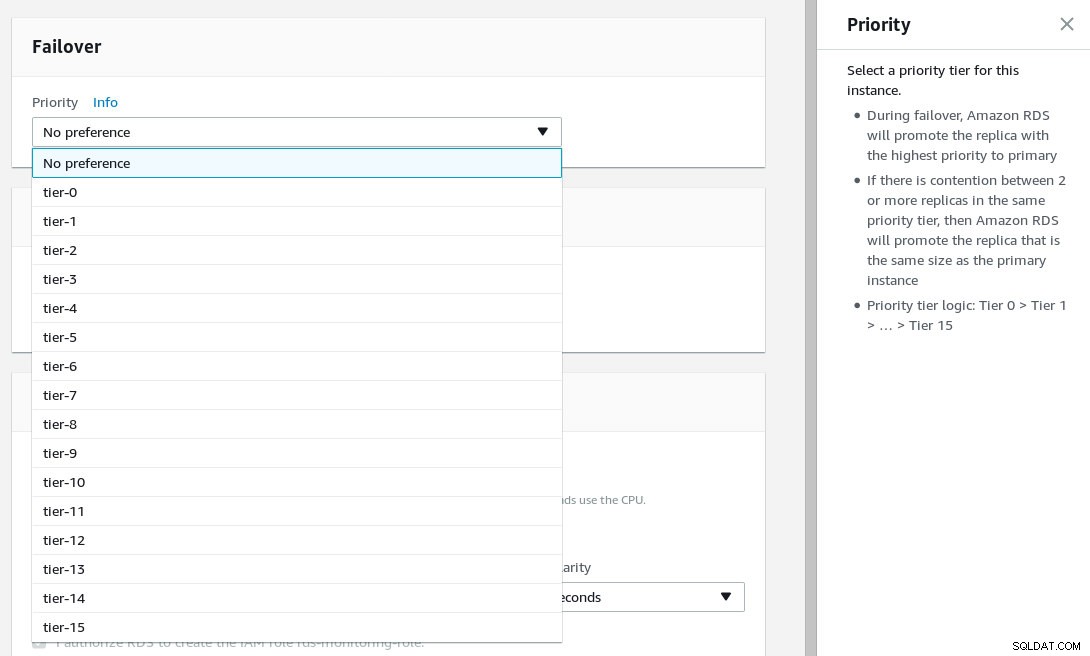 Opis zdjęcia
Opis zdjęcia -
Ustaw przechowywanie kopii zapasowej (maksymalnie 35 dni).
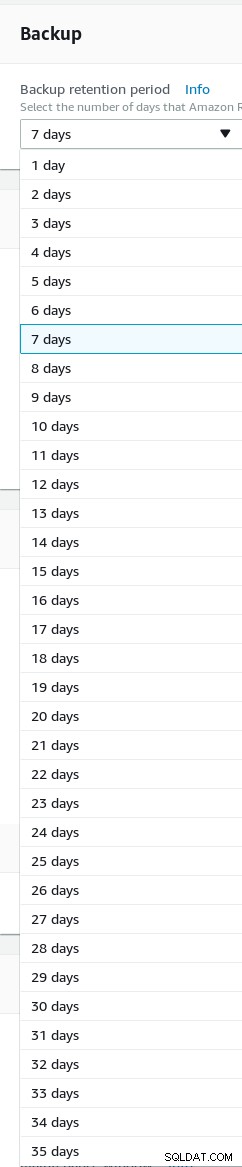 Przechowywanie kopii zapasowych kreatora Aurora PostgreSQL
Przechowywanie kopii zapasowych kreatora Aurora PostgreSQL -
Wybierz harmonogram konserwacji. Dostępne są automatyczne aktualizacje mniejszych wersji, jednak ważne jest, aby zweryfikować przy wsparciu AWS, czy harmonogram poprawek może zostać przyspieszony w przypadku, gdy projekt PostgreSQL wyda jakieś pilne aktualizacje. Na przykład przesłanie aktualizacji 2018-05-10 zajęło AWS ponad dwa miesiące.
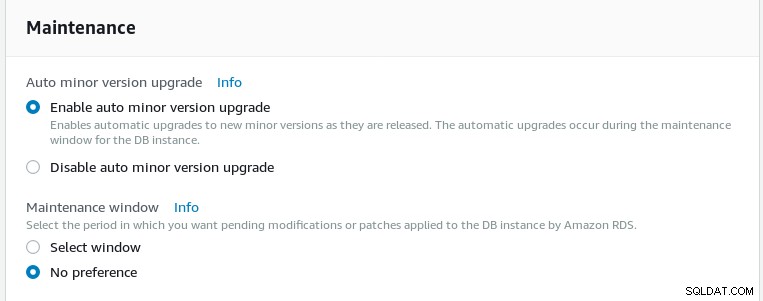 Harmonogram konserwacji kreatora Aurora PostgreSQL
Harmonogram konserwacji kreatora Aurora PostgreSQL -
Jeśli baza danych została pomyślnie utworzona, zostanie wyświetlony link do instrukcji, jak się z nią połączyć:
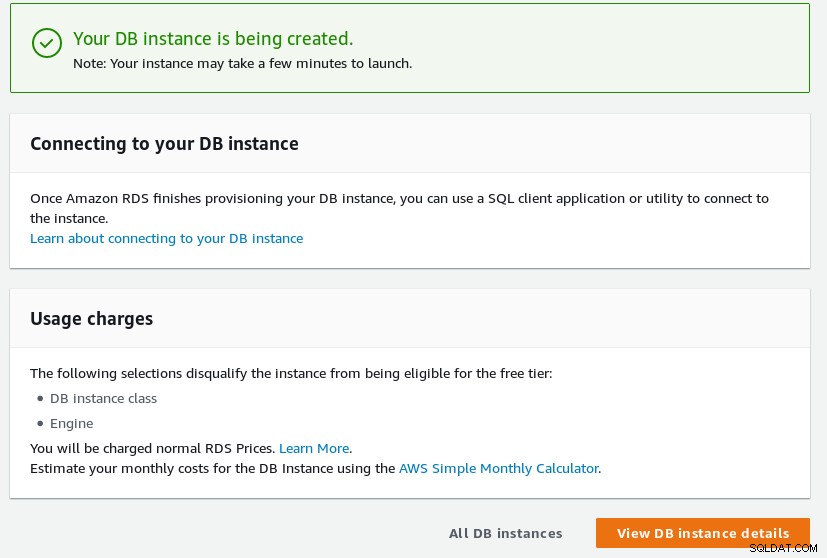 Konfiguracja kreatora Aurora PostgreSQL zakończona
Konfiguracja kreatora Aurora PostgreSQL zakończona
Łączenie z bazą danych
Przejrzyj szczegółowe instrukcje dotyczące dostępnych opcji połączeń w oparciu o konfigurację infrastruktury. W najprostszym scenariuszu połączenie odbywa się za pośrednictwem publicznej instancji EC2.
Uwaga:klient musi być zgodny z PostgreSQL 9.6.3 lub nowszym.
[example@sqldat.com ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Monitorowanie
Amazon zapewnia różne metryki do monitorowania bazy danych, poniższy przykład pokazujący metryki instancji:
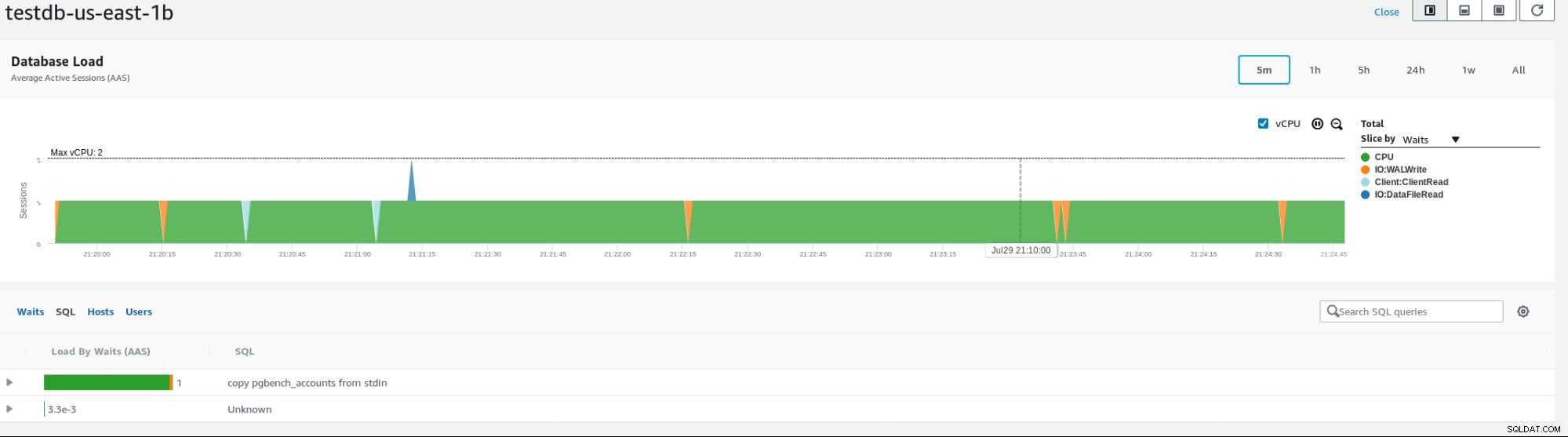 Dane wystąpienia RDSPobierz raport na dziś zarządzaj i skaluj PostgreSQLPobierz raport
Dane wystąpienia RDSPobierz raport na dziś zarządzaj i skaluj PostgreSQLPobierz raport RDS dla PostgreSQL
Jest to oferta pozwalająca na większą szczegółowość pod względem wyboru konfiguracji. Na przykład, w przeciwieństwie do Aurory, która korzysta z zastrzeżonego systemu pamięci masowej, RDS oferuje konfigurowalne przechowywanie przy użyciu woluminów EBS, które mogą być albo dyskami SSD ogólnego przeznaczenia (GP2), aprowizowanymi IOPS, albo magnetycznymi (niezalecane).
Aby wspomóc duże instalacje, wymagające dostosowania niedostępnego w ofercie Aurora, Amazon opublikował niedawno zalecenia dotyczące najlepszych praktyk, dostępne tylko dla RDS.
Wysoka dostępność musi być skonfigurowana ręcznie (lub zautomatyzowana przy użyciu dowolnego ze znanych narzędzi AWS) i zaleca się skonfigurowanie wdrożenia Multi-AZ.
Replikacja jest implementowana przy użyciu natywnej replikacji PostgreSQL.
Istnieją pewne ograniczenia dotyczące instancji PostgreSQL DB, które należy wziąć pod uwagę.
Mając na uwadze powyższe uwagi, oto przewodnik po konfiguracji środowiska RDS PostgreSQL Multi-AZ:
-
Z konsoli zarządzania RDS uruchom kreatora
 Kreator RDS PostgreSQL
Kreator RDS PostgreSQL -
Wybierz między konfiguracją produkcyjną a programistyczną.
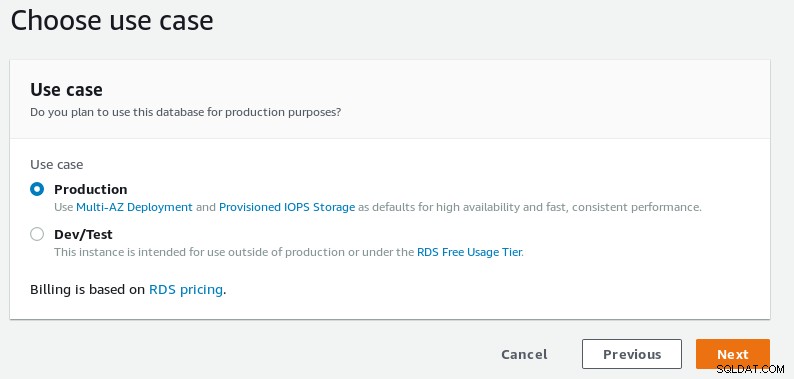 Wybór przypadków użycia bazy danych kreatora RDS PostgreSQL
Wybór przypadków użycia bazy danych kreatora RDS PostgreSQL -
Wprowadź szczegółowe informacje o nowym klastrze bazy danych.
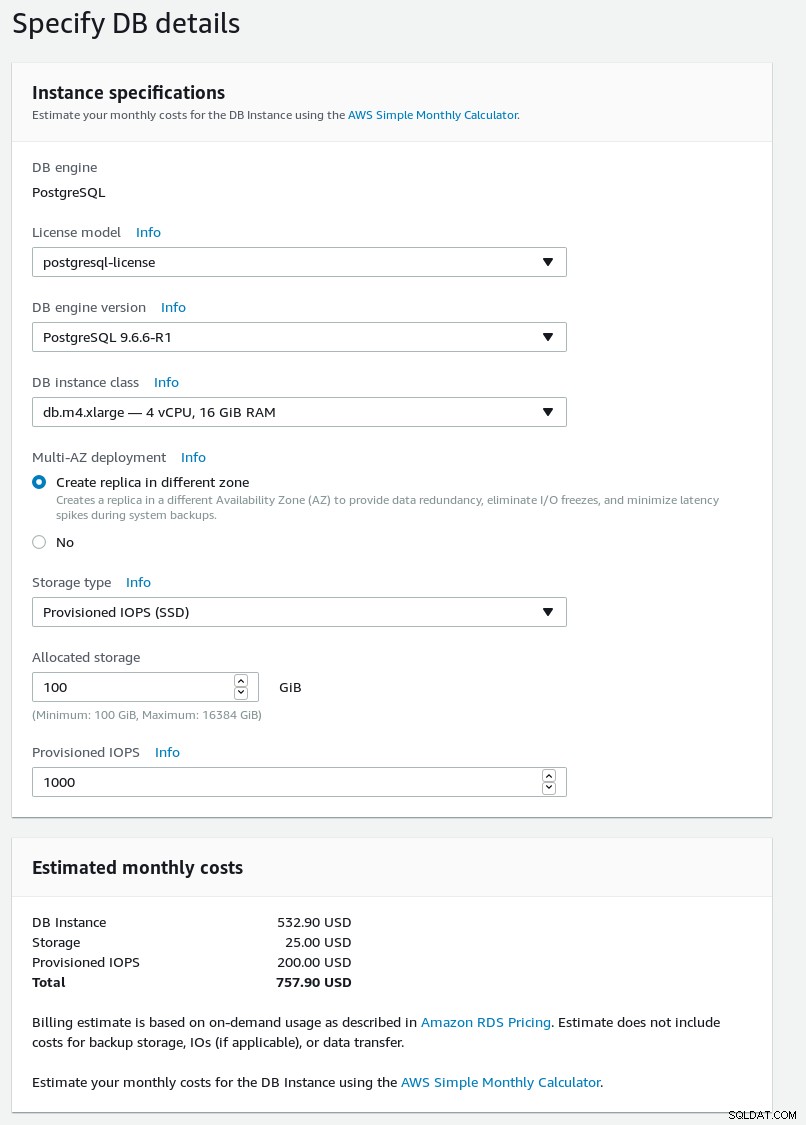 Szczegóły bazy danych kreatora RDS PostgreSQL
Szczegóły bazy danych kreatora RDS PostgreSQL 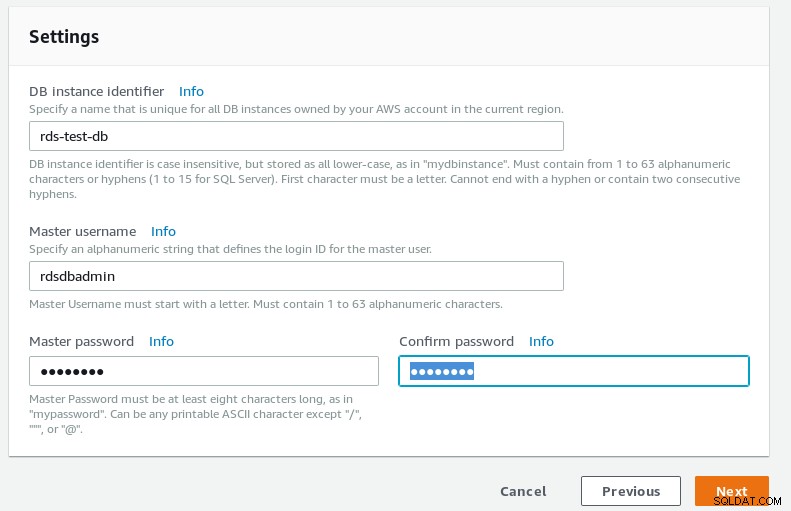 Ustawienia bazy danych kreatora RDS PostgreSQL
Ustawienia bazy danych kreatora RDS PostgreSQL -
Na następnej stronie skonfiguruj harmonogram sieci, zabezpieczeń i konserwacji:
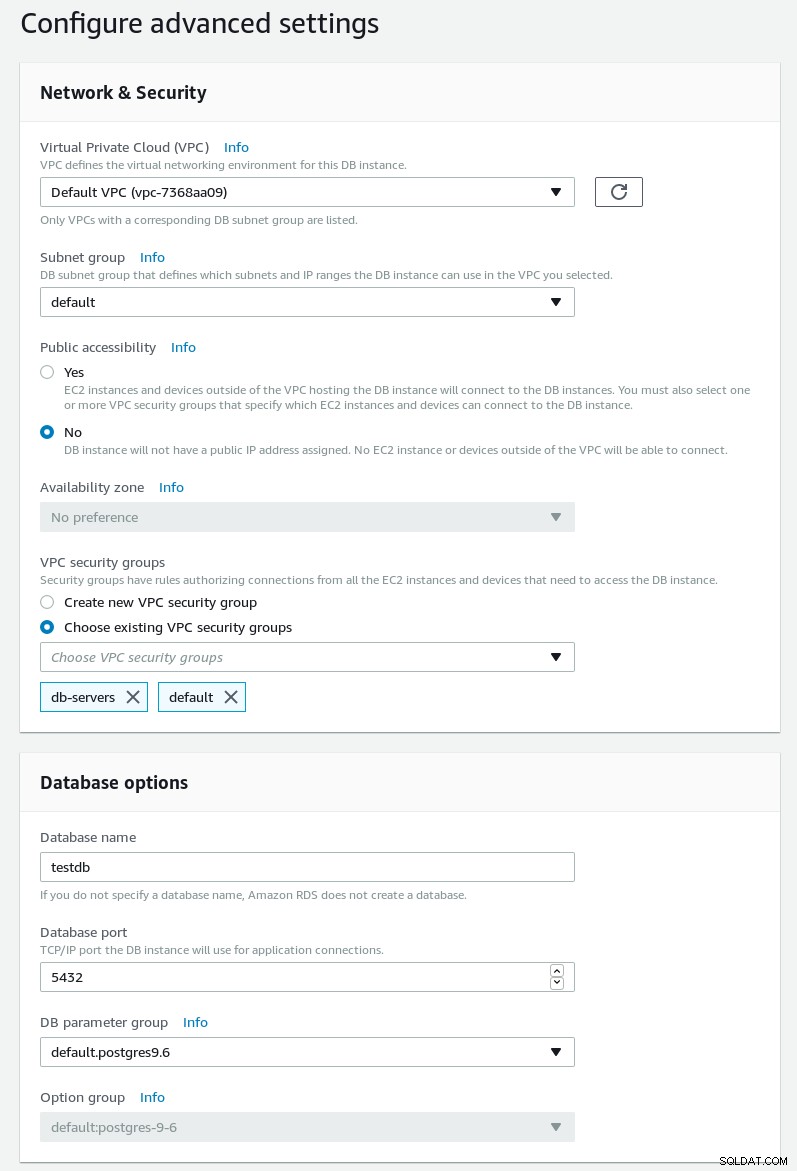 Zaawansowane ustawienia kreatora RDS PostgreSQL
Zaawansowane ustawienia kreatora RDS PostgreSQL  Bezpieczeństwo i konserwacja kreatora RDS PostgreSQL
Bezpieczeństwo i konserwacja kreatora RDS PostgreSQL
Wniosek
Usługi Amazon RDS dla PostgreSQL obejmują RDS PostgreSQL i Aurora PostgreSQL, które są zarządzanymi ofertami DaaS. Wyposażone w wiele funkcji i solidną pamięć masową zaplecza, mają pewne ograniczenia w porównaniu z tradycyjną konfiguracją, jednak przy starannym planowaniu te oferty mogą zapewnić dobrze zrównoważony stosunek kosztów do funkcjonalności. Amazon RDS dla PostgreSQL jest przeznaczony dla użytkowników wymagających większej liczby opcji konfiguracji swoich środowisk i generalnie jest droższy. Większość użytkowników skorzysta na uruchomieniu z Aurora PostgreSQL i przejdzie do bardziej złożonych konfiguracji.