W przypadku Disaster Recovery dążymy do skonfigurowania systemów do obsługi wszystkiego, co może pójść nie tak z naszą bazą danych. Co się stanie, jeśli baza danych ulegnie awarii? Co się stanie, jeśli programista przypadkowo skróci tabelę? Co jeśli dowiemy się, że niektóre dane zostały usunięte w zeszłym tygodniu, ale nie zauważyliśmy ich do dziś? Takie rzeczy się zdarzają, a posiadanie solidnego planu i systemu sprawi, że DBA będzie wyglądał jak bohater, gdy serca wszystkich innych już się zatrzymały, gdy katastrofa podnosi swoją brzydką głowę.
Każda baza danych, która ma jakąkolwiek wartość, powinna mieć sposób na zaimplementowanie jednej lub więcej opcji odzyskiwania po awarii. PostgreSQL ma wbudowany bardzo solidny system replikacji i jest wystarczająco elastyczny, aby można go było skonfigurować w wielu konfiguracjach, aby wspomóc odzyskiwanie po awarii, gdyby coś poszło nie tak. Skoncentrujemy się na scenariuszach takich jak kwestionowane powyżej, jak skonfigurować nasze opcje odzyskiwania po awarii i korzyściach z każdego rozwiązania.
Wysoka dostępność
Dzięki replikacji strumieniowej w PostgreSQL, wysoka dostępność jest prosta w konfiguracji i utrzymaniu. Celem jest udostępnienie witryny przełączania awaryjnego, którą można awansować do stanu master, jeśli główna baza danych przestanie działać z jakiegokolwiek powodu, takiego jak awaria sprzętu, awaria oprogramowania, a nawet awaria sieci. Hostowanie repliki na innym hoście jest świetne, ale hostowanie jej w innym centrum danych jest jeszcze lepsze.
Aby uzyskać szczegółowe informacje na temat konfigurowania replikacji strumieniowej, Manynines udostępnia szczegółowe szczegółowe informacje na temat głębokiego nurkowania dostępne tutaj. Oficjalna dokumentacja replikacji strumieniowej PostgreSQL zawiera szczegółowe informacje na temat protokołu replikacji strumieniowej i tego, jak to wszystko działa.
Standardowa konfiguracja będzie wyglądać tak, główna baza danych akceptująca połączenia odczytu/zapisu, z repliką bazy danych odbierającą całą aktywność WAL w czasie zbliżonym do rzeczywistego, odtwarzającą wszystkie zmiany danych lokalnie.
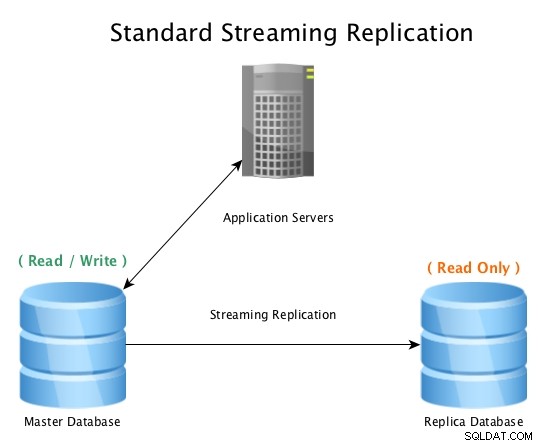 Standardowa replikacja strumieniowa z PostgreSQL
Standardowa replikacja strumieniowa z PostgreSQL Gdy baza danych master staje się bezużyteczna, inicjowana jest procedura przełączania awaryjnego, aby przełączyć ją w tryb offline i promować bazę danych repliki do master, a następnie skierować wszystkie połączenia do nowo promowanego hosta. Można to zrobić poprzez zmianę konfiguracji systemu równoważenia obciążenia, konfiguracji aplikacji, aliasów IP lub innych sprytnych sposobów przekierowania ruchu.
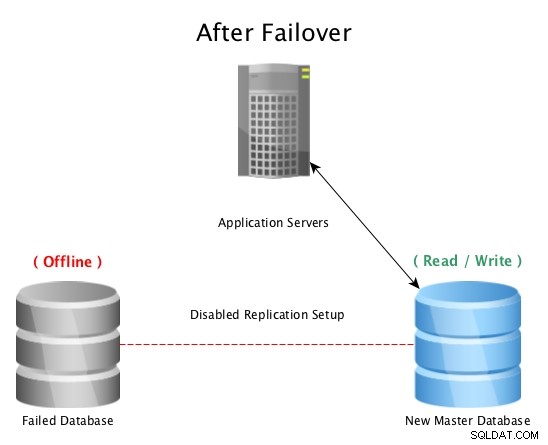 Po przełączeniu awaryjnym z replikacją strumieniową PostgreSQL
Po przełączeniu awaryjnym z replikacją strumieniową PostgreSQL W przypadku awarii głównej bazy danych (takiej jak awaria dysku twardego, przerwa w dostawie prądu lub cokolwiek, co uniemożliwia pracę mastera zgodnie z przeznaczeniem), przełączenie awaryjne na tryb gotowości jest najszybszym sposobem, aby pozostać w trybie online, obsługując zapytania do aplikacji lub klientów bez poważnych problemów. przestój. Rozpoczyna się wtedy wyścig o naprawienie uszkodzonego hosta bazy danych lub wprowadzenie nowej repliki w tryb online, aby zachować sieć bezpieczeństwa w postaci gotowości do pracy. Posiadanie wielu stanów gotowości zapewni, że okno po katastrofalnej awarii będzie również gotowe na wtórną awarię, jakkolwiek mało prawdopodobne może się to wydawać.
Uwaga:w przypadku przełączenia awaryjnego na replikę strumieniową rozpocznie się w miejscu, w którym przerwał poprzedni master, co pomaga w utrzymaniu bazy danych w trybie online, ale nie w odzyskiwaniu przypadkowo utraconych danych.
Odzyskiwanie punktu w czasie
Inną opcją odzyskiwania po awarii jest odzyskiwanie punktu w czasie (PITR). Dzięki PITR kopię bazy danych można przywrócić w dowolnym momencie, o ile mamy podstawową kopię zapasową sprzed tego czasu i wszystkie segmenty WAL potrzebne do tego czasu.
Opcja odzyskiwania do punktu w czasie nie jest tak szybko wprowadzana do trybu online jak Hot Standby, jednak główną korzyścią jest możliwość odzyskania migawki bazy danych przed dużym wydarzeniem, takim jak usunięta tabela, wstawienie nieprawidłowych danych, a nawet niewytłumaczalne uszkodzenie danych . Wszystko, co zniszczyłoby dane w taki sposób, w jaki chcielibyśmy uzyskać kopię przed tym zniszczeniem, PITR ratuje sytuację.
Odzyskiwanie punktu w czasie działa poprzez tworzenie okresowych migawek bazy danych, zwykle za pomocą programu pg_basebackup, i przechowywanie zarchiwizowanych kopii wszystkich plików WAL wygenerowanych przez mastera
Konfiguracja odzyskiwania punktu w czasie
Instalator wymaga kilku opcji konfiguracyjnych ustawionych na urządzeniu głównym, z których niektóre dobrze są zgodne z wartościami domyślnymi w aktualnej najnowszej wersji PostgreSQL 11. W tym przykładzie skopiujemy plik 16 MB bezpośrednio do naszego zdalnego hosta PITR za pomocą rsync i skompresowanie ich po drugiej stronie za pomocą zadania cron.
Archiwizacja WAL
Mistrz postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'UWAGA: Ustawienie archive_command może obejmować wiele rzeczy, ogólnym celem jest wysłanie wszystkich zarchiwizowanych plików WAL na inny host ze względów bezpieczeństwa. Jeśli stracimy jakiekolwiek pliki WAL, PITR za utraconym plikiem WAL stanie się niemożliwy. Niech Twoja kreatywność programistyczna oszaleje, ale upewnij się, że jest niezawodna.
[Opcjonalnie] Skompresuj zarchiwizowane pliki WAL:
Każda konfiguracja będzie się nieco różnić, ale jeśli dana baza danych nie jest bardzo uboga w aktualizacje danych, nagromadzenie 16 MB plików dość szybko zapełni miejsce na dysku. Łatwy skrypt kompresji, skonfigurowany przez cron, może wyglądać jak poniżej.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]UWAGA: Podczas dowolnej metody odzyskiwania wszystkie skompresowane pliki będą musiały zostać później zdekompresowane. Niektórzy administratorzy decydują się na kompresowanie plików tylko po ich X dniach, utrzymując ogólną małą ilość miejsca, ale także zachowując nowsze pliki WAL gotowe do odzyskania bez dodatkowej pracy. Wybierz najlepszą opcję dla danych baz danych, aby zmaksymalizować szybkość odzyskiwania.
Podstawowe kopie zapasowe
Jednym z kluczowych elementów kopii zapasowej PITR jest podstawowa kopia zapasowa i częstotliwość wykonywania podstawowych kopii zapasowych. Mogą to być godziny, dni, tygodnie, miesiące, ale wybierz najlepszą opcję w oparciu o potrzeby odzyskiwania, a także ruch danych w bazie danych. Jeśli w każdą niedzielę mamy cotygodniowe kopie zapasowe i musimy odzyskać dane aż do sobotniego popołudnia, wówczas udostępniamy online podstawową kopię zapasową z poprzedniej niedzieli ze wszystkimi plikami WAL między tą kopią zapasową a sobotnim popołudniem. Jeśli ten proces odzyskiwania zajmie 10 godzin, jest to prawdopodobnie niepożądanie zbyt długi. Codzienne kopie zapasowe skrócą ten czas odzyskiwania, ponieważ podstawowa kopia zapasowa będzie pochodzić z tego ranka, ale także zwiększy nakład pracy na hoście dla podstawowej kopii zapasowej się.
Jeśli tygodniowe odzyskiwanie plików WAL zajmuje tylko kilka minut, ponieważ baza danych odnotowuje niski churn, cotygodniowe kopie zapasowe są w porządku. Te same dane będą w końcu istnieć, ale kluczem jest to, jak szybko będziesz w stanie uzyskać do nich dostęp.
W naszym przykładzie skonfigurujemy cotygodniową podstawową kopię zapasową, a ponieważ korzystamy z replikacji strumieniowej w celu zapewnienia wysokiej dostępności, a także zmniejszamy obciążenie urządzenia głównego, utworzymy podstawową kopię zapasową z bazy danych repliki.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zUWAGA: Polecenie pg_basebackup zakłada, że ten host jest skonfigurowany do dostępu bez hasła do „replikacji” użytkownika na urządzeniu głównym, co można zrobić przez „zaufanie” w pg_hba dla tego hosta kopii zapasowej PITR, hasło w pliku .pgpass lub w inny bezpieczniejszy sposób . Pamiętaj o bezpieczeństwie podczas tworzenia kopii zapasowych.
Konfiguracja odzyskiwania do punktu w czasie to tylko część pracy, a konieczność odzyskania danych to druga część. Przy odrobinie szczęścia może się to nigdy nie zdarzyć, jednak zaleca się okresowe przywracanie kopii zapasowej PITR w celu sprawdzenia, czy system działa, i upewnienia się, że proces jest znany / poprawnie oskryptowany.
W naszym scenariuszu testowym wybierzemy punkt w czasie do odzyskania i zainicjujemy proces odzyskiwania. Na przykład:w piątek rano programista wprowadza nową zmianę w kodzie do środowiska produkcyjnego bez przechodzenia przez jego przegląd, co powoduje zniszczenie szeregu ważnych danych klientów. Ponieważ nasze Hot Standby jest zawsze zsynchronizowane z masterem, przełączenie się na niego niczego nie naprawi, ponieważ byłyby to te same dane. Kopie zapasowe PITR nas uratują.
Kod został wysłany o 11 rano, więc musimy przywrócić bazę danych tuż przed tą godziną, o 10:59, o której decydujemy, i na szczęście robimy codzienne kopie zapasowe, więc mamy kopię zapasową z północy dzisiejszego ranka. Ponieważ nie wiemy, co zostało zniszczone, decydujemy się również na pełne przywrócenie tej bazy danych na naszym hoście PITR i udostępnienie jej online jako master, ponieważ ma takie same specyfikacje sprzętowe jak master, na wszelki wypadek zdarzył się scenariusz.
Zamknij Mistrza
Ponieważ zdecydowaliśmy się na pełne przywracanie z kopii zapasowej i promowanie jej do stanu master, nie ma potrzeby utrzymywania tego w trybie online. Wyłączamy go, ale trzymamy go na wypadek, gdybyśmy musieli coś z niego później pobrać, na wszelki wypadek.
Skonfiguruj podstawową kopię zapasową do odzyskiwania
Następnie na naszym hoście PITR pobieramy naszą najnowszą podstawową kopię zapasową sprzed wydarzenia, czyli kopię zapasową „2018-12-21_backup”.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Dzięki temu podstawowa kopia zapasowa, a także pliki WAL dostarczone przez pg_basebackup są gotowe do użycia, jeśli teraz udostępnimy je online, przywróci to miejsce, w którym miała miejsce kopia zapasowa, ale chcemy odzyskać wszystkie transakcje WAL między o północy i 11:59, więc ustawiliśmy nasz plik recovery.conf.
Utwórz plik recovery.conf
Ponieważ ta kopia zapasowa faktycznie pochodzi z repliki strumieniowej, prawdopodobnie istnieje już plik recovery.conf z ustawieniami repliki. Nadpiszemy go nowymi ustawieniami. Szczegółowa lista informacji dla wszystkich różnych opcji jest dostępna w dokumentacji PostgreSQL tutaj.
Uważając na pliki WAL, polecenie restore skopiuje potrzebne pliki skompresowane do katalogu przywracania, rozpakuje je, a następnie przeniesie tam, gdzie PostgreSQL potrzebuje ich do odzyskania. Oryginalne pliki WAL pozostaną tam, gdzie są potrzebne z innych powodów.
Nowy plik recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Rozpocznij proces odzyskiwania
Teraz, gdy wszystko jest skonfigurowane, rozpoczniemy proces odzyskiwania. Kiedy tak się dzieje, dobrym pomysłem jest śledzenie dziennika bazy danych, aby upewnić się, że przywraca się zgodnie z przeznaczeniem.
Uruchom bazę danych:
pg_ctl -D /var/lib/pgsql/11/data startTail dzienniki:
Będzie wiele wpisów w dzienniku pokazujących, że baza danych odzyskuje dane z plików archiwów, a w pewnym momencie pojawi się wiersz z napisem „odzyskiwanie zatrzymane przed zatwierdzeniem transakcji…”
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07W tym momencie proces odzyskiwania pochłonął wszystkie pliki WAL, ale wymaga również sprawdzenia, zanim zostanie udostępniony online jako master. W tym przykładzie dziennik odnotowuje, że następną transakcją po docelowym czasie odzyskiwania 11:59:00 była 11:59:01 i nie została odzyskana. Aby zweryfikować, zaloguj się do bazy danych i sprawdź, czy działająca baza danych powinna być migawką dokładnie z 11:59.
Kiedy wszystko wygląda dobrze, nadszedł czas, aby promować powrót do zdrowia jako mistrz.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Teraz baza danych jest w trybie online, przywrócona do punktu, w którym zdecydowaliśmy, i akceptuje połączenia odczytu/zapisu jako węzeł główny. Upewnij się, że wszystkie parametry konfiguracyjne są poprawne i gotowe do produkcji.
Baza danych jest online, ale proces odzyskiwania jeszcze się nie zakończył! Teraz, gdy ta kopia zapasowa PITR jest w trybie online jako główna, należy skonfigurować nową konfigurację gotowości i PITR, do tego czasu ta nowa kopia zapasowa może być w trybie online i obsługiwać aplikacje, ale nie jest zabezpieczona przed kolejną awarią, dopóki wszystko nie zostanie ponownie skonfigurowane.
Inne scenariusze odzyskiwania punktu w czasie
Przywrócenie kopii zapasowej PITR dla całej bazy danych jest przypadkiem ekstremalnym, ale istnieją inne scenariusze, w których brakuje tylko podzbioru danych, są one uszkodzone lub uszkodzone. W takich przypadkach możemy wykazać się kreatywnością, korzystając z naszych opcji odzyskiwania. Bez przełączania mastera w tryb offline i zastępowania go kopią zapasową, możemy przenieść kopię zapasową PITR online w żądanym czasie na innym hoście (lub innym porcie, jeśli nie ma problemu z miejscem) i bezpośrednio wyeksportować odzyskane dane z kopii zapasowej do głównej bazy danych. Można to wykorzystać do odzyskania kilku wierszy, kilku tabel lub dowolnej potrzebnej konfiguracji danych.
Dzięki replikacji strumieniowej i przywracaniu do punktu w czasie, PostgreSQL zapewnia nam dużą elastyczność w zapewnieniu, że możemy odzyskać wszelkie potrzebne nam dane, o ile mamy hosty w trybie gotowości gotowe do pracy jako master lub kopie zapasowe gotowe do odzyskania. Dobrą opcję odzyskiwania po awarii można dodatkowo rozszerzyć o inne opcje tworzenia kopii zapasowych, większą liczbę węzłów replik, wiele lokalizacji kopii zapasowych w różnych centrach danych i kontynentach, okresowe zrzuty pg_dump w innej replice itp.
Te opcje mogą się sumować, ale prawdziwe pytanie brzmi „jak cenne są dane i ile chcesz wydać, aby je odzyskać?”. W wielu przypadkach utrata danych jest końcem działalności, więc dobre opcje odzyskiwania po awarii powinny być dostępne, aby zapobiec najgorszemu.