W tej trzeciej części Benchmarkingu zarządzanych rozwiązań PostgreSQL w chmurze , skorzystałem z oferty bezpłatnego poziomu Google GCP. To było wartościowe doświadczenie i jako administrator spędzający większość czasu przy konsoli nie mogłem przegapić okazji wypróbowania powłoki chmury, jednej z funkcji konsoli, która odróżnia Google od dostawcy chmury, z którym jestem bardziej zaznajomiony , Amazon Web Services.
Aby szybko podsumować, w części 1 przyjrzałem się dostępnym narzędziom do testów porównawczych i wyjaśniłem, dlaczego wybrałem procedurę testową AWS dla Aurory. Testowałem również Amazon Aurora dla PostgreSQL w wersji 10.6. W części 2 sprawdziłem AWS RDS dla PostgreSQL w wersji 11.1.
Podczas tej rundy testy oparte na AWS Benchmark Procedure dla Aurora zostaną przeprowadzone z Google Cloud SQL dla PostgreSQL 9.6, ponieważ wersja 11.1 jest wciąż w fazie beta.
Instancje w chmurze
Wymagania wstępne
Jak wspomniano w poprzednich dwóch artykułach, zdecydowałem się pozostawić ustawienia PostgreSQL jako domyślne w chmurze GUC, chyba że uniemożliwiają one uruchamianie testów (patrz niżej poniżej). Przypomnij sobie z poprzednich artykułów, że założono, że po wyjęciu z pudełka dostawca chmury powinien mieć skonfigurowaną instancję bazy danych, aby zapewnić rozsądną wydajność.
Łatka czasowa AWS pgbench dla PostgreSQL 9.6.5 została zastosowana w czystej wersji PostgreSQL 9.6.10 dla Google Cloud.
Korzystając z informacji, które Google opublikował na swoim blogu Google Cloud for AWS Professionals, dopasowałem specyfikacje klienta i docelowych instancji w odniesieniu do komponentów Compute, Storage i Networking. Na przykład odpowiednik Ulepszonej sieci AWS w Google Cloud jest osiągany przez zmianę rozmiaru węzła obliczeniowego na podstawie wzoru:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Jeśli chodzi o konfigurowanie docelowej instancji bazy danych, podobnie jak w przypadku AWS, Google Cloud nie zezwala na repliki, jednak pamięć masowa jest szyfrowana w stanie spoczynku i nie ma możliwości jej wyłączenia.
Wreszcie, aby osiągnąć najlepszą wydajność sieci, klient i instancje docelowe muszą znajdować się w tej samej strefie dostępności.
Klient
Specyfikacje instancji klienta pasujące do najbliższej instancji AWS to:
- procesor wirtualny:32 (16 rdzeni x 2 wątki/rdzeń)
- RAM:208 GiB (maksymalnie dla instancji 32 vCPU)
- Pamięć:dysk stały Compute Engine
- Sieć:16 Gb/s (maksymalnie [32 vCPU x 2 Gb/s/vCPU] i 16 Gb/s)
Szczegóły instancji po inicjalizacji:
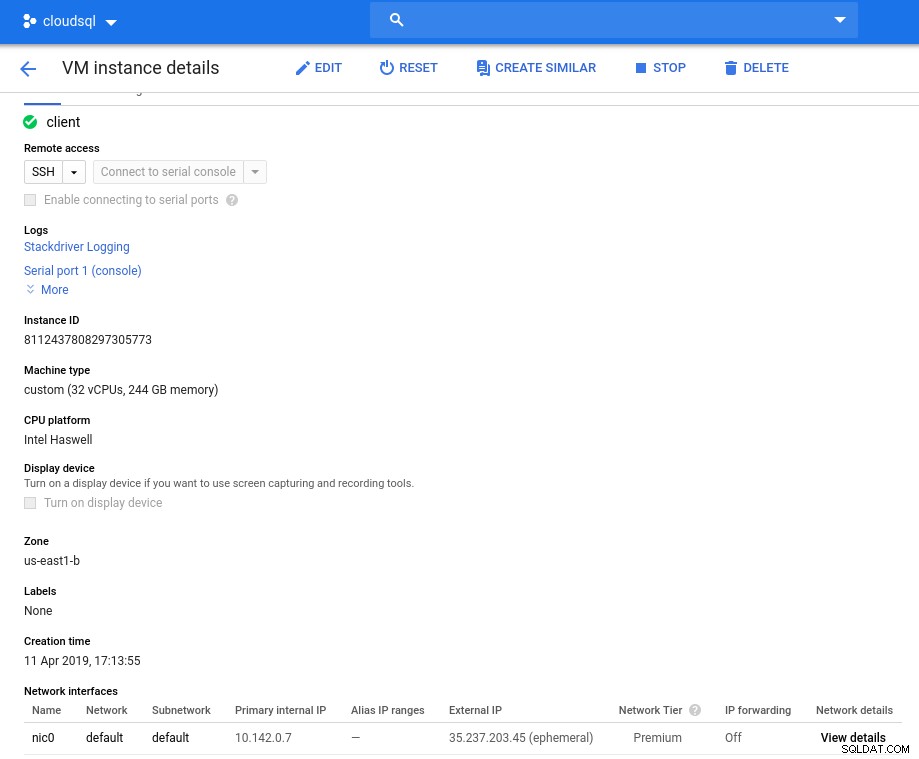 Instancja klienta:obliczenia i sieć
Instancja klienta:obliczenia i sieć Uwaga:Instancje są domyślnie ograniczone do 24 procesorów wirtualnych. Pomoc techniczna Google musi zatwierdzić zwiększenie limitu do 32 procesorów wirtualnych na instancję.

Chociaż takie prośby są zwykle rozpatrywane w ciągu 2 dni roboczych, muszę pochwalić Dział Pomocy Google za wypełnienie mojej prośby w ciągu zaledwie 2 godzin.
Dla ciekawskich, formuła prędkości sieci opiera się na dokumentacji silnika obliczeniowego, do której odwołuje się ten blog GCP.
Klaster DB
Poniżej znajdują się specyfikacje instancji bazy danych:
- procesor wirtualny:8
- RAM:52 GiB (maksymalnie)
- Pamięć:144 MB/s, 9000 IOPS
- Sieć:2000 MB/s
Pamiętaj, że maksymalna dostępna pamięć dla instancji 8 vCPU to 52 GiB. Więcej pamięci można przydzielić, wybierając większą instancję (więcej procesorów wirtualnych):
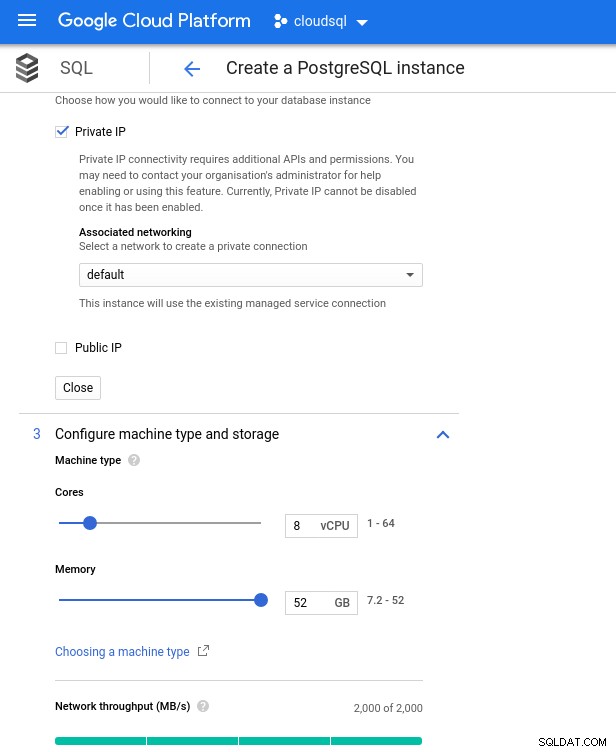 Wymiarowanie procesora bazy danych i pamięci
Wymiarowanie procesora bazy danych i pamięci Chociaż Google SQL może automatycznie rozszerzać podstawową pamięć masową, co, nawiasem mówiąc, jest naprawdę fajną funkcją, zdecydowałem się wyłączyć tę opcję, aby zachować spójność z zestawem funkcji AWS i uniknąć potencjalnego wpływu we/wy podczas operacji zmiany rozmiaru. („potencjalne”, ponieważ nie powinno to mieć żadnego negatywnego wpływu, jednak z mojego doświadczenia wynika, że zmiana rozmiaru dowolnego typu podstawowej pamięci masowej zwiększa I/O, nawet jeśli na kilka sekund).
Przypomnijmy, że instancja bazy danych AWS została utworzona przez zoptymalizowaną pamięć masową EBS, która zapewniała maksymalnie:
- Przepustowość 1700 Mb/s
- Przepustowość 212,5 MB/s
- 12 000 IOPS
W Google Cloud osiągamy podobną konfigurację, dostosowując liczbę procesorów wirtualnych (patrz wyżej) i pojemność pamięci:
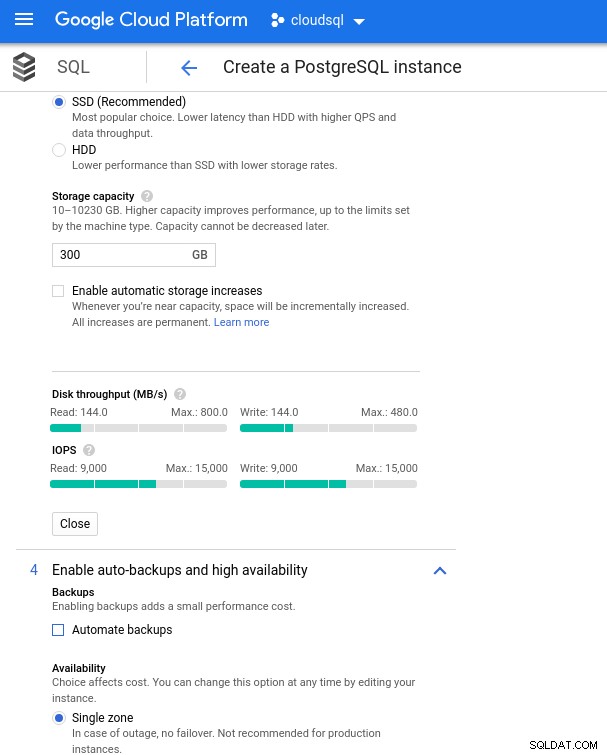 Konfiguracja przechowywania bazy danych i ustawienia kopii zapasowych
Konfiguracja przechowywania bazy danych i ustawienia kopii zapasowych Wykonywanie testów
Konfiguracja
Następnie zainstaluj narzędzia testowe, pgbench i sysbench, postępując zgodnie z instrukcjami w przewodniku Amazon dostosowanym do wersji PostgreSQL 9.6.10.
Zainicjuj zmienne środowiskowe PostgreSQL w .bashrc i ustaw ścieżki do plików binarnych i bibliotek PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libLista kontrolna przed lotem:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)I jesteśmy gotowi do startu:
pgbench
Zainicjuj bazę danych pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…i kilka minut później:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Jak teraz przywykliśmy, rozmiar bazy danych musi wynosić 160 GB. Sprawdźmy, czy:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Po zakończeniu wszystkich przygotowań rozpocznij test odczytu/zapisu:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsUps! Jakie jest maksimum?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Tak więc, podczas gdy AWS ustawia w dużej mierze wystarczającą liczbę max_connections, ponieważ nie napotkałem tego problemu, Google Cloud wymaga niewielkiej poprawki... Wróć do konsoli w chmurze, zaktualizuj parametr bazy danych, poczekaj kilka minut, a następnie sprawdź:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Po ponownym uruchomieniu testu wszystko wydaje się działać dobrze:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...ale jest jeszcze jeden haczyk. Byłem zaskoczony, gdy próbowałem otworzyć nową sesję psql w celu policzenia liczby połączeń:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsCzy to możliwe, że superuser_reserved_connections nie jest ustawiony domyślnie?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)To jest ustawienie domyślne, więc co innego mogłoby to być?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Załatwia to kolejne uderzenie max_connections, jednak wymagało to zrestartowania testu pgbench. I to jest historia kryjąca się za pozornym duplikatem przebiegu na poniższych wykresach.
I wreszcie wyniki są w:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)stół systemowy
Wypełnij bazę danych:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareWyjście:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...A teraz uruchom test:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runA wyniki:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Dane porównawcze
Wtyczka PostgreSQL dla Stackdriver została wycofana 28 lutego 2019 r. Chociaż Google zaleca Blue Medora, na potrzeby tego artykułu zdecydowałem się zrezygnować z tworzenia konta i polegać na dostępnych wskaźnikach Stackdriver.
- Wykorzystanie procesora:
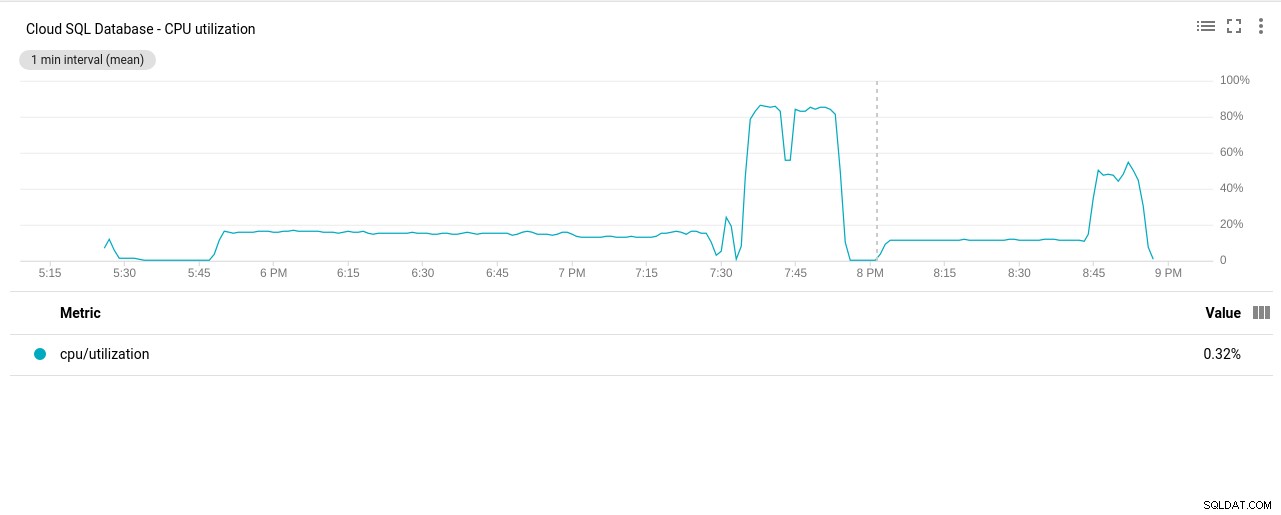 Autor zdjęcia Google Cloud SQL:wykorzystanie procesora PostgreSQL
Autor zdjęcia Google Cloud SQL:wykorzystanie procesora PostgreSQL - Operacje odczytu/zapisu na dysku:
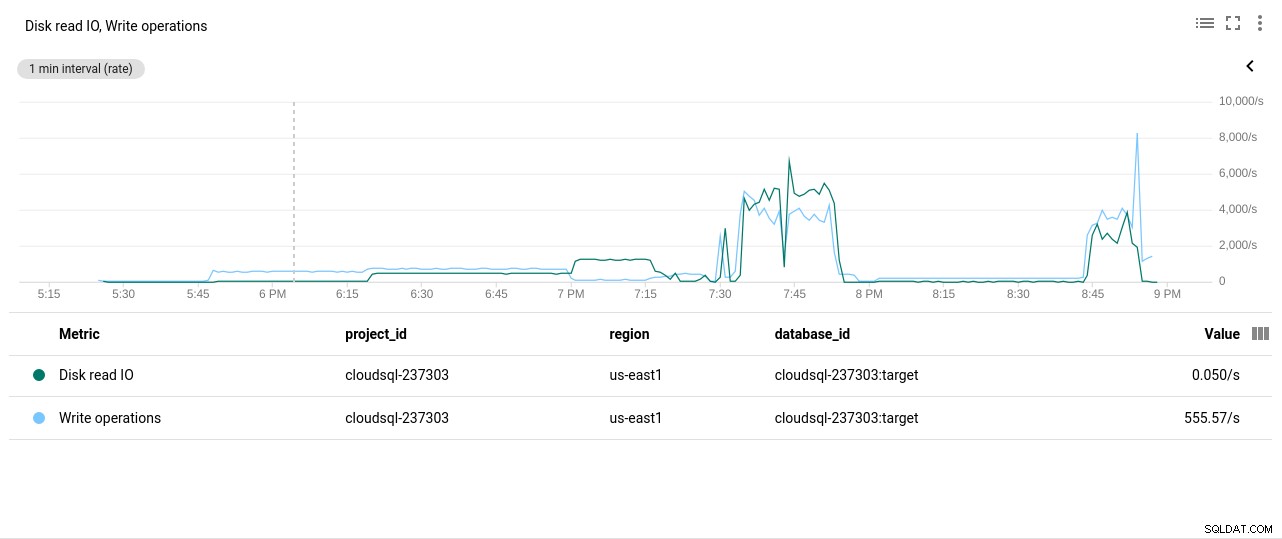 Autor zdjęcia Google Cloud SQL:operacje odczytu/zapisu dysku PostgreSQL
Autor zdjęcia Google Cloud SQL:operacje odczytu/zapisu dysku PostgreSQL - Bajty wysłane/odebrane przez sieć:
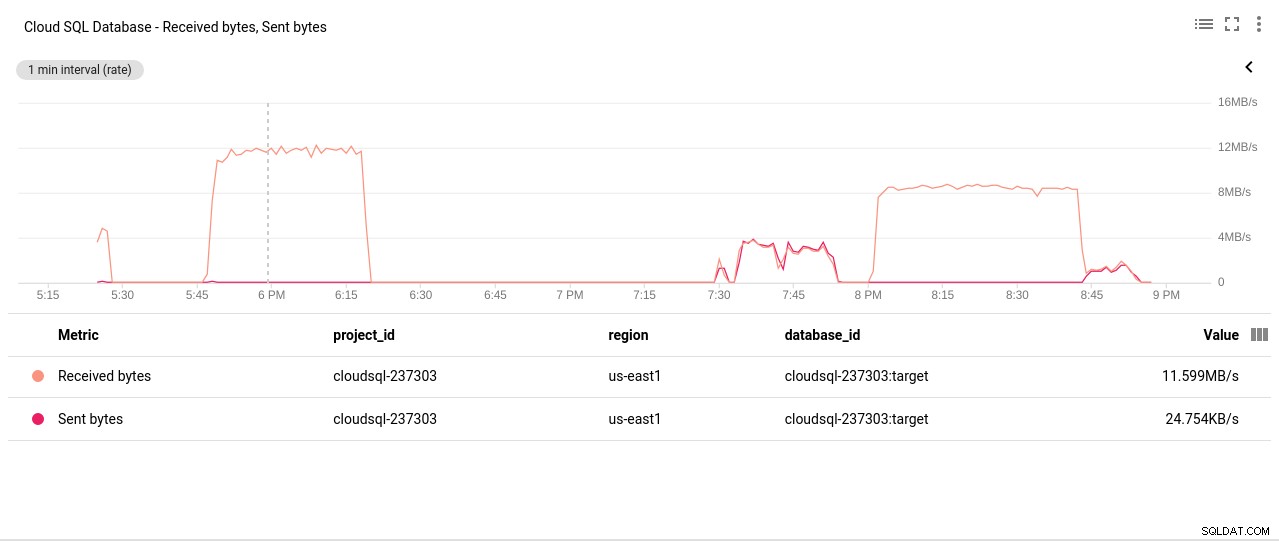 Autor zdjęcia Google Cloud SQL:wysłane/odebrane bajty sieci PostgreSQL
Autor zdjęcia Google Cloud SQL:wysłane/odebrane bajty sieci PostgreSQL - Liczba połączeń PostgreSQL:
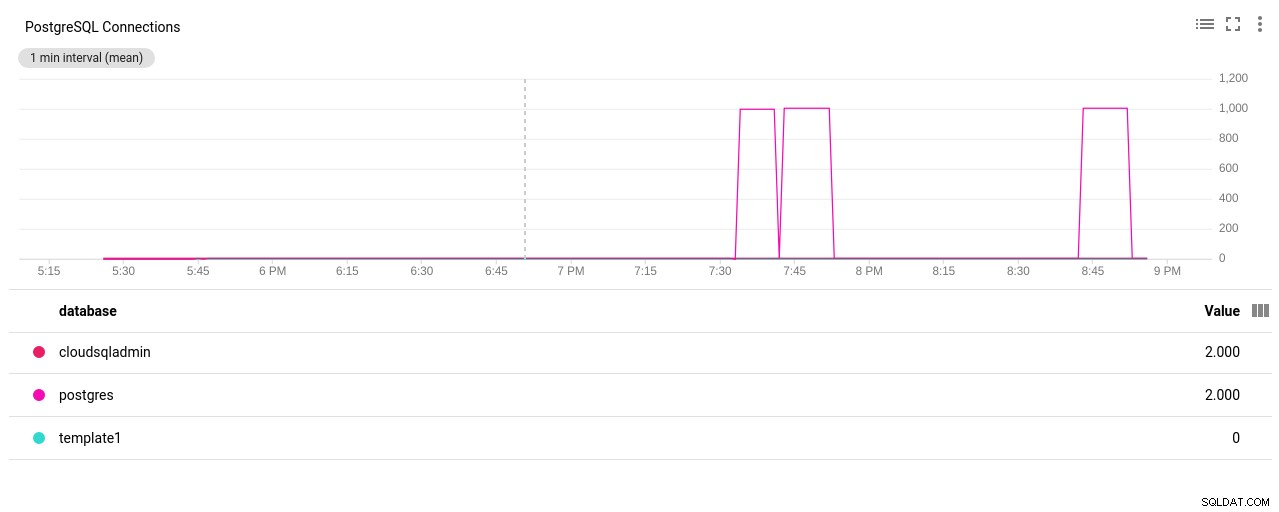 Autor zdjęcia Google Cloud SQL:liczba połączeń PostgreSQL
Autor zdjęcia Google Cloud SQL:liczba połączeń PostgreSQL
Wyniki testu porównawczego
Inicjalizacja pgbench
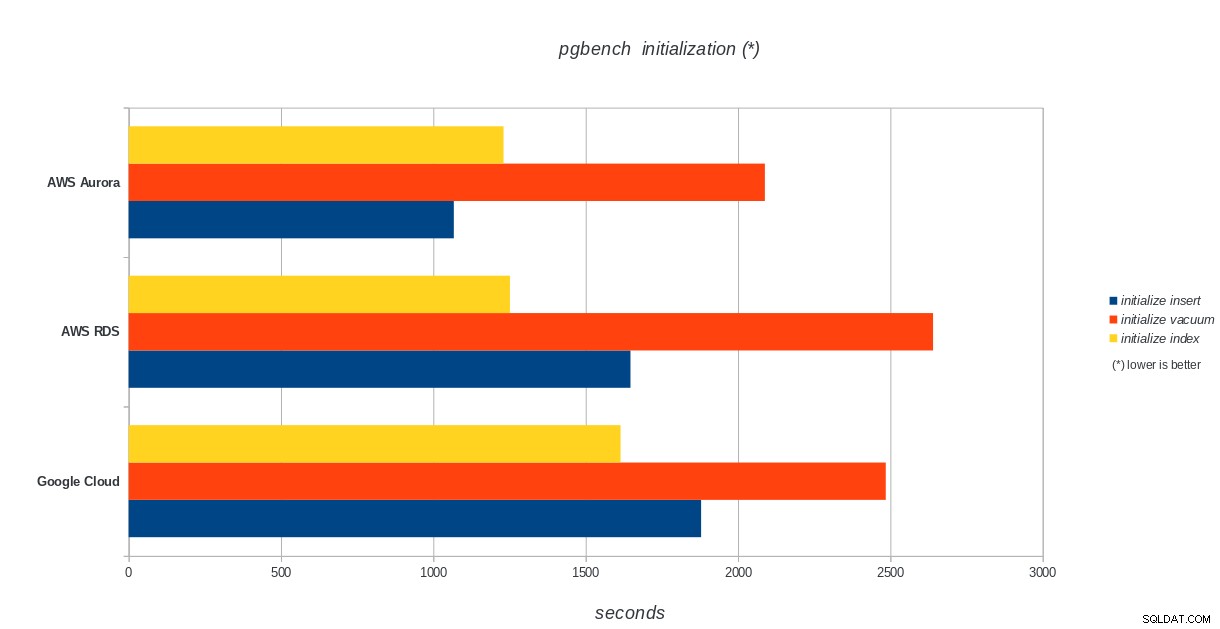 AWS Aurora, AWS RDS, Google Cloud SQL:wyniki inicjalizacji PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:wyniki inicjalizacji PostgreSQL pgbench uruchomienie pgbench
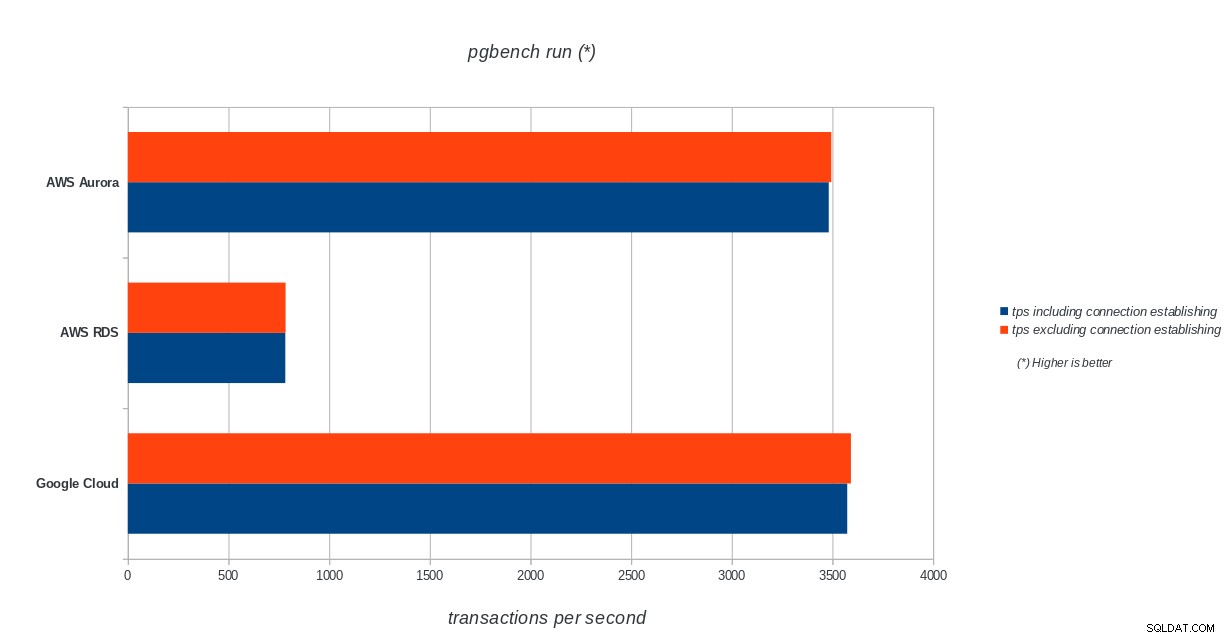 AWS Aurora, AWS RDS, Google Cloud SQL:wyniki uruchomienia PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:wyniki uruchomienia PostgreSQL pgbench stół systemowy
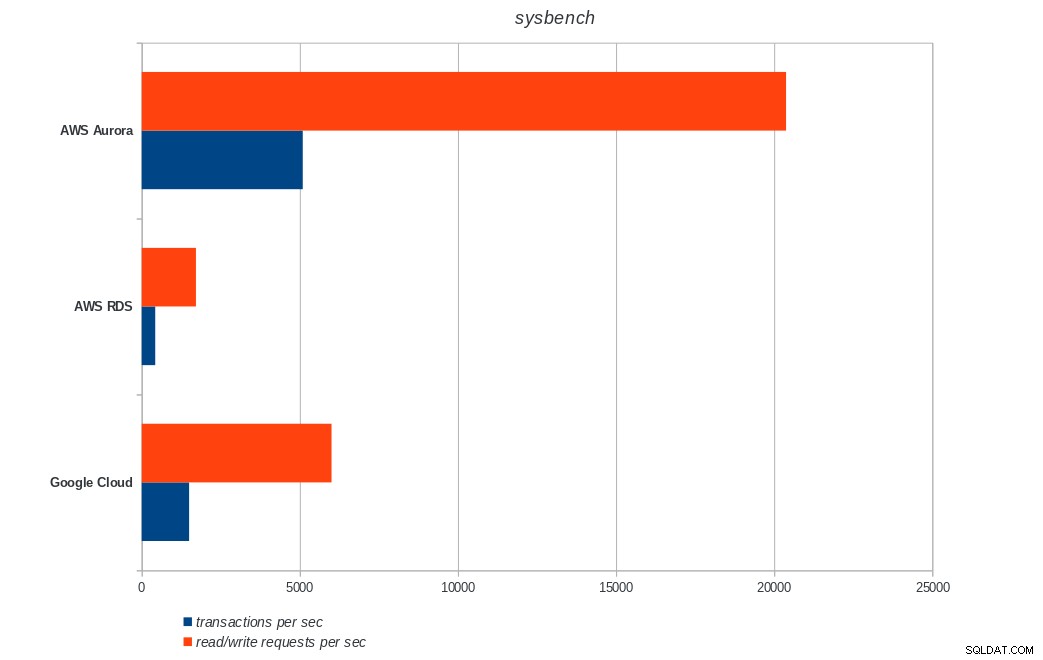 AWS Aurora, AWS RDS, Google Cloud SQL:wyniki sysbench PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:wyniki sysbench PostgreSQL Wniosek
Amazon Aurora jest zdecydowanie na pierwszym miejscu w testach zapisu ciężkich (sysbench), będąc jednocześnie na równi z Google Cloud SQL w testach odczytu/zapisu pgbench. Test obciążenia (inicjacja pgbench) stawia na pierwszym miejscu Google Cloud SQL, a za nim Amazon RDS. Opierając się na pobieżnym spojrzeniu na modele cenowe dla AWS Aurora i Google Cloud SQL, zaryzykowałbym stwierdzenie, że Google Cloud jest lepszym wyborem dla przeciętnego użytkownika, podczas gdy AWS Aurora lepiej nadaje się do środowisk o wysokiej wydajności. Więcej analiz nastąpi po ukończeniu wszystkich testów porównawczych.
Następna i ostatnia część tej serii testów będzie dotyczyć Microsoft Azure PostgreSQL.
Dziękujemy za przeczytanie i proszę o komentarz poniżej, jeśli masz uwagi.